Python之路(第二篇):Python基本数据类型字符串(一)
一、基础
1、编码
UTF-8:中文占3个字节
GBK:中文占2个字节
Unicode、UTF-8、GBK三者关系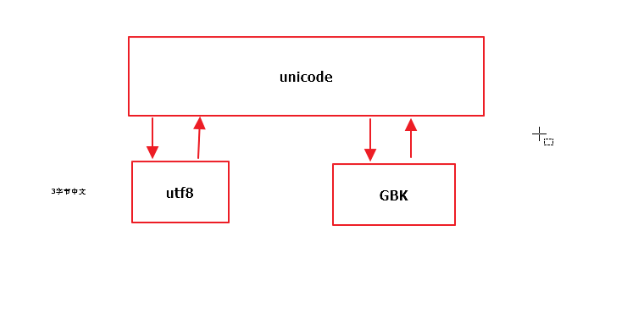
ascii码是只能表示英文字符,用8个字节表示英文,unicode是统一码,世界通用码,规定采用2个字节对世界各地不同文字进行编码,gbk是针对中国汉字提出的编码标准,用2个字节对汉字进行表示。utf8是对unicode的升级改进版,但是unicode到utf-8并不是直接的对应。
UTF-8最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度,当字符在ASCII码的范围时,就用一个字节表示,保留了ASCII字符一个字节的编码做为它的一部分,注意的是unicode一个中文字符占2个字节,而UTF-8一个中文字符占3个字节。
ascii和unicode可以相互转换,gbk和unicode可以相互转换。
2、input()函数
n = input(" ")
>>>hello
>>>n
>>>'hello'
n = input(" ")
>>>10
>>>n
>>>'10'
输入数字10,这里的n是字符串'10',而非数字10
这里如果
n * 10将输出
'10101010101010101010'
如果将字符串转换数字,可以用Int( )
new_n = int(n)
3、while循环、continue、break
while 条件语句1:
功能代码1
else 条件语句2:
功能代码2
while循环也可以加else
例子:使用while循环输入 1 2 3 4 5 6 8 9 10
n = 1
while n < 11:
if n == 7 :
pass
else:
print(n)
n = n + 1
或者
count = 1
while count < 11
if count == 7:
count = count + 1
continue
print(count)
count = count + 1
当while执行到if count ==7时,遇到continue,下面的print语句和count=count + 1不会被执行,重新跳回while语句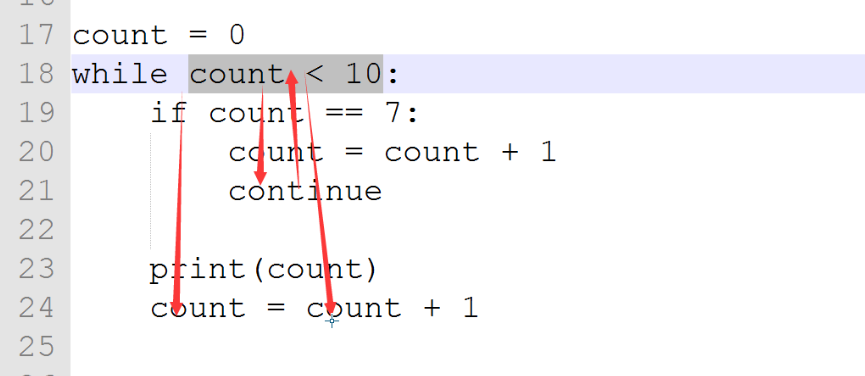
再比如
count = 1
while count < 11:
count = count + 1
continue
print('123')
print('end')
这里的print('123')永远不能被执行到
第二个例子
count = 1
while count < 11:
count = count + 1
print(count)
break
print('123')
print('end')
输出结果
2
end
这里的print('123')也不能被执行到,遇到break语句直接跳出循环,只能执行一次循环,即输出一次print(count)语句
此程序完整执行过程如下图
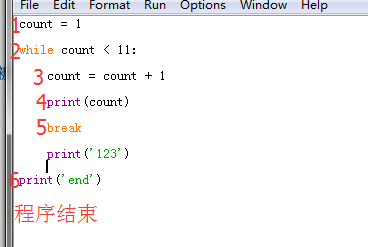
总结:continue终止当前循环进行下次循环,break终止整个循环
4、算术运算符
+ - * / % ** //
加 减 乘 除 取余 乘方 取整数商
5、字符串
name = "马大帅"
if "马" in name :
print("ok")
else:
print("error")
'马大帅' 称为字符串
'马' 成为一个字符
'马大'或者'大帅'称为子字符串,也可以叫做子序列,注意这里的字符要连续的,而'马帅'不能称之为子字符串
6、成员运算:
判断某个字符在某个字符串用in 或者not in
name = "马大帅"
if "吗" not in name :
print("ok")
else:
print("error")
7、布尔值
if语句和while语句都使用布尔值作为条件。
布尔值只有两种情况:
真 True 假 False
