Hive知识汇总
两种Hive表
hive存储:数据+元数据
托管表(内部表)
创建表:
hive> create table test2(id int,name String,tel String)
> ROW FORMAT DELIMITED
> FIELDS TERMINATED BY ',';
准备数据文件my.txt
1,scc0,20,131888888888
2,scc1,22,13222222222
3,scc2,21,183938384983
灌数据:
load data local inpath '/usr/local/src/my.txt' into table test2;
查看数据:
hive> select * from test2;
OK
1 scc0 20
2 scc1 22
3 scc2 21
Time taken: 0.132 seconds, Fetched: 3 row(s)
hdfs中的warehouse文件夹下面会多一个文件夹叫做test2。里面的文件名叫做my.txt
删除表:
hive> drop table test2;
OK
Time taken: 0.43 seconds
warehouse文件夹下的test2以及里面的所有文件被删除。内部表删除会同时删除元数据和数据文件。在建表的时候可以指定location,创建的内部表默认是存在warehouse/[tablename],也可以指定目录存放。
create table test2(id int,name String,tel String) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' location '/scc/tmpdir';
外部表
创建表:
多加一个关键词external
create table test3(id int,name String,tel String) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
也可以指定location。默认还是放在warehouse/[tablename]
灌数据方式同上。
查看方式同上。
删除命令同上:
删除后查询:
hive> show tables;
OK
haha
Time taken: 0.034 seconds, Fetched: 1 row(s)
表中已经不再存在test3, 但是HDFS中的目录以及文件均存在。说明外部表在删除的时候仅仅删除了元数据,并未删除存储文件。
分区和桶
表大于分区大于桶
参考此链接
1. 先说分区
在HDFS中,分区的表现为表的子目录。
在创建分区的命令上,分区表现为指定分区partitioned by (partitio-name string)
在查询方式上,分区就相当于表的字段。
创建带分区(以时间time为分区)的表:
create table tbhaspar(id int,name string,tel string) partitioned by(time string) row format delimited fields terminated by ',';
准备数据:
(下面数据中不含time字段,也可以带有time字段,如果按照下面灌数据的方式,带有的time字段的数据会被分区名覆盖掉)
1,scc0,131888888888
2,scc1,13222222222
3,scc2,183938384983
4,scc3,16222232222
5,scc4,17222222222
灌数据:
load data local inpath '/usr/local/src/my.txt' into table tbhaspar partition (time='03-01');
load data local inpath '/usr/local/src/my.txt' into table tbhaspar partition (time='03-02');
load data local inpath '/usr/local/src/my.txt' into table tbhaspar partition (time='03-03');
查询
(创建表的时候指定了3个字段1个分区,接下来的查询结果就好像是看到了4个字段):
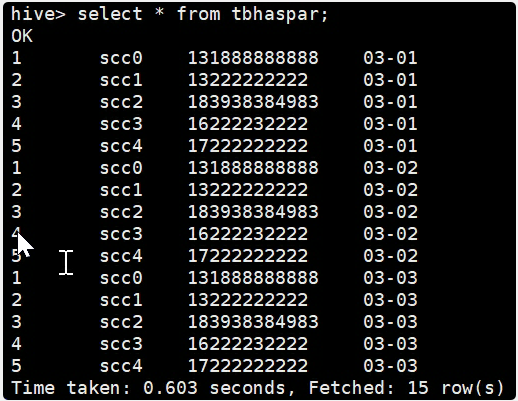
hive> select * from tbhaspar;
OK
1 scc0 131888888888 03-01
2 scc1 13222222222 03-01
3 scc2 183938384983 03-01
4 scc3 16222232222 03-01
5 scc4 17222222222 03-01
1 scc0 131888888888 03-02
2 scc1 13222222222 03-02
3 scc2 183938384983 03-02
4 scc3 16222232222 03-02
5 scc4 17222222222 03-02
1 scc0 131888888888 03-03
2 scc1 13222222222 03-03
3 scc2 183938384983 03-03
4 scc3 16222232222 03-03
5 scc4 17222222222 03-03
Time taken: 0.081 seconds, Fetched: 15 row(s)
查看表信息:
hive> describe tbhaspar;
OK
id int
name string
tel string
time string
# Partition Information
# col_name data_type comment
time string
Time taken: 0.09 seconds, Fetched: 9 row(s)
指定分区查询
(下面的查询方式,好像分区真的是一个字段):
select * from tbhaspar where time = '03-01';
对,上面说的都是
静态分区,下面看看动态分区。
动态分区
可以根据查询得到的数据动态分配到分区里。其实动态分区与静态分区区别就是不指定分区目录,由系统自己选择。
该功能需要手动开启:
hive> set hive.exec.dynamic.partition=true;
- 创建一个跟刚才一样的分区表id,name,tel partition=time
- 灌数据。灌数据的方式只能通过从别的表查询得到,不能直接从local文件加载。我们下面从刚才的静态分区表进行加载(当然我们此时把分区表当成未分区表来用,现实中都是先把数据加载到普通表,然后再读取并加载到动态分区中)。
hive> insert overwrite table tbhasdypar partition(time) select * from tbhaspar;
执行完就开始调MR了。。等一会儿看结果!直接就分区了!很帅!


