深度学习基础(三)NIN_Network In Network
该论文提出了一种新颖的深度网络结构,称为“Network In Network”(NIN),以增强模型对感受野内local patches的辨别能力。与传统的CNNs相比,NIN主要的创新点在于结构内使用的mlpconv layers(multiple layer perceptron convolution layers)和global average pooling。下面先介绍二者:
- MLP Convolution Layers
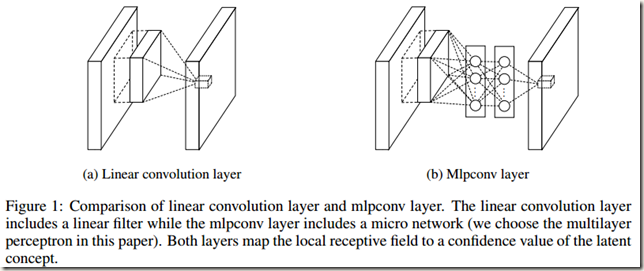
如Fig.1所示,传统卷积网络中的 linear convolution layer由linear filter+nonlinear activation构成,而mlpconv layer内部是一个micro network(在论文中作者选择multilayer perceptron(MLP)作为 micro network)。作者之所以尝试寻找一种新的layer代替 linear convolution layer,是因为传统的卷积层存在着明显的缺陷。一是CNN中的卷积核是 data patch 上的一个广义线性模型(Generalized linear model,GLM),它的 abstraction 程度较低(这里的abstraction是指特征对同一概念(concept)的变体是不变的)。如果将GLM换成一个更有效的非线性函数逼近器就能够增强 local model 的abstraction能力。二是当latent concepts的samples线性可分时,GLM才能达到很好的abstraction程度,比如concepts的变体全都在GLM定义的分界面一侧,我们在使用传统卷积时实际上是假设 the latent concepts是线性可分的。但是,相同concept的data往往是呈非线性流形(nonlinear manifold)分布的,因而对应那些concepts的表示(representations)通常是输入的高度非线性函数。当latnet concepts的samples是线性可分时,linear convolution的abstraction能力是足够的。线性不可分时,传统的CNN会通过利用一系列完备的filters覆盖latent concepts的所有变体来弥补线性划分的不足。也就是说,对于同一个concept,使用不同的linear filters来检测不同的变体(variations)。但是,单个concept有太多filters的话下一层需要考虑到所有来自前面layers的combinations of variations,这会给下一层增加额外的负担。正如CNN中那样,来自higher layers的filters会在原始输入上映射出更大的区域,这样通过combinig来自低层的lower level concepts会产生一个higher level的concept。因此作者认为,在将lower level concepts combining成higher level concepts之前,在每一个local patch上进行更好的abstraction会很有意义。(patch:每次filter进行卷积时input或faeture maps参数计算的小区域;concept: 应该是希望检测的objects的高级特征,如船舶、飞机等,论文后面说是categories;abstraction: 对同一concept的变体提取的特征不变的特征提取)
为此,作者将GLM替换为一个“micro network”结构,它是一个通用非线性函数逼近器(general nonlinear function approximator)。论文中作者选择多层感知器(multilayer perceptron,MLP)作为micro network,原因有如下两点:
1) 多层感知器与卷积神经网络结构兼容,可以使用反向传播算法进行训练
2) 多层感知器本身可以是一个深度模型(Deep model),这与feature re-use的精神是一致的
mlpconv layer执行的计算如下:

式中,n是多层感知器层数,从max()也可以看出多层感知器中使用的激活函数是Rectified linear unit。该计算过程等同于在一个传统的卷积层之后连接级联的跨通道参数池化层。每一个池化层先在输入的feature maps上进行加权线性重构,然后将结果输入一个rectifier linear unit激活。跨通道池化得到feature maps接下来会在后面的layers中重复被跨通道池化。这种级联的跨通道参数池化结构(cascaded cross channel parameteric pooling structure)允许复杂的可学习的跨通道信息交互。
跨通道参数池化层就相当于一个卷积核为1*1的 linear convolution layer(包括激活函数)。这种解释有助于直观理解NIN的结构。
此外,论文中还解释了为何micro network不使用maxout network。如下:
