详解Oracle partition分区表
随着表中行数的增多,管理和性能性能影响也将随之增加。备份将要花费更多时间,恢复也将 要花费更说的时间,对整个数据表的查询也将花费更多时间。通过把一个表中的行分为几个部分,可以减少大型表的管理和性能问题,以这种方式划分发表数据的方法称为对表的分区。分区表的优势:
Oracle数据库提供对表或索引的分区方法有几种:
二、实例演示Oracle对表或索引的分区操作
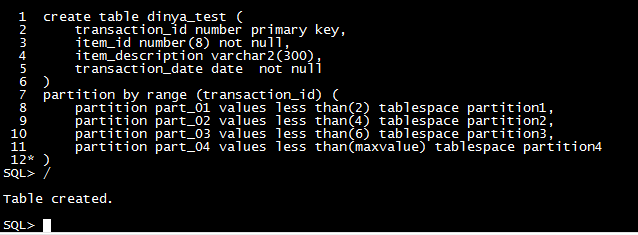
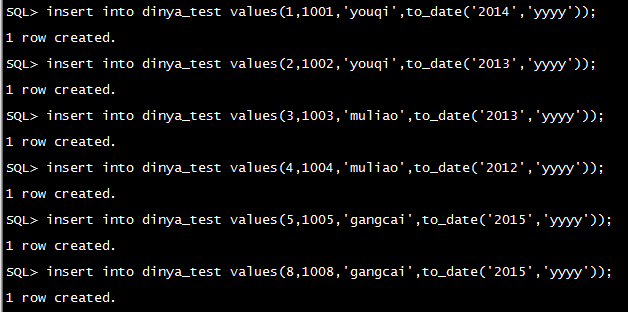
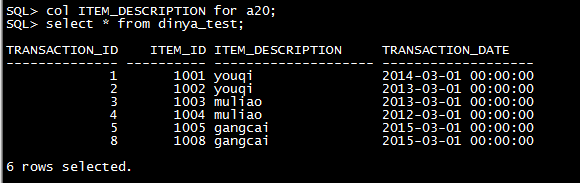
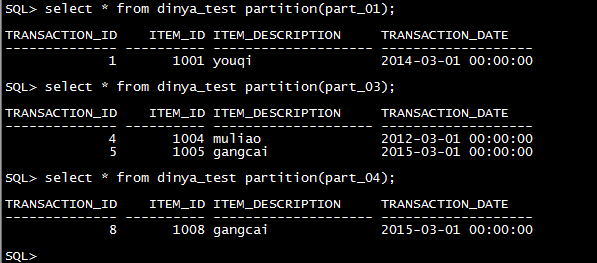


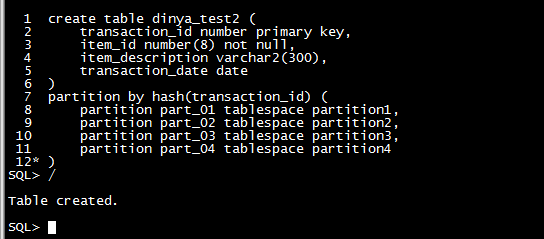
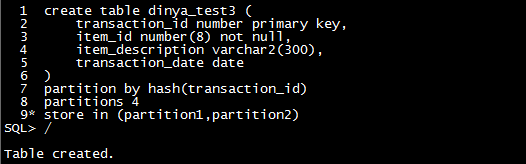
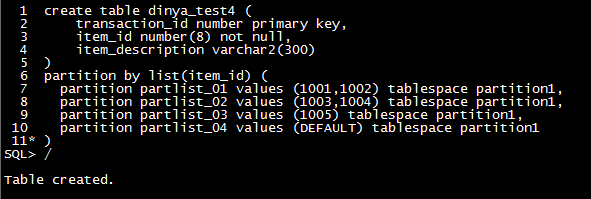
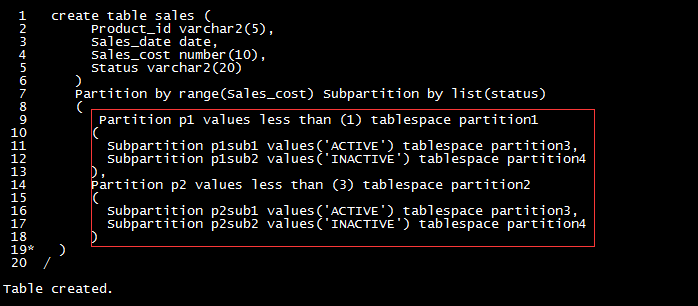
| 分区 |
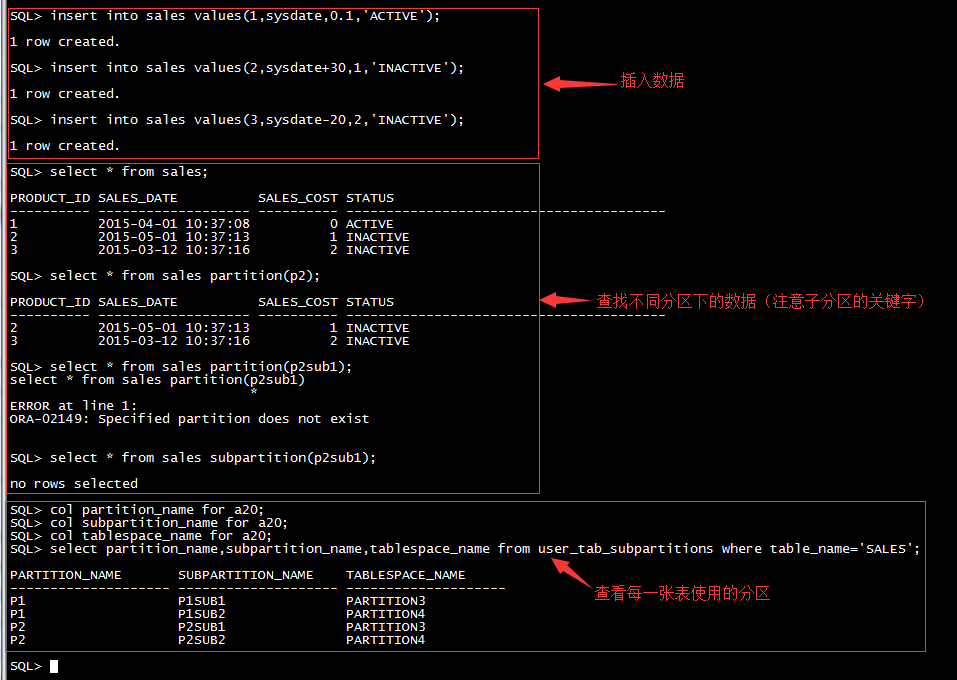
--查询表上有多少分区:SELECT * FROM USER_TAB_PARTITIONS WHERE TABLE_NAME='tableName'
--显示表分区信息 显示数据库所有分区表的详细分区信息:select * from DBA_TAB_PARTITIONS
--显示当前用户可访问的所有分区表的详细分区信息:select * from ALL_TAB_PARTITIONS
--显示当前用户所有分区表的详细分区信息:select * from USER_TAB_PARTITIONS
|
| 子分区 |
--显示子分区信息 显示数据库所有组合分区表的子分区信息:select * from DBA_TAB_SUBPARTITIONS
--显示当前用户可访问的所有组合分区表的子分区信息:select * from ALL_TAB_SUBPARTITIONS
