(持续更新中~~~)kafka--消息引擎与分布式流处理平台
kafka概述
kafka是一个分布式的基于发布/订阅模式的消息队列(message queue),一般更愿意称kafka是一款开源的消息引擎系统,只不过消息队列会耳熟一些。kafka主要应用于大数据实时领域。
为什么会有消息队列,主要是为了异步处理,提高效率。我们来看一张图
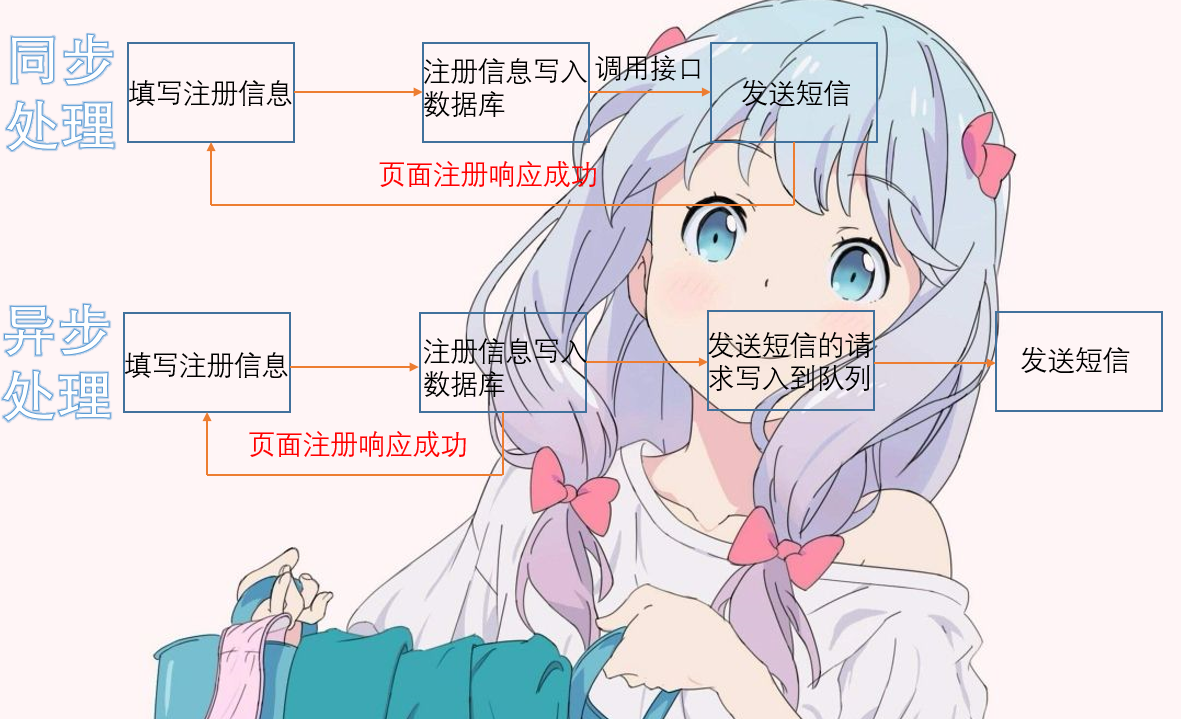
使用消息队列,可以把耗时任务扔到队列里面,异步调用,从而提升效率。也就是我们所说的解耦。
然而除了解耦,还有没有其他作用呢?答案显然是有的,用一个专业点的名词解释的话,就是削峰填谷。
削峰填谷,真的是非常形象的四个字。所谓的削峰填谷,就是指缓冲上下游瞬时突发流量,使其更平滑。特别是那种发送能力很强的上游系统,如果没有消息引擎的保护,脆弱的下游系统可能会直接被压垮导致全链路服务雪崩。但是,一旦有了消息引擎,它能够有效的对抗上游的流量冲击,真正做到将上游的"峰"填到"谷"中,避免了流量的震荡。消息引擎系统的另一大好处就是我们刚才说的,在于发送方和接收方的松耦合,这也在一定程度上简化了应用的开发,减少了系统间不必要的交互
直接解释的话,可能没有直观的感受,我们来举一个实际的例子。比如在京东购买商品。当点击购买的时候,会调用订单系统生成对应的订单,然而要处理该订单则会依次调用下游系统的多个子服务,比如调用银行等支付接口、查询你的登录信息、验证商品信息等等。显然上游的订单操作比较简单,它的TPS要远高于处理订单的下游服务。因此如果上游和下游直接对接,势必会出现下游服务无法及时处理上游订单从而造成订单堆积的情况。特别是当出现双十一、双十二、类似秒杀这种业务的时候,上游订单流量会瞬间增加,可能出现的结果就是直接压垮下游子系统服务。解决此问题的一个常见的做法就是对上游系统进行限速,但是这种做法显然是不合理的,毕竟问题不是出现在它那里。况且你要是限速了,别人家网站双十一成交一千万笔单子,自家网站才成交一百万笔单子,这样钱送到嘴边都赚不到。所以更常见的办法就是引入像kafka这样的消息引擎系统来对抗这种上下游系统的TPS不一致以及瞬时峰值流量。
还是这个例子,当引入了kafka之后,上游系统不再直接与下游系统进行交互。当新订单生成之后它仅仅是向kafka broker发送一条消息即可。类似的,下游的各个子服务订阅kafka中的对应主题,并实时从该主题的各自分区(partition)中获取到订单消息进行处理,从而实现上游订单服务和下游订单处理服务的解耦。这样当出现秒杀业务的时候,kafka能够将瞬时增加的订单流量全部以消息的形式保存在对应的主题中。既不影响上游服务的TPS,同时也给下游服务流出了足够的时间去消费它们。这就是kafka这类消息引擎存在的最大意义所在。
目前里面出现了很多的专业词汇,broker、主题、partition等等,这些我们后面都会介绍。
kafka消费模式
我们知道消息队列传输的是消息,那么这个消息如何传递也是很重要的一环。一般消息队列支持两种传递模式。
点对点模式:生产者将生产的消息发送到queue中,然后消费者再从queue中取出消息进行消费。消息一旦被消费,那么queue中不再有存储,所以消费者不可能消费到已经被消费的信息。queue支持多个消费者同时消费,但是一个消息只能被一个消费者消费,不存在说多个消费者同时消费一个消息。日常生活中就好电话客服服务,同一个客户呼入电话,只能被一位客服人员处理,第二个客服人员不能为该客户服务
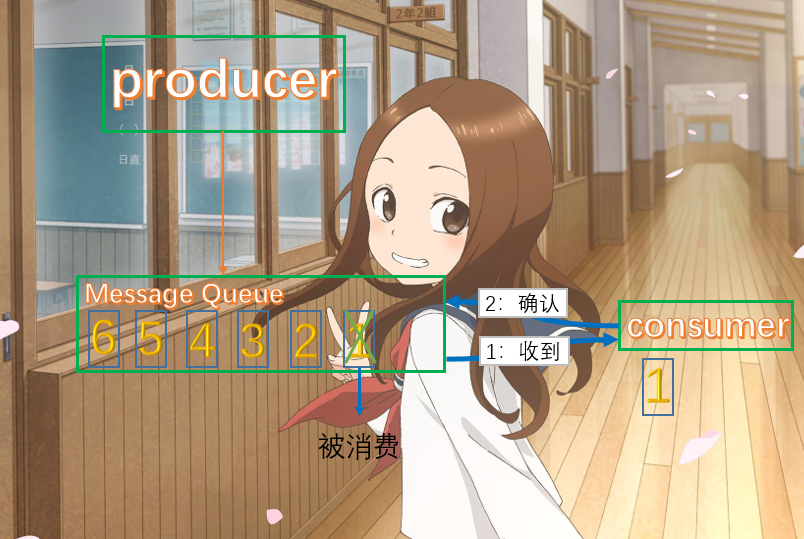
发布订阅模式和点对点模型不同,它有一个主题(Topic)的概念。该模型也有发送方和接收方,只不过叫法不一样。发送方也被成为发布者(publisher),接收方成为订阅者(subscriber)。和点对点模型不一样,这个模型可以存在多个发布者和多个订阅者,它们都能接收到相同主题的消息。好比微信公众号,一个公众号可以有多个订阅者,一个订阅者也可以订阅多个公众号。

搞定kafka的专业术语
在kafka的世界中有很多概念和术语是需要我们提前理解并且熟练掌握的,下面来盘点一下。
之前我们提到过,kafka属于分布式的消息引擎系统,主要功能是提供一套完善的消息发布与订阅方案。在kafka中,发布订阅的对象是主题(topic),可以为每个业务、每个应用、甚至是每一类数据都创建专属的主题
