利用sklearn进行tfidf计算
转自:http://blog.csdn.net/liuxuejiang158blog/article/details/31360765?utm_source=tuicool
在文本处理中,TF-IDF可以说是一个简单粗暴的东西。它可以用作特征抽取,关键词筛选等。

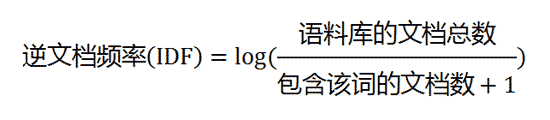
以网页搜索“核能的应用”为例,关键字分成“核能”、“的”、“应用”。根据直觉,我们知道,包含这三个词较多的网页比包含它们较少的网页相关性强。但是仅仅这样,就会有漏洞,那就是文本长的比文本短的关键词数量要多,所以相关性会偏向长文本的网页。所以我们需要归一化,即用比例代替数量。用关键词数除以总的词数,得到我们的“单文本词频(Term Frequency)”最后的TF为各个关键词的TF相加。这样还不够,还是有漏洞。像“的”、“和”等这样的常用字,对衡量相关性没什么作用,但是几乎所有的网页都含有这样的字,所以我们要忽略它们。于是就有了IDF(Inverse Document Frequency)
原理非常简单,结合单词的词频和包含该单词的文档数,统计一下,计算TF和IDF的乘积即可。但是自己的写的代码,在运算速度上,一般不尽人意,在自己写了一段代码之后,为了方便检验结果是否正确、效率如何,在网上寻找了一些开源代码。这里用到了sklearn里面的TF-IDF。主要用到了两个函数:CountVectorizer()和TfidfTransformer()。CountVectorizer是通过fit_transform函数将文本中的词语转换为词频矩阵,矩阵元素weight[i][j] 表示j词在第i个文本下的词频,即各个词语出现的次数;通过get_feature_names()可看到所有文本的关键字,通过toarray()可看到词频矩阵的结果。TfidfTransformer也有个fit_transform函数,它的作用是计算tf-idf值。
贴代码:
#!/usr/bin/python
# -*- coding: utf-8 -*-\
import string
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer if __name__ == "__main__":
corpus = []
tfidfdict = {}
f_res = open('sk_tfidf.txt', 'w')
for line in open('seg.txt', 'r').readlines(): #读取一行语料作为一个文档
corpus.append(line.strip())
vectorizer=CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(corpus))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
word=vectorizer.get_feature_names()#获取词袋模型中的所有词语
weight=tfidf.toarray()#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
for i in range(len(weight)):#打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重
for j in range(len(word)):
getword = word[j]
getvalue = weight[i][j]
if getvalue != 0: #去掉值为0的项
if tfidfdict.has_key(getword): #更新全局TFIDF值
tfidfdict[getword] += string.atof(getvalue)
else:
tfidfdict.update({getword:getvalue})
sorted_tfidf = sorted(tfidfdict.iteritems(),
key=lambda d:d[1], reverse = True )
for i in sorted_tfidf: #写入文件
f_res.write(i[0] + '\t' + str(i[1]) + '\n')
利用sklearn进行tfidf计算的更多相关文章
- 利用sklearn计算文本相似性
利用sklearn计算文本相似性,并将文本之间的相似度矩阵保存到文件当中.这里提取文本TF-IDF特征值进行文本的相似性计算. #!/usr/bin/python # -*- coding: utf- ...
- Python TF-IDF计算100份文档关键词权重
上一篇博文中,我们使用结巴分词对文档进行分词处理,但分词所得结果并不是每个词语都是有意义的(即该词对文档的内容贡献少),那么如何来判断词语对文档的重要度呢,这里介绍一种方法:TF-IDF. 一,TF- ...
- 利用Sklearn实现加州房产价格预测,学习运用机器学习的整个流程(包含很多细节注解)
Chapter1_housing_price_predict .caret, .dropup > .btn > .caret { border-top-color: #000 !impor ...
- 利用编辑距离(Edit Distance)计算两个字符串的相似度
利用编辑距离(Edit Distance)计算两个字符串的相似度 编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数.许可 ...
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- NLP相似度之tf-idf计算
当然,在学习过程中也是参考了很多其他的资料,代码都是一行一行敲出来的. 一.将多个文件合并成一个文件,避免频繁的打开和关闭 import sys for line in sys.stdin: ss = ...
- MeteoInfoLab脚本示例:利用比湿、温度计算相对湿度
利用比湿和温度计算相对湿度的函数是qair2rh(qair, temp, press=1013.25),三个参数分别是比湿.温度和气压,气压有一个缺省值1013.25,因此计算地面相对湿度的时候也可以 ...
- 利用sklearn实现k-means
基于上面的一篇博客k-means利用sklearn实现k-means #!/usr/bin/env python # coding: utf-8 # In[1]: import numpy as np ...
- Hadoop 实现 TF-IDF 计算
学习Hadoop 实现TF-IDF 算法,使用的是CDH5.13.1 VM版本,Hadoop用的是2.6.0的jar包,Maven中增加如下即可 <dependency> <grou ...
随机推荐
- ImageMagick之PDF转换成图片(image)
安装完ImageMagick之后,直接执行“magick convert f:\parseWord\tmp\testpdf.pdf f:\parseWord\tmp\testpdf.jpg”,会报错: ...
- JS settimeout 使用笔记
无参数使用方法: setTimeout(function_name,delay_time); 基本使用方法是逗号前是函数名字,不能带有 xxxx(),不然不执行: 但是很多函数都要带参数的,以下是解决 ...
- SQL递归
递归一般出现在树形结构中 1:根据孩子节点查找所有父节点 With T As ( Select * From U_Companies TB Where CompanyID=80047 Union Al ...
- css之首字母大写 | 全部大写 | 全部小写 | text-transform
div{text-transform:capitalize}首字母大写
- 关于Function.prototype.bind
bind()方法会创建一个新函数,称为绑定函数.当调用这个绑定函数时,绑定函数会以创建它时传入bind()方法的第一个参数作为 this,传入 bind() 方法的第二个以及以后的参数加上绑定函数运行 ...
- Mac系统默认MAWP配置
MAC系统是自带apache的,配置起来也很容易,但是本身是不支持php的需要手动开启一下,这里记录一下配置过程 1.apache配置文件在/etc/apache2/httpd.conf,把Docum ...
- ado.net access oracle dataset via store procedure
使用存储过程返回结果集,并绑定到ado.net对象中在sql server里面是非常直观的. 1: create procedure GetAllRecords 2: as 3: select * f ...
- JS常见问题
语法错误 由于编程语言中的语法比自然语言的语法要严格得多,因此在编写脚本时对细节应倍加关注.例如,如果您本意是将字符串作为某个参数,但是在键入时忘了使用引号引起来,就会产生问题. 脚本解释顺序 对 J ...
- [2015hdu多校联赛补题]hdu5299 Circles Game
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5299 题意: 在欧几里得平面上有n个圆,圆之间不会相交也不会相切,现在Alice和Bob玩游戏,两人轮 ...
- libcurl多线程超时设置不安全(转)
from http://www.cnblogs.com/kex1n/p/4135263.html (1), 超时(timeout) libcurl 是 一个很不错的库,支持http,ftp等很多的协议 ...