Java集合之LinkedHashMap
一、初识LinkedHashMap
上篇文章讲了HashMap。HashMap是一种非常常见、非常有用的集合,但在多线程情况下使用不当会有线程安全问题。
大多数情况下,只要不涉及线程安全问题,Map基本都可以使用HashMap,不过HashMap有一个问题,就是迭代HashMap的顺序并不是HashMap放置的顺序,也就是无序。HashMap的这一缺点往往会带来困扰,因为有些场景,我们期待一个有序的Map。
这个时候,LinkedHashMap就闪亮登场了,它虽然增加了时间和空间上的开销,但是通过维护一个运行于所有条目的双向链表,LinkedHashMap保证了元素迭代的顺序。该迭代顺序可以是插入顺序或者是访问顺序。
二、四个关注点在LinkedHashMap上的答案
| 关 注 点 | 结 论 |
| LinkedHashMap是否允许空 | Key和Value都允许空 |
| LinkedHashMap是否允许重复数据 | Key重复会覆盖、Value允许重复 |
| LinkedHashMap是否有序 | 有序 |
| LinkedHashMap是否线程安全 | 非线程安全 |
三、LinkedHashMap基本结构
关于LinkedHashMap,先提两点:
1、LinkedHashMap可以认为是HashMap+LinkedList,即它既使用HashMap操作数据结构,又使用LinkedList维护插入元素的先后顺序。
2、LinkedHashMap的基本实现思想就是----多态。可以说,理解多态,再去理解LinkedHashMap原理会事半功倍;反之也是,对于LinkedHashMap原理的学习,也可以促进和加深对于多态的理解。
为什么可以这么说,首先看一下,LinkedHashMap的定义:
public class LinkedHashMap<K,V>
extends HashMap<K,V>
implements Map<K,V>
{
...
}
看到,LinkedHashMap是HashMap的子类,自然LinkedHashMap也就继承了HashMap中所有非private的方法。再看一下LinkedHashMap中本身的方法:
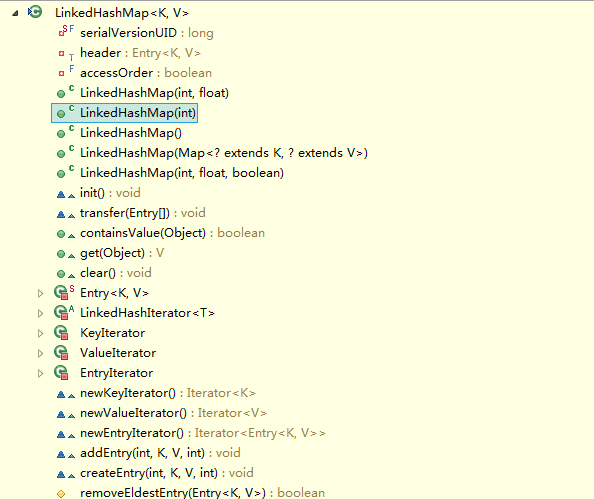
看到LinkedHashMap中并没有什么操作数据结构的方法,也就是说LinkedHashMap操作数据结构(比如put一个数据),和HashMap操作数据的方法完全一样,无非就是细节上有一些的不同罢了。
LinkedHashMap只定义了两个属性:
/**
* The head of the doubly linked list.
* 双向链表的头节点
*/
private transient Entry<K,V> header;
/**
* The iteration ordering method for this linked hash map: true
* for access-order, false for insertion-order.
* true表示最近最少使用次序,false表示插入顺序
*/
private final boolean accessOrder;
LinkedHashMap一共提供了五个构造方法:
// 构造方法1,构造一个指定初始容量和负载因子的、按照插入顺序的LinkedList
public LinkedHashMap(int initialCapacity, float loadFactor) {
super(initialCapacity, loadFactor);
accessOrder = false;
}
// 构造方法2,构造一个指定初始容量的LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap(int initialCapacity) {
super(initialCapacity);
accessOrder = false;
}
// 构造方法3,用默认的初始化容量和负载因子创建一个LinkedHashMap,取得键值对的顺序是插入顺序
public LinkedHashMap() {
super();
accessOrder = false;
}
// 构造方法4,通过传入的map创建一个LinkedHashMap,容量为默认容量(16)和(map.zise()/DEFAULT_LOAD_FACTORY)+1的较大者,装载因子为默认值
public LinkedHashMap(Map<? extends K, ? extends V> m) {
super(m);
accessOrder = false;
}
// 构造方法5,根据指定容量、装载因子和键值对保持顺序创建一个LinkedHashMap
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
从构造方法中可以看出,默认都采用插入顺序来维持取出键值对的次序。所有构造方法都是通过调用父类的构造方法来创建对象的。
LinkedHashMap和HashMap的区别在于它们的基本数据结构上,看一下LinkedHashMap的基本数据结构,也就是Entry:
private static class Entry<K,V> extends HashMap.Entry<K,V> {
// These fields comprise the doubly linked list used for iteration.
