spark 学习_rdd常用操作
【spark API 函数讲解 详细 】https://www.iteblog.com/archives/1399#reduceByKey
[重要API接口,全面 】 http://spark.apache.org/docs/1.1.1/api/python/pyspark.rdd.RDD-class.html
********
[广播变量】 http://www.csdn.net/article/1970-01-01/2824552
调用广播变量通过:a.value,广播变量可以用在定义的函数的内部。
lt15=sc.broadcast(lt13.collect())
def matrix(p):
temp1=[p[0],p[1]]
for i in lt15.value:
if i in p[2]:
temp1.append(1)
else:
temp1.append(0)
return temp1
spark-submit --master yarn-cluster --executor-memory 5g --num-executors 50 特征工程最终版本.py
#下面这种方法尚未试过
spark-submit --name ${mainClassName} --driver-memory ${driverMemory} --conf spark.akka.frameSize=100
--conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC -XX:+PrintGCDetails -XX:+PrintGCTimeStamps"
--num-executors ${numExecutors} --executor-memory ${executorMemory} --master yarn-cluster ${jarPath}
#提交sql脚本
./bin/spark-sql --master yarn --num-executors 3 --executor-memory 15g --executor-cores 4 -f /home/etl/script/gailunlfile/user_keep_info.sql
0、官方文档:http://spark.apache.org/docs/latest/ml-guide.html
1、http://itindex.net/detail/52732-spark-编程-笔记
spark RDD格式数据集转换:http://blog.csdn.net/chenjieit619/article/details/52861940
对RDD操作的各接口解释: http://www.360doc.com/content/16/0819/12/16883405_584310256.shtml
[Spark与Pandas中DataFrame的详细对比] http://blog.csdn.net/bitcarmanlee/article/details/52002225
1、在hadoop 中输入 pyspark 进入python开发环境;输入spark-shell 进去scala编程环境
2、scala> val r2=sc.textFile("1.txt") 把源数据转换为RDD格式
r2.first() 查看第一条数据
r2.take(5) 查看前5条数据
3、
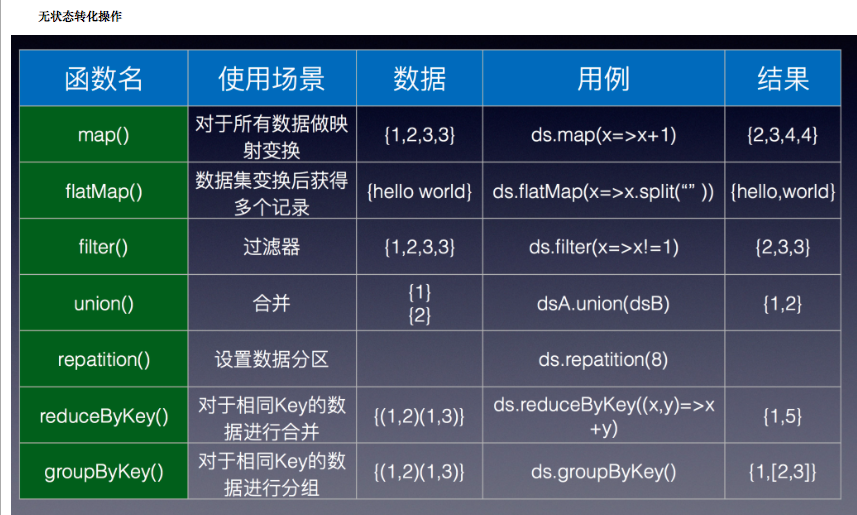
4、spark 从labelPoint数据中筛选出符合标签值得数据组合成新的labelpoint数据
==============================
def parsePoint(line): #把rdd数据转换成Labelpoint 格式数据
values=[float(x) for x in line.split('\t')]
return LabeledPoint(values[0],values[1:])
================================
def filterPoint(p): #筛选labelpoint数据,符合条件的留下,不符合条件的删除,返回一个新的labelpoint数据
if(p.label == 0):
return LabeledPoint(p.label,p.features)
else:
None
===================================
data1=sc.textFile('hdfs://getui-bi-hadoop/user/zhujx/1029_IOS_features_sex')
parsedata=data1.map(parsePoint) #调用函数,将数据转化为LabeledPoint 格式
bb=parsedata.filter(filterPoint) #调用函数,筛选出符合条件的数据,返回的还是labelpoint格式数据,不符合的数据已经被删掉了
数据集bb就可以带入模型了
