SIGAI机器学习第十六集 支持向量机3
讲授线性分类器,分类间隔,线性可分的支持向量机原问题与对偶问题,线性不可分的支持向量机原问题与对偶问题,核映射与核函数,多分类问题,libsvm的使用,实际应用
大纲:
多分类问题
libsvm简介
实验环节
实际应用
SVM整体思路总结
多分类问题:
SVM怎么解决多分类问题,整体上有两种思路,第一种思路是多个二分类器的组合来解决多分类问题,第二种思路是直接优化一个多类的损失函数,就是训练出的就只是一个模型可以解决多分类问题。
第一种思路有两种实现:
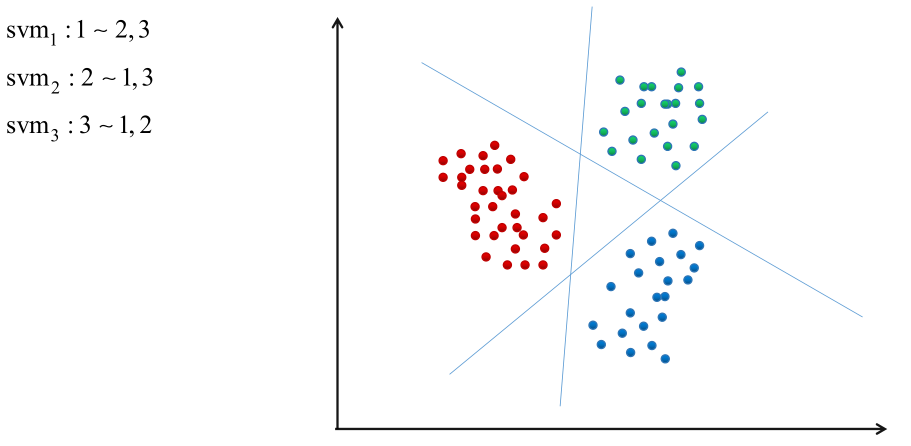
①1对剩余方案
假如有N个类,就训练n个分类器,每一个分类器是用来区分这个样本是属于第i类还是剩下的所有其他类,即第i个分类器是训练是否属于第i类。预测的时候,依次将样本带入N个分类器,哪个分类器取值最大就是哪个类。
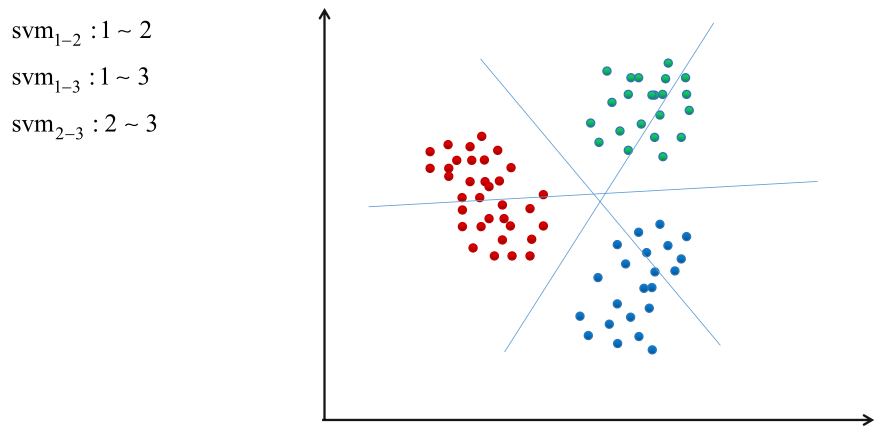
②1对1方案
训练Cn2个分类器,每两个类训练一个分类器。预测时,进行投票决定,将样本输入所有分类器,取被分类最多的那个类作为样本的类。
libsvm简介:
libsvm是SVM的一个著名的开源库,由台湾大学林智仁教授和他的学生开发,在全世界都被大规模使用了,在深度学习出现之前,这个库在机器学习里边是非常有名的,像opencv和其他知名的库它们的SVM都是封装了这个库,库的基础上面再封装的接口。使用c++语言编写,可以去它官网下载源码看一下,除了标准的c库(math库),它不依赖其他任何乱七八糟的库,看起来简洁易懂,其中的公式变量命名是按照SVM论文中变量命名方式命名的。提供java、python、matlab等语言的接口,跨平台(既可以在linux上调用也可以在Windows上调用,因为它就是用标准的c++写的,没有用和平台有关的库函数,如Windows、Linux上的多线程等函数,所以它的一致性是非常好的)。
实现了5种支持向量机(C-SVC带惩罚因子的支持向量机分类,V-SCV等...),既支持分类问题,也支持回归问题。
支持交叉验证,帮助我们选参数。
支持多分类,采用1对1方案。
支持概率输出,怎么估计一个样本属于某个类的概率的,有专门的论文讲,一般来说SVM不是一种概率模型不能估计概率,但是它用了一个技巧可以近似估计概率。
除了可以调用它的API,它还提供编译好的程序用来敲命令用的,
svm-train,训练程序,会训练一个模型保存到文件中去;svm-predict,预测程序,把模型读出来,对样本进行预测;svm-scale,对样本进行归一化,对于精度是至关重要的。
训练程序命令:
svm-train [options] training_set_file [model_file]
options表示可选的命令行参数。training_set_file表示训练样本集文件,就是里边按照它们指定的格式存放了所有的训练样本。model_file模型文件名,如果没有就不保存模型,有的话就保存到指定的文件名中。

预测程序命令:
svm-predict [options] test_file model_file output_file
model_file是模型文件名。test_file是测试文件名。里边是测试样本,测试样本可以带有标签值也可以不带,如果带会统计准确率。output_file是分类结果输出文件。预测程序先载入model_file,再载入test_file,预测完了结果写到output_file里边去。
实验环节:
训练:svm-train -s 0 -t 2 a1a a1a_model
程序输出:

保存的模型文件中的内容:

预测:svm-predict a1a.t a1a_model a1a_predict