Entry<K,V> before, after;
Entry(int hash, K key, V value, HashMap.Entry<K,V> next) {
super(hash, key, value, next);
}
...
}
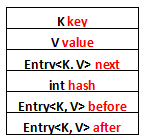
列一下Entry里面有的一些属性吧:
1、K key
2、V value
3、Entry<K, V> next
4、int hash
5、Entry<K, V> before
6、Entry<K, V> after
其中前面四个,也就是红色部分是从HashMap.Entry中继承过来的;后面两个,也就是蓝色部分是LinkedHashMap独有的。不要搞错了next和before、After,next是用于维护HashMap指定table位置上连接的Entry的顺序的,before、After是用于维护Entry插入的先后顺序的。
还是用图表示一下,列一下属性而已:
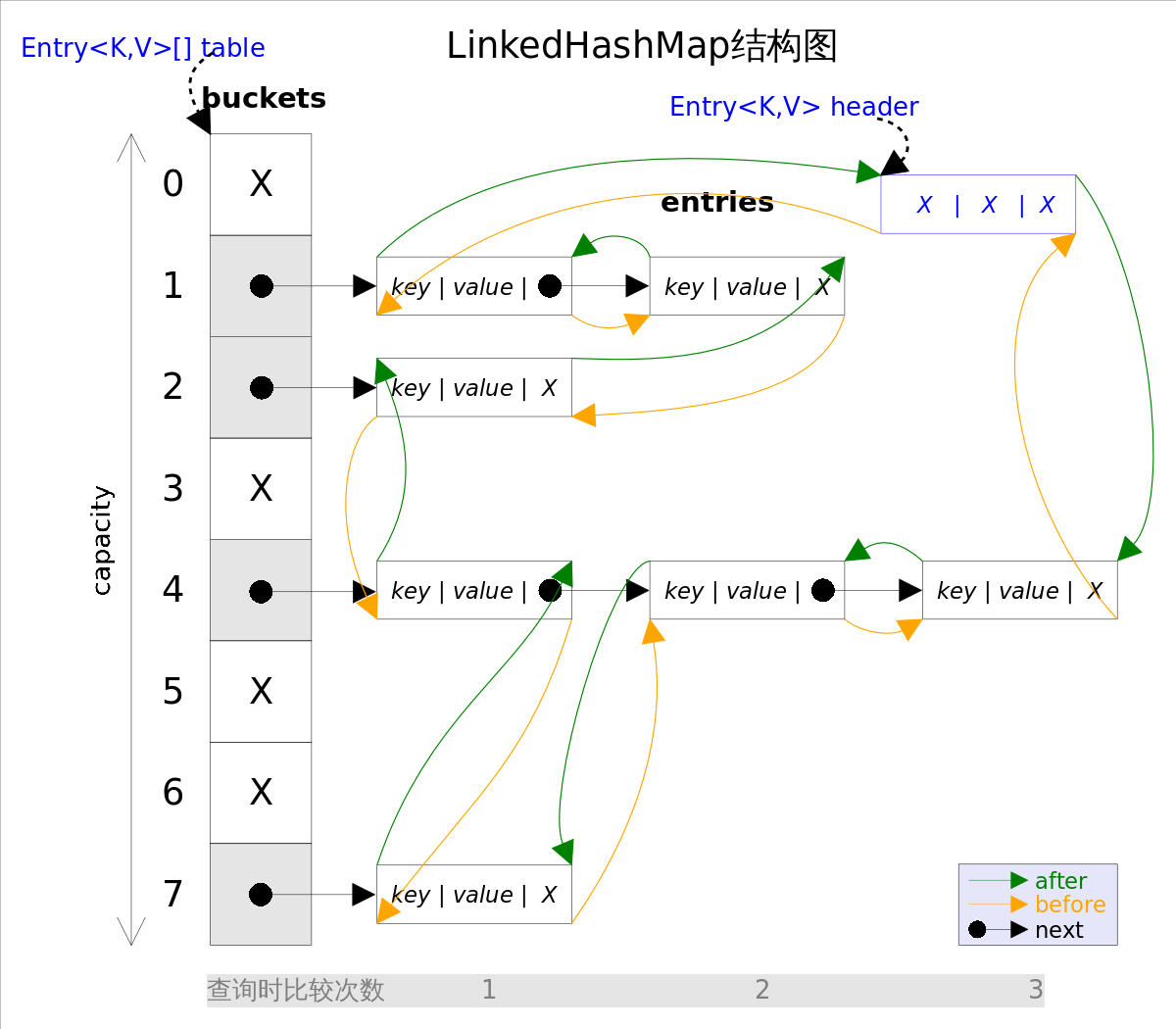
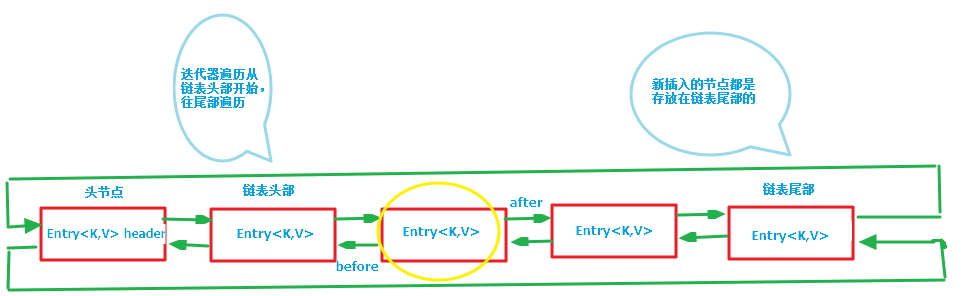
第一张图为LinkedHashMap整体结构图,第二张图专门把循环双向链表抽取出来,直观一点,注意该循环双向链表的头部存放的是最久访问的节点或最先插入的节点,尾部为最近访问的或最近插入的节点,迭代器遍历方向是从链表的头部开始到链表尾部结束,在链表尾部有一个空的header节点,该节点不存放key-value内容,为LinkedHashMap类的成员属性,循环双向链表的入口。
四、初始化LinkedHashMap
假如有这么一段代码:
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>();
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
}
首先是第3行~第4行,new一个LinkedHashMap出来,看一下做了什么:
通过源代码可以看出,在LinkedHashMap的构造方法中,实际调用了父类HashMap的相关构造方法来构造一个底层存放的table数组。
public LinkedHashMap() {
super();
accessOrder = false;
}
public HashMap() {
this.loadFactor = DEFAULT_LOAD_FACTOR;
threshold = (int)(DEFAULT_INITIAL_CAPACITY * DEFAULT_LOAD_FACTOR);
table = new Entry[DEFAULT_INITIAL_CAPACITY];
init();
}
我们已经知道LinkedHashMap的Entry元素继承HashMap的Entry,提供了双向链表的功能。在上述HashMap的构造器中,最后会调用init()方法,进行相关的初始化,这个方法在HashMap的实现中并无意义,只是提供给子类实现相关的初始化调用。
LinkedHashMap重写了init()方法,在调用父类的构造方法完成构造后,进一步实现了对其元素Entry的初始化操作。
void init() {
header = new Entry<K,V>(-1, null, null, null);
header.before = header.after = header;
}
这里出现了第一个多态:init()方法。尽管init()方法定义在HashMap中,但是由于:
1、LinkedHashMap重写了init方法
2、实例化出来的是LinkedHashMap
因此实际调用的init方法是LinkedHashMap重写的init方法。假设header的地址是0x00000000,那么初始化完毕,实际上是这样的:

注意这个header,hash值为-1,其他都为null,也就是说这个header不放在数组中,就是用来指示开始元素和标志结束元素的。
header的目的是为了记录第一个插入的元素是谁,在遍历的时候能够找到第一个元素。
五、LinkedHashMap存储元素