2. 再说桶
桶是更细粒度的数据范围划分。桶的作用体现之一:MR阶段可以大大减少Join操作(别人这么说的,我不知道)。
Hive采用对列值哈希,然后除以桶的个数求余的方式决定该条记录存放在哪个桶当中。
建一个带桶的表
按照id分成3个桶。
hive> create table buck2 (id int,name string) clustered by (id) sorted by(id) into 3 buckets row format delimited fields terminated by ',' stored as textfile;
灌数据
先看一眼我们要灌的数据
hive> insert overwrite table buck2 select id,name from tbhaspar;
看结果
看结果之前,先设置一下这个:
set mapreduce.job.reduces=4;
为什么?因为分区的效果就是在MapReduce中体现出来的。我们设置多个Reduce观察一下排序结果。

HDFS的buck2下面多了三个文件夹,对应值hash得到的三种余数。
执行:
hive> select * from buck2 ;
下图结果中,正好是三个桶,而且是hash分桶,很明显。
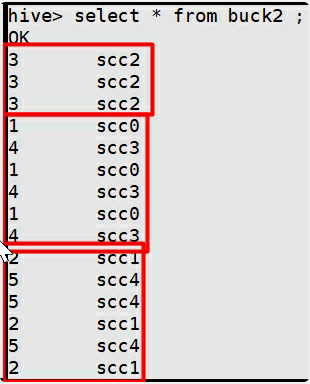
上面是一个无序结果。下面的命令可以查看有序的结果。会在每个reduce里面排序。
hive> select * from buck2 sort by id ;
Hive避免MapReduce
把这个属性设置为true
hive.exec.mode.local.auto=true
hive在运行的时候尝试先使用本地模式运行 否则几乎所有的操作都会触发MR
分区查询-strict严格模式
hive.mapred.mode=strict
上述参数 严格模式下 如果针对分区表的查询,where子句没有添加分区过滤的话,任务禁止提交。
hive.mapred.mode=nonstrict
上述参数 取消严格模式
Hive数据倾斜问题 以及解决思路
MR阶段,Map产生的数据是根据Hash算法生成的key,按key选择合适的reduce,会因为数据特殊性引起的key聚集,造成某些Reduce任务繁重,某些reduce几乎没有任务。
配置参数:
hive.map.aggr=true//Map 端部分聚合,相当于Combiner
hive.groupby.skewindata=true
原理就是:将数据随机分成两个Job,第一个job随机分到不同的reduce,很有可能出现相同的key在不同的reduce里面。第二个Job可以根据预处理的反馈,将key分配到对应的reduce中,基本上同一个key都在一个reduce里面。整体上可以减少数据处理时间,做到负载均衡。
SQL调节:
- 如果两个表都是大表,那么可以对key较少的那部分,可以赋一个随机的key,值为null。倾斜的数据可以分配到不同的reduce上,null值也不会影响最后的结果计算。
- 如果表一大一小(约定1000条记录一下),内存加载较小的表在map端完成redcue操作。
还有其他方法,没使用过,略去不表。
Hive中的order by,sort by,distribute by, cluster by作用以及用法
- order by:在查询的时候sql指定,进行全局排序。不管会有多少个map节点,只会在一个reduce节点内进行处理,所以会很慢。并且,如果手动设置了严格模式,还是必须要指定limit条数的,因为数据量非常大,可能不会出结果。
- sort by:原理类似于归并排序。在每个reduce节点进行排序,做到局部有序,最后进行全局排序的时候就可以提升不少的效率。
- distribute by:都是和sort by 一起使用,并且先于它。作用是将指定的字段值相同的,分配到同一个reduce进行处理。参考这个链接- distribute by和sort by一起使用
- cluster by:是2,3的合并
cluster by id等价于distibute by id sort by id
和3中语句等价的语句:
select mid, money, name from store cluster by mid sort by money
Hive文件存储、压缩格式
- text file
默认设置。建表时会把数据文件拷贝到hdfs上不进行处理。 - sequence file
二进制存储。分割,压缩比较方便。使用<key,value>存储,key是空的。
三种压缩可选,None,Record,Block。Record效率低一些,一般用Block - rc file行列存储 不好用
- orc file 3的升级版。性能很好,存储效率比text file节省很多。
从本地加载数据只用用text file格式。然后才可以通过text file转换成2,3,4的格式。
text file文件可以直接通过cat 查看。而2,3,4的源文件无法直接查看,只能借助表查询才能查看其中的内容。
=====================
我的其他相关文章:
Hive知识汇总的更多相关文章
- Oracle手边常用70则脚本知识汇总
Oracle手边常用70则脚本知识汇总 作者:白宁超 时间:2016年3月4日13:58:36 摘要: 日常使用oracle数据库过程中,常用脚本命令莫不是用户和密码.表空间.多表联合.执行语句等常规 ...