向主题发布消息的客户端应用程序成为生产者(producer),生产者通常持续不断地向一个或多个主题发送消息,而订阅这些主题获取消息的客户端应用程序就被称之为消费者(consumer)。和生产者类似,消费者也能同时订阅多个主题。我们把生产者和消费者统称为客户端(clients)。你可以同时运行多个生产者和消费者实例,这些实例不断地向kafka集群中的多个主题生产和消费消息。有客户端自然也就有服务端。kafka的服务器端由被称为broker的服务进程构成,即一个kafka集群由多个broker组成,broker负责接收和处理客户端发来的请求,以及对消息进行持久化。虽然多个broker进程能够运行在同一台机器上,但更常见的做法是将不同的broker分散运行在不同的机器上。这样即便集群中的某一台机器宕机,运行在其之上的broker进程挂掉了其他机器上的broker也依旧能对外提供服务。这其实就是kafka提供高可用的手段之一
在实现高可用的另一个手段就是备份机制(replication)。备份的思想很简单,就是把相同的数据拷贝到多台机器上,而这些相同的数据拷贝就叫做副本(replica)。副本的数量是可以配置的,这些副本保存着相同的数据,但却有不同的角色和作用。kafka定义了两种副本,领导者副本(leader replica)和追随者副本(follower replica)。前者对外提供服务,这里的对外指的是与客户端进行交互;而后者只是被动地追随领导者副本而已,不与外界进行交互。当然了,很多其他系统中追随者副本是可以对外提供服务的,比如mysql,从库是可以处理读操作的,也就是所谓的"主写从读",但是在kafka中追随者副本不会对外提供服务,至于为什么我们作为思考题解答。对了,关于领导者--追随者,之前其实是叫做主(master)--从(slave),但是不建议使用了,因为slave有奴隶的意思,政治上有点不合适,所以目前大部分的系统都改成leader-follower了。
副本的工作机制很简单:生产者向主题写的消息总是往领导者那里,消费者向主题获取消息也都是来自于领导者。也就是无论是读还是写,针对的都是领导者副本,至于追随者副本,它只做一件事情,那就是向领导者副本发送请求,请求领导者副本把最新生产的消息发送给它,这样便能够保持和领导者的同步。
虽然有了副本机制可以保证数据的持久化或者数据不丢失,但没有解决伸缩性的问题。伸缩性即所谓的scalability,是分布式系统中非常重要且必须谨慎对待的问题。什么事伸缩性呢?我们拿副本来说,虽然现在有了领导者副本和追随者副本,但倘若领导者副本积累了太多的数据以至于单台broker都无法容纳了,此时应该怎么办?有个很自然的想法就是,能否把数据分割成多分保存在不同的broker上?没错,kafka就是这么设计的。
这种机制就是所谓的分区(partition)。如果了解其他的分布式系统,那么可能听说过分片、分区域等提法,比如MongoDB和ElasticSearch中的sharding、Hbase中的region,其实它们都是相同的原理,只是partition是最标准的名称。
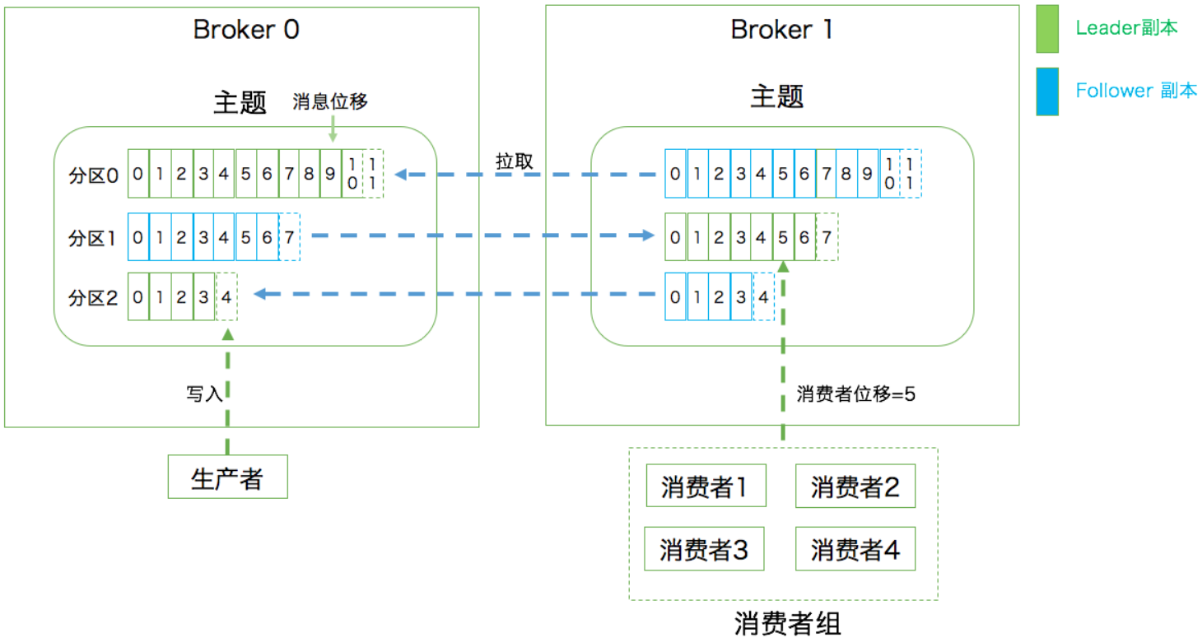
kafka中的分区机制指定的是将每个主题划分为多个分区,每个分区都是一组有序的消息日志。生产者生产的每一条消息只会被发到一个分区中,也就说如果向有两个分区的主题发送一条消息,那么这条消息要么在第一个分区中,要么在第二条分区中。而kafka的分区编号是从0开始的,如果某个topic有100个分区,那么它们的分区编号就是从0到99
到这里可能会有疑问,那就是刚才提到的副本如何与这里的分区联系在一起呢?实际上,副本是在分区这个层级定义的。每个分区下可以配置若干个副本,其中只能有1个领导者副本和N-1个追随者副本。生产者向分区写入消息,每条消息在分区中的位置由一个叫位移(offset)的数据来表征。分区位移总是从0开始,假设一个生产者向一个空分区写入了10条消息,那么这10条消息的位移依次是0、1、2、...、9
至此我们能完整地串联起kafka的三层消息架构
第一层是主题层,每个主题可以配置M个分区,每个分区又可以配置N个副本第二层是分区层,每个分区的N个副本中只能有一个副本来充当领导者角色,对外提供服务;其他的N-1个副本只是追随者副本,用来提供数据冗余之用。第三层是消息层,分区中包含若干条消息,每条消息的位移从0开始,依次递增。最后客户端程序只能与分区的领导者副本进行交互