程序输出:

输出了预测的准确率,可以改变模型的参数,比如选用不同的核函数,观察准确率变化。规律是惩罚因子C越大的话训练的越慢,训练的模型越精确,错误率越低。
实际应用:
1995-2012,尤其1998年SMO算法出来之后,无论在学术界和工业界,NLP、机器视觉等各类问题,最好的效果都是SVM,都是用的RBF核,效果是比较好的,十几年和神经网络较量中一直处于上风,直到深度学习出现,具体应用为:
[1] Burges JC. A tutorial on support vector machines for pattern recognition. Bell Laboratories, Lucent Technologies,1997.介绍模式识别在一些应用领域的综述。
[2] Bill Triggs. Histograms of oriented gradients for human detection. Navneet Dalal. computer vision and pattern recognition. 2005.是一个经典文章,它是用HoG特征加上线性的SVM,来解决行人检测问题,
[3] Thorsten Joachims. Text categorization with support vector machines. ECML 1998.
[4] Thorsten Joachims. Transductive Inference for Text Classification using Support Vector Machines. international conference on machine learning, 1999.
[5] Simon Tong, Daphne Koller. Support vector machine active learning with applications to text classification. Journal of Machine Learning Research. 2002.
[6] Edgar Osuna, Robert M Freund, Federico Girosit. Training support vector machines: an application to face detection. computer vision and pattern recognition. 1997.
[7] Guodong Guo, Stan Z Li, Kap Luk Chan. Face recognition by support vector machines. ieee international conference on automatic face and gesture recognition. 2000.
[8] Bernd Heisele, Purdy Ho, Tomaso Poggio. Face recognition with support vector machines: global versus component-based approach. international conference on computer vision. 2001.
[9] Luiz S Oliveira, Robert Sabourin. Support vector machines for handwritten numerical string recognition. international conference on frontiers in handwriting recognition. 2004.