if 条件判断语句
功能代码某块
这里的条件判断语句最终会产生一个布尔值,或者是True 或者False
name = "马大帅"
p ="吗" not in name
print(p)
if p:
print("ok")
else:
print("error")
输出结果
True
ok
布尔操作符:and or not
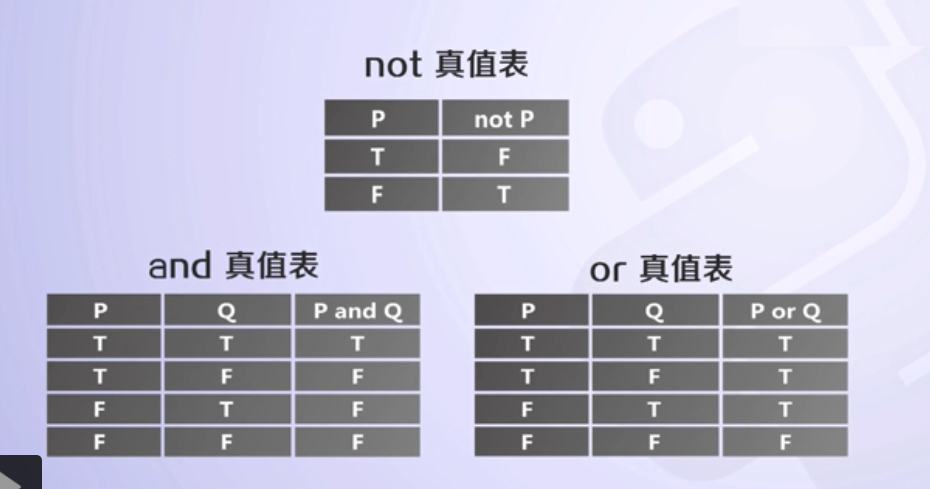
在 Python 看来,只有以下内容会被看作假(注意冒号括号里边啥都没有,连空格都不要有!):False None 0 "" '' () [] {}
其他一切都被解释为真!

举个例子
i = 10
while i:
print ("我爱学习!")
print("end")
输出结果
我爱学习!
我爱学习!
我爱学习!
我爱学习!
我爱学习!
我爱学习!
我爱学习!
我爱学习!
我爱学习!
...(这里代表一直输出"我爱学习")
这个程序会一直输出"我爱学习",除非按下CTRL+C停止执行程序
而print("end")语句永远不会被执行到。
再比如
i = 10
while i:
print ("我爱学习!",i)
i = i -1
print("end")
输出结果
我爱学习! 10
我爱学习! 9
我爱学习! 8
我爱学习! 7
我爱学习! 6
我爱学习! 5
我爱学习! 4
我爱学习! 3
我爱学习! 2
我爱学习! 1
end
通过观察"我爱学习"后的数字变化,我们可以看到,这个循环的执行过程,当i循环到0时 ,即while 0 :,0为False,终止循环。开始执行
print("end")语句。
8、比较运算符:判断大小符号
== 等于
> 大于
< 小于
>= 大于等于
<= 小于等于
!= 不等于
9、运算的优先级
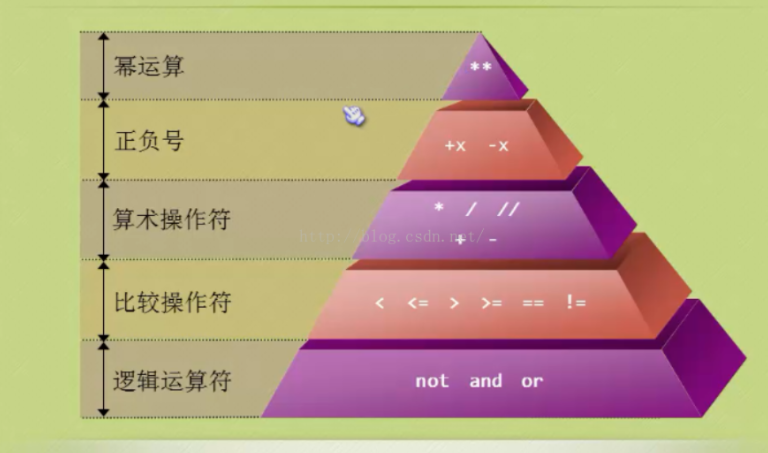
先计算括号内,复杂的表达式推荐使用括号
一般的执行顺序:从左到右
布尔运算优先级
从高到低:not and or
例子:
user = 'nicholas'
psswd ='123'
v = user == 'nicholas' and passwd == '123' or 1 == 2 and pwd == '9876'
print(v)
分析:
v = true and true or
此时不用继续计算即可得出v为真的结果,不用考虑布尔运算的优先级,注意这个运算是从左到右的,**而非看到and自动进行运算而后从左到右运算**
一些结论:
从左到右
(1)第一个表达式 or
True or ————>>得出结果True
(2)第一个表达式 and
True and ————>>继续运算
(3)第一个表达式 or
False or ————>>继续运算
(4)第一个表达式 and
False and ————>>得出结果False
即**短路逻辑**
短路逻辑
表达式从左至右运算,若 or 的左侧逻辑值为 True ,则短路 or 后所有的表达式(不管是 and 还是 or),直接输出
or 左侧表达式 (即True)。
表达式从左至右运算,若 and 的左侧逻辑值为 False ,则短路其后所有 and 表达式,直到有 or 出现,输出 and 左侧表达式到
or 的左侧,参与接下来的逻辑运算。
若 or 的左侧为 False ,或者 and 的左侧为 True 则不能使用短路逻辑。
10、赋值运算符
>= 简单的赋值运算符 c = a + b 将 a + b 的运算结果赋值给c
+= 加法赋值运算符 c += a 等效于 c = c + a
-= 减法赋值运算符 c -= a 等效于 c = c - a
*= 乘法赋值运算符 c *= a 等效于 c = c * a
/= 除法赋值运算符 c /= a 等效于 c = c / a
%= 取模赋值运算符 c %= a 等效于 c = c % a
**= 幂赋值运算符 c **= a 等效于 c = c ** a
//= 取整除赋值运算符 c //= a 等效于 c = c // a
二、基本数据类型