那么kafka是如何持久化数据的呢?总的来说,kafka使用消息日志(log)来保存数据,一个日志就是磁盘上一个只能追加写(append-only)消息的物理文件。因为只能追加写入,故避免了缓慢的随机I/O操作,改为性能较好的顺序I/O操作,这也是实现kafka高吞吐量特性的一个重要手段。不过如果不停地向一个日志写入消息,最终也会耗尽所有的磁盘空间,因此kafka必然要定期地删除消息以回收磁盘。怎么删除?简单来说就是通过日志段(log segment)机制。在kafka底层,一个日志又进一步细分成多个日志段,消息被追加写到当前最新的日志段中,当写满了一个日志段后,kafka会自动切分出一个新的日志段,并将老的日志段封存起来。kafka在后台还有定时任务会定期地检查老的日志段是否能够被删除,从而实现回收磁盘的目的。
这里再重点说一下消费者,之前说过有两种消息模型,即点对点模型(peer to peer, p2p)和分布订阅模型。这里面的点对点指的是同一条消息只能被下游的一个消费者消费,其他消费者不能染指。在kafka中实现这种p2p模型的方法就是引入了消费者组(consumer group)。所谓的消费者组,指的是多个消费者实例共同组成一个组来消费一个主题。这个主题中的每个分区都只会被消费者组里面的一个消费者实例消费,其他消费者实例不能消费它。为什么要引入消费者组呢?主要是为了提升消费者端的吞吐量,多个消费者实例同时消费,加速了整个消费端的吞吐量(TPS)。关于消费者组的机制,后面会详细介绍,现在只需要知道消费者组就是多个消费者组成一个组来消费主题里面的消息、并且消息只会被组里面的一个消费者消费即可。此外,这里的消费者实例可以是运行消费者应用的进程,也可以是一个线程,它们都称为一个消费者实例(consumer instance)
消费者组里面的消费者不仅瓜分订阅主题的数据,而且更酷的是它们还能彼此协助。假设组内某个实例挂掉了,kafka能够自动检测,然后把这个Failed实例之前负责的分区转移给其他活着的消费者。这个过程就是大名鼎鼎的"重平衡(rebalance)"。嗯,其实即是大名鼎鼎,也是臭名昭著,因为由重平衡引发的消费者问题比比皆是。事实上,目前很多重平衡的bug,整个社区都无力解决。
每个消费者在消费消息的过程中,必然需要有个字段记录它当前消费到了分区的哪个位置上,这个字段就是消费者位移(consumer offset)。注意,我们之前说一个主题可以有多个分区、每个分区也是用位移来表示消息的位置。但是这两个位移完全不是一个概念,分区位移表示的是分区内的消息位置,它是不变的,一旦消息被成功写入一个分区上,那么它的位置就是固定了的。而消费者位移则不同,它可能是随时变化的,毕竟它是消费者消费进度的指示器嘛。另外每个消费者都有着自己的消费者位移,因此一定要区分这两类位移的区别。一个是分区位移,另一个是消费者位移
小结:
生产者,producer:向主题发布新消息的应用程序消费者,consumer:从主题订阅新消息的应用程序消息,record:kafka是消息引擎,这里的消息就是指kafka处理的主要对象主题,topic:主题是承载消息的逻辑容器,在实际使用中多用来区分具体的业务,即不同的业务对应不同的主题。分区,partition:一个有序不变的消息序列,每个主题下可以有多个分区。分区编号从0开始,分布在不同的broker上面,实现发布于订阅的负载均衡。生产者将消息发送到主题下的某个分区中,以分区偏移(offset)来标识一条消息在一个分区当中的位置(唯一性)分区位移,offset:表示分区中每条消息的位置信息,是一个单调递增且不变的值副本,replica:kafka中同一条数据能够被拷贝到多个地方以提供数据冗余,这便是所谓的副本。副本还分为领导者副本和追随者副本,各自有各自的功能职责。读写都是针对领导者副本来的,追随者副本只是用来和领导者副本进行数据同步、保证数据冗余、实现高可用。消费者位移,consumer offset:表示消费者消费进度,每个消费者都有自己的消费者位移消费者组,consumer group:多个消费者实例共同组成的一个组,同时消费多个分区以实现高吞吐。重平衡,rebalance:消费者组内某个消费者实例挂掉之后,其它消费者实例自动重新分配订阅主题分区的过程。重平衡是kafka消费者端实现高可用的重要手段
思考:为什么kafka不像mysql那样支持主写从读呢?