===================================
抽样语句:
splitdata=parsedata.randomSplit((0.8,0.2))
traindata=splitdata[0]
testdata=splitdata[1]
********************************
下面是在python中对RDD的生成,以及一些基本的Transformation,Action操作。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
|
# -*- coding:utf-8 -*-from pyspark import SparkContext, SparkConffrom pyspark.streaming import StreamingContextimport mathappName ="jhl_spark_1" #你的应用程序名称master= "local"#设置单机conf = SparkConf().setAppName(appName).setMaster(master)#配置SparkContextsc = SparkContext(conf=conf)# parallelize:并行化数据,转化为RDDdata = [1, 2, 3, 4, 5]distData = sc.parallelize(data, numSlices=10) # numSlices为分块数目,根据集群数进行分块# textFile读取外部数据rdd = sc.textFile("./c2.txt") # 以行为单位读取外部文件,并转化为RDDprint rdd.collect()# map:迭代,对数据集中数据进行单独操作def my_add(l): return (l,l)data = [1, 2, 3, 4, 5]distData = sc.parallelize(data) # 并行化数据集result = distData.map(my_add)print (result.collect()) # 返回一个分布数据集# filter:过滤数据def my_add(l): result = False if l > 2: result = True return resultdata = [1, 2, 3, 4, 5]distData = sc.parallelize(data)#并行化数据集,分片result = distData.filter(my_add)print (result.collect())#返回一个分布数据集# zip:将两个RDD对应元素组合为元组x = sc.parallelize(range(0,5))y = sc.parallelize(range(1000, 1005))print x.zip(y).collect()#union 组合两个RDDprint x.union(x).collect()# Aciton操作# collect:返回RDD中的数据rdd = sc.parallelize(range(1, 10))print rddprint rdd.collect()# collectAsMap:以rdd元素为元组,以元组中一个元素作为索引返回RDD中的数据m = sc.parallelize([('a', 2), (3, 4)]).collectAsMap()print m['a']print m[3]# groupby函数:根据提供的方法为RDD分组:rdd = sc.parallelize([1, 1, 2, 3, 5, 8])def fun(i): return i % 2result = rdd.groupBy(fun).collect()print [(x, sorted(y)) for (x, y) in result]# reduce:对数据集进行运算rdd = sc.parallelize(range(1, 10))result = rdd.reduce(lambda a, b: a + b)print result |
除上述以外,对RDD还存在一些常见数据操作如:
name()返回rdd的名称
min()返回rdd中的最小值
sum()叠加rdd中所有元素
take(n)取rdd中前n个元素
count()返回rdd的元素个数
spark 学习_rdd常用操作的更多相关文章
- ubuntu的学习教程(常用操作)
摘要 最近在学习linux,把自己学习过程中遇到的常用操作以及一些有助于理解的内容记录下来.我主要用的是ubuntu系统 命令提示符 '~' 这个是指用户的家目录,用户分为root用户和普通用户,ro ...
- (数据科学学习手札141)利用Learn Git Branching轻松学习git常用操作
1 简介 大家好我是费老师,Git作为世界上最流行的版本控制系统,可以说是每一位与程序打交道的朋友最值得学习的软件之一.除了管理自己的项目,如果你对参与开源项目感兴趣,那么Git更是联结Github. ...