LinkedHashMap并未重写父类HashMap的put方法,而是重写了父类HashMap的put方法调用的子方法void recordAccess(HashMap m) ,void addEntry(int hash, K key, V value, int bucketIndex) 和void createEntry(int hash, K key, V value, int bucketIndex),提供了自己特有的双向链接列表的实现。
继续看LinkedHashMap存储元素,也就是put("111","111")做了什么,首先当然是调用HashMap的put方法:
//这个方法应该挺熟悉的,如果看了HashMap的解析的话
public V put(K key, V value) {
//key为null的情况
if (key == null)
return putForNullKey(value);
//通过key算hash,进而算出在数组中的位置,也就是在第几个桶中
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
//查看桶中是否有相同的key值,如果有就直接用新值替换旧值,而不用再创建新的entry了
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
} modCount++;
//上面度是熟悉的东西,最重要的地方来了,就是这个方法,LinkedHashMap执行到这里,addEntry()方法不会执行HashMap中的方法,
//而是执行自己类中的addEntry方法,
addEntry(hash, key, value, i);
return null;
}
第23行又是一个多态,因为LinkedHashMap重写了addEntry方法,因此addEntry调用的是LinkedHashMap重写了的方法:
void addEntry(int hash, K key, V value, int bucketIndex) {
//调用create方法,将新元素以双向链表的的形式加入到映射中
createEntry(hash, key, value, bucketIndex);
// Remove eldest entry if instructed, else grow capacity if appropriate
// 删除最近最少使用元素的策略定义
Entry<K,V> eldest = header.after;
if (removeEldestEntry(eldest)) {
removeEntryForKey(eldest.key);
} else {
if (size >= threshold)
resize(2 * table.length);
}
}
因为LinkedHashMap由于其本身维护了插入的先后顺序,因此LinkedHashMap可以用来做缓存,第7行~第9行是用来支持FIFO算法的,这里暂时不用去关心它。看一下createEntry方法:
void createEntry(int hash, K key, V value, int bucketIndex) {
HashMap.Entry<K,V> old = table[bucketIndex];
Entry<K,V> e = new Entry<K,V>(hash, key, value, old);
table[bucketIndex] = e;
//将该节点插入到链表尾部
e.addBefore(header);
size++;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
createEntry(int hash,K key,V value,int bucketIndex)方法覆盖了父类HashMap中的方法。这个方法不会拓展table数组的大小。该方法首先保留table中bucketIndex处的节点,然后调用Entry的构造方法(将调用到父类HashMap.Entry的构造方法)添加一个节点,即将当前节点的next引用指向table[bucketIndex] 的节点,之后调用的e.addBefore(header)是修改链表,将e节点添加到header节点之前。
第2行~第4行的代码和HashMap没有什么不同,新添加的元素放在table[i]上,差别在于LinkedHashMap还做了addBefore操作,这四行代码的意思就是让新的Entry和原链表生成一个双向链表。假设字符串111放在位置table[1]上,生成的Entry地址为0x00000001,那么用图表示是这样的:

