C标准库<ctype.h>实现
本文地址:http://www.cnblogs.com/archimedes/p/c-library-ctype.html,转载请注明源地址。
1.背景知识
ctype.h是C标准函数库中的头文件,定义了一批C语言字符分类函数(C character classification functions),用于测试字符是否属于特定的字符类别,如字母字符、控制字符等
我们经常将字符排序并分成不同的类别,为了识别一个字母,可以编写:
if('A' <= c && c <= 'Z' || 'a' <= c && c <= 'z')
......
当执行字符集是ASCII码的时候,可以得到正确的结果,但是这种惯用用法不适合其他字符集
同样,为了判断一个数字,可以这样编写:
if('' <= c && c <= '')
......
判断空白,可以编写代码:
if(c == ' ' || c == '\t' || c == '\n')
......
但是问题来了,我们很快就会厌倦代码中充斥着类似这样的判断语句而变长,最容易联想的解决办法是引入函数来替代这些判断语句,于是将出现如下的代码:
if(isalpha(c))
...
if(isdigit(c))
...
if(isspace(c))
...
貌似问题得到了解决,但是考虑一个典型的文本处理程序对输入流中的每一个字符会平均调用3次这样的函数,就会严重影响程序的执行效率
于是想到进一步的改进,考虑使用宏来替代这些函数,
#define isdigit(x) ((x) >= '0' && (x) <= '9')
这会产生问题,如宏参数x具有副作用;例如,如果调用isdigit(x++)或isdigit(run_some_program()),可能不是很显然,isdigit的参数将被求值两次。早期版本的Linux就使用了这种潜在犯错的方法。关于宏的缺点,本文就不赘述。
为保障安全和代码紧凑,进一步的改进,使用一个或多个转换表的宏集合,每个宏有如下形式:
#define _XXXMASK 0x...
#define isXXX(c) (_Ctytable[c] & _XXXMASK)
字符c编入以_Ctytable命名的转换表索引中,每个表项的不同位以索引字符为特征。如果任何一个和掩码_XXXXMASK相对应的位被设置了,那个字符就要在测试类别中,对所有正确的参数,宏展开成一个紧凑的非零表达式。
这种方法的弊端:当宏的参数不在它的定义域内,就会访问转换表外的存储空间
2.<ctype.h>的内容
<ctype.h>定义的宏如下表所示:
isalnum |
是否为字母数字 |
isalpha |
是否为字母 |
islower |
受否为小写字母 |
isupper |
是否为大写字母 |
isdigit |
是否为数字 |
isxdigit |
是否为16进制数字 |
iscntrl |
是否为控制字符 |
isgraph |
是否为图形字符(例如,空格、控制字符都不是) |
isspace |
是否为空格字符(包括制表符、回车符、换行符等) |
isblank |
是否为空白字符 (C99/C++11新增)(包括水平制表符) |
isprint |
是否为可打印字符 |
ispunct |
是否为标点 |
tolower |
转换为小写 |
toupper |
转换为大写 |
下图来自Plauger和Brodie的Standard C:
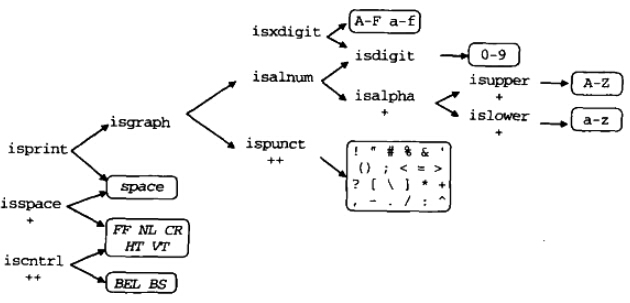
3.<ctype.h>的实现
P.J.Plauger版本C标准库 Ctype 中判断字符是否属于某个类型,主要是通过转换表来实现的
以判断是否为小写字母为例:
/* ctype.h */
#ifndef _CTYPE
#define _CTYPE /* _Ctype 转换位 */
#define _XA 0x200 /* extra alphabetic */
#define _XS 0x100 /* extra space */
#define _BB 0x80 /* BEL, BS, etc. */
#define _CN 0x40 /* CR, FF, HT, NL, VT */
#define _DI 0x20 /* '0' - '9' */
#define _LO 0x10 /* 'a' - 'z' */
#define _PU 0x08 /* punctuation */
#define _SP 0x04 /* space */
#define _UP 0x02 /* 'A' - 'Z' */
#define _XD 0x01 /* '0' - '9', 'A' - 'F', 'a' - 'f' */ /* 声明外部的 _Ctype 转换表 */
extern const short *_Ctype;
/* 判断是否为小写字母的带参数宏 islower */
#define islower(c) (_Ctype[(int)(c)] & _LO) // 其余省略 ...
