大数据和Hadoop时代的维度建模和Kimball数据集市
小结:
1、
Hadoop 文件系统中的存储是不可变的,换句话说,只能插入和追加记录,不能修改数据。如果你熟悉的是关系型数据仓库,这看起来可能有点奇怪。但是从内部机制看,数据库是以类似的机制工作,在一个进程异步地更新数据文件中的数据之前,将所有变更保存在一个不可变的预写式日志(WAL- write-ahead log,Oracle中称为redo log)中。
2、
Hadoop上的维度建模
为了解决性能问题,可以利用反规范化将大的维度表放进事实表,以保证数据是同定位的(co-located),而对较小的维度表可以在所有节点上广播(broadcast)。
3、
为了关联它们,需要在网络上发送数据,这样做会影响性能。
处理这个问题的一个策略,是在集群的所有节点上复制要关联的表,该策略被称为广播式关联(broadcast join)。
4、
我同意起初仅转储原始数据,这时不过多考虑结构是有意义的。但是,这不应该成为不对数据进行建模的借口。只读方式的结构只是降低了下游系统的能力和责任,一些人不得不咬牙去定义数据类型。访问无模式数据转储的每一个进程都需要自己弄清楚发生了什么,而这完全是多余的。通过定义数据类型和正确的结构,可以很容易地避免这些工作。
https://mp.weixin.qq.com/s/0Tn3lQ7BHnL0yyPrY6kT6g
大数据和Hadoop时代的维度建模和Kimball数据集市
本文翻译自“Dimensional Modeling and Kimball Data Marts in the Age of Big Data and hadoop”,翻译已获得原作者 Uli Bethke 授权。Uli Bethke 是 Sonra 公司的 CEO,爱尔兰 Hadoop 用户组主席,也是 Oracle 的 ACE。
维度建模已死?
在回答这个问题之前,让我们回头来看看什么是所谓的维度数据建模。
为什么需要为数据建模?
有一个常见的误区,数据建模的目的是用 ER 图来设计物理数据库,实际上远不仅如此。数据建模代表了企业业务流程的复杂度,记录了重要的业务规则和概念,并有助于规范企业的关键术语。它清晰地阐述、协助企业揭示商业过程中模糊的想法和歧义。此外,可以使用数据模型与其他利益相关者进行有效沟通。没有蓝图,不可能建造一个房子或桥梁。所以,没有数据模型这样一个蓝图,为什么要建立一个数据应用,比如数据仓库呢?
为什么需要维度建模?
维度建模是数据建模的一种特殊方法。维度建模有两个同义词,数据集市和星型结构。星型结构是为了更好地进行数据分析,参考下面图示的维度模型,可以有一个很直观的理解。通过它可以立即知道如何通过客户、产品、时间对订单进行分割,如何通过度量的聚集和比较对订单业务过程进行绩效评估。
维度建模最关键的一点,是要定义事务性业务过程中的最低粒度是什么。如果切割或钻入数据,到叶级就不能再往下钻取。从另一个角度看,星型结构中的最低粒度,即事实和维度之间没有进行任何聚集的关联。
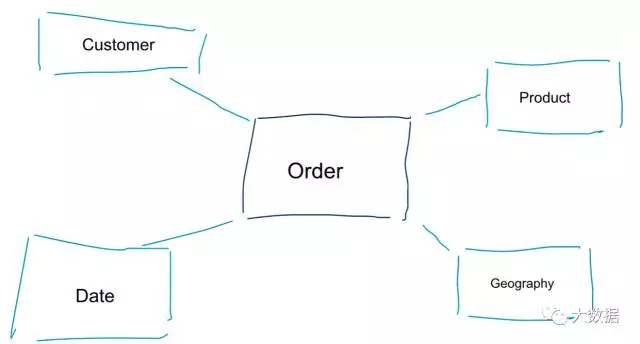
数据建模和维度建模
标准数据建模的任务,是消除重复和冗余的数据。当数据发生变化时,我们只需在一个地方修改它,这有助于保证数据的质量,避免了不同地方的数据不同步。参考下面图示的模型,它包含了代表地理概念的几张表。在规范化模型中,每个实体有一个独立的表,数据建模只有一张表:geography。在这张表中,city 会重复出现很多次。而对于每个 city,如果 country 改变了名字,就不得不在很多地方进行更新。
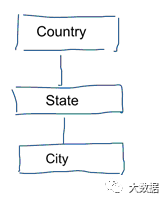
注:标准数据模型总是遵守 3NF 模式。
标准的数据建模,本身并不是为了商业智能的工作负载而设计的。太多的表会导致过多的关联,而表关联会导致性能下降,在数据分析中我们要尽力去避免这种情形发生。数据建模过程中,通过反规范化把多个相关表合并成一个表,例如前面例子里的多个表被预合并成一个 geography 表。
那么为何部分人认为维度建模已死?
