教你如何在win7中的cygwin64下安装hadoop
首先我们要准备如下环境及软件:
win7(64位) cygwin 1.7.- jdk-6u25-windows-x64.zip hadoop-0.20..tar.gz
1.在win7系统上正常安装jdk,同时注意设置好java环境的变量:
主要的变量包括:JAVA_HOME,PATH,CLASSPATH
(不会设置的请自备梯子)
2.接下来是安装Hadoop,我目前安装的版本为0.20.2版本,为了方便,
我暂时是直接放到了cygwin64的/home目录下(正常情况下,请放在/usr目录下),
并使用tar命令进行解压操作。
lenovo@lenovo-PC /home
$ tar -zxvf hadoop-0.20..tar.gz
3.光安装完Hadoop是不够的,还需要一些简单的配置工作,主要的配置文件有4个,
它们位于Hadoop的安装目录的conf子目录下,分别是:
hadoop-env.sh
core-site.xml
hdfs-site.xml
mapred-site.xml
下面将是如何修改的详细部分:
(1) 修改hadoop-env.sh文件:
这步比较简单,只需要将JAVA_HOME 修改成JDK 的安装目录即可:
红色标出的是修改后的样子。
# Set Hadoop-specific environment variables here. # The only required environment variable is JAVA_HOME. All others are
# optional. When running a distributed configuration it is best to
# set JAVA_HOME in this file, so that it is correctly defined on
# remote nodes. # The java implementation to use. Required.
export JAVA_HOME=/cygdrive/d/android/java/jdk1.7.0_15 # Extra Java CLASSPATH elements. Optional.
# export HADOOP_CLASSPATH= # The maximum amount of heap to use, in MB. Default is .
# export HADOOP_HEAPSIZE= # Extra Java runtime options. Empty by default.
# export HADOOP_OPTS=-server # Command specific options appended to HADOOP_OPTS when specified
export HADOOP_NAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_NAMENODE_OPTS"
export HADOOP_SECONDARYNAMENODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_SECONDARYNAMENODE_OPTS"
export HADOOP_DATANODE_OPTS="-Dcom.sun.management.jmxremote $HADOOP_DATANODE_OPTS"
export HADOOP_BALANCER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_BALANCER_OPTS"
export HADOOP_JOBTRACKER_OPTS="-Dcom.sun.management.jmxremote $HADOOP_JOBTRACKER_OPTS"
# export HADOOP_TASKTRACKER_OPTS=
# The following applies to multiple commands (fs, dfs, fsck, distcp etc)
# export HADOOP_CLIENT_OPTS # Extra ssh options. Empty by default.
# export HADOOP_SSH_OPTS="-o ConnectTimeout=1 -o SendEnv=HADOOP_CONF_DIR" # Where log files are stored. $HADOOP_HOME/logs by default.
# export HADOOP_LOG_DIR=${HADOOP_HOME}/logs # File naming remote slave hosts. $HADOOP_HOME/conf/slaves by default.
# export HADOOP_SLAVES=${HADOOP_HOME}/conf/slaves # host:path where hadoop code should be rsync'd from. Unset by default.