(1)数字 int
a = 1
a = 2
int整型(整数类型)
python3中用int表示,没有范围
python2中int有一定范围
超过一定范围,Python2中有长整型即long
python3中只有整型,用int,取消了long类型
**①**、int()将字符串转换为数字
a = "123"
type(a)
b = int(a)
print(b)
type(b)
输出
<class 'str'>
123
<class 'int'>
type()即可查看变量类型
但是
a = "123n"
b = int(a)
此时是无法用int()转换字符串为数字的。
num = "c"
v = int(num,base = 16)
print(v)
注释: v = int(num,base = 16) 将num以16进制看待,将num转为10进制的数字。这里是可以的。
②bit_lenghth
当前数字的二进制,至少用n位表示
age = 5
r = age.bit_length()
#当前数字的二进制,至少占用了n位表示
print(r)
输出结果
3
即5在二进制中表示为101,至少需要3个位置来表示
(2)字符串 str
a ='hello'
a= 'ssssdda'
字符串方法介绍
a--capitalize()
# capitalize() 首字母大写
test = "lingou"
v1 = test.capitalize( )
print(v1)
输出结果
Lingou
b--casefold( )、lower()
#lower() 所有变小写
# casefold( ) 所有变小写,与lower相比casefold更牛逼,很多未知(不是英文的,如法文、德文等)的对相应变小写
#lower() 方法只对ASCII编码,也就是‘A-Z’有效,对于其他语言(非汉语或英文)中把大写转换为小写的情况只能用 casefold() 方法。
test = "LinGou"
v2 = test.casefold( )
print(v2)
v3 =test.lower()
print(v3)
输出结果
lingou
lingou
c--center( )
#center( ) 设置宽度,并将内容居中,这里的"*"可以不写,默认为空白。
#这里的30是总宽度,单位字节
test = "LinGou"
v4 = test.center(30,"*" )
print(v4)
输出结果
************LinGou************
空白情况
test = "LinGou"
v5 = test.center(30 )
print(v5)
输出结果
LinGou
注:这个输出结果LinGou左右是有空格的
d--count( )
#count( ) 去字符串中寻找,寻找子序列的出现次数
#count(sub[, start[, end]])
#count( 子序列,寻找的开始位置,寻找的结束位置)
#count( sub, start=None, end=None) None默认表示此参数不存在
test = "LinGouLinGengxin"
v6 = test.count("in" )
print(v6)
v7 = test.count("in",3,6)
#这里的3,6 是对字符串"LinGouLinGengxin"的索引编码,从第三个开始到第六个结束
#L i n G o u L i n G e n g x i n
#0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15
print(v7)
v8 = test.count("in",3)#从第3个位置开始找
print(v8)
输出结果
3
0
2
e--endswith()、startswith()
#endswith() 以什么什么结尾
#startswith()以什么什么开始
test = "LinGouLinGengxin"
v9 = test.endswith("in" )
v10 = test.startswith("in")