需要注意的问题:
数据归一化:特征向量的每个分量要归一化到-1~+1或0~1,这样数值计算误差才会比较小,不会产生爆炸溢出等。
核函数与参数的选择:工业应用中一般不选用高斯核RBF,虽然它看上去很美精度会比一般的核高一些,但是它面临计算效率问题,尤其是向量维数非常高、支持向量数目比较大的时候,非线性映射K(XTX)会导致计算的非常慢,实际应用中很多时候选用线性核。所以看实际情况,如果样本数量很少而且速度慢也不要紧的话选用高斯核也没关系。
其他参数的选择:选定核函数之后,要选择合适的参数来,可以采用交叉验证选择合适的参数出来。一个标准的答案是,惩罚因子C越大模型就越精确,但是训练的时间长,得到的非零的α即支持向量越多。
数据预处理(归一化)之后,按照流程直接进行SVM训练就可以了,核心还是构造特征向量,特征向量根据不同的问题来构造,比如说图像识别里用的是一种特征,NLP中用的是另一种特征,各个特征都要依赖各个领域里面的知识,所以通用性很差,这个弊端是非常明显的相比于深度学习。
SVM整体思路总结:
整个SVM推导的一个过程,对算法有一个整体的认识,整体结构会更强一些,不至于陷入局部的细节不能理解。
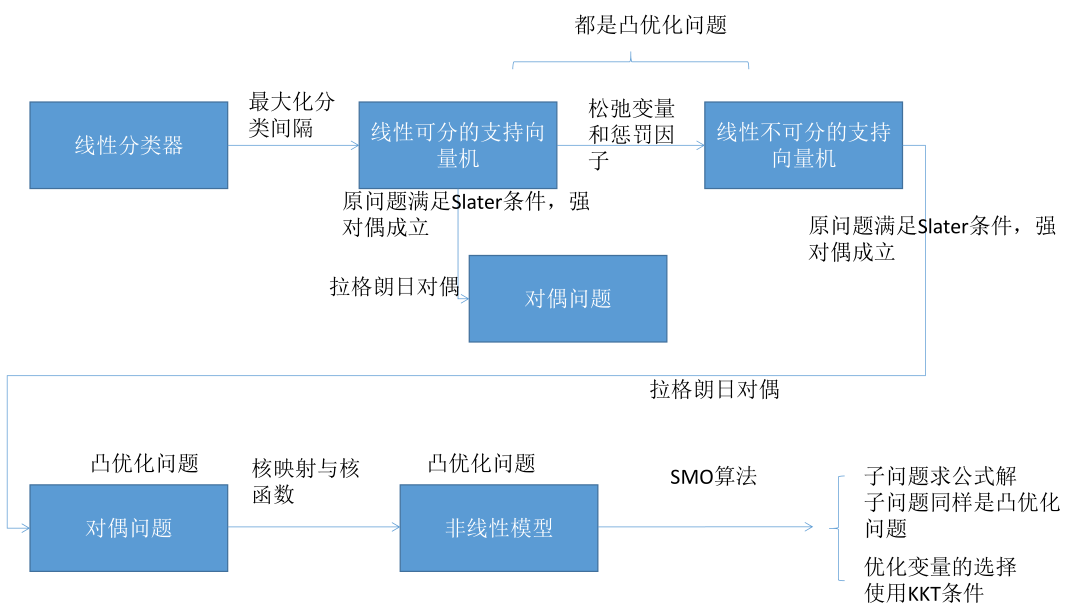
最开始SVM是一个线性分类器,目标是最大化分类间隔,由此引入了线性可分的SVM求解的原问题,它要满足两个条件,即要让所有样本都正确分类和让所有样本分类间隔最大化,就得到它的原问题了,一个带不等式约束的极值问题,后来证明了这个问题是一个凸优化问题,而且证明了它的目标函数是一个严格的凸函数,也证明了原问题满足Slater条件强对偶成立,因为原问题中有很多不等式约束存在求解起来非常的麻烦,因此用拉格朗日对偶把他转化成对偶问题。
整个SVM理解起来比较困难,主要是拉个朗日对偶和KKT条件两个地方。拉格朗日对偶就是先为等式约束和不等式约束建立一个朗格朗日乘子函数(这个和拉格朗日乘数法一样),然后把乘子变量当成常数值把原始要优化的变量当成变量,调整这些变量让拉格朗日乘子函数L取极小值,这样就消掉了那些原始要优化的变量只剩下拉格朗日乘子变量α,然后再控制α让L取极大值,这就是对偶问题。
因为线性可分问题太理想化了,现实实际应用中并不能保证都是线性可分的,所以要对SVM进行扩展。怎么扩展呢?就是引入了一个松弛变量,允许它违反不等式约束,但是一旦它违反了不等式约束就给它一个惩罚,这样松弛变量和惩罚因子C把SVM扩展成一个线性不可分问题,同样可以证明这个问题是一个凸优化问题,同时满足Slater条件,强对偶成立,同样可以利用拉格朗日乘数法把它转化为一个对偶问题。前边线性分类器中wx+b=0这个方程是有冗余的,一是为了消除冗余再则为了简化距离函数,就限定了|wx+b|=1,通个这个约束,问题就得到了简化。这里的拉格朗日对偶和线性可分的拉格朗日对偶方法是一样的,不过多了一个原始优化变量ξ,和线性可分的问题相比,唯一多了一个是对α的约束a≤C,C是惩罚因子,通过对偶问题可以看到惩罚因子C越大训练出来的模型越精确,因为对偶问题求解的范围是每个αi,0≤α≤C,如果C大的话,它的搜索范围会更大,在更大的范围搜索最优解。到这里为止整个SVM的预测函数函数线性函数,也就是说它还是一个线性模型,怎么处理非线性问题呢?是通过核映射和核函数做到的。