# export HADOOP_MASTER=master:/home/$USER/src/hadoop # Seconds to sleep between slave commands. Unset by default. This
# can be useful in large clusters, where, e.g., slave rsyncs can
# otherwise arrive faster than the master can service them.
# export HADOOP_SLAVE_SLEEP=0.1 # The directory where pid files are stored. /tmp by default.
# export HADOOP_PID_DIR=/var/hadoop/pids # A string representing this instance of hadoop. $USER by default.
# export HADOOP_IDENT_STRING=$USER # The scheduling priority for daemon processes. See 'man nice'.
# export HADOOP_NICENESS=
(注意:这里的路径不能是windows 风格的目录d:\java\jdk1.7.0_15,而是LINUX 风格/cygdrive/d/java/jdk1.7.0_15)
(2) 修改core-site.xml:
红色标出的是增加的代码。
(3)修改hdfs-site.xml(指定副本为1)
红色标出的是增加的代码。
(4) 修改mapred-site.xml (指定jobtracker)
红色标出的是增加的代码。
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Put site-specific property overrides in this file. --> <configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
4.验证安装是否成功,并运行Hadoop
(1) 验证安装
(2) 格式化并启动Hadoop
$ bin/hadoop namenode –format
// :: INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = lenovo-PC/192.168.41.1
STARTUP_MSG: args = [▒Cformat]
STARTUP_MSG: version = 0.20.2
STARTUP_MSG: build = https://svn.apache.org/repos/asf/hadoop/common/branches/branch-0.20 -r 911707; compiled by 'chrisdo' on Fri Feb 19 08:07:34 UTC 2010
************************************************************/
Usage: java NameNode [-format] | [-upgrade] | [-rollback] | [-finalize] | [-importCheckpoint]
// :: INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at lenovo-PC/192.168.41.1
************************************************************/
$ bin/start-all.sh
starting namenode, logging to /home/hadoop-0.20./bin/../logs/hadoop-lenovo-namenode-lenovo-PC.out
localhost: /home/hadoop-0.20./bin/slaves.sh: line : ssh: command not found
localhost: /home/hadoop-0.20./bin/slaves.sh: line : ssh: command not found
starting jobtracker, logging to /home/hadoop-0.20./bin/../logs/hadoop-lenovo-jobtracker-lenovo-PC.out
localhost: /home/hadoop-0.20./bin/slaves.sh: line : ssh: command not found
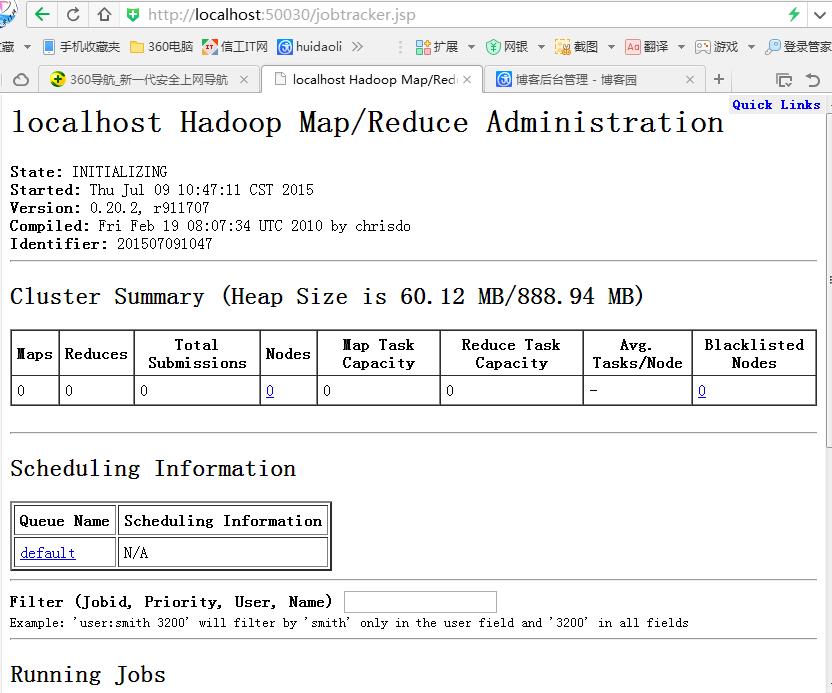
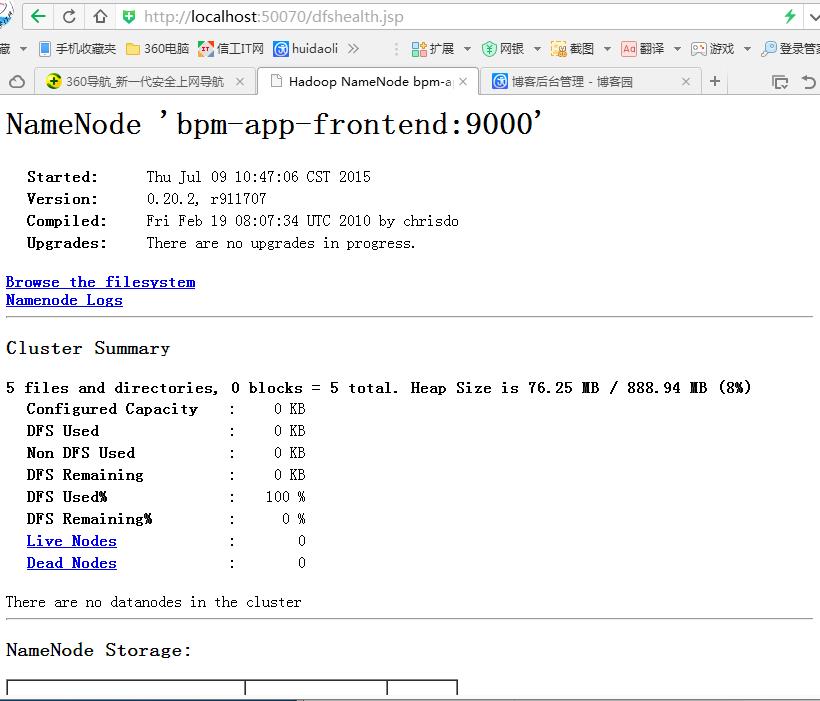
(3) 查看Hadoop
命令行查看:
(注意:win7下cygwin中DateNode和TaskTracker进程是无法显示的,应该是cygwin的问题)
现在可以网页查看效果了:
(4) 关闭Hadoop
bin/stop-all.sh
版权申明:本文有部分内容是参考网上的资料,如有疑问请联系,谢谢合作。
教你如何在win7中的cygwin64下安装hadoop的更多相关文章
- win7中python3.4下安装scrapy爬虫框架(亲测可用)
貌似最新的scrapy已经支持python3,但是错误挺多的,以下为在win7中的安装步骤: 1.首先需要安装Scrapy的依赖包,包括parsel, w3lib, cryptography, pyO ...
