Spark 实时计算整合案例
1.概述
最近有同学问道,除了使用 Storm 充当实时计算的模型外,还有木有其他的方式来实现实时计算的业务。了解到,在使用 Storm 时,需要编写基于编程语言的代码。比如,要实现一个流水指标的统计,需要去编写相应的业务代码,能不能有一种简便的方式来实现这一需求。在解答了该同学的疑惑后,整理了该实现方案的一个案例,供后面的同学学习参考。
2.内容
实现该方案,整体的流程是不变的,我这里只是替换了其计算模型,将 Storm 替换为 Spark,原先的数据收集,存储依然可以保留。
2.1 Spark Overview
Spark 出来也是很久了,说起它,应该并不会陌生。它是一个开源的类似于 Hadoop MapReduce 的通用并行计算模型,它拥有 Hadoop MapReduce 所具有的有点,但与其不同的是,MapReduce 的 JOB 中间输出结果可以保存在内存中,不再需要回写磁盘,因而,Spark 能更好的适用于需要迭代的业务场景。
2.2 Flow
上面只是对 Spark 进行了一个简要的概述,让大家知道其作用,由于本篇博客的主要内容并不是讲述 Spark 的工作原理和计算方法,多的内容,这里笔者就不再赘述,若是大家想详细了解 Spark 的相关内容,可参考官方文档。[参考地址]
接下来,笔者为大家呈现本案例的一个实现流程图,如下图所示:
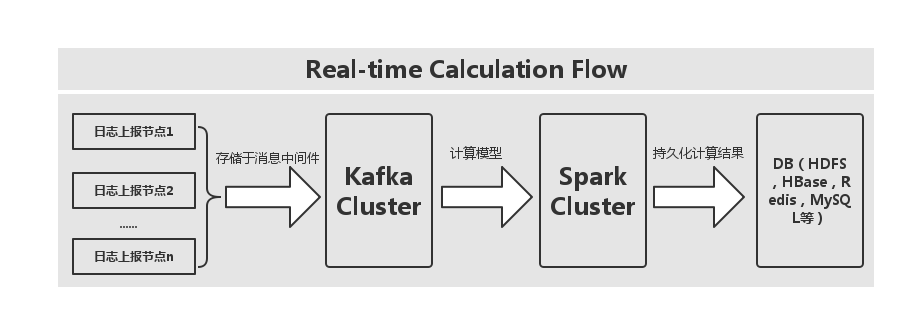
通过上图,我们可以看出,首先是采集上报的日志数据,将其存放于消息中间件,这里消息中间件采用的是 Kafka,然后在使用计算模型按照业务指标实现相应的计算内容,最后是将计算后的结果进行持久化,DB 的选择可以多样化,这里笔者就直接使用了 Redis 来作为演示的存储介质,大家所示在使用中,可以替换该存储介质,比如将结果存放到 HDFS,HBase Cluster,或是 MySQL 等都行。这里,我们使用 Spark SQL 来替换掉 Storm 的业务实现编写。
3.实现
在介绍完上面的内容后,我们接下来就去实现该内容,首先我们要生产数据源,实际的场景下,会有上报好的日志数据,这里,我们就直接写一个模拟数据类,实现代码如下所示:
object KafkaIPLoginProducer {
private val uid = Array("123dfe", "234weq","213ssf")
private val random = new Random()
private var pointer = -1
def getUserID(): String = {
pointer = pointer + 1
if (pointer >= users.length) {
pointer = 0
uid(pointer)
} else {
uid(pointer)
}
}
def plat(): String = {
random.nextInt(10) + "10"
}
def ip(): String = {
random.nextInt(10) + ".12.1.211"
}
def country(): String = {
"中国" + random.nextInt(10)
}
def city(): String = {
"深圳" + random.nextInt(10)
}
def location(): JSONArray = {
JSON.parseArray("[" + random.nextInt(10) + "," + random.nextInt(10) + "]")
}
def main(args: Array[String]): Unit = {
val topic = "test_data3"
val brokers = "dn1:9092,dn2:9092,dn3:9092"
val props = new Properties()
props.put("metadata.broker.list", brokers)
props.put("serializer.class", "kafka.serializer.StringEncoder")
val kafkaConfig = new ProducerConfig(props)
val producer = new Producer[String, String](kafkaConfig)
while (true) {
val event = new JSONObject()
event
.put("_plat", "1001")
.put("_uid", "10001")
.put("_tm", (System.currentTimeMillis / 1000).toString())
.put("ip", ip)
.put("country", country)
.put("city", city)
.put("location", JSON.parseArray("[0,1]"))
println("Message sent: " + event)
producer.send(new KeyedMessage[String, String](topic, event.toString))
event
.put("_plat", "1001")
.put("_uid", "10001")
.put("_tm", (System.currentTimeMillis / 1000).toString())
.put("ip", ip)
.put("country", country)
.put("city", city)
.put("location", JSON.parseArray("[0,1]"))
println("Message sent: " + event)
producer.send(new KeyedMessage[String, String](topic, event.toString))
event
.put("_plat", "1001")
.put("_uid", "10002")
.put("_tm", (System.currentTimeMillis / 1000).toString())
.put("ip", ip)