一般人都认可数据建模的方式,而把维度建模当成特殊处理方式,它们都是有价值的。那为什么在大数据和 Hadoop 的时代,部分人会认为维度建模没用了?
“数据仓库之死”
首先,一些人混淆了维度建模和数据仓库。他们认为数据仓库已死,于是得出结论:维度建模也可以被丢进历史的垃圾箱。这种论点在逻辑上是连贯的,但是,数据仓库的概念远没有过时。我们总是需要集成的、可靠的数据来产生商业智能仪表盘(BI Dashboards)。
只读结构的误解
第二个常听见的争论,比如“我们遵循只读方式的结构(Schema),所以不需要对数据再进行建模了”。依我看来,这是数据分析过程中最大的误解之一。我同意起初仅转储原始数据,这时不过多考虑结构是有意义的。但是,这不应该成为不对数据进行建模的借口。只读方式的结构只是降低了下游系统的能力和责任,一些人不得不咬牙去定义数据类型。访问无模式数据转储的每一个进程都需要自己弄清楚发生了什么,而这完全是多余的。通过定义数据类型和正确的结构,可以很容易地避免这些工作。
再谈反规范化和物理模型
是否那些宣传维度建模的观点实际上已过时了?的确有些观点比上面列出的两条更好,要理解它们需要对物理建模和 Hadoop 的工作方式有一些了解。
前面简单提到采用维度建模的原因之一,和数据的物理存储方式有关。标准数据建模中每个真实世界里的实体,有一个自己的表。我们这样做,是为了避免数据冗余和质量问题在数据中蔓延。越多的表,就需要越多的关联,这是标准建模的缺点。表关联的代价是昂贵的,特别是关联数据集中关联大量记录的时候尤其突出。当我们考虑维度建模时,会把多个表合并起来,这就是所谓的预关联或者说数据反规范化。最后的结果是,得到更少的表、更少的关联、更低的延迟和更好的查询性能。
可参与领英上相关的讨论。
彻底反规范化
为什么不把反规范化做到彻底?去掉所有的表关联只保留一张表?的确,这样做可以不需要对任何表进行关联,但是可以想象到,它会带来一些负面影响。首先,它需要更多的存储,因为要存储大量的冗余数据。随着数据分析的列式存储格式的出现,这一点现在不那么令人担忧了。反规范化最大的问题是,每次属性值发生变化,就不得不在很多地方进行更新,可能是几千甚至几百万次更新。一个解决办法是在晚上对模型进行全量重载,通常这比增量更新要更快、更容易。列式数据库通常采用这种方法,首先将要做的更新存储在内存中,然后异步地写入磁盘。