如果熟悉LinkedList的源码应该不难理解,还是解释一下,注意下existingEntry表示的是header:
1、after=existingEntry,即新增的Entry的after=header地址,即after=0x00000000
2、before=existingEntry.before,即新增的Entry的before是header的before的地址,header的before此时是0x00000000,因此新增的Entry的before=0x00000000
3、before.after=this,新增的Entry的before此时为0x00000000即header,header的after=this,即header的after=0x00000001
4、after.before=this,新增的Entry的after此时为0x00000000即header,header的before=this,即header的before=0x00000001
这样,header与新增的Entry的一个双向链表就形成了。再看,新增了字符串222之后是什么样的,假设新增的Entry的地址为0x00000002,生成到table[2]上,用图表示是这样的:

就不细解释了,只要before、after清除地知道代表的是哪个Entry的就不会有什么问题。
注意,这里的插入有两重含义:
1.从table的角度看,新的entry需要插入到对应的bucket里,当有哈希冲突时,采用头插法将新的entry插入到冲突链表的头部。
2.从header的角度看,新的entry需要插入到双向链表的尾部。
总得来看,再说明一遍,LinkedHashMap的实现就是HashMap+LinkedList的实现方式,以HashMap维护数据结构,以LinkList的方式维护数据插入顺序。
六、LinkedHashMap读取元素
LinkedHashMap重写了父类HashMap的get方法,实际在调用父类getEntry()方法取得查找的元素后,再判断当排序模式accessOrder为true时(即按访问顺序排序),先将当前节点从链表中移除,然后再将当前节点插入到链表尾部。由于的链表的增加、删除操作是常量级的,故并不会带来性能的损失。
/**
* 通过key获取value,与HashMap的区别是:当LinkedHashMap按访问顺序排序的时候,会将访问的当前节点移到链表尾部(头结点的前一个节点)
*/
public V get(Object key) {
// 调用父类HashMap的getEntry()方法,取得要查找的元素。
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
// 记录访问顺序。
e.recordAccess(this);
return e.value;
}
/**
* 在HashMap的put和get方法中,会调用该方法,在HashMap中该方法为空
* 在LinkedHashMap中,当按访问顺序排序时,该方法会将当前节点插入到链表尾部(头结点的前一个节点),否则不做任何事
*/
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
//当LinkedHashMap按访问排序时
if (lm.accessOrder) {
lm.modCount++;
//移除当前节点
remove();
//将当前节点插入到头结点前面
addBefore(lm.header);
}
}
/**
* 移除节点,并修改前后引用
*/
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
七、利用LinkedHashMap实现LRU算法缓存
前面讲了LinkedHashMap添加元素,删除、修改元素就不说了,比较简单,和HashMap+LinkedList的删除、修改元素大同小异,下面讲一个新的内容。
LinkedHashMap可以用来作缓存,比方说LRUCache,看一下这个类的代码,很简单,就十几行而已:
public class LRUCache extends LinkedHashMap
{
public LRUCache(int maxSize)
{
super(maxSize, 0.75F, true);
maxElements = maxSize;
