图的最短路径-----------SPFA算法详解(TjuOj2831_Wormholes)
这次整理了一下SPFA算法,首先相比Dijkstra算法,SPFA可以处理带有负权变的图。(个人认为原因是SPFA在进行松弛操作时可以对某一条边重复进行松弛,如果存在负权边,在多次松弛某边时可以更新该边。而 Dijkstra 算法如果某一条边松弛后就认为该边已经是该连接点到源点的最短路径了,不会重复检查更新。 Dijkstra只能保证局部最优解而不会保证该解是全局最优解)
实现方法:
建立一个队列,初始时队列里只有起始点,再建立一个表格记录起始点到所有点的最短路径(该表格的初始值要赋为极大值,该点到他本身的路径赋为0)。然后执行松弛操作,用队列里有的点作为起始点去刷新到所有点的最短路,如果刷新成功且被刷新点不在队列中则把该点加入到队列最后。重复执行直到队列为空。
判断有无负环:
如果某个点进入队列的次数超过N次则存在负环(SPFA无法处理带负环的图,但是可以判断是否出现负权环)
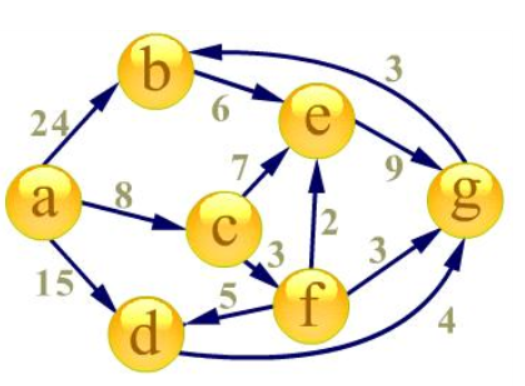
首先建立起始点a到其余各点的
最短路径表格
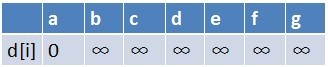
首先源点a入队,当队列非空时:
1、队首元素(a)出队,对以a为起始点的所有边的终点依次进行松弛操作(此处有b,c,d三个点),此时路径表格状态为:
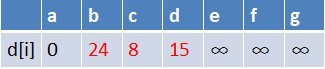
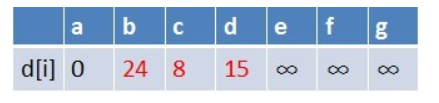
在松弛时三个点的最短路径估值变小了,而这些点队列中都没有出现,这些点
需要入队,此时,队列中新入队了三个结点b,c,d
队首元素b点出队,对以b为起始点的所有边的终点依次进行松弛操作(此处只有e点),此时路径表格状态为:
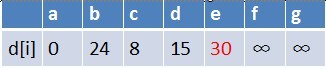
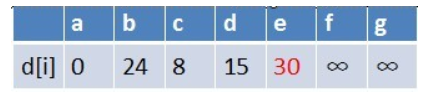
在最短路径表中,e的最短路径估值也变小了,e在队列中不存在,因此e也要
入队,此时队列中的元素为c,d,e
队首元素c点出队,对以c为起始点的所有边的终点依次进行松弛操作(此处有e,f两个点),此时路径表格状态为:
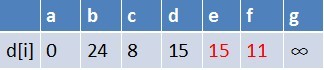
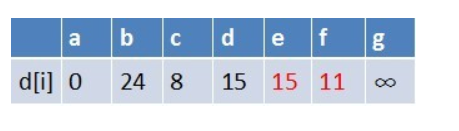
在最短路径表中,e,f的最短路径估值变小了,e在队列中存在,f不存在。因此
e不用入队了,f要入队,此时队列中的元素为d,e,f
队首元素d点出队,对以d为起始点的所有边的终点依次进行松弛操作(此处只有g这个点),此时路径表格状态为:
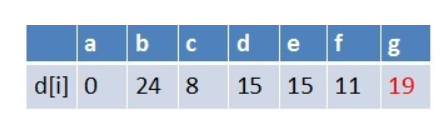
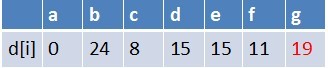
在最短路径表中,g的最短路径估值没有变小(松弛不成功),没有新结点入队,队列中元素为f,g
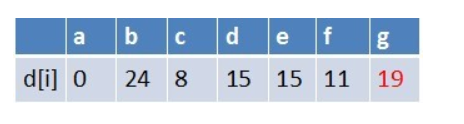
队首元素f点出队,对以f为起始点的所有边的终点依次进行松弛操作(此处有d,e,g三个点),此时路径表格状态为:

在最短路径表中,e,g的最短路径估值又变小,队列中无e点,e入队,队列中存在g这个点,g不用入队,此时队列中元素为g,e
队首元素g点出队,对以g为起始点的所有边的终点依次进行松弛操作(此处只有b点),此时路径表格状态为:
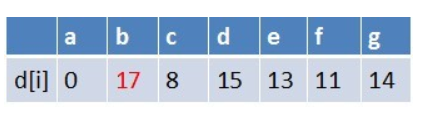
在最短路径表中,b的最短路径估值又变小,队列中无b点,b入队,此时队列中元素为e,b
队首元素e点出队,对以e为起始点的所有边的终点依次进行松弛操作(此处只有g这个点),此时路径表格状态为:
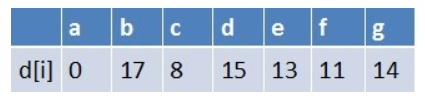
在最短路径表中,g的最短路径估值没变化(松弛不成功),此时队列中元素为b
队首元素b点出队,对以b为起始点的所有边的终点依次进行松弛操作(此处只有e这个点),此时路径表格状态为:
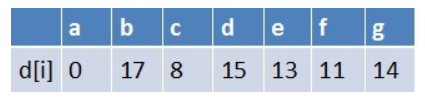
在最短路径表中,e的最短路径估值没变化(松弛不成功),此时队列为空了
最终a到g的最短路径为14
至此,算法结束。
最后,需要注意如果存在负权环的话,那么,队列中永远不可能为空,因为在某次更新时候d[a]会被更新为负值,进而d数组中的每条边都会被循环更新。因为正常每个点入队的次数不会超过总的点数,所以某点入队次数超出总点数则必定出现负权环。利用该性质可以判断是否出现负权环。
该方法在TjuOj2831中的实现如下:
