Hadoop 高可用(HA)的自动容灾配置
参考链接
0. 说明
在 Hadoop 完全分布式安装 & ZooKeeper 集群的安装部署的基础之上进行 Hadoop 高可用(HA)的自动容灾配置
Hadoop 高可用
High Availablility 相当于再配置一台 NameNode
单节点模式容易产生单点故障
冷备份和热备份的区别
热备份:有两个 NameNode 同时工作,其中一台机器处于 active 状态,另一台机器处于 standby 状态。
两个节点数据是即时同步的,起同步作用的进程成为 JournalNode
冷备份:相当于 SecondaryNameNode
1. NameNode & DataNode 多目录配置
0. 关闭集群
stop-all.sh
1. NameNode 多目录配置
目的:用于冗余,存储多个镜像文件副本
# 编辑 hdfs-site.xml
sudo vim /soft/hadoop/etc/hadoop/hdfs-site.xml <property>
<name>dfs.namenode.name.dir</name>
<value>/home/centos/hadoop/dfs/name1,/home/centos/hadoop/dfs/name2</value>
</property>
分发配置文件
xsync.sh /soft/hadoop/etc/hadoop/hdfs-site.xml
重命名 name 文件夹为 name1 ( 在 /home/centos/hadoop/dfs 目录执行以下操作 )
mv name name1
拷贝 name1 文件夹到 name2
cp -r name1 name2
2. DataNode 多目录配置
目的:用于扩容,将所有数据文件存放在不同的磁盘设备上,如 SSD 等等
# 编辑 hdfs-site.xml
sudo vim /soft/hadoop/etc/hadoop/hdfs-site.xml
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/centos/hadoop/dfs/data1,/home/centos/hadoop/dfs/data2</value>
</property>
分发配置文件
xsync.sh /soft/hadoop/etc/hadoop/hdfs-site.xml
重命名 data 文件夹为 data1
xcall.sh mv /home/centos/hadoop/dfs/data /home/centos/hadoop/dfs/data1
启动 HDFS
start-dfs.sh
3. 配置高可用(冷备份)
3.0 拷贝 full 文件夹到 ha
# 复制 Hadoop 配置文件
cp -r /soft/hadoop/etc/full /soft/hadoop/etc/ha # 更改软链接
ln -sfT /soft/hadoop/etc/ha /soft/hadoop/etc/hadoop
3.1 修改 hdfs-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>s105:50090</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/centos/ha/dfs/name1,/home/centos/ha/dfs/name2</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/centos/ha/dfs/data1,/home/centos/ha/dfs/data2</value>
</property> <!-- hdfs高可用配置 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>s101:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>s105:8020</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>s101:50070</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>s105:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://s102:8485;s103:8485;s104:8485/mycluster</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>shell(/bin/true)</value>
</property>
</configuration>
3.2 修改 core-site.xml
<?xml version="1.0"?>
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/home/centos/ha/dfs/journal/node/local/data</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/centos/ha</value>
</property>
</configuration>
3.3 修改 slaves 文件
s102
s103
s104
3.4 配置 s105 的 SSH 免密登陆
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa ssh-copy-id centos@s101
ssh-copy-id centos@s102
ssh-copy-id centos@s103
ssh-copy-id centos@s104
ssh-copy-id centos@s105
3.5 将 s101 的工作目录发送给 s105
删除 s102-s105 的配置文件,不要用 xcall.sh 脚本
ssh s102 rm -rf /soft/hadoop/etc