} protected boolean removeEldestEntry(java.util.Map.Entry eldest)
{
return size() > maxElements;
} private static final long serialVersionUID = 1L;
protected int maxElements;
}
顾名思义,LRUCache就是基于LRU算法的Cache(缓存),这个类继承自LinkedHashMap,而类中看到没有什么特别的方法,这说明LRUCache实现缓存LRU功能都是源自LinkedHashMap的。LinkedHashMap可以实现LRU算法的缓存基于两点:
1、LinkedList首先它是一个Map,Map是基于K-V的,和缓存一致
2、LinkedList提供了一个boolean值可以让用户指定是否实现LRU
那么,首先我们了解一下什么是LRU:LRU即Least Recently Used,最近最少使用,也就是说,当缓存满了,会优先淘汰那些最近最不常访问的数据。比方说数据a,1天前访问了;数据b,2天前访问了,缓存满了,优先会淘汰数据b。
我们看一下LinkedList带boolean型参数的构造方法:
public LinkedHashMap(int initialCapacity,
float loadFactor,
boolean accessOrder) {
super(initialCapacity, loadFactor);
this.accessOrder = accessOrder;
}
就是这个accessOrder,它表示:
(1)false,所有的Entry按照插入的顺序排列
(2)true,所有的Entry按照访问的顺序排列
第二点的意思就是,如果有1 2 3这3个Entry,那么访问了1,就把1移到尾部去,即2 3 1。每次访问都把访问的那个数据移到双向队列的尾部去,那么每次要淘汰数据的时候,双向队列最头的那个数据不就是最不常访问的那个数据了吗?换句话说,双向链表最头的那个数据就是要淘汰的数据。
"访问",这个词有两层意思:
1、根据Key拿到Value,也就是get方法
2、修改Key对应的Value,也就是put方法
首先看一下get方法,它在LinkedHashMap中被重写:
public V get(Object key) {
Entry<K,V> e = (Entry<K,V>)getEntry(key);
if (e == null)
return null;
e.recordAccess(this);
return e.value;
}
然后是put方法,沿用父类HashMap的:
public V put(K key, V value) {
if (key == null)
return putForNullKey(value);
int hash = hash(key.hashCode());
int i = indexFor(hash, table.length);
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
addEntry(hash, key, value, i);
return null;
}
修改数据也就是第6行~第14行的代码。看到两端代码都有一个共同点:都调用了recordAccess方法,且这个方法是Entry中的方法,也就是说每次的recordAccess操作的都是某一个固定的Entry。
recordAccess,顾名思义,记录访问,也就是说你这次访问了双向链表,我就把你记录下来,怎么记录?把你访问的Entry移到尾部去。这个方法在HashMap中是一个空方法,就是用来给子类记录访问用的,看一下LinkedHashMap中的实现:
void recordAccess(HashMap<K,V> m) {
LinkedHashMap<K,V> lm = (LinkedHashMap<K,V>)m;
if (lm.accessOrder) {
lm.modCount++;
remove();
addBefore(lm.header);
}
}
private void remove() {
before.after = after;
after.before = before;
}
private void addBefore(Entry<K,V> existingEntry) {
