Selenium 爬取全国水质周报Word
很久没写爬虫了 ,昨天有个学姐说需要爬取水质的一些数据,给了个网站( http://xxfb.hydroinfo.gov.cn/ssIndex.html?type=2&tdsourcetag=s_pctim_aiomsg ),不过 那个网站 出问题了 ,无法加载数据,,,, .不过 爬虫的库都安装了 总不能 啥都不写 ,所以就从另一个网站爬取一些水质周报.
爬虫主要用的库 有:Selenium
一 安装Selenium
Selenium是一系列基于Web的自动化工具,提供一套测试函数,用于支持Web自动化测试。函数非常灵活,能够完成界面元素定位、窗口跳转、结果比较。爬虫过程,需要模拟鼠标点击,快速定位元素,利用 Selenium 可以非常方便的完成. 在控制台中输入 pip install selenium 进行安装.
二分析页面
爬虫最重要的一步是分析 页面内容. 本次爬虫网站为http://www.cnemc.cn/csszzb2093030.jhtml ,观察网站,主界面有一个ul,ul的id 为:contentPageData , 每个ul的li 都有a标签

点击a某个a标签后 ,打开新网页,网页中间就是我们需要下载的内容,单击页面的a标签就可以下载文件。
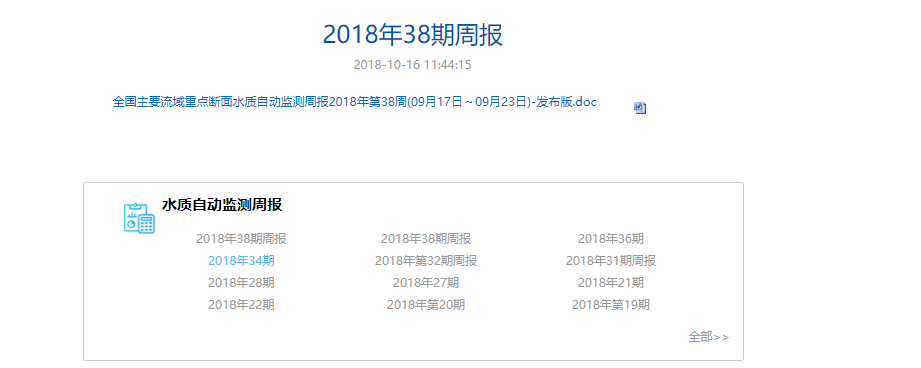
整个 操作非常少 。所以爬虫非常容易 。 主要步骤是:
1 进入主页面 http://www.cnemc.cn/csszzb2093030.jhtml,在输入框输入需要爬取的某一页。,点击跳转即到需要爬取的一页
2 获取该页面所有符合要求的a标签
3 根据a标签地址,进入下载页 ,找到需要下载文件的a 标签 最后实现点击就可以完成。
在之前 ,必须进行浏览器下载设置 。
- options = webdriver.ChromeOptions()
- # 设置中文
- options.add_argument('lang=zh_CN.UTF-8')
- options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"')
- prefs = {"download.default_directory": "地址"}
- options.add_experimental_option("prefs", prefs)
- driver = webdriver.Chrome(chrome_options=options)
爬虫过程中 ,需要注意 ,在进行页面跳转后,需要让程序休息几秒,确保浏览器已经完成跳转。
- #! /usr/bin/env python
- # -*- coding: utf-8 -*-
- # __author__ = "hlx"
- # Date: 2018/10/12
- from selenium import webdriver
- import time
- import os
- # 进入浏览器设置
- options = webdriver.ChromeOptions()
- # 设置中文
- options.add_argument('lang=zh_CN.UTF-8')
- options.add_argument('user-agent="Mozilla/5.0 (iPod; U; CPU iPhone OS 2_1 like Mac OS X; ja-jp) AppleWebKit/525.18.1 (KHTML, like Gecko) Version/3.1.1 Mobile/5F137 Safari/525.20"')
- prefs = {"download.default_directory": "D:\\MyProgram\\Python\\Pycharm\\Worm\\"}
- options.add_experimental_option("prefs", prefs)
- driver = webdriver.Chrome(chrome_options=options)
- my_Log=[]
- def download_Data(url_list):
- '''
- :param url_list:页面url列表
- :return:文档下载url
- '''
- for index in range(len(url_list)):
- url = url_list[index]
- driver.get(url)
- #获取文件下载名称
- try:
- filename= driver.find_element_by_xpath("//div[@class='text']//p//a").text
- #点击文件下载链接
- driver.find_element_by_xpath("//div[@class='text']//p//a").click()
- #等待下载完成
- print("正在下载"+filename)
- time.sleep(3)
- my_Log.append(filename+"下载完成")
- except:
- print("下载第"+str(index+1)+"失败")
- my_Log.append(url + "下载失败")
- #文件下载位置
- #="D:\\MyProgram\\Python\\Pycharm\\Worm\\"+filename
- #flag=True
- #count=10
- def WaterQuality_Spider(url,pageCount):
- '''
- :param url: 网站url
- :param pageCount: 爬取的数目
- :return: list url
- '''
- list_url=[]
- for index in range(pageCount):
- driver.get('http://www.cnemc.cn/csszzb2093030.jhtml')
- #休息一下 不然跳转不来
- time.sleep(3)
- page=str(index)
- driver.find_element_by_id("pageNum").send_keys(page)#在页码处填写页码
- #name=driver.find_element_by_xpath("//span[@class='list_hand'][last()]")
- driver.find_element_by_xpath("//span[@class='list_hand'][last()]").click()#转到该页
- # 休息一下 不然跳转不来
- time.sleep(2)
