Jmeter(十九)_ForEach控制器实现网页爬虫
一直以来,爬虫似乎都是写代码去实现的,今天像大家介绍一下Jmeter如何实现一个网页爬虫! 龙渊阁测试开发家园 317765580
Jmeter的爬虫原理其实很简单,就是对网页提交一个请求,然后把返回的所有href提取出来,利用ForEach控制器去实现url遍历。这样解释是不是很清晰?下面就来简单介绍一下如何操作。
首先我们需要对网页提交一个请求,就拿腾讯新闻网举例子吧!我们像腾讯新闻网发起一个请求,观察一下返回值可以发现中间有很多href标签+文字标题的url
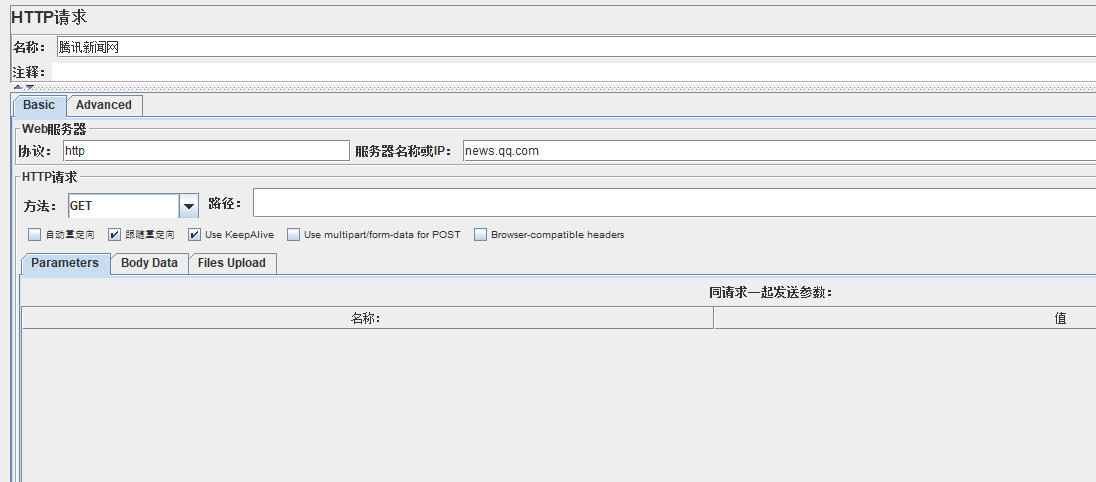

我们现在需要把这些url提取出来,利用强大的正则表达式!记得匹配数字填-1,意思就是把所有合适的url都取出来 龙渊阁测试开发家园 317765580
a target="_blank" class="linkto" href="http:// *(.*l)"

加一个debug查看一下是否真的取出来了 龙渊阁测试开发家园 317765580

又或者我们在结果里面直接利用正则匹配一下,可以看到很多网页链接都被取出来了 龙渊阁测试开发家园 317765580

接下来我们需要动用到ForEach控制器了,利用这个控制器对所有取出来的url进行遍历触发。记得在控制器里面填入变量名称,也就是刚刚正则表达式里面的变量名
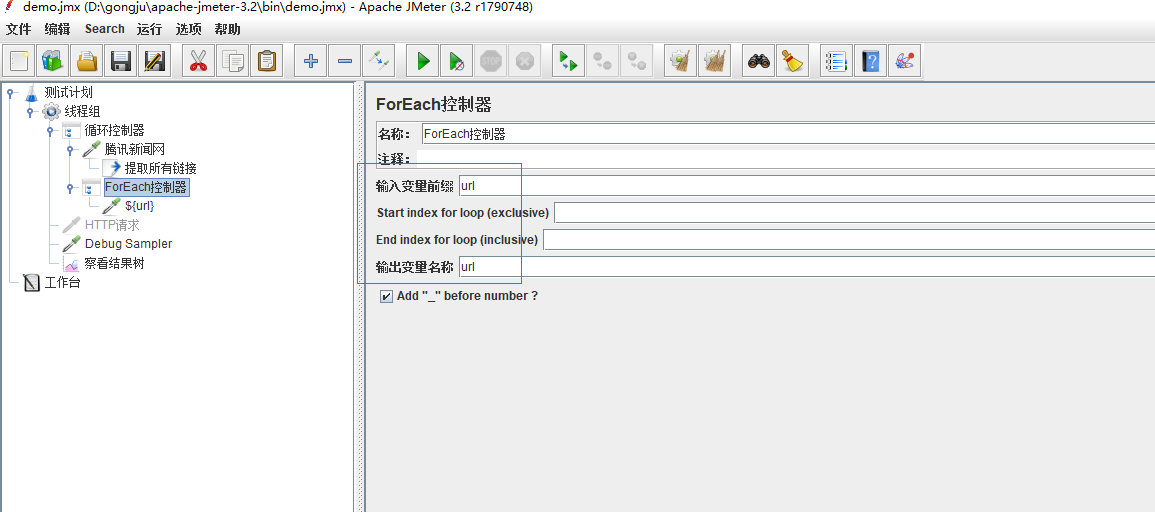
接下来在ForEach控制器下面再添加一个http请求,利用它去执行请求触发