--显示当前用户所有组合分区表的子分区信息:select * from USER_TAB_SUBPARTITIONS
|
| 分区表 |
--显示数据库所有分区表的信息:select * from DBA_PART_TABLES where table_name=upper('dinya_test')
--显示当前用户可访问的所有分区表信息:select * from ALL_PART_TABLES
--显示当前用户所有分区表的信息:select * from USER_PART_TABLES
|
| 分区列 |
--显示分区列 显示数据库所有分区表的分区列信息:select * from DBA_PART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的分区列信息:select * from ALL_PART_KEY_COLUMNS
--显示当前用户所有分区表的分区列信息:select * from USER_PART_KEY_COLUMNS
|
| 子分区列 |
--显示子分区列 显示数据库所有分区表的子分区列信息:select * from DBA_SUBPART_KEY_COLUMNS
--显示当前用户可访问的所有分区表的子分区列信息:select * from ALL_SUBPART_KEY_COLUMNS
--显示当前用户所有分区表的子分区列信息:select * from USER_SUBPART_KEY_COLUMNS
|
| 特例 |
--怎样查询出oracle数据库中所有的的分区表:select * from user_tables a where a.partitioned='YES' |
--删除一个表的数据是
详解Oracle partition分区表的更多相关文章
- [转帖]万字详解Oracle架构、原理、进程,学会世间再无复杂架构
万字详解Oracle架构.原理.进程,学会世间再无复杂架构 http://www.itpub.net/2019/04/24/1694/ 里面的图特别好 数据和云 2019-04-24 09:11:59 ...