after = existingEntry;
before = existingEntry.before;
before.after = this;
after.before = this;
}
看到每次recordAccess的时候做了两件事情:
1、把待移动的Entry的前后Entry相连
2、把待移动的Entry移动到尾部
当然,这一切都是基于accessOrder=true的情况下。最后用一张图表示一下整个recordAccess的过程吧:

void recordAccess(HashMap<K,V> m) 这个方法就是我们一开始说的,accessOrder为true时,就是使用的访问顺序,访问次数最少到访问次数最多,此时要做特殊处理。处理机制就是访问了一次,就将自己往后移一位,这里就是先将自己删除了,然后在把自己添加,这样,近期访问的少的就在链表的开始,最近访问的元素就会在链表的末尾。如果为false。那么默认就是插入顺序,直接通过链表的特点就能依次找到插入元素,不用做特殊处理。
八、代码演示LinkedHashMap按照访问顺序排序的效果
最后代码演示一下LinkedList按照访问顺序排序的效果,验证一下上一部分LinkedHashMap的LRU功能:
public static void main(String[] args)
{
LinkedHashMap<String, String> linkedHashMap =
new LinkedHashMap<String, String>(16, 0.75f, true);
linkedHashMap.put("111", "111");
linkedHashMap.put("222", "222");
linkedHashMap.put("333", "333");
linkedHashMap.put("444", "444");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.get("111");
loopLinkedHashMap(linkedHashMap);
linkedHashMap.put("222", "2222");
loopLinkedHashMap(linkedHashMap);
} public static void loopLinkedHashMap(LinkedHashMap<String, String> linkedHashMap)
{
Set<Map.Entry<String, String>> set = inkedHashMap.entrySet();
Iterator<Map.Entry<String, String>> iterator = set.iterator(); while (iterator.hasNext())
{
System.out.print(iterator.next() + "\t");
}
System.out.println();
}
注意这里的构造方法要用三个参数那个且最后的要传入true,这样才表示按照访问顺序排序。看一下代码运行结果:
111=111 222=222 333=333 444=444
222=222 333=333 444=444 111=111
333=333 444=444 111=111 222=2222
代码运行结果证明了两点:
1、LinkedList是有序的
2、每次访问一个元素(get或put),被访问的元素都被提到最后面去了
Java集合之LinkedHashMap的更多相关文章
- 死磕 java集合之LinkedHashMap源码分析
欢迎关注我的公众号"彤哥读源码",查看更多源码系列文章, 与彤哥一起畅游源码的海洋. 简介 LinkedHashMap内部维护了一个双向链表,能保证元素按插入的顺序访问,也能以访问 ...
- Java集合之LinkedHashMap源码分析
概述 HashMap是无序的, 即put的顺序与遍历顺序不保证一样. LinkedHashMap是HashMap的一个子类, 它通过重写父类的相关方法, 实现自己的功能. 它保留插入的顺序. 如果需要 ...
- 死磕 java集合之LinkedHashSet源码分析
问题 (1)LinkedHashSet的底层使用什么存储元素? (2)LinkedHashSet与HashSet有什么不同? (3)LinkedHashSet是有序的吗? (4)LinkedHashS ...