题意是FJ有很多农场,每个农场有很多双向通路,也有单向的虫洞,从通路到达不同农场会花费时间,从虫洞到达不同农场会回到过去的某一个时刻(即权为负),如果有一种方式(环)使得FJ通过某些农场回到原点的同时,时间也回到过去的时刻(发现负权环),那么输出YES,否则NO。
While exploring his many farms, Farmer John has discovered a number of amazing wormholes. A wormhole is very peculiar because it is a one-way path that delivers you to its destination at a time that is BEFORE you entered the wormhole! Each of FJ's farms comprises N (1 ≤ N ≤ 500) fields conveniently numbered 1..N, M (1 ≤ M ≤ 2500) paths, and W (1 ≤ W ≤ 200) wormholes.
As FJ is an avid time-traveling fan, he wants to do the following: start at some field, travel through some paths and wormholes, and return to the starting field a time before his initial departure. Perhaps he will be able to meet himself :) .
To help FJ find out whether this is possible or not, he will supply you with complete maps to F (1 ≤ F ≤ 5) of his farms. No paths will take longer than 10,000 seconds to travel and no wormhole can bring FJ back in time by more than 10,000 seconds.
Input
* Line 1: A single integer, F. F farm descriptions follow.
* Line 1 of each farm: Three space-separated integers respectively: N, M, and W
* Lines 2..M + 1 of each farm: Three space-separated numbers (S, E, T) that describe, respectively: a bidirectional path between S and E that requires T seconds to traverse. Two fields might be connected by more than one path.
* Lines M + 2..M + W + 1 of each farm: Three space-separated numbers (S, E, T) that describe, respectively: A one way path from S to E that also moves the traveler back T seconds.
Output
* Lines 1..F: For each farm, output "YES" if FJ can achieve his goal, otherwise output "NO" (do not include the quotes).
Sample Input
2
3 3 1
1 2 2
1 3 4
2 3 1
3 1 3
3 2 1
1 2 3
2 3 4
3 1 8
Sample Output
NO
YES
Input Details
Two farm maps. The first has three paths and one wormhole, and the second has two paths and one wormhole.
Output Details
For farm 1, FJ cannot travel back in time.
For farm 2, FJ could travel back in time by the cycle 1->2->3->1, arriving back at his starting location 1 second before he leaves. He could start from anywhere on the cycle to accomplish this.