核映射把一个向量映射到高维空间里去,核函数是先让两个向量xi、xj做内积在用核函数K映射一下,它等价于先让xi、xj两个向量分别进行核映射之后再做内积,核函数的巧妙之处是它不用显式的给向量做升维处理,映射到高维空间再做内积,而是先给向量做内积再映射一下,它等价于先做映射再做内积的。常用的核函数是线性核(其实就是没有带核函数)、多项式核、径向基函数核/高斯核,尤其是高斯核它的准确率是非常高的。可以证明线性不可分问题同样是一个凸优化问题,加上核函数核映射之后还是一个凸优化问题,因为它的Hession矩阵的半正定性是由核函数保证的,把向量映射到高维空间等价于一个矩阵的转置和它做内积,这就是核函数的精妙之处,用拉格朗日都偶的另外一个好处就是很方便的引入核函数,因为核函数在对偶问题里处理起来是很方便的而在原问题里边不好做。在这里加入核函数之后,尤其是高斯核、多项式核函数以后,SVM就是一个非线性模型了,它可以处理很复杂非线性分类问题,可以处理异或问题。
对偶问题怎么求解呢?这个问题用标准算法处理起来非常困难,这里SMO算法专门为处理对偶问题量身定制,SMO算法是一种分治法,每次挑选出两个变量进行优化(因为它有等式约束,挑一个是不行的,会破坏它的等式约束的,所以说至少要同时优化两个变量),那么就转化为求解一个含有两个变量的二元二次函数的极值问题,但是它带有等式约束和不等式约束,利用等式约束可以消掉一个αi去实现αj,另外它的不等式约束限定了αi、αj的变量范围,所以说它是求某个二次函数在某个区域的极值问题,这样子问题可以求出它的严格的公式解,假设这个子问题是一元二次的凸优化问题(即开口向上的抛物线),证明了这个子问题是一个凸优化问题,也证明了SMO算法它最终一定会收敛(收敛的判定依据是,用KKT条件选择要优化的变量时,如果已经选不出来即所有变量都满足KKT条件,那就是达到最优解的地方迭代终止)。所以说KKT条件这里有两个作用,第一个就是选优化变量αi、αj(主要是选αi,如果αi选出来之后再选αj就和KKT条件关系不大了),第二个就是判断迭代循环有没有终止掉有没有达到最优点处。
以上就是SVM推导的核心过程,回去以后要多做实验、多思考、多理解。
SIGAI机器学习第十六集 支持向量机3的更多相关文章
- SIGAI机器学习第十四集 支持向量机1
讲授线性分类器,分类间隔,线性可分的支持向量机原问题与对偶问题,线性不可分的支持向量机原问题与对偶问题,核映射与核函数,多分类问题,libsvm的使用,实际应用 大纲: 支持向量机简介线性分类器分类间 ...
- SIGAI机器学习第十五集 支持向量机2
讲授线性分类器,分类间隔,线性可分的支持向量机原问题与对偶问题,线性不可分的支持向量机原问题与对偶问题,核映射与核函数,多分类问题,libsvm的使用,实际应用 大纲: SVM求解面临的问题 SMO算 ...