print(v9)
print(v10)
输出结果
True
False
f--find()、index()
#find()从开始往后找,找到第一个之后,获取其索引位置
#index()功能同上,index找不到,报错,一般建议用find()
test = "LinGouLinGengxin"
v11 = test.find("in" )
v12 = test.find("XING" )
v13 = test.index("in")
# v14 = test.index("XING" )
print(v11)
print(v12)
print(v13)
#print(v14)
输出结果
1
-1
1
取消v14 = test.index("XING" )和print(v14)的注释后运行程序会直接报错
因为index找不到"XING",而find()找不到会返回-1
g--format()
#format()格式化,将一个字符串中的占位符替换为指定的值
# { }就是占位符,通过format将占位符替换为指定的值
test = "I am {name}"
print(test)
v15 = test.format(name = "LinGou" )
print(v15)
输出结果
I am {name}
I am LinGou
-第二个
test = "I am {name},age{a}"
print(test)
v16 = test.format(name = "LinGou",a = 19 )
print(v16)
输出结果
I am {name},age{a}
I am LinGou,age19
-第三个
test = "I am {0},age{1}"
print(test)
v17 = test.format("LinGou",19 )
print(v17)
输出结果
I am {0},age{1}
I am LinGou,age19
当占位符有数字代表,format函数里不再需要具体的name =""
这里是按照先后顺序替换的。
第四个
#format_map()格式化,传入的值
# 书写格式{"name":"LinGou","a":19}
test = "I am {name},age {a}"
print(test)
v18 = test.format_map({"name":"LinGou","a":19} )
v19 = test.format(name = "LinGou",a = "19")
print(v18)
print(v19)
输出结果
I am {name},age {a}
I am LinGou,age 19
I am LinGou,age 19
分析:这里的v18和v19是等价的,只是书写方式不一样。format_map后面加的是字典。
h--isalnum( )
#isalnum( )字符串中是否只包含 字母和数字
test = "LinGou"
v20 = test.isalnum( )
print(v20)
test2 = "LinGou+"
v21 = test2.isalnum( )
print(v21)
输出结果
True
False
Python之路(第二篇):Python基本数据类型字符串(一)的更多相关文章
- python之路第二篇(基础篇)
入门知识: 一.关于作用域: 对于变量的作用域,执行声明并在内存中存在,该变量就可以在下面的代码中使用. if 10 == 10: name = 'allen' print name 以下结论对吗? ...
- Python之路(第九篇)Python文件操作
一.文件的操作 文件句柄 = open('文件路径+文件名', '模式') 例子 f = open("test.txt","r",encoding = “utf ...
- 第二篇 python进阶
目录 第二篇 python进阶 一 数字类型内置方法 二 字符串类型内置方法 三 列表类型内置方法(list) 四 元组类型内置方法(tuple) 五 字典内置方法 六 集合类型内置方法(self) ...