下面我们可以观察结果了,见证奇迹的时候到了。观察结果我们发现所有匹配的url都被触发了! 龙渊阁测试开发家园 317765580

Jmeter(十九)_ForEach控制器实现网页爬虫的更多相关文章
- 第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用、自动限速、自定义spider的settings,对抗反爬机制
第三百四十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—cookie禁用.自动限速.自定义spider的settings,对抗反爬机制 cookie禁用 就是在Scrapy的配置文件set ...
- 第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能
第三百六十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)用Django实现搜索功能 Django实现搜索功能 1.在Django配置搜索结果页的路由映 ...
- 第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装
第三百五十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—elasticsearch(搜索引擎)介绍以及安装 elasticsearch(搜索引擎)介绍 ElasticSearch是一个基于 ...
- 第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式
第三百三十九节,Python分布式爬虫打造搜索引擎Scrapy精讲—Scrapy启动文件的配置—xpath表达式 我们自定义一个main.py来作为启动文件 main.py #!/usr/bin/en ...
- Jmeter(三十五)_精确实现网页爬虫
Jmeter实现了一个网站文章的爬虫,可以把所有文章分类保存到本地文件中,并以文章标题命名 它原理就是对网页提交一个请求,然后把返回的所有值提取出来,利用ForEach控制器去实现遍历.下面来介绍一下 ...
- Jmeter_ForEach控制器实现网页爬虫
一直以来,爬虫似乎都是写代码去实现的,今天像大家介绍一下Jmeter如何实现一个网页爬虫! Jmeter的爬虫原理其实很简单,就是对网页提交一个请求,然后把返回的所有href提取出来,利用ForEac ...
- Jmeter(十九) - 从入门到精通 - JMeter监听器 -上篇(详解教程)
1.简介 监听器用来监听及显示JMeter取样器测试结果,能够以树.表及图形形式显示测试结果,也可以以文件方式保存测试结果,JMeter测试结果文件格式多样,比如XML格式.CSV格式.默认情况下,测 ...
- Jmeter(四十五) - 从入门到精通高级篇 - Jmeter之网页爬虫-上篇(详解教程)
1.简介 上大学的时候,第一次听同学说网页爬虫,当时比较幼稚和懵懂,觉得就是几只电子虫子爬在网页上在抓取东西.后来又听说写代码可以实现网页爬虫,宏哥感觉高大上,后来工作又听说,有的公司做爬虫被抓的新闻 ...
- Python之路【第十九篇】:爬虫
Python之路[第十九篇]:爬虫 网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本.另外一些不常使用 ...
随机推荐
- eclipse 汉化详细方法
1.首先确认自己的 eclipse 是哪个版本,这个很关键,涉及到后面要用到的语言包需要与版本匹配,启动 eclipse,观察对应的版本号,比如我用的是 Photon 版本 2.参照官方给的方法进行下 ...
- postMessage 消息传递
点击查看demo 前言 web开发了,除了前台与服务器交换数据,还有可能前台页面间需要进行数据传递,比如窗口间,页面和嵌套的iframe间.这些问题之前都有解决办法,但是现在html5引入的messa ...
- Linux版的Mimikaz
A tool to dump the login password from the current linux desktop user. Adapted from the idea behind ...
- lua-resty-gearman模块
粘贴一段百度对gearman的解释: Gearman是一个用来把工作委派给其他机器.分布式的调用更适合做某项工作的机器.并发的做某项工作在多个调用间做负载均衡.或用来在调用其它语言的函数的系统. lu ...
- pyspider爬取数据导入mysql--1.安装驱动
接上篇,刚装好的pyspider,我们打算大显身手,抓一批数据到mysql中. 然而,出师未捷,提示我们:ImportError: No module named MySQLdb 这是因为还没有安装M ...
- javascript瀑布流效果
javascript瀑布流效果 其实javascript瀑布流 前几年都已经很流行了(特别是美丽说,蘑菇街),最近看到网上有人问这个瀑布流效果,所以自己有空的时候就研究了下,其实也是研究别人的代码,研 ...
- JAVA框架 Mybaits 动态sql
动态sql 一:if标签使用: 我们在查询的时候,有时候由于查询的条件的不确定性,导致where的后面的条件的不同,这时候就需要我们进行where后面的条件进行拼接. Mapper配置文件: < ...
- Android 写一个Activity之间来回跳转的全局工具类(主要是想实现代码的复用)
废话不多说了,直接上代码,相信大家都能看得懂的. 一.主要工具类 package com.yw.chat.utils; import android.app.Activity; import andr ...
- cloudstack的虚拟机arp -a时网关的mac地址 都是Incomplete
定位ARP攻击源头和防御方法 主动定位方式:因为所有的ARP攻击源都会有其特征——网卡会处于混杂模式,可以通过ARPKiller这样的工具扫描网内有哪台机器的网卡是处于混杂模式的,从而判断这台机器有可 ...
- strstr(),strchr()
strstr($a, $b)和strchr()一样,起的别名,表示查找$a中第一次出现$b,并返回字符串的剩余部分: .strrchr()从后往前查第一个出现的 直接写两行代码: <?php $ ...