因为kafka的主题已经被分为多个分区,分布在不同的broker上,而不同的broker又分布在不同的机器上,因此从某种角度来说,kafka已经实现了负载均衡的效果。不像mysql,压力都在主上面,所以才要从读;另外,kafka保存的数据和数据库的数据有着实质性的差别,kafka保存的数据是流数据,具有消费的概念,而且需要消费者位移。所以如果支持从读,那么消费端控制offset会更复杂,而且领导者副本同步到追随者副本需要时间的,会造成数据不一致的问题;另外对于生产者来说,kafka是可以通过配置来控制是否等待follower对消息确认的,如果支持从读的话,那么也需要所有的follower都确认了才可以回复生产者,造成性能下降,而且follower出现了问题也不好处理。
kafka只是消息队列(消息引擎系统)吗
kafka真的只是消息引擎系统吗?要搞清楚这个问题,就要从kafka的发展历史说起,纵观kafka的发展历史,它确实是消息引擎起家的,但它不仅是一个消息引擎系统,同时也是一个分布式流处理平台(distributed stream processing platform)。如果这一节你只能记住一句户的话,那我希望你能记住,kafka虽然是消息引擎起家,但它不仅是一个消息引擎,还是一个分布式流处理平台。
总所周知,kafka是LinkedIn公司内部孵化的项目,LinkedIn最开始有强烈的数据强实时处理方面的需求,其内部的诸多子系统要执行多种类型的数据处理与分析,主要包括业务系统和应用程序性能监控,以及用户行为数据处理等。当时他们碰到的主要问题包括:
数据正确性不足。因为数据的收集主要采用轮询(polling)的方式,如何确定轮询的时间间隔就变成了一个高度经验化的事情。虽然可以采用一些类似于启发式算法来帮助评估间隔时间,但一旦指定不当,必然会造成较大的数据偏差。系统高度定制化,维护成本高。各个业务子系统都需要对接数据收集模块,引入了大量的定制开销和人工成本
为了解决这些问题,LinkedIn工程师尝试过使用ActiveMQ来解决这些问题,但效果并不理想。显然需要有一个"大一统"的系统来取代现有的工作方式,而这个系统就是kafka。因此kafka自诞生伊始是以消息引擎系统的面目出现在大众视野的,如果翻看比较老的kafka对应的官网的话,你会发现kafka社区将其清晰地定位为一个分布式、分区化且带备份功能的提交日志(commit log)服务。
因此,kafka在设计之初就旨在提供三个方面的特性:
提供一套API实现生产者和消费者降低网络传输和磁盘存储开销实现高伸缩架构
在现如今的大数据领域,kafka在承接上下游、串联数据流管道方面发挥了重要的作用:所有的数据几乎都要从一个系统流入kafka,然后再流入下游的另一个系统中 。这样使用方式屡见不鲜以至于引发了kafka社区的思考:与其我把数据从一个系统传递到下一个系统进行处理,我为何不自己实现一套流处理框架呢?基于这个考量,kafka社区在0.10.0.0版本推出了流处理组件kafka streams,也正是从这个版本开始,kafka正式变身为分布式的流处理平台,而不再仅仅只是消息引擎系统了。今天kafka是和storm、spark、flink同等级的实时流处理平台了。
那么作为流处理平台,kafka与其他大数据流式计算框架相比,优势在哪里呢?