- 用一个开发案例详解Oracle临时表
用一个开发案例详解Oracle临时表 2016-11-14 bisal ITPUB  一.开发需求 最近有一个开发需求,大致需要先使用主表,或主表和几张子表关联查询出ID(主键)及一些主表字段 ...
- 详解Oracle手动创建数据库几大步骤
在这里我们将介绍Oracle手动创建数据库几大步骤,包括前期的准备工作,以及具体的实施. Oracle手动创建数据库是本文介绍的重点,希望通过本文能帮助大家更好的利用Oracle.51CTO也向您推荐 ...
- [转帖]详解oracle数据库唯一主键SYS_GUID()
详解oracle数据库唯一主键SYS_GUID() https://www.toutiao.com/i6728736163407856139/ 其实 需要注意 这里满不能截取 因为截取了 就不一定唯一 ...
- [转帖]【Oracle】详解Oracle中NLS_LANG变量的使用
[Oracle]详解Oracle中NLS_LANG变量的使用 https://www.cnblogs.com/HDK2016/p/6880560.html NLS_LANG=LANGUAGE_TERR ...
- 【Oracle】详解ORACLE中的trigger(触发器)
本篇主要内容如下: 8.1 触发器类型 8.1.1 DML触发器 8.1.2 替代触发器 8.1.3 系统触发器 8.2 创建触发器 8.2.1 触发器触发次序 8.2.2 创建DML触发器 8.2. ...
- 【Oracle】详解Oracle中的序列
序列: 是oacle提供的用于产生一系列唯一数字的数据库对象. 自动提供唯一的数值 共享对象 主要用于提供主键值 将序列值装入内存可以提高访问效率 创建序列: 1. 要有创建序列的权限 create ...
- 详解ORACLE数据库的分区表
此文从以下几个方面来整理关于分区表的概念及操作: 1.表空间及分区表的概念 2.表分区的具体作用 3.表分区的优缺点 4.表分区的几种类型及操作方法 5.对表分区的维护性 ...
- 详解Oracle数据货场中三种优化:分区、维度和物化视图
转 xiewmang 新浪博客 本文主要介绍了Oracle数据货场中的三种优化:对分区的优化.维度优化和物化视图的优化,并给出了详细的优化代码,希望对您有所帮助. 我们在做数据库的项目时,对数据货场的 ...
随机推荐
- Struts2 学习
Struts2简介 1.概念:轻量级的MVC框架,主要解决了请求分发的问题,重心在控制层和表现层.低侵入性,与业务代码的耦合度很低.Struts2实现了MVC,并提供了一系列API,采用模式化方式简化 ...
- Fernflower 反编译.class文件
最近有些奇怪Intellij IDEA通过什么查看的源码,通过打开源码意外的发现如下注释 原来是通过Fernflower这个反编译工具w(゚Д゚)w. 使用Fernflower反编译出的代码相当友好, ...
- 家庭记账本之微信小程序(二)
在网上查阅了资料后,了解到了在完成微信小程序之前要完成注册阶段的工作,此次在这介绍注册阶段的流程. 1.首先你要确定小程序的定位.目的以及文案资料等(准备工作). 2.打开微信公众平台官网,点击右上角 ...
- 遇到NotificationService: Suppressing notification from package com.example.dell.servicebestpractice by u错误
一般来说是手机设置没有允许通知
- Chrome调试WebView时Inspect出现空白的解决方法(使用离线包不Fan墙)
起因 使用HTML5开发Android应用时,少不了调试WebView.做前端的还是习惯Chrome的开发者工具,以前都是输入Chrome://inspect就可以调试WebView了,太方便了. 最 ...
- MVC设计思路
MVC 学会重复.学会总结.学会预习和练习 前端页面 <----> 服务器(控制层.业务层.DAO层) <---> DB 说明:无论是框架还是servletJSP,用的 ...
- [c/c++] programming之路(18)、动态分配内存malloc
一.图解堆栈 #include<stdio.h> #include<stdlib.h> #include<Windows.h> void main0(){ **]; ...
- for循环介绍
流程控制之for循环names=['yb','zs','yxd','lb'] i=0 while i < len(names): #4 < 4 print(names[i]) i+=1 # ...
- linux --- 5. nginx 初始
一. 安装nginx 1.安装nginxz之前的依赖包 yum install gcc patch libffi-devel python-devel zlib-devel bzip2-devel o ...
- rm 命令
rm 命令 rm命令可以删除一个目录中的一个或多个文件或目录,也可以将某个目录及其下属的所有文件及其子目录均删除掉.对于链接文件,只是删除整个链接文件,而原有文件保持不变. 语法 rm (选项) (文 ...