分布式关系型数据库(MPP)上的数据分布
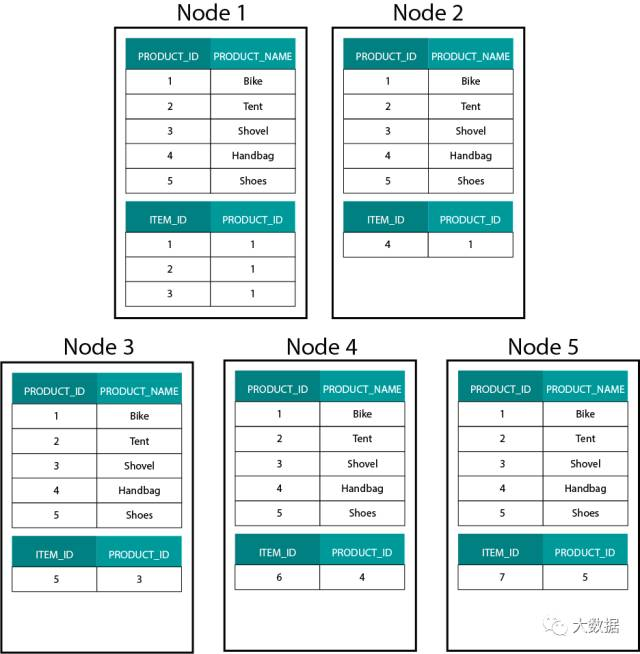
在 Hadoop,例如 Hive、SparkSQL 上建立维度模型,要很好地理解一个技术上的核心特征,就是它和分布式关系型数据库(MPP)上的建立方式是不一样的。在 MPP 中的节点上分布数据,可以控制每条数据记录的位置。基于分区策略,例如 Hash、List、Range 等,可以在同一个节点上跨表同定位(co-located)各个记录的键值。由于数据的局部性得到保证,关联速度会非常快,因为不需要在网络上发送任何数据。参考下面图示的例子,在 ORDER 和 ORDER_ITEM 表中有相同 ORDER_ID 的记录存储在同一节点上:
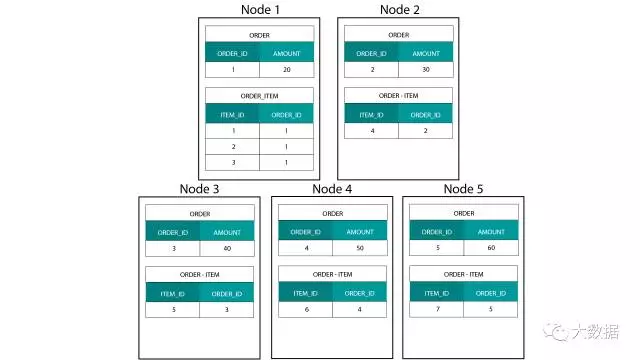
ORDER 和 ORDER_ITEM 表中 ORDER_ID 对应的键值,在相同的节点做到同定位。
Hadoop上的数据分布
数据分布在基于 Hadoop 的系统中是非常不同的,我们将数据分割成大型的块(chunks),并在 Hadoop 分布式文件系统(HDFS)的各个节点进行分发和复制。这种数据分发策略不能保证数据的一致性。参考下面图示的例子,记录 ORDER_ID 的键被存储在不同的节点:
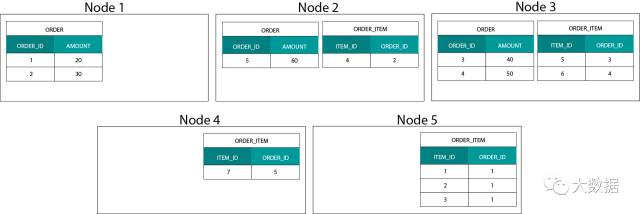
为了关联它们,需要在网络上发送数据,这样做会影响性能。
处理这个问题的一个策略,是在集群的所有节点上复制要关联的表,该策略被称为广播式关联(broadcast join)。如果对 MPP 使用相同的策略,可以想象,只能用在较小的 lookup 或维度表中。
那么当关联一个大的事实表和一个大的维度表,比如客户或产品,甚至关联两个大型事实表时,我们该怎么办?