#endif
_Ctype 转换表:
/* xctype.c _Ctype 转换表 -- ASCII 版 */
#include <limits.h>
#include <stdio.h>
#include "ctype.h"
#if EOF != -1 || UCHAR_MAX != 255
#error WRONG CTYPE table
#endif
/* 组合位 */
#define XDI (_DI|_XD)
#define XLO (_LO|_XD)
#define XUP (_UP|_XD) /* 转换表 */
static const short ctype_tab[] = { , /* EOF */
_BB, _BB, _BB, _BB, _BB, _BB, _BB, _BB,
_BB, _CN, _CN, _CN, _CN, _CN, _BB, _BB,
_BB, _BB, _BB, _BB, _BB, _BB, _BB, _BB,
_BB, _BB, _BB, _BB, _BB, _BB, _BB, _BB,
_SP, _PU, _PU, _PU, _PU, _PU, _PU, _PU,
_PU, _PU, _PU, _PU, _PU, _PU, _PU, _PU,
XDI, XDI, XDI, XDI, XDI, XDI, XDI, XDI,
XDI, XDI, _PU, _PU, _PU, _PU, _PU, _PU,
_PU, XUP, XUP, XUP, XUP, XUP, XUP, _UP,
_UP, _UP, _UP, _UP, _UP, _UP, _UP, _UP,
_UP, _UP, _UP, _UP, _UP, _UP, _UP, _UP,
_UP, _UP, _UP, _PU, _PU, _PU, _PU, _PU,
_PU, XLO, XLO, XLO, XLO, XLO, XLO, _LO,
_LO, _LO, _LO, _LO, _LO, _LO, _LO, _LO,
_LO, _LO, _LO, _LO, _LO, _LO, _LO, _LO,
_LO, _LO, _LO, _PU, _PU, _PU, _PU, _BB,
};
const short *_Ctype = &ctype_tab[];
举一个例子来说明:
当判断‘a’是否为小写字母的时候,使用宏islower,通过宏替换,也即执行(_Ctype[(int)(c)] & _LO)
预处理之后,假设当前的c是'a'那么变成了: (_Ctype[(int)('a')] & _LO)
_Ctype[97]的转换宏是 _LO ,通过查_Ctype 转换表, _LO 的值又是 0x10,所以最后是:
(_LO & _LO) ----> 0x10 & 0x10 ----> 1, 说明当前字符为小写字母
其他的字符的判断都可以通过类似的替换与‘&’得到,不一一赘述。
附上linux内核中的ctype.h实现,基本原理相似
#ifndef _LINUX_CTYPE_H
#define _LINUX_CTYPE_H /*
* NOTE! This ctype does not handle EOF like the standard C
* library is required to.