- Python开发【第二篇】:初识Python
Python开发[第二篇]:初识Python Python简介 Python前世今生 python的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏 ...
- [转帖]虚拟内存探究 -- 第二篇:Python 字节
虚拟内存探究 -- 第二篇:Python 字节 http://blog.coderhuo.tech/2017/10/15/Virtual_Memory_python_bytes/ 是真看不懂哦 ...
- Python之路第二天,基础(2)-基本数据类型
一.Python数据类型 数 在Python中有4种类型的数,整数,长整数,浮点数和复数. 2是一个整数的例子 长整数不过是大一点的整数 3.23和52.3E是浮点数的例子.E标记表示10的幂.52. ...
- Python之路(第二十五篇) 面向对象初级:反射、内置方法
[TOC] 一.反射 反射的概念是由Smith在1982年首次提出的,主要是指程序可以访问.检测和修改它本身状态或行为的一种能力(自省).这一概念的提出很快引发了计算机科学领域关于应用反射性的研究.它 ...
- 初学Python——文件操作第二篇
前言:为什么需要第二篇文件操作?因为第一篇的知识根本不足以支撑基本的需求.下面来一一分析. 一.Python文件操作的特点 首先来类比一下,作为高级编程语言的始祖,C语言如何对文件进行操作? 字符(串 ...
- Python开发【第二篇】:Python基础知识
Python基础知识 一.初识基本数据类型 类型: int(整型) 在32位机器上,整数的位数为32位,取值范围为-2**31-2**31-1,即-2147483648-2147483647 在64位 ...
随机推荐
- mui-webview-子页面调用父页面的js方法
子页面// 获取当前webviewvar self = plus.webview.currentWebview();var opener = self.opener();//此句调用父页面jsopen ...
- 检查WMI协议是否通的
在APM上的运行执行“wbemtest”,然后在上面的root\sivm前面加RPC不通的机器,先查WMI协议是否是通的
- python 进阶(转自http://python.jobbole.com/82633/)
网络 通用 urllib -网络库(stdlib). requests -网络库. grab – 网络库(基于pycurl). pycurl – 网络库(绑定libcurl). urllib3 – P ...
- Jenkins+svn+ant+tomcat持续集成
转载自 http://www.cnblogs.com/liuhaixia/p/7267473.html Jenkins是基于Java开发的一种持续集成工具,用于监控秩序重复的工作.通过Jenkins+ ...
- python学习day7 数据类型及内置方法补充
http://www.cnblogs.com/linhaifeng/articles/7133357.html#_label4 1.列表类型 用途:记录多个值(一般存放同属性的值) 定义方法 在[]内 ...
- java面试:HR面
就算技术面全都答对了,有时也会因为HR面没有认真对待而拿不到offer. HR的想法 找工作难,招人也好难.HR想要招什么样的人? 稳定.如果你跳槽频繁,HR可能会担心你干了没一年就跑路了,她又得重新 ...
- vim常用命令之多行注释和多行删除
vim中多行注释和多行删除命令,这些命令也是经常用到的一些小技巧,可以大大提高工作效率. 1.多行注释: 1. 首先按esc进入命令行模式下,按下Ctrl + v,进入列(也叫区块)模式; ...
- http://www.bugku.com:Bugku——PHP伪协议+魔幻函数+序列化的综合应用(http://120.24.86.145:8006/test1/)
这一道题目,幸好俺有基础知识护体,不然还真干不掉. 首先,登录看题目,取消隐藏代码的注释.可知可输入三个参数txt.file和password并进行逻辑判断:应该让txt==‘welcom ...
- ASP.Net MVC 中a标签的onclick时间和href同时存在时候的处理
问题出现: 本次项目在用到下载文件.导出文件的时候,需要在下载.导出之前进行判断,最初使用方式一.二,没能解决问题 方式一:使用href直接跳转controller方法,以下载为例: public A ...
- 项目总结04:SQL批量导入数据:将具有多表关联的Excel数据,通过sql语句脚本的形式,导入到数据库
将具有多表关联的Excel数据,通过sql语句脚本的形式,导入到数据库 写在前面:本文用的语言是java:数据库是MySql: 需求:在实际项目中,经常会被客户要求,做批量导入数据:一般的简单的单表数 ...