.put("country", country)
.put("city", city)
.put("location", JSON.parseArray("[0,1]"))
println("Message sent: " + event)
producer.send(new KeyedMessage[String, String](topic, event.toString))
event
.put("_plat", "1002")
.put("_uid", "10001")
.put("_tm", (System.currentTimeMillis / 1000).toString())
.put("ip", ip)
.put("country", country)
.put("city", city)
.put("location", JSON.parseArray("[0,1]"))
println("Message sent: " + event)
producer.send(new KeyedMessage[String, String](topic, event.toString))
Thread.sleep(30000)
}
}
}
上面代码,通过 Thread.sleep() 来控制数据生产的速度。接下来,我们来看看如何实现每个用户在各个区域所分布的情况,它是按照坐标分组,平台和用户ID过滤进行累加次数,逻辑用 SQL 实现较为简单,关键是在实现过程中需要注意的一些问题,比如对象的序列化问题。这里,细节的问题,我们先不讨论,先看下实现的代码,如下所示:
object IPLoginAnalytics {
def main(args: Array[String]): Unit = {
val sdf = new SimpleDateFormat("yyyyMMdd")
var masterUrl = "local[2]"
if (args.length > 0) {
masterUrl = args(0)
}
// Create a StreamingContext with the given master URL
val conf = new SparkConf().setMaster(masterUrl).setAppName("IPLoginCountStat")
val ssc = new StreamingContext(conf, Seconds(5))
// Kafka configurations
val topics = Set("test_data3")
val brokers = "dn1:9092,dn2:9092,dn3:9092"
val kafkaParams = Map[String, String](
"metadata.broker.list" -> brokers, "serializer.class" -> "kafka.serializer.StringEncoder")
val ipLoginHashKey = "mf::ip::login::" + sdf.format(new Date())
// Create a direct stream
val kafkaStream = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topics)
val events = kafkaStream.flatMap(line => {
val data = JSONObject.fromObject(line._2)
Some(data)
})
def func(iter: Iterator[(String, String)]): Unit = {
while (iter.hasNext) {
val item = iter.next()
println(item._1 + "," + item._2)
}
}
events.foreachRDD { rdd =>
// Get the singleton instance of SQLContext
val sqlContext = SQLContextSingleton.getInstance(rdd.sparkContext)
import sqlContext.implicits._
// Convert RDD[String] to DataFrame
val wordsDataFrame = rdd.map(f => Record(f.getString("_plat"), f.getString("_uid"), f.getString("_tm"), f.getString("country"), f.getString("location"))).toDF()
// Register as table
wordsDataFrame.registerTempTable("events")
// Do word count on table using SQL and print it
val wordCountsDataFrame = sqlContext.sql("select location,count(distinct plat,uid) as value from events where from_unixtime(tm,'yyyyMMdd') = '" + sdf.format(new Date()) + "' group by location")
var results = wordCountsDataFrame.collect().iterator
/**
* Internal Redis client for managing Redis connection {@link Jedis} based on {@link RedisPool}
*/
object InternalRedisClient extends Serializable {
@transient private var pool: JedisPool = null
def makePool(redisHost: String, redisPort: Int, redisTimeout: Int,