ssh s103 rm -rf /soft/hadoop/etc
ssh s104 rm -rf /soft/hadoop/etc
ssh s105 rm -rf /soft/hadoop/etc
将 s101 配置文件分发
xsync.sh /soft/hadoop/etc
3.6 启动 JournalNode
hadoop-daemons.sh start journalnode
3.7 格式化 NameNode
hdfs namenode -format
3.8 将 s101 的 ha 目录发送给 s105
scp -r ~/ha centos@s105:~
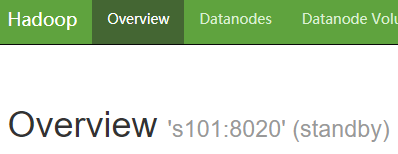
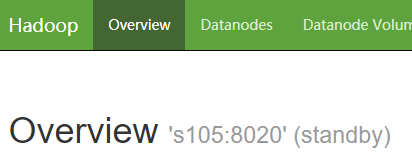
3.9 启动 HDFS ,观察 s101 和 s105 的 NameNode 情况
start-dfs.sh
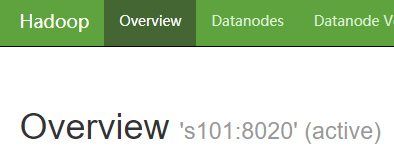
3.10 手动切换 s101 的 NameNode 为 active 状态
hdfs haadmin -transitionToActive nn1
4. 配置高可用(热备份)
4.0 说明
Hadoop 高可用热备份的配置建立在冷备份的配置基础之上
4.1 关闭 Hadoop
stop-all.sh
4.2 启动 s102-s104 的 ZooKeeper
zkServer.sh start
4.3 修改 hdfs-site.xml ,添加以下内容
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
4.4 修改 core-site.xml ,添加以下内容
<property>
<name>ha.zookeeper.quorum</name>
<value>s102:,s103:,s104:</value>
</property>
4.5 分发配置文件
xsync.sh /soft/hadoop/etc/hadoop/hdfs-site.xml
xsync.sh /soft/hadoop/etc/hadoop/core-site.xml
4.6 初始化 ZooKeeper
hdfs zkfc -formatZK
4.7 启动 HDFS
start-dfs.sh
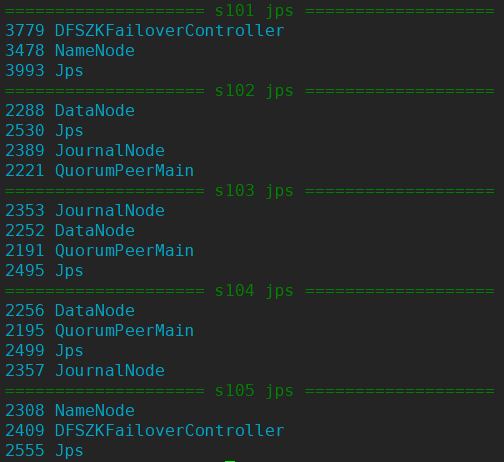
4.8 查看进程
xcall.sh jps
4.9 启动 Zookeeper 命令行脚本 zkCli.sh
zkCli.sh
5. 测试 Hadoop 高可用(HA)的自动容灾
5.0 说明
通过关闭 s101 的 NameNode 进程验证 Hadoop 高可用的自动容灾
5.1 通过 Web 查看 Hadoop 两个节点 s101 、s105 的状态
http://192.168.23.101:50070
http://192.168.23.105:50070


5.2 关闭 s101
已知 s101 的 NameNode 进程 id 为 3478
kill -
5.3 再次查看 Hadoop 两个节点 s101 、s105 的状态
通过 Web 可以看出 s105 的状态为 active ,实现了自动容灾

6. 查看 Hadoop 高可用文件
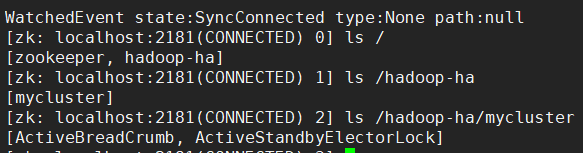
在 s102 启动 ZooKeeper 命令行( zkCli.sh ),再执行以下操作
其中:
- ActiveStandbyElectorLock 是临时结点,负责存储 active 状态下的节点地址
- ActiveBreadCrumb 是永久结点,负责在 ZooKeeper 会话关闭时,下一次启动状态下正确分配 active 节点,避免脑裂(brain-split),即两个 active 节点状态
[zk: localhost:(CONNECTED) ] ls /
[zookeeper, hadoop-ha]
[zk: localhost:(CONNECTED) ] ls /hadoop-ha
[mycluster]
[zk: localhost:(CONNECTED) ] ls /hadoop-ha/mycluster
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: localhost:(CONNECTED) ] get /hadoop-ha/mycluster/ActiveBreadCrumb myclusternn1s101 �>(�>
cZxid = 0x500000008
ctime = Thu Sep :: CST
mZxid = 0x500000016
mtime = Thu Sep :: CST
pZxid = 0x500000008
cversion =
dataVersion =
aclVersion =
ephemeralOwner = 0x0
dataLength =
numChildren =
[zk: localhost:(CONNECTED) ] get /hadoop-ha/mycluster/ActiveStandbyElectorLock myclusternn1s101 �>(�>
cZxid = 0x500000015
ctime = Thu Sep :: CST
mZxid = 0x500000015
mtime = Thu Sep :: CST
pZxid = 0x500000015
cversion =
dataVersion =
aclVersion =
ephemeralOwner = 0x666618cd7c5a0005
dataLength =
numChildren =
Hadoop 高可用(HA)的自动容灾配置的更多相关文章
- 大数据入门第十天——hadoop高可用HA
一.HA概述 1.引言 正式引入HA机制是从hadoop2.0开始,之前的版本中没有HA机制 2.运行机制 实现高可用最关键的是消除单点故障 hadoop-ha严格来说应该分成各个组件的HA机制——H ...