*/ #define _U 0x01 /* upper */
#define _L 0x02 /* lower */
#define _D 0x04 /* digit */
#define _C 0x08 /* cntrl */
#define _P 0x10 /* punct */
#define _S 0x20 /* white space (space/lf/tab) */
#define _X 0x40 /* hex digit */
#define _SP 0x80 /* hard space (0x20) */ extern const unsigned char _ctype[]; #define __ismask(x) (_ctype[(int)(unsigned char)(x)]) #define isalnum(c) ((__ismask(c)&(_U|_L|_D)) != 0)
#define isalpha(c) ((__ismask(c)&(_U|_L)) != 0)
#define iscntrl(c) ((__ismask(c)&(_C)) != 0)
#define isdigit(c) ((__ismask(c)&(_D)) != 0)
#define isgraph(c) ((__ismask(c)&(_P|_U|_L|_D)) != 0)
#define islower(c) ((__ismask(c)&(_L)) != 0)
#define isprint(c) ((__ismask(c)&(_P|_U|_L|_D|_SP)) != 0)
#define ispunct(c) ((__ismask(c)&(_P)) != 0)
/* Note: isspace() must return false for %NUL-terminator */
#define isspace(c) ((__ismask(c)&(_S)) != 0)
#define isupper(c) ((__ismask(c)&(_U)) != 0)
#define isxdigit(c) ((__ismask(c)&(_D|_X)) != 0) #define isascii(c) (((unsigned char)(c))<=0x7f)
#define toascii(c) (((unsigned char)(c))&0x7f) static inline unsigned char __tolower(unsigned char c)
{
if (isupper(c))
c -= 'A'-'a';
return c;
} static inline unsigned char __toupper(unsigned char c)
{
if (islower(c))
c -= 'a'-'A';
return c;
} #define tolower(c) __tolower(c)
#define toupper(c) __toupper(c) /*
* Fast implementation of tolower() for internal usage. Do not use in your
* code.
*/
static inline char _tolower(const char c)
{
return c | 0x20;
} #endif
ctype.h
/*
* linux/lib/ctype.c
*
* Copyright (C) 1991, 1992 Linus Torvalds
*/ #include <linux/ctype.h>
#include <linux/compiler.h>
#include <linux/export.h> const unsigned char _ctype[] = {
_C,_C,_C,_C,_C,_C,_C,_C, /* 0-7 */
_C,_C|_S,_C|_S,_C|_S,_C|_S,_C|_S,_C,_C, /* 8-15 */
_C,_C,_C,_C,_C,_C,_C,_C, /* 16-23 */
_C,_C,_C,_C,_C,_C,_C,_C, /* 24-31 */
_S|_SP,_P,_P,_P,_P,_P,_P,_P, /* 32-39 */
_P,_P,_P,_P,_P,_P,_P,_P, /* 40-47 */
_D,_D,_D,_D,_D,_D,_D,_D, /* 48-55 */
_D,_D,_P,_P,_P,_P,_P,_P, /* 56-63 */
_P,_U|_X,_U|_X,_U|_X,_U|_X,_U|_X,_U|_X,_U, /* 64-71 */
_U,_U,_U,_U,_U,_U,_U,_U, /* 72-79 */
_U,_U,_U,_U,_U,_U,_U,_U, /* 80-87 */
_U,_U,_U,_P,_P,_P,_P,_P, /* 88-95 */
_P,_L|_X,_L|_X,_L|_X,_L|_X,_L|_X,_L|_X,_L, /* 96-103 */
_L,_L,_L,_L,_L,_L,_L,_L, /* 104-111 */
_L,_L,_L,_L,_L,_L,_L,_L, /* 112-119 */
_L,_L,_L,_P,_P,_P,_P,_C, /* 120-127 */
,,,,,,,,,,,,,,,, /* 128-143 */
,,,,,,,,,,,,,,,, /* 144-159 */
_S|_SP,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P, /* 160-175 */
_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P,_P, /* 176-191 */
_U,_U,_U,_U,_U,_U,_U,_U,_U,_U,_U,_U,_U,_U,_U,_U, /* 192-207 */
_U,_U,_U,_U,_U,_U,_U,_P,_U,_U,_U,_U,_U,_U,_U,_L, /* 208-223 */
_L,_L,_L,_L,_L,_L,_L,_L,_L,_L,_L,_L,_L,_L,_L,_L, /* 224-239 */
_L,_L,_L,_L,_L,_L,_L,_P,_L,_L,_L,_L,_L,_L,_L,_L}; /* 240-255 */ EXPORT_SYMBOL(_ctype);
ctype.c
参考资料
《C标准库》
Plauger和Brodie的《Standard C》
C标准库<ctype.h>实现的更多相关文章
- C 标准库 - ctype.h
C 标准库 - ctype.h This header declares a set of functions to classify and transform individual charact ...