maxTotal: Int, maxIdle: Int, minIdle: Int): Unit = {
makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle, true, false, 10000)
}
def makePool(redisHost: String, redisPort: Int, redisTimeout: Int,
maxTotal: Int, maxIdle: Int, minIdle: Int, testOnBorrow: Boolean,
testOnReturn: Boolean, maxWaitMillis: Long): Unit = {
if (pool == null) {
val poolConfig = new GenericObjectPoolConfig()
poolConfig.setMaxTotal(maxTotal)
poolConfig.setMaxIdle(maxIdle)
poolConfig.setMinIdle(minIdle)
poolConfig.setTestOnBorrow(testOnBorrow)
poolConfig.setTestOnReturn(testOnReturn)
poolConfig.setMaxWaitMillis(maxWaitMillis)
pool = new JedisPool(poolConfig, redisHost, redisPort, redisTimeout)
val hook = new Thread {
override def run = pool.destroy()
}
sys.addShutdownHook(hook.run)
}
}
def getPool: JedisPool = {
assert(pool != null)
pool
}
}
// Redis configurations
val maxTotal = 10
val maxIdle = 10
val minIdle = 1
val redisHost = "dn1"
val redisPort = 6379
val redisTimeout = 30000
InternalRedisClient.makePool(redisHost, redisPort, redisTimeout, maxTotal, maxIdle, minIdle)
val jedis = InternalRedisClient.getPool.getResource
while (results.hasNext) {
var item = results.next()
var key = item.getString(0)
var value = item.getLong(1)
jedis.hincrBy(ipLoginHashKey, key, value)
}
}
ssc.start()
ssc.awaitTermination()
}
}
/** Case class for converting RDD to DataFrame */
case class Record(plat: String, uid: String, tm: String, country: String, location: String)
/** Lazily instantiated singleton instance of SQLContext */
object SQLContextSingleton {
@transient private var instance: SQLContext = _
def getInstance(sparkContext: SparkContext): SQLContext = {
if (instance == null) {
instance = new SQLContext(sparkContext)
}
instance
}
}
我们在开发环境进行测试的时候,使用 local[k] 部署模式,在本地启动 K 个 Worker 线程来进行计算,而这 K 个 Worker 在同一个 JVM 中,上面的示例,默认使用 local[k] 模式。这里我们需要普及一下 Spark 的架构,架构图来自 Spark 的官网,[链接地址]
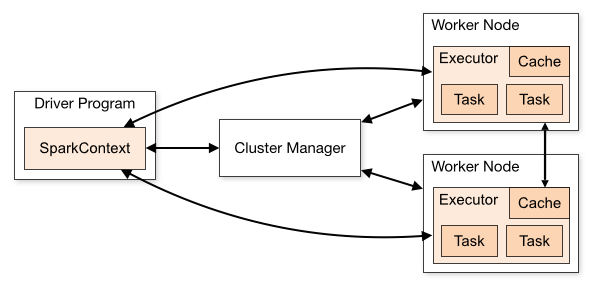
这里,不管是在 local[k] 模式,Standalone 模式,还是 Mesos 或是 YARN 模式,整个 Spark Cluster 的结构都可以用改图来阐述,只是各个组件的运行环境略有不同,从而导致他们可能运行在分布式环境,本地环境,亦或是一个 JVM 实利当中。例如,在 local[k] 模式,上图表示在同一节点上的单个进程上的多个组件,而对于 YARN 模式,驱动程序是在 YARN Cluster 之外的节点上提交 Spark 应用,其他组件都是运行在 YARN Cluster 管理的节点上的。
而对于 Spark Cluster 部署应用后,在进行相关计算的时候会将 RDD 数据集上的函数发送到集群中的 Worker 上的 Executor,然而,这些函数做操作的对象必须是可序列化的。上述代码利用 Scala 的语言特性,解决了这一问题。
4.结果预览
在完成上述代码后,我们执行代码,看看预览结果如下,执行结果,如下所示:
4.1 启动生产线程

4.2 Redis 结果预览

5.总结
整体的实现内容不算太复杂,统计的业务指标,这里我们使用 SQL 来完成这部分工作,对比 Storm 来说,我们专注 SQL 的编写就好,难度不算太大。可操作性较为友好。
6.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
Spark 实时计算整合案例的更多相关文章
- demo2 Kafka+Spark Streaming+Redis实时计算整合实践 foreachRDD输出到redis
基于Spark通用计算平台,可以很好地扩展各种计算类型的应用,尤其是Spark提供了内建的计算库支持,像Spark Streaming.Spark SQL.MLlib.GraphX,这些内建库都提供了 ...