第一点是更容易实现端到端的正确性(correctness)。流处理要最终替代它的兄弟批处理需要具备两点核心优势:要实现正确性和提供能够推导时间的工具。实现正确性是流处理能够匹敌批处理的基石。正确性一直是批处理的强项,而实现正确性的基石则是要求框架能提供'精确一次语义处理',即处理一条消息有且只有一次机会能够影响系统状态。目前主流的大数据流处理框架都宣称实现了'精确一次语义处理',但是这是有限定条件的,即它们只能实现框架内的精确一次语义处理,无法实现端到端的。这是为什么呢?因为当这些框架与外部消息引擎系统结合使用时,它们无法影响到外部系统的处理语义,所以如果你搭建了一套环境使得spark或flink从kafka读取消息之后进行有状态的数据计算,最后再写回kafka,那么你只能保证在spark或者flink内部,这条消息对于状态的影响只有一次。但是计算结果有可能多次写入的kafka,因为它们不能控制kafka的语义处理。相反地,kafka则不是这样,因为所有的数据流转和计算都在kafka内部完成,故kafka可以实现端到端的精确一次处理。第二点是kafka自己对于流式计算的定位。官网上明确表示kafka streams是一个用于搭建实时流处理的客户端库而非是一个完整地功能系统。这就是说,你不能期望着kafka提供类似于集群调度、弹性部署等开箱即用的运维特性,你需要自己选择合适的工具或者系统来帮助kafka流处理应用实现这些功能。读到这里可能觉得这怎么是有点呢?坦率的说,这是一个双刃剑的设计,也是kafka剑走偏锋不正面pk其他流计算框架的特意考量。大型公司的流处理平台一定是大规模部署的,因此具备集群调度功能以及灵活的部署方案是不可获取的要素。但毕竟世界上还存在着很多中小企业,它们的流处理数据量并不巨大,逻辑也不复杂,部署几台或者十几台机器足以应付。在这样的需求下,搭建重量级的完整性平台实在是'杀鸡用宰牛刀',而这正式kafka流处理组件的用武之地。因此从这个角度来说,未来在流处理框架当中,kafka应该是有着一席之地的。
这里再来解释一下什么是精确一次语义处理。举个例子,如果我们使用kafka计算某网页的pv,我们将每次网页访问都作为一个消息发送给kafka,pv的计算就是我们统计kafka总共接收了多少条这样的消息即可。精确一次语义处理表示每次网页访问都会产生、且只产生一条消息
处理消息引擎和流处理平台,kafka还有别的用途吗?当然有,kafka甚至能够被用作分布式存储系统,但是实际生产中,没有人会把kafka当中分布式存储系统来用的。kafka从一个优秀的消息引擎系统起家,逐渐演变成现在的分布式的流处理平台。我们不仅要熟练掌握它作为消息引擎系统的非凡特性以及使用技巧,最好还要多了解下其流处理组件的设计与案例应用。
应该选择哪种kafka
我们上一节谈了kafka当前的定位问题,kafka不再是一个单纯的消息引擎系统,而是能够实现精确一次(exactly-once)语义处理的实时流平台。我们到目前为止所说的kafka都是Apache kafka,kafka是Apache社区的一个顶级项目,如果我们把视角从流处理平台扩展到流处理生态圈,kafka其实还有很长的路要走,毕竟是半路出家转型成流处理平台的。前面我们提到过kafka streams组件,正是它提供了kafka实时处理流数据的能力。但是其实还有一个重要的组件没有提及,那就是kafka connect。
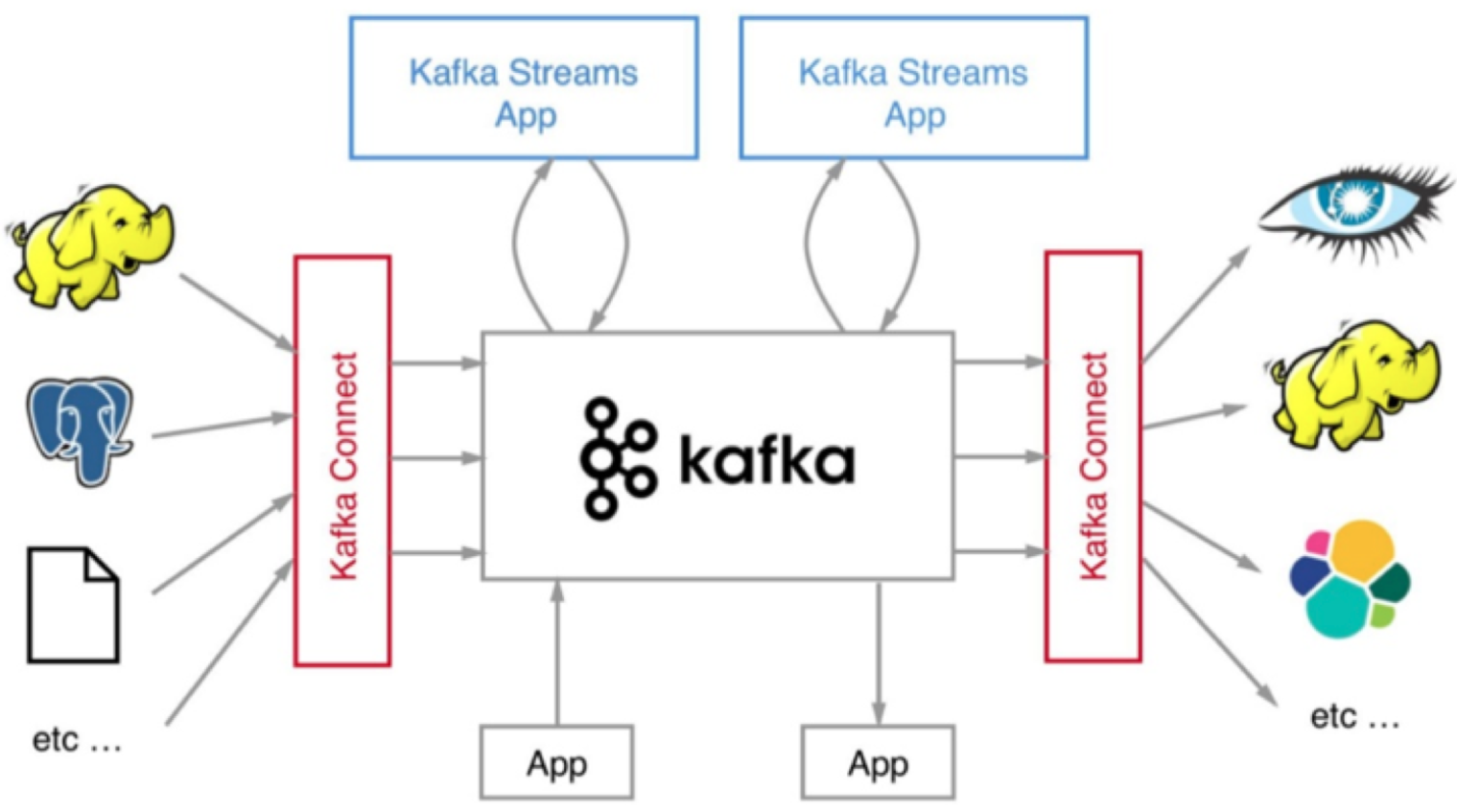
我们在评估流处理平台的时候,框架本身的性能、所提供操作算子(operator)的丰富程度固然是重要的评判指标,但是框架与上下游交互的能力也是非常重要的。能够与之进行数据传输的外部系统越多,围绕它打造的生态圈就越牢固,因而也就有更多的人愿意去使用它,从而形成正向反馈,不断地促进该生态圈的发展。就kafka而言,kafka connect通过一个个具体的连接器(connector),串联起上下游的外部系统。
整个kafka生态圈如下图所示,值得注意的是,这张图的外部系统只是kafka connect组件支持的一部分而已。目前还有一个可喜的趋势是使用kafka connect组件的用户越来越多,相信在未来会有越来越多的人开发自己的连接器。
说了这么多,可能会有人好奇这跟这一节的主题有什么关系呢?其实清晰地了解kafka的发展脉络和生态圈现状,对于我们选择合适的kafka版本大有裨益。下面我们就进入今天的主题---如何选择kafka版本
首先你知道几种kafka
咦?kafka不是一个开源框架吗?什么叫有几种kafka,实际上,kafka的确有好几种kafka啊?实际上,kafka的确有好几种,这里我不是指它的版本,而是指存在多个组织或者公司发布的不同kafka。就像linux的发行版,有Ubuntu、centos等等,虽说kafka没有发行版的概念,但姑且可以这样的近似的认为市面上的确存在着多个kafka"发行版"。当然用发行版这个词只是为了这里方便解释,但是发行版这个词在kafka生态圈非常陌生,以后聊天时不要用发行版这个词。下面我们就看看kafka都有哪些"发行版"
Apache kafka:Apache kafka是最"正宗"的kafka,也应该是最熟悉的发行版了。字kafka开源伊始,它便在Apache基金会孵化并最终毕业成为顶级项目,也被称之为社区版kafka。目前我也是以这个版本的kafka进行介绍的。更重要的是,它是后面其他所有发行版的基础。也就是说,其他的发行版要么是原封不动的继承了Apache kafka,要么是在其基础之上进行了扩展、添加了新功能,总之Apache kafka是我们学习和使用kafka的基础。