- list_a=driver.find_elements_by_xpath("//ul[@id='contentPageData']//a")#获取结果链接
- for thea in list_a:
- theurl = thea.get_attribute("href")
- list_url.append(theurl)
- download_Data(list_url)
- list_url = []
- my_Log.append("第"+str(index+1)+"下载完成")
- f = open("log.txt", 'a')
- for index in range(len(my_Log)):
- f.write(my_Log[index] + "\n")
- my_Log=[]
- print("第"+str(index+1)+"下载完成")
- return "ok"
- if __name__=="__main__":
- count=input("输入爬取的页数: ")
- url='http://www.cnemc.cn/csszzb2093030.jhtml'
- print("启动爬虫")
- WaterQuality_Spider(url,int(count))
- print("爬虫结束")
执行几分钟后,就可以获得结果
Selenium 爬取全国水质周报Word的更多相关文章
- python 利用selenium爬取百度文库的word文章
今天学习如何使用selenium库来爬取百度文库里面的收费的word文档 from selenium import webdriver from selenium.webdriver.common.k ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- [Python爬虫] Selenium爬取新浪微博客户端用户信息、热点话题及评论 (上)
转载自:http://blog.csdn.net/eastmount/article/details/51231852 一. 文章介绍 源码下载地址:http://download.csdn.net/ ...
- selenium爬取煎蛋网
selenium爬取煎蛋网 直接上代码 from selenium import webdriver from selenium.webdriver.support.ui import WebDriv ...
- 利用selenium爬取京东商品信息存放到mongodb
利用selenium爬取京东商城的商品信息思路: 1.首先进入京东的搜索页面,分析搜索页面信息可以得到路由结构 2.根据页面信息可以看到京东在搜索页面使用了懒加载,所以为了解决这个问题,使用递归.等待 ...
- python爬虫学习之爬取全国各省市县级城市邮政编码
实例需求:运用python语言在http://www.ip138.com/post/网站爬取全国各个省市县级城市的邮政编码,并且保存在excel文件中 实例环境:python3.7 requests库 ...
- 利用Selenium爬取淘宝商品信息
一. Selenium和PhantomJS介绍 Selenium是一个用于Web应用程序测试的工具,Selenium直接运行在浏览器中,就像真正的用户在操作一样.由于这个性质,Selenium也是一 ...
- Scrapy 框架 使用 selenium 爬取动态加载内容
使用 selenium 爬取动态加载内容 开启中间件 DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMidd ...
随机推荐
- 微信小程序开发1-入门知识准备
注:一个物联网专业的学生狗,平时学习较多的是嵌入式编程方面的知识,最近可能是闲的蛋疼,想要研究研究客户端开发,对于网页,手机Android客户端从来没有接触过,因此所有东西都要从头来过,慢慢学习.不过 ...
- Expo大作战(二)--expo的生命周期,expo社区交流方式,expo学习必备资源,开发使用expo时关注的一些问题
简要:本系列文章讲会对expo进行全面的介绍,本人从2017年6月份接触expo以来,对expo的研究断断续续,一路走来将近10个月,废话不多说,接下来你看到内容,讲全部来与官网 我猜去全部机翻+个人 ...
- 【Java入门提高篇】Day19 Java容器类详解(二)Map接口
上一篇里介绍了容器家族里的大族长——Collection接口,今天来看看容器家族里的二族长——Map接口. Map也是容器家族的一个大分支,但里面的元素都是以键值对(key-value)的形式存放的, ...
- Appium环境搭建(MAC版)
一.环境搭建 (1)安装node.js brew install node (2)安装Xcode 测试iOS App需要.打开Finder,在Applications文件夹下,看是否有Xcode.ap ...
- json_encode无返回结果
今天写php curl模拟客户端访问测试一个抽奖post数据,拿回来的数据是json,使用json_decode函数就是没结果,百度谷歌好久.终于发现是BOM的文件头造成的, 微软为utf-8文件添加 ...
- 【Python】插入sqlite数据库
import sqlite3 from datetime import datetime conn = sqlite3.connect('data.db') print("Opened da ...
- Visual Studio Code配置JavaScript环境
一·下载并安装Node.js/Visual Studil Code 下载对应你系统的Node.js版本:https://nodejs.org/en/download/ 选安装目录进行安装 环境配置 · ...
- 使用 PowerShell 将数据磁盘附加到 Windows VM
本文介绍如何使用 PowerShell 将新磁盘和现有磁盘附加到 Windows 虚拟机. 在开始之前,请查看以下提示: 虚拟机的大小决定了可以附加多少个磁盘. 有关详细信息,请参阅虚拟机大小. 若要 ...
- 将sqllite3数据库迁移到mysql
一.安装python mysql module (OneDrive): 1.运行python D:\OneDrive\Work\django\mysqlregistry.py2.http://www. ...
- idea 2017破解方法
http://blog.csdn.net/zx110503/article/details/78734428