- git学习 本地常用操作01
注意: Microsoft的Word格式是二进制格式,因此,版本控制系统是没法跟踪Word文件的改动 不要使用Windows自带的记事本编辑任何文本文件 开始git项目: 初始化本地项目: 初始化:g ...
- Linux学习之五--常用操作
文件操作: rm命令 删除文件夹实例:rm -rf /var/log/httpd/access将会删除/var/log/httpd/access目录以及其下所有文件.文件夹 2 删除文件使用实例:rm ...
- Spark学习之常用算子介绍
1. reduceByKey reduceByKey的作用对像是(key, value)形式的rdd,而reduce有减少.压缩之意,reduceByKey的作用就是对相同key的数据进行处理,最终每 ...
- Python基础学习----字典常用操作
字典的常见操作: # 字典: # 格式:{键值对,键值对} dict_demo={"name":"bai-boy","age":17} # ...
- Spark学习之键值对操作总结
键值对 RDD 是 Spark 中许多操作所需要的常见数据类型.键值对 RDD 通常用来进行聚合计算.我们一般要先通过一些初始 ETL(抽取.转化.装载)操作来将数据转化为键值对形式.键值对 RDD ...
- c/c++再学习:常用字符串转数字操作
c/c++再学习:常用字符串转数字操作 能实现字符串转数字有三种方法,atof函数,sscanf函数和stringstream类. 具体demo代码和运行结果 #include "stdio ...
- Spark学习之键值对(pair RDD)操作(3)
Spark学习之键值对(pair RDD)操作(3) 1. 我们通常从一个RDD中提取某些字段(如代表事件时间.用户ID或者其他标识符的字段),并使用这些字段为pair RDD操作中的键. 2. 创建 ...
随机推荐
- SQL with(unlock)与with(readpast)
所有Select加 With (NoLock)解决阻塞死锁,在查询语句中使用 NOLOCK 和 READPAST 处理一个数据库死锁的异常时候,其中一个建议就是使用 NOLOCK 或者 READPAS ...
- REST framwork之认证,权限与频率
认证组件 局部视图认证 在app01.service.auth.py: class Authentication(BaseAuthentication): def authenticate(self, ...
- python 之 json 与pickle 模块
序例化:将对象转换为可通过网络传输或可以存储到本地磁盘的数据格式(如:XML.JSON或特定格式的字节串)的过程称为序列化:反之,则称为反序列化. 1.[JSON] import json dic={ ...
- ToList()分组用法...
- Python的字典类型
Python的字典类型为dict,用{}来表示,字典存放键值对数据,每个键值对用:号分隔,每个键值对之间用,号分隔,其基本格式如下: d = {key1 : value1, key2 : value2 ...
- 【Jmeter自学】Jmeter作用域(五)
.Jmeter作用域 .Jmeter参数化 .Jmeter的集合点 .jmeter之关联 1.Jmeter作用域 问题: 每个元件作用域 层次结构确认 每个元件执行顺序 配置元件 前置 定时器 Sam ...
- day6--二分查找法
二分查找法 我们在使用一个列表的时候,往往需要找到一个元素的位置也就是它的索引,按照一般的情况,肯定是一个一个的找过去,元素多了就是一件麻烦事.. 后来就引进了一个概念:二分查找法 它是根据情况将数据 ...
- C#分解质因数
using System; using System.Collections.Generic; using System.Linq; using System.Text; namespace app ...
- [Unity插件]Lua行为树(五):装饰节点Repeater
Repeater:重复执行子节点,直到一定次数 特点如下: 1.执行次数可以是无限循环,也可以是固定次数 2.一般来说,子节点的执行返回状态不会影响Repeater节点,但可以设置当子节点返回失败时, ...
- Eclipse properties.config.yml 配置文件中文编码问题。Eclipse 配置文件插件解决方案
写了中文默认转成unicode. 正常应该是这样子的 其实不是什么大问题只需要装一个插件就行了,插件有很多.推荐使用,Properties Editor 安装方式如下 .这里使用的是离线安装.即本地文 ...