maxout network通过对affine feature maps进行最大池化达到减少feature maps数量的目的(affine feature maps是 linear convolution 不带activation function直接计算得到的结果)。最大池化线性函数的结果能够得到一个可以逼近任何凸函数的分段线性逼近器,所以与进行线性划分的传统卷积层相比,maxout network效果更好,因为它能够对位于凸集(Convex set)内的concepts进行正确划分。
但是,maxout network默认在输入空间中latent concepts的samples分布在一个凸集内,这一先验知识却不一定成立。考虑到distributions of the latent concepts的复杂性,我们需要的是一个更加通用的函数逼近器(more general function approximator),比如MLP
- Global Average Pooling
传统的CNNs在网络的lower layers执行卷积。在分类任务中,网络最后一层卷积层的feature maps被向量化,并且随后被送入全连接层与softmax logistic regression layer。这种结构结合了convolutional structure和传统的neural network classifiers,将卷积层视为feature extractors,然后使用传统的方法对得到的特征进行分类。但是,全连接层在训练时容易overfitting,后来采用regularizer方法dropout大幅减轻了过拟合。
在该论文中,作者提出了另外一种叫做global average pooling的方法来代替传统的全连接层。具体是:在最后一层mlpconv layer中为分类任务中的每一个类生成一个feature map;后面不接全连接网络,而是取每个feature map的均值,这样就得到一个长度为N的向量,与类别对应;添加softmax层,前面的向量直接传入计算,这样就得到了每个类别的概率。
与全连接层相比,全局平均池化有三个优点:
1) 全局平均池化强制建立feature maps和categories之间的对应关系,这使它更适用于卷积结构。因此feature maps可以很容易地被转换成categories confidence maps
2)全局平均池化层中没有需要优化的参数,因而能够避免overfitting
3)全局平均池化对空间信息进行汇总,因此它对输入的空间转换更加鲁棒
Global average pooling 可以被视为一个能够将feature maps强制转换为concepts(categories)的confidence maps的structural regularizer,因为mlpconv layers能比GLMs更好地逼近confidence maps
- Network In Network Structure
论文中有句概括性的话,“NIN is proposed from a more general perspective, the micro network is integrated into CNN structure in persuit of better abstractions for all levels of features”。翻译过来就是,NIN是从一个更一般的角度(非线性划分)提出的,将micro network 整合到CNN结构中是为了更好地abstract所有levels的特征。
NIN的整个结构是由一系列mlpconv layers + global average pooling + objective cost layer 构成。除此之外,可以像在CNN和maxout network中那样在mlpconv layers之间添加sub-sampling layers。
下面Fig.2是一个NIN结构,由3层mlpconv layers堆叠+1层global average pooling layer构成,每个mlpconv layer内包含一个3层的感知器。:
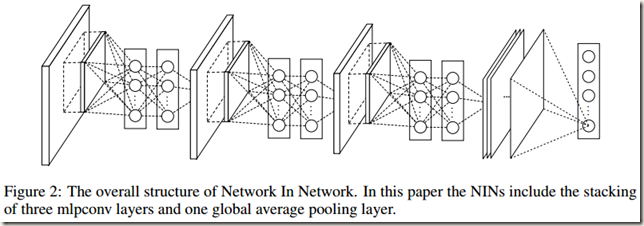
Fig.2很好理解,有点困惑的可能是mlpconv layers。前面说到过,在mlpconv layers中先进行一次传统的卷积(filter尺寸随意,比如3*3),然后结果经过MLP计算(1*1卷积)得到结果。下面根据下图介绍具体过程:
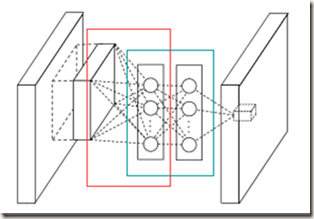
1) 红框部分是在进行传统的卷积,可见卷积使用了多个filters。图中竖排圆圈是卷积得到的feature maps在某个位置上所有通道的数值,而不是某个feature map。这也是为了简单直
观。
2) 图中蓝色框部分是MLP的前两层,最后一层在mlpconv layer输出的feature map上,只有一个节点,即蓝色框后面的小立方体
3)MLP是在多组feature maps的同一位置建立的,而且feature maps每个通道内的元素前一组feature maps中对应元素连接的权重相同(想象1*1卷积)