- [大数据] hadoop高可用(HA)部署(未完)
一.HA部署架构 如上图所示,我们可以将其分为三个部分: 1.NN和DN组成Hadoop业务组件.浅绿色部分. 2.中间深蓝色部分,为Journal Node,其为一个集群,用于提供高可用的共享文件存 ...
- hadoop高可用HA的配置
zk3 zk4 zk5 配置hadoop的HA大概可以分为以下几步: 配置zookpeer(namenode之间的通信要靠zk来实现) 配置hadoop的 hadoop-env.sh hdfs-sit ...
- Rancher安装多节点高可用(HA)
Rancher版本:Rancher v1.0.1 基本配置需求 多节点的HA配置请参照单节点需求 节点需要开放的端口 全局访问:TCP 端口22,80,443,18080(可选:用于在集群启动前 查看 ...
- hadoop在zookeeper上的高可用HA
(参考文章:https://www.linuxprobe.com/hadoop-high-available.html) 一.技术背景 影响HDFS集群不可用主要包括以下两种情况:一是NameNode ...
- hadoop学习笔记(七):hadoop2.x的高可用HA(high avaliable)和联邦F(Federation)
Hadoop介绍——HA与联邦 0.1682019.06.04 13:30:55字数 820阅读 138 Hadoop 1.0中HDFS和MapReduce在高可用.扩展性等方面存在问题: –HDFS ...
- centos7搭建hadoop2.10高可用(HA)
本篇介绍在centos7中搭建hadoop2.10高可用集群,首先准备6台机器:2台nn(namenode);4台dn(datanode):3台jns(journalnodes) IP hostnam ...
- HADOOP高可用机制
HADOOP高可用机制 HA运作机制 什么是HA HADOOP如何实现HA HDFS-HA详解 HA集群搭建 目标: 掌握分布式系统中HA机制的思想 掌握HADOOP内置HA的运作机制 掌握HADOO ...
- 【Hadoop】2、Hadoop高可用集群部署
1.服务器设置 集群规划 Namenode-Hadoop管理节点 10.25.24.92 10.25.24.93 Datanode-Hadoop数据存储节点 10.25.24.89 10.25.24. ...
随机推荐
- 腾讯、百度、网易游戏、华为Offer及笔经面经
原文出处:http://bbs.yingjiesheng.com/forum.php?mod=viewthread&tid=1011893&fromuid=1745894 应届生上泡了 ...
- [开源] .NET数据库ORM类库 Insql
介绍 新年之际,给大家介绍个我自己开发的ORM类库Insql.TA是一个轻量级的.NET ORM类库 . 对象映射基于Dapper , Sql配置灵感来自于Mybatis.简单优雅性能是TA的追求. ...
- 几种常见算法的Python实现
1.选择排序 选择排序是一种简单直观的排序算法.它的原理是这样:首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置,然后,再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的后 ...
- Winform下判断文件和文件夹是否存在
//选择文件夹 FolderBrowserDialog dia = new FolderBrowserDialog(); if (dia.ShowDialog() == System.Windows. ...
- Java Service Wrapper--来自官网文件
-----------------------------------------------------------------------------Java Service Wrapper Pr ...
- ActiveMQ demo
Maven 配置文件 <dependency> <groupId>org.apache.activemq</groupId> <artifactId>a ...
- Centos 7 安装后设置
1.宽带连接 终端: nm-connection-editor 添加:DSL 另外一篇:Centos7宽带连接 2.输入法设置 设置-->区域和语言--> + -->搜索chines ...
- ApplicationListener用法
ApplicationListener是spring提供的接口,作用是在web服务器启动时去加载某些程序. 用法: 1.实现ApplicationListener接口,并重写onApplication ...
- 集合框架三(List和Set的补充(不加泛型))
List List存放的元素有序,可重复 List list = new ArrayList(); list.add("123"); list.add("456" ...
- 纯小白入手 vue3.0 CLI - 2.6 - 组件的复用
vue3.0 CLI 真小白一步一步入手全教程系列:https://www.cnblogs.com/ndos/category/1295752.html 我的 github 地址 - vue3.0St ...