Confluent kafka:我先说说Confluent公司吧。2014年,kafka的3个创始人Jay Kreps、Naha Narkhede 和饶军离开 LinkedIn创办了Confluent公司,专注于提供基于kafka的企业级流处理解决方案。2019年1月,Confluent公司成功融资1.25亿美元,估值也到了25亿美元,足见资本市场的青睐。这里说点题外话,饶军是我们中国人,清华大学毕业的大神级人物。我们已经看到越来越多的Apache顶级项目创始人中出现了中国人的身影。另一个例子就是,Apache pulsar,它是一个以打败kafka为目标的新一代消息引擎系统,在开源社区中活跃的中国人数不胜数,这种现象实在令人振奋。还说回Confluent公司,它主要从事商业化的kafka工具开发,并在此基础上发布了Confluent kafka。Confluent kafka提供了Apache kafka没有的高级特性,比如跨数据中心备份、schema注册中心以及集群监控工具等等。
Cloudera/Hortonworks KafkaCloudera提供的CDH和Hortonworks提供的HDP是非常著名的大数据平台,里面集成了目前主流的大数据框架,能够帮助用户实现从分布式存储、集群调度、流处理到机器学习、实时数据库等全方位的数据处理。很多创业公司在搭建数据平台时首选就是这两个产品。不管是CDH还是HDP,里面都集成了Apache kafka,因此就把这款产品中的kafka称之为CDH kafka和HDP kafka
当然在2018年10月两家公司宣布合并,共同打造世界领先的数据平台,也许以后CDH和HDP也会合并成一款产品,但能肯定的是Apache kafka依然会包含其中,并作为新数据平台的一部分对外提供服务。
特点比较
okay,说完了目前市面上的这些kafka,我们来对比一下它们的优势和劣势
1.Apache kafka
对Apache kafka而言,它现在依旧是开发人数最多,版本迭代速度最快的kafka。在2018年度Apache基金会邮件列表中开发者数量最多的top5排行榜中,kafka社区邮件组排名第二位。如果你使用Apache kafka碰到任何问题并将问题提交到社区,社区都会比较及时的响应你。这对于我们kafka普通使用者来说无疑是非常友好的。
但是Apache kafka的劣势在于它仅仅提供最最基础的主组件,特别是对于前面提到的kafka connect而言,社区版kafka只提供一种连接器,即读写磁盘文件的连接器,而没有与其他外部系统交互的连接器,在实际使用过程中需要自行编写代码实现,这是它的一个劣势。另外Apache kafka没有提供任何监控框架或工具,而在线上环境不加监控肯定是不行的,你必然需要借助第三方的监控框架来对kafka进行监控。好消息是目前有一些开源的监控框架可以帮助用于监控kafka(比如kafka manager)
总而言之,如果仅仅需要一个消息引擎系统亦或是简单的流处理应用场景,同时需要对系统有较大把控度,那么我推荐你使用Apache kafka2.Confluent kafka
下面来看看Confluent kafka。Confluent kafka目前分为免费版和企业版两种。前者和Apache kafka非常相像,除了常规的组件之外,免费版还包含schema注册中心和rest proxy两大功能。前者是帮助你集中管理kafka消息格式以实现数据向前/向后兼容;后者用开放的HTTP接口的方式允许你通过网络访问kafka的各种功能,这两个都是Apache kafka所没有的。除此之外,免费版还包含了更多的连接器,它们都是Confluent公司开发并认证过的,你可以免费使用它们。至于企业版,它提供的功能就更多了,最有用的当属跨数据中心备份和集群监控两大功能了。多个数据中心之间数据的同步以及对集群的监控历来是kafka的痛点,Confluent kafka企业版提供了强大的解决方案来帮助你干掉它们。不过Confluent kafka没有发展国内业务的计划,相关资料以及技术支持都很欠缺,很多国内的使用者都无法找到对应的中文文档,因此目前Confluent kafka在国内的普及率是比较低的。
一言以蔽之,如果你需要使用kafka的一些高级特性,那么推荐你使用Confluent kafka。3.CDH/HDP kafka
最后说说大数据云公司发布的kafka,这些大数据平台天然继承了Apache kafka,通过便捷化的界面操作将kafka的安装、运维、管理、监控全部统一在控制台中。如果你是这些平台的用户一定觉得非常方便,因为所有的操作都可以在前段UI界面上完成,而不必执行复杂的kafka命令。另外这些平台的监控界面也非常友好,你通常不需要进行任何配置就能有效的监控kafka。
但是凡事有利就有弊,这样做的结果就是直接降低了你对kafka集群的掌握程度。毕竟你对下层的kafka集群一无所知,你怎么能够做到心中有数呢?这种kafka的另一个弊端在于它的滞后性,由于它有自己的发布周期,因此是否能及时地包含最新版本的kafka就成为了一个问题。比如CDH6.1.0版本发布时Apache kafka已经演进到了2.1.0版本,但CDH中的kafka仍然是2.0.0版本,显然那些在kafka2.1.0中修复的bug只能等到CDH下次版本更新时才有可能被真正修复。
简单来说,如果你需要快速的搭建消息引擎系统,或者你需要搭建的是多框架构成的数据平台且kafka只是其中的一个组件,那么建议使用这些大数据云公司提供的kafka。
小结