- 【Streaming】30分钟概览Spark Streaming 实时计算
本文主要介绍四个问题: 什么是Spark Streaming实时计算? Spark实时计算原理流程是什么? Spark 2.X下一代实时计算框架Structured Streaming Spark S ...
- Spark实时案例
1.概述 最近有同学问道,除了使用 Storm 充当实时计算的模型外,还有木有其他的方式来实现实时计算的业务.了解到,在使用 Storm 时,需要编写基于编程语言的代码.比如,要实现一个流水指标的统计 ...
- 56、Spark Streaming: transform以及实时黑名单过滤案例实战
一.transform以及实时黑名单过滤案例实战 1.概述 transform操作,应用在DStream上时,可以用于执行任意的RDD到RDD的转换操作.它可以用于实现,DStream API中所没有 ...
- 【转】Spark Streaming 实时计算在甜橙金融监控系统中的应用及优化
系统架构介绍 整个实时监控系统的架构是先由 Flume 收集服务器产生的日志 Log 和前端埋点数据, 然后实时把这些信息发送到 Kafka 分布式发布订阅消息系统,接着由 Spark Streami ...
- Spark Streaming实时计算框架介绍
随着大数据的发展,人们对大数据的处理要求也越来越高,原有的批处理框架MapReduce适合离线计算,却无法满足实时性要求较高的业务,如实时推荐.用户行为分析等. Spark Streaming是建立在 ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- Spark Streaming——Spark第一代实时计算引擎
虽然SparkStreaming已经停止更新,Spark的重点也放到了 Structured Streaming ,但由于Spark版本过低或者其他技术选型问题,可能还是会选择SparkStreami ...
- Spark练习之通过Spark Streaming实时计算wordcount程序
Spark练习之通过Spark Streaming实时计算wordcount程序 Java版本 Scala版本 pom.xml Java版本 import org.apache.spark.Spark ...
随机推荐
- Google的Bigtable学习笔记(不保证正确性)
跪求各路大侠指正:1.首先是一个列式存储的简单数据模型的数据库,它比键值对模型/文档模型NoSQL数据库复杂点(也就更强一点).2.它的分布式存储性能依靠于GFS也就对单机房网络有硬性指标.3.它同时 ...
- Zabbix3.0+CentOS7.0+MariaDB5.5监视服务器安装
本次安装采用: Centos7.0 Zabbix3.0 MariaDB5.5 ------------------- 2012/12/2更新 最新的Centos7.1或者Redhat7.1版本在最后 ...
- 解决JSON.stringify()在IE10下无法使用的问题
今天在IE10下遇到了JSON.stringify()无法使用的问题,错误信息为:'JSON' is undefined . 开始以为是没有添加json2.js引用的原因.后来发现,其他地方也没添加j ...
- [ucgui] 对话框3——GUIBuilder生成界面c文件及修改
>_<" 其实生成GUI有相应的工具:
- JAXB命名空间及命名空间前缀处理
本篇介绍下JAXB进阶使用,命名空间处理 使用package-info.java添加默认命名空间在需要添加命名空间的包下面添加package-info.java文件,然后添加@XmlSchema注解, ...
- Oracle中SQL的分类
DDL 数据定义语言: 用于创建(create).修改(alter)或删除(drop)数据库对象. DML 数据操作语言: 添加(insert into).修改(update)和删除(delete)表 ...
- JQuery官方学习资料(译):使用JQuery的.index()方法
.index()是一个JQuery对象方法,一般用于搜索JQuery对象上一个给定的元素.该方法有四种不同的函数签名,接下来将讲解这四种函数签名的具体用法. 无参数的.index() < ...
- 【Android】进入Material Design时代
由于本文引用了大量官方文档.图片资源,以及开源社区的Lib和相关图片资源,因此在转载的时候,务必注明来源,如果使用资源请注明资源的出处,尊重版权,尊重别人的劳动成果,谢谢! Material Desi ...
- paip.enhes efis 自动获取文件的中文编码
paip.enhes efis 自动获取文件的中文编码 ##为什么需要自动获取文件的中文编码 提高开发效率,自动获取文件的中文编码 .不需要手动设置编码...轻松的.. ##cpdetector 可 ...
- iOS开发-NSURLSession详解
Core Foundation中NSURLConnection在2003年伴随着Safari浏览器的发行,诞生的时间比较久远,iOS升级比较快,AFNetWorking在3.0版本删除了所有基于NSU ...