- SIGAI机器学习第十九集 随机森林
讲授集成学习的概念,Bootstrap抽样,Bagging算法,随机森林的原理,训练算法,包外误差,计算变量的重要性,实际应用 大纲: 集成学习简介 Boostrap抽样 Bagging算法 随机森林 ...
- SIGAI机器学习第十八集 线性模型2
之前讲过SVM,是通过最大化间隔导出的一套方法,现在从另外一个角度来定义SVM,来介绍整个线性SVM的家族. 大纲: 线性支持向量机简介L2正则化L1-loss SVC原问题L2正则化L2-loss ...
- SIGAI机器学习第二十四集 聚类算法1
讲授聚类算法的基本概念,算法的分类,层次聚类,K均值算法,EM算法,DBSCAN算法,OPTICS算法,mean shift算法,谱聚类算法,实际应用. 大纲: 聚类问题简介聚类算法的分类层次聚类算法 ...
- SIGAI机器学习第二十二集 AdaBoost算法3
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用. AdaB ...
- SIGAI机器学习第二十集 AdaBoost算法1
讲授Boosting算法的原理,AdaBoost算法的基本概念,训练算法,与随机森林的比较,训练误差分析,广义加法模型,指数损失函数,训练算法的推导,弱分类器的选择,样本权重削减,实际应用 AdaBo ...
- SIGAI机器学习第十集 线性判别分析
讲授LDA基本思想,寻找最佳投影矩阵,PCA与LDA的比较,LDA的实际应用 前边讲的数据降维算法PCA.流行学习都是无监督学习,计算过程中没有利用样本的标签值.对于分类问题,我们要达到的目标是提取或 ...
- 机器学习笔记(六) ---- 支持向量机(SVM)
支持向量机(SVM)可以说是一个完全由数学理论和公式进行应用的一种机器学习算法,在小批量数据分类上准确度高.性能好,在二分类问题上有广泛的应用. 同样是二分类算法,支持向量机和逻辑回归有很多相似性,都 ...
随机推荐
- SSM-CRUD
一.项目介绍 前端技术:query+Bootstrap+ajax+json 后端技术:SSM(spring.springMVC.mybatis).JSR303校验 数据库:mysql 服务器:tomc ...
- 长乐培训Day7
T1 删除 题目 [题目描述] 现在,我的手上有 n 个数字,分别是 a1,a2,a3,...,an. 我现在需要删除其中的 k 个数字.当然我不希望随随便便删除,我希望删除 k 数字之后,剩下的 n ...
- scrapy2——框架简介和抓取流程
scrapy简介 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中 scrapy的执行流程 Scrapy主要包括 ...
- mongodb 启动及创建用户
1. 守护进程启动,参考: https://blog.csdn.net/jj546630576/article/details/81117765 2. 用户管理参考: https://www.cnbl ...
- 【统计与建模】R语言基本操作
# vec <- rep( seq(1,5,by=0.5),3) # vec <- seq( 1 , 10 , by = 1 ) # min(vec) #最小值 # max(vec) #最 ...
- 题解-APIO2019桥梁
problem \(\mathrm {loj-3145}\) 题意概要:给定一张 \(n\) 点 \(m\) 边的无向图,边有边权,共 \(q\) 次操作,每次会将第 \(x\) 条边的权值改为 \( ...
- C#使用任务并行库(TPL)
TPL(Task Parallel Library) 任务并行库 (TPL) 是 System.Threading和 System.Threading.Tasks 命名空间中的一组公共类型和 API. ...
- shell 函数的高级用法
函数介绍 linux shell中的函数和大多数编程语言中的函数一样 将相似的任务或者代码封装到函数中,供其他地方调用 语法格式 如何调用函数 shell终端中定义函数 [root@master da ...
- SQL SERVER-Extendevent
事件类介绍 https://docs.microsoft.com/zh-cn/previous-versions/sql/sql-server-2008/ms188275(v=sql.100)
- NumPy 百题大冲关,冲鸭!
角色名称:NumPy 角色描述:NumPy是一个NASA都在用的扩展库. NumPy提供了许多高级的数值编程技能,如:矩阵数据类型.矢量处理,以及精密的运算库.专为进行严格的数字处理而战斗.是很多大型 ...