总结一下,我们今天讨论了不同的kafka"发行版"以及它们的优缺点,根据这些优缺点,我们可以有针对性地根据实际需求选择合适的kafka。最后我们回顾一下今天的内容:
Apache kafka,也成社区办kafka。优势在于迭代速度快,社区响应度高,使用它可以让你有更高的把控度;缺陷在于仅提供最基础的核心组件,缺失一些高级的特性。Confluent kafka,Confluent公司提供的kafka。优势在于集成了很多高级特性且由kafka原版人马打造,质量上有保证;缺陷在于相关资料不全,普及率较低,没有太多可供参考的范例。CDH/HPD kafka,大数据云公司提供的kafka,内嵌Apache kafka。优势在于操作简单,节省运维成本;缺陷在于把控度低,演进速度较慢。
聊聊kafka的版本号
今天聊聊kafka版本号的问题,这个问题实在是太重要了,我觉得甚至是日后能否用好kafka的关键。上一节我们介绍了kafka的几种发行版,其实不论是哪种kafka,本质上都内嵌了最核心的Apache kafka,也就是社区版kafka,那今天我们就说说Apache kafka版本号的问题。在开始之前,先强调一下,后面出现的所有"版本"这个词都表示kafka具体的版本号,而非上一节中介绍kafka种类,这一点要切记。
那么现在可能会有这样的疑问,我为什么要关心版本号的问题呢?直接使用最新版本不就好了吗?当然了,这的确是一种有效的版本选择的策略,但我想强调的是这种策略并非在任何场景下都适用。如果你不了解各个版本之间的差异和功能变化,你怎么能准确地评判某kafka版本是不是满足你的业务需求呢?因此在深入学习kafka之前,花些时间搞明白版本演进,实际上是非常划算的一件事。
kafka版本命名
当前Apache kafka已经迭代到2.2版本,社区正在为2.3.0发版日期进行投票,相信2.3.0也会马上发布。但是稍微有些令人吃惊的是,很多人对于kafka的版本命名理解存在歧义。比如我们在官网下载kafka时,会看到这样的版本。

于是有些人或许就会纳闷,难道kafka的版本号不是2.11或者2.12吗?其实不然,前面的版本号是编译kafka源代码的Scala编译器版本。kafka服务器端的代码完全由Scala语言编写,Scala同时支持面向对象编程和函数式编程,用Scala写的源代码编译之后也是普通".class"文件,因此我们说Scala是JVM系的语言,它的很多设计思想都是为人称道的。
事实上目前java新推出的很多功能都是在不断地向Scala靠近,比如lambda表达式、函数式接口、val变量等等。一个有意思的事情是,kafka新版客户端代码完全由java语言编写,于是有人展开了java vs Scala的讨论,并从语言特性的角度尝试分析kafka社区为什么放弃Scala转而使用java重写客户端代码。其实事情远没有那么复杂,仅仅是因为社区来了一批java程序员而已,而以前老的Scala程序员隐退罢了。可能有点跑题了,但是不管怎么样,我依然建议你有空学一学python语言。
回到刚才的版本号讨论,现在你应该知道了对于kafka-2.11-2.1.1的提法,真正的kafka版本号是2.1.1,那么这个2.1.1又表示什么呢?前面的2表示大版本号,即major version;中间的1表示小版本号或者次版本号,即minor version;最后的1表示修订版本号,也就是patch号。kafka社区在发布1.0.0版本后特意写过一篇文章,宣布kafka版本命名规则正式从4位演进到3位,比如0.11.0.0版本就是4位版本号。
kafka版本演进
于kafka目前总共演进了7个大版本,分别是0.7、0.8、0.9、0.10、0.11、1.0和2.0,其中的小版本和patch版本很多。哪些版本引入了哪些重大的功能改进?建议你最好做到如数家珍,因为这样不仅令你在和别人交谈时显得很酷,而且如果你要向架构师转型或者已然是架构师,那么这些都是能够帮助你进行技术选型、架构评估的重要依据。
我们先从0.7版本说起,实际上也没有什么可说的,这是最早开源时的上古版本了。这个版本只提供了最基础的消息队列功能,甚至连副本机制都没有,我实在想不出来有什么理由你要使用这个版本,因此如果有人要向你推荐这个版本,果断走开好了。
kafka从0.7时代演进到0.8之后正式引入了副本机制,至此kafka成为了一个真正意义上完备的分布式、高可靠消息队列解决方案。有了副本备份机制,kafka就能够比较好地做到消息无丢失。那时候生产和消费消息使用的还是老版本客户端的api,所谓老版本是指当你使用它们的api开发生产者和消费者应用时,你需要指定zookeeper的地址而非broker的地址。
如果你现在尚不能理解这两者的区别也没有关系,我会在后续继续介绍它们。老版本的客户端有很多的问题,特别是生产者api,它默认使用同步方式发送消息,可以想到其吞吐量一定不会太高。虽然它也支持异步的方式,但实际场景中消息有可能丢失,因此0.8.2.0版本社区引入了新版本producer api,即需要指定broker地址的producer。
据我所知,国内依然有少部分用户在使用0.8.1.1、0.8.2版本。我的建议是尽量使用比较新的版本,如果你不能升级大版本,我也建议你至少要升级到0.8.2.2这个版本,因为该版本中老版本消费者的api是比较稳定的。另外即使升级到了0.8.2.2,也不要使用新版本producer api,此时它的bug还非常的多。