Hadoop上的维度建模
为了解决性能问题,可以利用反规范化将大的维度表放进事实表,以保证数据是同定位的(co-located),而对较小的维度表可以在所有节点上广播(broadcast)。
关联两个大型事实表时,可以把低粒度的表嵌套到更高粒度的表中,例如把 ORDER_ITEM 表嵌套到 ORDER 表中。高级的查询引擎,比如 Impala 或 Drill 可以让数据扁平化(flatten out):

嵌套数据的策略很有用,类似于 Kimball 概念中用桥接表来表示维度模型中的 M:N 关系。
Hadoop和缓慢变化维
Hadoop 文件系统中的存储是不可变的,换句话说,只能插入和追加记录,不能修改数据。如果你熟悉的是关系型数据仓库,这看起来可能有点奇怪。但是从内部机制看,数据库是以类似的机制工作,在一个进程异步地更新数据文件中的数据之前,将所有变更保存在一个不可变的预写式日志(WAL- write-ahead log,Oracle中称为redo log)中。
不可变性(immutability)对维度模型有什么影响?你也许还记得维度建模课程中渐变维的概念(Slowly Changing Dimensions - SCDS)。SCDS 有选择地保存属性值变更的历史,于是可以在某个时间点上对属性值进行度量。但这不是默认的处理方式,默认情况下会用最新的值来更新维度表。那么在 Hadoop 上如何选择呢?记住!我们不能更新数据。我们可以简单地为 SCD 选择默认方式并对每一个变化进行审核(audit)。如果想运行基于当前值的报表,可以在 SCD 之上创建一个视图,让它仅仅检索到最新值,利用 Windows 函数可以很容易做到这一点。或者,可以运行一个所谓合并(Compaction)的服务,用最新的值物理地创建维度表的一个单独版本。
Hadoop的存储演化
Hadoop 平台的供应商并没有忽视这些 Hadoop 的限制,例如 Hive 就提供了满足 ACID 的事务和可更新的表。根据大量的主要公开问题以及个人经验,这个特性还没有完善到可以部署生产环境。Cloudera 采取了另外一个手段,利用 Kudu 建立了一个新的可变更存储格式,它并没有基于 HDFS,而是基于本地 OS 操作系统。它完全摆脱了 Hadoop 的限制,类似于列式 MPP 的传统存储层。通常来说,在 Impala + Kudu 这样一个 MPP 上运行 BI 和 Dashboard 的任何使用场景,会比 Hadoop 更好。不得不说,当它涉及到弹性、并发性和扩展性时,有自己的局限。当遇到这些限制时,Hadoop 和它的近亲 Spark 是解决 BI 工作负载的好选择。
判决:维度模型和星型模式过时了吗?
我们都知道,Ralph Kimball 已经退休了,但他设计原则的思想和观念仍然是有效的,也将会继续存在。即使我们不得不让它们适应新的技术和存储类型,它们仍然能够带来巨大的价值。
大数据和Hadoop时代的维度建模和Kimball数据集市的更多相关文章
- 大数据架构师必读的NoSQL建模技术
大数据架构师必读的NoSQL建模技术 从数据建模的角度对NoSQL家族系统做了比较简单的比较,并简要介绍几种常见建模技术. 1.前言 为了适应大数据应用场景的要求,Hadoop以及NoSQL等与传统企 ...
- 大数据和Hadoop生态圈
大数据和Hadoop生态圈 一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop ...
- 大数据和hadoop有什么关系?
本文资料来自百度文库相关文档 Hadoop,Spark和Storm是目前最重要的三大分布式计算系统,Hadoop常用于离线的复杂的大数据处理,Spark常用于离线的快速的大数据处理,而Storm常用于 ...
- Hadoop专业解决方案-第1章 大数据和Hadoop生态圈
一.前言: 非常感谢Hadoop专业解决方案群:313702010,兄弟们的大力支持,在此说一声辛苦了,经过两周的努力,已经有啦初步的成果,目前第1章 大数据和Hadoop生态圈小组已经翻译完成,在此 ...