4)MLP计算过程中得到的feature maps长宽一致。理解不了的话可以从1*1卷积的角度思考
下面是一幅带参数的NIN,可以帮助我们理解mlpconv layers:
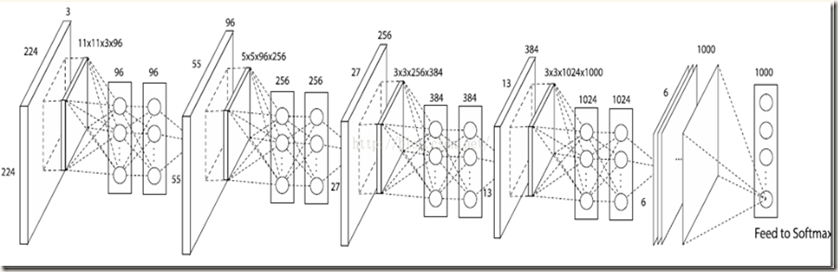
下图是Fig.2中NIN结构的细节:
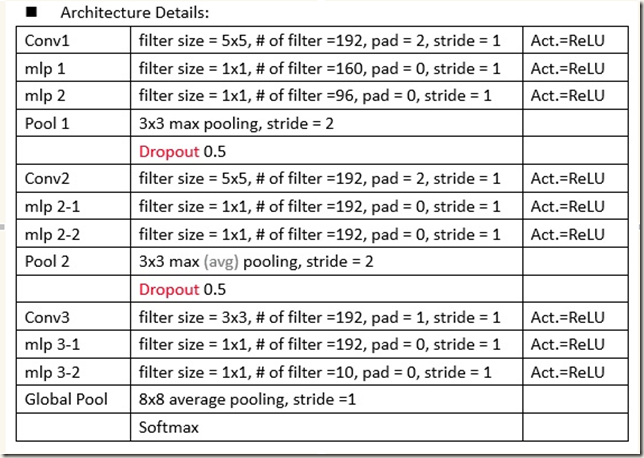
看到网上有人针对上图中的结构写了实现代码就搬过来了。如下,dropout设置为0.5,weight decay设置为0.0001,使用data augmentation。在数据的预处理上采用减掉mean再除以std的方法:
import keras
import numpy as np
from keras.datasets import cifar10
from keras.preprocessing.image import ImageDataGenerator
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Conv2D, MaxPooling2D, GlobalAveragePooling2D, AveragePooling2D
from keras.initializers import RandomNormal
from keras import optimizers
from keras.callbacks import LearningRateScheduler, TensorBoard
from keras.layers.normalization import BatchNormalization batch_size = 128
epochs = 164
iterations = 391
num_classes = 10
dropout = 0.5
log_filepath = './nin' def color_preprocessing(x_train,x_test):
x_train = x_train.astype('float32')
x_test = x_test.astype('float32')
mean = [125.307, 122.95, 113.865]
std = [62.9932, 62.0887, 66.7048]
for i in range(3):
x_train[:,:,:,i] = (x_train[:,:,:,i] - mean[i]) / std[i]
x_test[:,:,:,i] = (x_test[:,:,:,i] - mean[i]) / std[i] return x_train, x_test def scheduler(epoch):
learning_rate_init = 0.08
if epoch >= 81:
learning_rate_init = 0.01
if epoch >= 122:
learning_rate_init = 0.001
return learning_rate_init def build_model():
model = Sequential() model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.01), input_shape=x_train.shape[1:]))
model.add(Activation('relu'))
model.add(Conv2D(160, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.05)))
model.add(Activation('relu'))
model.add(Conv2D(96, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.05)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same')) model.add(Dropout(dropout)) model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.05)))
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.05)))
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1),padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.05)))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(3, 3),strides=(2,2),padding = 'same')) model.add(Dropout(dropout)) model.add(Conv2D(192, (3, 3), padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.05)))