/*
* 2831_Wormholes.cpp
*
* Created on: 2018年11月15日
* Author: Jeason
*/
#include <iostream>
#include <stdio.h>
#include <string.h>
#include <cstring>
#include <vector>
#include <queue>
#define N 1000
using namespace std;
int numPoint,numPath,numHole;
int T,temp,temA,temB,temLength;
int dist[N],num_visited[N]; //dist用于记录搜寻源点到各点的距离,num_visited用于记录每个点入队的次数;
int root; //SPFA的搜寻起点;
queue<int> Q;
struct node
{
int nextPoint;
int length;
};
vector <node> Tree[N]; void readData(){
cin >> numPoint >> numPath >> numHole;
for(int i = ; i < numPath ;i++){
cin >> temA >> temB >> temLength;
node P1,P2;
P1.nextPoint = temB;
P1.length = temLength;
P2.nextPoint = temA;
P2.length = temLength;
Tree[temA].push_back(P1);
Tree[temB].push_back(P2);
root = temA; //找起点;
}
for(int i = ; i < numHole ;i++){
node P;
cin >> temA >> temB >> temLength;
P.nextPoint = temB;
P.length = - temLength;
Tree[temA].push_back(P);
}
} void init()
{
for( int i = ; i < N; i++ )
Tree[i].clear();
memset(num_visited,,sizeof(num_visited));
} int SPFA()
{
while(!Q.empty()){ temp = Q.front();
Q.pop();
// cout << temp << "点出队" << endl;
if(num_visited[temp] > numPoint)
return ; //返回0说明有负权环出现,Q队列一直不为空,死循环
for(int i = ; i < Tree[temp].size(); i++){ //对出队的每个点进行遍历,并进行松弛
if(dist[ Tree[temp][i].nextPoint ] > dist[temp] + Tree[temp][i].length ){
dist[ Tree[temp][i].nextPoint ] = dist[temp] + Tree[temp][i].length;
Q.push(Tree[temp][i].nextPoint);
// cout << Tree[temp][i].nextPoint << " > " << temp << " + " << Tree[temp][i].length << endl;
// cout << "已被松弛:" << temp <<"--->" << Tree[temp][i].nextPoint <<endl;
// cout << Tree[temp][i].nextPoint << "点入队" << endl;
num_visited[Tree[temp][i].nextPoint]++;
}
}
}
return ; //返回1说明SPFA操作成功,没有负权环出现
} int main()
{
cin >> T;
while(T--){
init();
readData(); for(int i = ; i < N;i++)
dist[i] = ;
Q.push(root);
// cout << root << "点入队" << endl;
dist[root] = ;
num_visited[root]++;
if ( SPFA() )
cout << "NO" << endl;
else
cout << "YES" <<endl;
}
return ;
} /* Sample Input
2
3 3 1
1 2 2
1 3 4
2 3 1
3 1 3 3 2 1
1 2 3
2 3 4
3 1 8
Sample Output
NO
YES * */
图的最短路径-----------SPFA算法详解(TjuOj2831_Wormholes)的更多相关文章
- 图的最短路径-----------Dijkstra算法详解(TjuOj2870_The Kth City)
做OJ需要用到搜索最短路径的题,于是整理了一下关于图的搜索算法: 图的搜索大致有三种比较常用的算法: 迪杰斯特拉算法(Dijkstra算法) 弗洛伊德算法(Floyd算法) SPFA算法 Dijkst ...
- 【最短路径Floyd算法详解推导过程】看完这篇,你还能不懂Floyd算法?还不会?
简介 Floyd-Warshall算法(Floyd-Warshall algorithm),是一种利用动态规划的思想寻找给定的加权图中多源点之间最短路径的算法,与Dijkstra算法类似.该算法名称以 ...
- SPFA 算法详解
适用范围:给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了. 我们约定有向加权图G不存在负权回路,即最短路径 ...
- SPFA 算法详解( 强大图解,不会都难!) (转)
适用范围:给定的图存在负权边,这时类似Dijkstra等算法便没有了用武之地,而Bellman-Ford算法的复杂度又过高,SPFA算法便 派上用场了. 我们约定有向加权图G不存在负权回路,即最短路径 ...