- 教你如何在win7中安装cygwin64
首先,说说我们为什么要安装cygwin吧,长期在win7下开发的人员可能不习惯使用unix系统,但由于工作问题,你又被逼要在unix环境下开发,那该如何是好啊?但现在你不用再纠结了,因为有cygwin ...
- 如何在Eclipse中配置Tomcat(免安装版)
如何在Eclipse中配置Tomcat(免安装版) 2013-10-09 23:19wgelgrsh | 分类:JAVA相关 | 浏览642次 分享到: 2013-10-10 17:10提问者采纳 ...
- 如何在Linux中轻松删除源安装的软件包?
第1步:安装Stow 在这个例子中,我们使用的是CentOS,因此我们需要扩展的EPEL库.您可以使用以下命令安装它们:yum install epel-release然后,下面这段命令:yum in ...
- win7 64位系统下安装autoitlibrary库遇到问题解决
转载来自http://blog.sina.com.cn/s/blog_53f023270101skyq.html 今天需要在win7 64位系统下安装autoitlibrary库,起初安装好了robo ...
- win7(windows 7)系统下安装SQL2005(SQL Server 2005)图文教程( Win7 SQL Server2005 安装教程)
win7(windows 7)系统下安装SQL2005(SQL Server 2005)图文教程 由于工作需要,今天要在电脑上安装SQL Server 2005.以往的项目都是使用Oracle,MS的 ...
- anaconda环境中---py2.7下安装tf1.0 + py3.5下安装tf1.5
anaconda环境中---py2.7下安装tf1.0 + py3.5下安装tf1.5 @wp20181030 环境:ubuntu18.04, anaconda2, ubuntu系统下事先安装了pyt ...
- UEFI+GPT安装WIN7,WIN8/WIN10下安装WIN7双系统
一.BIOS更改 首先来bios更改:我们知道,uefi+gpt引导虽然出来的时间比较长,但是win7还不能完全的支持,所以在使用uefi+gpt安装win7的时候就会出现各种错误!所以我们在安装Wi ...
- win7(x64)下安装cocos2d并编译安卓项目
好吧,不为啥,就是如题. win7 x64 脑袋内存比较小,说不定明儿就忘了,今天记录一下. 没有什么经验,所有步骤基本都是百度出来的,这里边操作边记录,为了保护原创作者,这里我都附上我查找的链接. ...
随机推荐
- 安装jdk配置环境变量JAVA_HOME不起作用
今天重新安装系统,需要装jdk,配置环境变量,于是先配置JAVA_HOME D:\Program Files\Java\jdk1.8.0_144, 然后在配置path路径,但是cmd到dos命令行输 ...
- vscode c++ 编译生成后,调试时无法命中断点
//test.cpp #include <stdio.h> ; void print_line(char *str) { if (str != NULL) printf("%s\ ...
- LeetCode - 868. Binary Gap
Given a positive integer N, find and return the longest distance between two consecutive 1's in the ...
- tomcat启动出错 invalid LOC header
tomcat启动出错 invalid LOC header,run as maven test 没有报错,只有警告: 'build.plugins.plugin.version' for org.ap ...
- Python yield 函数功能
python中有一个非常有用的语法叫做生成器,所利用到的关键字就是yield.有效利用生成器这个工具可以有效地节约系统资源,避免不必要的内存占用. 一段代码 def test_dict_sort(): ...
- java代码理解
public int maxProfit(int k, int[] prices) { int pl = prices.length; int nothin ...
- java生成excel,word文件
第一部分: 在网站开发中,用户可能需要打印word或者excel表,这种需求是非常多的. java语言生成excel表格和python的方式有点像,使用Apache POI的组件,一通全通.开发过程通 ...
- URL传值乱码问题。(已解决)
1. 问题描述 今天,我在写我的记账本的主界面,想在右上角加一个用户名提示,需要我把登陆界面的用户名传递给主界面,输入英文可以,输入汉字,发现显示在右上角的是乱码. 2. 解决办法 看这个乱码眼熟,我 ...
- Herriott池的设计
0.矩阵法计算光路 1.谐振腔和透镜组的等效,计算x和x’ 2.近轴光路的近似计算和矩阵法. 3.相邻光线的角度 4.为啥分模式 5.椭圆模式 6.要考虑的其他问题,相邻光斑的干涉
- ECMAScript基础
概念: 1):区分大小写 2):变量是弱类型的. 3):每行结尾的分号可有可无 4):注释与Java,C和PHP语言的注释相同 5):括号表明代码块 原始值:是存储在栈中的简单数据段,也就是说他们的值 ...