model.add(Activation('relu'))
model.add(Conv2D(192, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.05)))
model.add(Activation('relu'))
model.add(Conv2D(10, (1, 1), padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.05)))
model.add(Activation('relu')) model.add(GlobalAveragePooling2D())
model.add(Activation('softmax')) sgd = optimizers.SGD(lr=.1, momentum=0.9, nesterov=True)
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model if __name__ == '__main__': # load data
(x_train, y_train), (x_test, y_test) = cifar10.load_data()
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes) x_train, x_test = color_preprocessing(x_train, x_test) # build network
model = build_model()
print(model.summary()) # set callback
tb_cb = TensorBoard(log_dir=log_filepath, histogram_freq=0)
change_lr = LearningRateScheduler(scheduler)
cbks = [change_lr,tb_cb] # set data augmentation
print('Using real-time data augmentation.')
datagen = ImageDataGenerator(horizontal_flip=True,width_shift_range=0.125,height_shift_range=0.125,fill_mode='constant',cval=0.)
datagen.fit(x_train) # start training
model.fit_generator(datagen.flow(x_train, y_train,batch_size=batch_size),steps_per_epoch=iterations,epochs=epochs,callbacks=cbks,validation_data=(x_test, y_test))
model.save('nin.h5')
此外,作者又在这份代码的基础上加入了batch normalization改进该网络,见此。具体是其它地方完全不动,只在conv和activation之间加入一个bn层,如下:
model.add(Conv2D(192, (5, 5), padding='same', kernel_regularizer=keras.regularizers.l2(0.0001), kernel_initializer=RandomNormal(stddev = 0.01), input_shape=x_train.shape[1:]))
model.add(BatchNormalization())
model.add(Activation('relu'))
- Experiment
实验内容见论文或下方的翻译链接
- 参考文献
深度学习基础(三)NIN_Network In Network的更多相关文章
- 算法工程师<深度学习基础>
<深度学习基础> 卷积神经网络,循环神经网络,LSTM与GRU,梯度消失与梯度爆炸,激活函数,防止过拟合的方法,dropout,batch normalization,各类经典的网络结构, ...
- 深度学习基础系列(九)| Dropout VS Batch Normalization? 是时候放弃Dropout了
Dropout是过去几年非常流行的正则化技术,可有效防止过拟合的发生.但从深度学习的发展趋势看,Batch Normalizaton(简称BN)正在逐步取代Dropout技术,特别是在卷积层.本文将首 ...
- 深度学习基础系列(五)| 深入理解交叉熵函数及其在tensorflow和keras中的实现
在统计学中,损失函数是一种衡量损失和错误(这种损失与“错误地”估计有关,如费用或者设备的损失)程度的函数.假设某样本的实际输出为a,而预计的输出为y,则y与a之间存在偏差,深度学习的目的即是通过不断地 ...
- TensorFlow深度学习基础与应用实战高清视频教程
TensorFlow深度学习基础与应用实战高清视频教程,适合Python C++ C#视觉应用开发者,基于TensorFlow深度学习框架,讲解TensorFlow基础.图像分类.目标检测训练与测试以 ...