- Oracle 数据库知识汇总篇
Oracle 数据库知识汇总篇(更新中..) 1.安装部署篇 2.管理维护篇 3.数据迁移篇 4.故障处理篇 5.性能调优篇 6.SQL PL/SQL篇 7.考试认证篇 8.原理体系篇 9.架构设计篇 ...
- Vertica 数据库知识汇总篇
Vertica 数据库知识汇总篇(更新中..) 1.Vertica 集群软件部署,各节点硬件性能测试 2.Vertica 创建数据库,创建业务用户测试 3.Vertica 数据库参数调整,资源池分配 ...
- 【转】ACM博弈知识汇总
博弈知识汇总 转自:http://www.cnblogs.com/kuangbin/archive/2011/08/28/2156426.html 有一种很有意思的游戏,就是有物体若干堆,可以是火柴棍 ...
- 最全的jQuery知识汇总
本帖最后由 断天涯大虾 于 2016-12-26 10:22 编辑<ignore_js_op> jQuery是什么? jQuery是javascript编写一个可重用的JavaScript ...
- jquery基础知识汇总
jquery基础知识汇总 一.简介 定义 jQuery创始人是美国John Resig,是优秀的Javascript框架: jQuery是一个轻量级.快速简洁的javaScript库.源码戳这 jQu ...
- ACM博弈知识汇总(转)
博弈知识汇总 有一种很有意思的游戏,就是有物体若干堆,可以是火柴棍或是围棋子等等均可.两个人轮流从堆中取物体若干,规定最后取光物体者取胜.这是我国民间很古老的一个游戏,别看这游戏极其简单,却蕴含着深刻 ...
- [转]【eoeAndroid索引】史上最牛最全android开发知识汇总
一.开发环境搭建 (已完成) 负责人:kris 状态:已完成 所整理标签为:搭建 SDK JDK NDK Eclipse ADT 模拟器 AVD 调试器(DEBUG) DDMS 测试 日志 Logca ...
- AngularJS进阶(十二)AngularJS常用知识汇总(不断更新中....)
AngularJS常用知识汇总(不断更新中....) 注:请点击此处进行充电! app.controller('editCtrl',['$http','$location','$rootScope', ...
随机推荐
- 【bzoj1758】 Wc2010—重建计划
http://www.lydsy.com/JudgeOnline/problem.php?id=1758 (题目链接) 题意 给出一棵树,每条边有边权,问选出一条长度为$[L,U]$的路径,使得路径上 ...
- 【CH4201】楼兰图腾
题目大意:给定一个长度为 N 的序列,从序列中任意挑出三个数,求满足中间的数字值最小(最大)有多少种情况. 题解:建立在值域上的树状数组,从左到右扫描一遍序列,统计出每个点左边有多少个数大于(小于)该 ...
- TensorFlow最佳实践样例
以下代码摘自<Tensor Flow:实战Google深度学习框架> 本套代码是在 http://www.cnblogs.com/shanlizi/p/9033330.html 基础上进行 ...
- Jenkins + Pipeline 构建流水线发布
Jenkins + Pipeline 构建流水线发布 利用Jenkins的Pipeline配置发布流水线 参考: https://jenkins.io/doc/pipeline/tour/depl ...
- CXF wsdl2java 生成java代码供客户端使用
CXF wsdl2java 生成java代码供客户端使用 环境配置:1.下载apache-cxf-2.6.2在环境变量中配置CXF_HOME 值为E:\gavin\cxf\apache-cxf-3.0 ...
- pytho部分命令
python --version查看版本号 pip install XXX 安装模块 pip uninstall XXX 卸载模块
- SQL记录-PLSQL数组
PL/SQL数组 PL/SQL程序设计语言提供叫一种叫做VARRAY的数据结构,其可存储相同类型元素的一个固定大小的连续集合.VARRAY用于存储数据的有序集合,但它往往是更加有用认为数组作为相同类型 ...
- long的变量后面没有L加会有什么后果
不加L的话,默认就是int型了. 当给long赋值一个超过int范围的值的时候,会出问题. java中对字面的数值是以int的形式来表示的 例如:long l= 6553555522222 报错:T ...
- 洛谷P2326 AKN’s PPAP
https://www.luogu.org/problemnew/show/P2326 按位贪心 找到最高位&1的数,确定次高位的时候只从最高位&1的数里选 此次类推 #include ...
- spring中bean配置和注入场景分析
bean与spring容器的关系 Bean配置信息定义了Bean的实现及依赖关系,Spring容器根据各种形式的Bean配置信息在容器内部建立Bean定义注册表,然后根据注册表加载.实例化Bean,并 ...