- Bellman-Ford算法与SPFA算法详解
PS:如果您只需要Bellman-Ford/SPFA/判负环模板,请到相应的模板部分 上一篇中简单讲解了用于多源最短路的Floyd算法.本篇要介绍的则是用与单源最短路的Bellman-Ford算法和它 ...
- SPFA算法详解
前置知识:Bellman-Ford算法 前排提示:SPFA算法非常容易被卡出翔.所以如果不是图中有负权边,尽量使用Dijkstra!(Dijkstra算法不能能处理负权边,但SPFA能) 前排提示*2 ...
- Bellman-Ford&&SPFA算法详解
Dijkstra在正权图上运行速度很快,但是它不能解决有负权的最短路,如下图: Dijkstra运行的结果是(以1为原点):0 2 12 6 14: 但手算的结果,dist[4]的结果显然是5,为什么 ...
- 八大排序算法详解(动图演示 思路分析 实例代码java 复杂度分析 适用场景)
一.分类 1.内部排序和外部排序 内部排序:待排序记录存放在计算机随机存储器中(说简单点,就是内存)进行的排序过程. 外部排序:待排序记录的数量很大,以致于内存不能一次容纳全部记录,所以在排序过程中需 ...
- BM算法 Boyer-Moore高质量实现代码详解与算法详解
Boyer-Moore高质量实现代码详解与算法详解 鉴于我见到对算法本身分析非常透彻的文章以及实现的非常精巧的文章,所以就转载了,本文的贡献在于将两者结合起来,方便大家了解代码实现! 算法详解转自:h ...
随机推荐
- PAT甲题题解-1072. Gas Station (30)-dijkstra最短路
题意:从m个加油站里面选取1个站点,使得其离住宅的最近距离mindis尽可能地远,并且离所有住宅的距离都在服务范围ds之内.如果有很多相同mindis的加油站,输出距所有住宅平均距离最小的那个.如果平 ...
- PAT甲题题解-1111. Online Map (30)-PAT甲级真题(模板题,两次Dijkstra,同时记下最短路径)
题意:给了图,以及s和t,让你求s到t花费的最短路程.最短时间,以及输出对应的路径. 对于最短路程,如果路程一样,输出时间最少的. 对于最短时间,如果时间一样,输出节点数最少的. 如果最短路程 ...
- 团队作业week9
1. Bug bash ▪ How many bugs is found in your bug bash? 2. Write a blog to talk about your scenario t ...
- 《Linux内核分析》-- 扒开系统调用的三层皮(下)之system_call中断处理过程 20135311傅冬菁
20135311傅冬菁 原创作品 <Linux内核分析>MOOC课程 分析system_call中断处理过程 内容分析与总结: 系统调用在内核代码中的工作机制和初始化 系统调用在用户态中 ...
- We are a 团队
虽然在团队中只是拖后腿的存在,但是几个人一起摸索着前进也确实有着不一样的感觉. 我们队伍共有五个人:董强强.张振鑫.王鼎.高庆阳还有我(排名不分先后) 我们有自己的关于软件工程的QQ群,会在群里讨论一 ...
- 『编程题全队』Alpha 阶段冲刺博客Day8
1.每日站立式会议 1.会议照片 2.昨天已完成的工作统计 孙志威: 1.修复了看板任务框拖拽时候位置不够精确的问题 2.向个人界面下添加了工具栏 3.个人界面下添加了任务框测试 孙慧君: 1.个人任 ...
- Spring之jdbcTemplate:增删改
JdbcTemplate增删改数据操作步骤:1.导入jar包:2.设置数据库信息:3.设置数据源:4.调用jdbcTemplate对象中的方法实现操作 package helloworld.jdbcT ...
- 等价类计数(Polya定理/Burnside引理)学习笔记
参考:刘汝佳<算法竞赛入门经典训练指南> 感觉是非常远古的东西了,几乎从来没有看到过需要用这个的题,还是学一发以防翻车. 置换:排列的一一映射.置换乘法相当于函数复合.满足结合律,不满足交 ...
- MT【105】待定系数算最大最小
已知$x,y,z>0$,则$max\{2x,\frac{1}{y},y+\frac{1}{x}\}$的最小值______ 分析:首先关注到$2x=\frac{1}{y}=y+\frac{1}{x ...
- 【题解】 P1879 玉米田Corn Fields (动态规划,状态压缩)
题目描述 Farmer John has purchased a lush new rectangular pasture composed of M by N (1 ≤ M ≤ 12; 1 ≤ N ...