- [笔记] 基于nvidia/cuda的深度学习基础镜像构建流程 V0.2
之前的[笔记] 基于nvidia/cuda的深度学习基础镜像构建流程已经Out了,以这篇为准. 基于NVidia官方的nvidia/cuda image,构建适用于Deep Learning的基础im ...
- 深度学习基础(五)ResNet_Deep Residual Learning for Image Recognition
ResNet可以说是在过去几年中计算机视觉和深度学习领域最具开创性的工作.在其面世以后,目标检测.图像分割等任务中著名的网络模型纷纷借鉴其思想,进一步提升了各自的性能,比如yolo,Inception ...
- 深度学习基础(CNN详解以及训练过程1)
深度学习是一个框架,包含多个重要算法: Convolutional Neural Networks(CNN)卷积神经网络 AutoEncoder自动编码器 Sparse Coding稀疏编码 Rest ...
- 机器学习&深度学习基础(tensorflow版本实现的算法概述0)
tensorflow集成和实现了各种机器学习基础的算法,可以直接调用. 代码集:https://github.com/ageron/handson-ml 监督学习 1)决策树(Decision Tre ...
- 机器学习&深度学习基础(目录)
从业这么久了,做了很多项目,一直对机器学习的基础课程鄙视已久,现在回头看来,系统的基础知识整理对我现在思路的整理很有利,写完这个基础篇,开始把AI+cv的也总结完,然后把这么多年做的项目再写好总结. ...
随机推荐
- maven在Idea建立工程,运行出现Server IPC version 9 cannot communicate with client version 4错误
问题的根源在于,工程当中maven dependencies里面的包,有个hadoop-core的包,版本太低,这样,程序里面所有引用到org.apache.hadoop的地方,都是低版本的,你用的是 ...
- 城市经纬度 json 理解SignalR Main(string[] args)之args传递的几种方式 串口编程之端口 多线程详细介绍 递归一个List<T>,可自己根据需要改造为通用型。 Sql 优化解决方案
城市经纬度 json https://www.cnblogs.com/innershare/p/10723968.html 理解SignalR ASP .NET SignalR 是一个ASP .NET ...
- 基于Spring aop写的一个简单的耗时监控
前言:毕业后应该有一两年没有好好的更新博客了,回头看看自己这一年,似乎少了太多的沉淀了.让自己做一个爱分享的人,好的知识点拿出来和大家一起分享,一起学习. 背景: 在做项目的时候,大家肯定都遇到对一些 ...
- python 信息同时输出到控制台与文件
python编程中,往往需要将结果用print等输出,如果希望输出既可以显示到IDE的屏幕上,也能存到文件中(如txt)中,该怎么办呢? 方法1 可通过日志logging模块输出信息到文件或屏幕.但可 ...
- 【资料下载区】【iCore1S相关代码、资料下载地址】更新日期2017/10/09
[iCore1S相关文档][更新中...] iCore1S原理图(PDF)下载iCore1S引脚注释(PDF)下载 [iCore1S相关例程代码][ARM][更新中...] DEMO1.0测试程序发布 ...
- hdoj:2071
Max Num Time Limit: 1000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Others)Total Sub ...
- SQL server 在附加数据库后,数据库总是变成了只读
1. 要把数据库文件的属性改了 右键点击两个文件的属性--安全--添加--立即查找--找everyone这个用户把他的权限都勾上 确定再附加就OK. 2. 在数据库管理器中对数据库点右键属性,然后切 ...
- JavaScript系统对象
1. 本地对象(非静态对象) 常用对象有: Object.Function.Array.String.Boolean.Number.Date.RegExp.Error 注:本地对象需要new之后再使用 ...
- IE 浏览器旧版本下载
1. http://www.oldversion.com/windows/internet-explorer/ IE10 浏览器 32bit & 64 bit:下载 2. https://ww ...
- VS Code设置成中文界面
1.打开VS Code,按:ctrl+shift+p打开指令面板,输入lang,选择Configure Display Language 2.将"locale"后面的"e ...