- 死磕 java集合之终结篇
概览 我们先来看一看java中所有集合的类关系图. 这里面的类太多了,请放大看,如果放大还看不清,请再放大看,如果还是看不清,请放弃. 我们下面主要分成五个部分来逐个击破. List List中的元素 ...
- Java基础知识强化之集合框架笔记58:Map集合之LinkedHashMap类的概述
1. LinkedHashMap类的概述 LinkedHashMap:Map接口的哈希表(保证唯一性) 和 链接(保证有序性)列表实现,具有可预知的迭代顺序. 2. 代码示例: package cn. ...
- Java集合系列[4]----LinkedHashMap源码分析
这篇文章我们开始分析LinkedHashMap的源码,LinkedHashMap继承了HashMap,也就是说LinkedHashMap是在HashMap的基础上扩展而来的,因此在看LinkedHas ...
- Java集合中的LinkedHashMap类
jdk1.8.0_144 本文阅读最好先了解HashMap底层,可前往<Java集合中的HashMap类>. LinkedHashMap由于它的插入有序特性,也是一种比较常用的Map集合. ...
- Java从入门到放弃18---Map集合/HashMap/LinkedHashMap/TreeMap/集合嵌套/Collections工具类常用方法
Java从入门到放弃18—Map集合/HashMap/LinkedHashMap/TreeMap/集合嵌套/Collections工具类常用方法01 Map集合Map集合处理键值映射关系的数据为了方便 ...
- Java集合系列(四):HashMap、Hashtable、LinkedHashMap、TreeMap的使用方法及区别
本篇博客主要讲解Map接口的4个实现类HashMap.Hashtable.LinkedHashMap.TreeMap的使用方法以及三者之间的区别. 注意:本文中代码使用的JDK版本为1.8.0_191 ...
随机推荐
- 为什么现在我最终推荐内存OLTP
在今年的8月份,我写了篇文章,介绍了我还不推荐用户使用内存OLTP的各个理由.近日很多人告诉我,他们有一些性能的问题,并考虑使用内存OLTP来解决它们. 众所皆知,在SQL Server里内存OLTP ...
- mysql初级命令
修改本地mysql root密码 #mysqladmin -uroot -p原密码 password 现密码 #mysqladmin -uroot -p passwd password nowwd ...
- 一种面向对象的TCP/IP中间件
这是一个使用C++封装的TCP/IP协议栈(仅传输层),属于本人所设计的中间件的一员,具有硬件无关,应用无关特性,使用非常方便,一看代码便知: #include "net.h" / ...
- (转)Dubbo与Zookeeper、SpringMVC整合和使用
原文地址: https://my.oschina.net/zhengweishan/blog/693163 Dubbo与Zookeeper.SpringMVC整合和使用 osc码云托管地址:http: ...
- 给Eclipse提速的7个技巧
这篇文章只是关注如何让Eclipse运行得更快.每个技巧都针对Windows.Linux和MacOS用户详细说明.在使用所有优化技巧之后,Eclipse应该能在10秒内启动,并且比以前运行得更流畅. ...
- python学习7
1.函数作为返回值 eg: 调用执行结果如下: 在函数lazy_sum中又定义了函数sum,并且,内部函数sum可以引用外部函数lazy_sum的参数和局部变量(eg:args),当lazy_sum返 ...
- BZOJ 1061: [Noi2008]志愿者招募
1061: [Noi2008]志愿者招募 Time Limit: 20 Sec Memory Limit: 162 MBSubmit: 4064 Solved: 2476[Submit][Stat ...
- 我的操作系统复习——I/O控制和系统调用
上篇博客介绍了存储器管理的相关知识——我的操作系统复习——存储器管理,本篇讲设备管理中的I/O控制方式和操作系统中的系统调用. 一.I/O控制方式 I/O就是输入输出,I/O设备指的是输入输出设备和存 ...
- [LeetCode] Permutation Sequence 序列排序
The set [1,2,3,…,n] contains a total of n! unique permutations. By listing and labeling all of the p ...
- Javascript的this用法及jQuery中$this和$(this)的区别
this是Javascript语言的一个关键字. 它代表函数运行时,自动生成的一个内部对象,只能在函数内部使用.比如, function test(){ this.x = 1; } 1.this就是全 ...