- 大数据和Hadoop平台介绍
大数据和Hadoop平台介绍 定义 大数据是指其大小和复杂性无法通过现有常用的工具软件,以合理的成本,在可接受的时限内对其进行捕获.管理和处理的数据集.这些困难包括数据的收入.存储.搜索.共享.分析和 ...
- 大数据技术Hadoop入门理论系列之一----hadoop生态圈介绍
Technorati 标记: hadoop,生态圈,ecosystem,yarn,spark,入门 1. hadoop 生态概况 Hadoop是一个由Apache基金会所开发的分布式系统基础架构. 用 ...
- [Hadoop 周边] 浅谈大数据(hadoop)和移动开发(Android、IOS)开发前景【转】
原文链接:http://www.d1net.com/bigdata/news/345893.html 先简单的做个自我介绍,我是云6期的,黑马相比其它培训机构的好偶就不在这里说,想比大家都比我清楚: ...
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- 老李分享:大数据框架Hadoop和Spark的异同 1
老李分享:大数据框架Hadoop和Spark的异同 poptest是国内唯一一家培养测试开发工程师的培训机构,以学员能胜任自动化测试,性能测试,测试工具开发等工作为目标.如果对课程感兴趣,请大家咨 ...
随机推荐
- Android获取通讯录并上传(包含通讯录加密)
好久没更新文章了,近期在做通讯录上传,把它分享出来,送给需要的朋友. 写了一个通讯录工具类,直接放代码吧,关键位置通过注释来解释. 这个工具类包含通讯录获取,加密,然后上传操作.看不懂的可以留言 im ...
- Android研发中对String的思考(源代码分析)
1.经常使用创建方式思考: String text = "this is a test text "; 上面这一句话实际上是运行了三件事 1.声明变量 String text; ...
- 20.翻译系列:Code-First中的数据库迁移技术【EF 6 Code-First系列】
原文链接:https://www.entityframeworktutorial.net/code-first/migration-in-code-first.aspx EF 6 Code-First ...
- 音视频编解码: YUV存储格式中的YUV420P,YUV420SP,NV12, NV21理解(转)
概述 之前介绍了YUV码流的采样格式,下面分析下YUV码流的存储格式,YUV码流的存储格式与采样格式息息相关.总的来讲,YUV存储格式主要分为两种: planar 平面格式 指先连续存储所有像素点的 ...
- iOS- UITextView与键盘回收与键盘遮挡输入框
一.UITextView 可以实现多行输入的文本框,基本属性与UITextField相似,可以输入多行,可以滚动.UITextView还有个代理方式- (BOOL)textView:(UITextVi ...
- 【Unity】UGUI聊天消息气泡 随文本内容自适应
游戏中需要用做UGUI做聊天界面.其中聊天气泡ChatItem的UI要求能随着聊天内容文本的长度自适应的. 网上搜了一下聊天气泡的UI,发现都不太符合咱的需求,具体来说是文本宽度不足一行时,文本宽度自 ...
- [Java并发编程(五)] Java volatile 的实现原理
[Java并发编程(五)] Java volatile 的实现原理 简介 在多线程并发编程中 synchronized 和 volatile 都扮演着重要的角色,volatile 是轻量级的 sync ...
- Golang学习教程
字节跳动已经全线从Python转Golang了,可能开始学习Golang这门语言会觉得无所适从,和Java,C++,Python等都不大一样,但是用多了会发现这门语言设计的还是很优雅的,下面总结Gol ...
- 解决使用微软模拟器VS Emulator for Android在VS2017 Xamarin开发中不能调试程序的问题。
在使用VS2017 XAMARIN调试Android应用程序时,屏幕闪一下,进入不了调试(使用谷歌的模拟器可以调试,但是太慢), 我们现在来解决一下这个问题. 第一步:打开Hyper-V管理器 第二步 ...
- Jquery EasyUI Combotree只能选择叶子节点且叶子节点有多选框
Jquery EasyUI Combotree只能选择叶子节点且叶子节点有多选框 Jquery EasyUI Combotree单选框,Jquery EasyUI Combotree只能选择叶子节点 ...