- C 标准库 - ctype.h之iscntrl 使用
iscntrl int iscntrl ( int c ); Check if character is a control character 检查给定字符是否为控制字符,即编码 0x00-0x1F ...
- C 标准库 - ctype.h之isalpha使用
isalpha int isalpha ( int c ); Checks whether c is an alphabetic letter. 检查给定字符是否字母字符,即是大写字母( ABCDEF ...
- C 标准库 - ctype.h之isalnum使用
isalnum int isalnum ( int c ); Checks whether c is either a decimal digit or an uppercase or lowerca ...
- C 标准库 - string.h
C 标准库 - string.h This header file defines several functions to manipulate C strings and arrays. stri ...
- C 标准库 - <assert.h>
C 标准库 - <assert.h> 简介 C 标准库的 assert.h头文件提供了一个名为 assert 的宏,它可用于验证程序做出的假设,并在假设为假时输出诊断消息. 已定义的宏 a ...
- C 标准库 - <stdarg.h>
C 标准库 - <stdarg.h> 简介 stdarg.h 头文件定义了一个变量类型 va_list 和三个宏,这三个宏可用于在参数个数未知(即参数个数可变)时获取函数中的参数. 可变参 ...
- C 标准库 - <signal.h>
C 标准库 - <signal.h> 简介 signal.h 头文件定义了一个变量类型 sig_atomic_t.两个函数调用和一些宏来处理程序执行期间报告的不同信号. 库变量 下面是头文 ...
- C 标准库 - <setjmp.h>
C 标准库 - <setjmp.h> 简介 setjmp.h 头文件定义了宏 setjmp().函数 longjmp() 和变量类型 jmp_buf,该变量类型会绕过正常的函数调用和返回规 ...
随机推荐
- 编译安装GCC 4.7.2
from:http://blog.chinaunix.net/uid-20717979-id-3485672.html 安装gcc需要GMP.MPFR.MPC这三个库,可从ftp://gcc.gnu. ...
- 文本框不够长,显示“XXX...”
WPF: How to make the TextBox/TextBlock/Label show "xxx..." if the text content too long? 设 ...
- MySQL工具汇总
本博客已经迁移至:http://cenalulu.github.io/ 本篇博文已经迁移,阅读全文请点击:http://cenalulu.github.io/mysql/mysql-tools-lis ...
- Transact-SQL 示例 - UPDATE中使用INNER JOIN
一般情况下博主已经对在SELECT语句当中使用INNER JOIN非常娴熟,但在UPDATE当中使用INNER JOIN的场景就为数不多了.以下博主将为你介绍在UPDATE场景当中使用INNER JO ...
- Lo-Dash – 替代 Underscore 的优秀 JS 工具库
前端开发人员大都喜欢 Underscore,它的工具函数很实用,用法简单.这里给大家推荐另外一个功能更全面的 JavaScript 工具——Lo-Dash,帮助你更好的开发网站和 Web 应用程序. ...
- MvvmLight框架使用入门(一)
MvvmLight是比较流行的MVVM框架,相对较为简单易用.可能正因为简单,对应的帮助文档不多,对初学者就不够友好了.这里会用几篇随笔,就个人对MvvmLight的使用经验,来做一个入门的介绍. 第 ...
- mysql: you can't specify target table 问题解决
首先创建一个表: CREATE TABLE `t1` ( `id` ) NULL DEFAULT NULL, `name` ) NULL DEFAULT NULL ) 插入几条数据: mysql> ...
- Scrum 项目1.0 2.0 3.0 4.0 5.0 6.0 7.0
1.确定选题. 应用NABCD模型,分析你们初步选定的项目,充分说明你们选题的理由. 录制为演说视频,上传到视频网站,并把链接发到团队博客上. 截止日期:2016.5.6日晚10点 阅读教材第8章,8 ...
- 重构if...else...或者switch程序块
我们在开发asp.net时,经常有使用if...else...或者是使用switch来进行多个条件判断.如下面这篇<用户控件(UserControl) 使用事件 Ver2>http://w ...
- HTML5表单元素的学习
本文内容 认识表单 基本元素的使用 表单高级元素的使用 现学现卖--创建用户反馈表单 ★ 认识 ...