时间来到了2015年11月,社区正式发布了0.9.0.0版本,在我看来这是一个重量级的大版本更迭,0.9大版本增加了基础的安全认证/权限功能,同时使用java重写了新版本消费者的api,另外还引入了kafka connect组件用于实现高性能的数据抽取。如果这么眼花缭乱的功能你一时无暇顾及,那么我希望你记住这个版本另一个好处,那就是新版本的producer api在这个版本中算比较稳定了。如果你使用0.9作为线上环境不妨切换到新版本producer,这是此版本一个不太为人所知的优势。但和0.8.2引入新api问题类似,不要使用新版本的consumer api,因为bug超级多,绝对用到你崩溃。即使你反馈问题到社区,社区也不管的,它会无脑的推荐你升级到新版本再试试,因此千万别用0.9新版本的consumer api。对于国内一些使用比较老的CDH的创业公司,鉴于其内嵌的就是0.9版本,所以要格外注意这些问题。
0.10.0.0是里程碑式的大版本,因为该版本引入了kafka streams。从这个版本起,kafka正式升级成为分布式流处理平台,虽然此时的kafka streams还不能上线部署使用。0.10大版本包含两个包含两个小版本:0.10.1和0.10.2,它们的主要功能变更都是在kafka streams组件上。如果把kafka作为消息引擎,实际上该版本并没有太多的功能提升。不过在我的印象中,自从0.10.2.2版本起,新版本consumer api算是比较稳定了。如果你依然在使用0.10大版本,那么我强烈建议你至少升级到0.10.2.2然后再使用新版本的consumer api。还有个事情不得不提,0.10.2.2修复了一个可能导致producer性能降低的bug。基于性能的缘故你也应该升级到0.10.2.2。
在2017年6月,社区发布了0.11.0.0版本,引入了两个重量级的功能变更:一个是提供幂等性producer api;另一个是对kafka消息格式做了重构。
前一个好像更加吸引眼球一些,毕竟producer实现幂等性以及支持事务都是kafka实现流处理结果正确性的基石。没有它们,kafka streams在做流处理时无法像批处理那样保证结果的正确性。当然同样是由于刚推出,此时的事务api有一些bug,不算十分稳定。另外事务api主要是为kafka streams应用服务的,实际使用场景中用户利用事务api自行编写程序的成功案例并不多见第二个改进是消息格式的变化。虽然它对用户是透明的,但是它带来的深远影响将一直持续。因为格式变更引起消息格式转换而导致的性能问题在生产环境中屡见不鲜,所以一定要谨慎对待0.11这个版本的变化。不得不说的是,在这个版本中,各个大功能组件都变得相当稳定了,国内该版本的用户也很多,应该算是目前最主流的版本之一了。也正是因为这个缘故,社区为0.11大版本特意退出了3个patch版本,足见它的受欢迎程度。我的建议是,如果你对1.0版本是否适用于线上环境依然感到困惑,那么至少将你的环境升级到0.11.0.3,因为这个版本的消息引擎功能已经非常完善了。
最后合并说一下1.0和2.0版本吧,因为在我看来这两个大版本主要还是kafka streams的各种改进,在消息引擎方面并未引入太多的重大功能特性。kafka streams的确在这两个版本有着非常大的变化,也必须承认kafka streams目前依然还在积极地发展着。如果你是kafka streams的用户,只要选择2.0.0版本吧。
去年8月国外出了一本书叫做kafka streams in action,中文译名:kafka streams实战,它是基于kafka streams1.0版本撰写的,但是用2.0版本去运行书中的很多例子,居然很多都已经无法编译了,足见两个版本的差别之大。不过如果你在意的依然是消息引擎,那么这两个大版本都是可以用于生产环境的。
最后还有个建议,不论你使用的是哪个版本,都请尽量保持服务器端版本和客户端版本一致,否则你将损失很多kafka为你提供的性能优化收益。
kafka线上集群部署方案怎么做
前面几节,我们分别从kafka的定位,版本的变迁以及功能的演进等方面循序渐进地梳理了Apache kafka的发展脉络。那么现在我们就来看看生产环境中的kafka集群方案该怎么做。既然是集群,那必然就要有多个kafka节点机器,因为只有单台机器构成的kafka伪集群只能用于日常测试之用,根本无法满足实际的线上生产需求。而真正的线上环境需要仔细地考量各种因素,结合自身的业务需求而制定。下面我们就从操作系统、磁盘、磁盘容量和带宽等方面来讨论一下。
操作系统:
这个不多BB,果断选择linux。至于为什么?主要是在以下这三个方面
I/O模型的使用什么是I/O模型,可以近似的认为是操作系统执行I/O指令的方法。主流的I/O模型有五种:阻塞式I/O,非阻塞式I/O,I/O多路复用,信号驱动I/O,异步I/O。每种I/O模型都有各自的使用场景,但我们想要支持高并发的话,都会选择I/O多路复用,至于异步I/O,由于操作系统支持的不完美,所以不选择。对于I/O多路复用有三种,select、poll、epoll,epoll是在linux内核2.4中提出的,对于I/O轮询可以做到效率最大化,至于这三者的具体关系就不详细介绍了,只需要知道epoll"最好"就行了。说了这么多,那么I/O模型和kafka又有什么关系呢?实际上kafka客户端底层使用java的selector,selector会自动从select、poll、epoll中选择一个,而Windows只支持select。因此在这一点上linux是有优势的,因为能够获得更高效的I/O性能。
数据网络传输效率首先kafka生产和消费的消息都是通过网络传输的,而消息保存在哪里呢?肯定是磁盘,故kafka需要在磁盘和网络之间进行大量数据传输。如果你熟悉linux,那么你肯定听说过零拷贝(zero copy)技术,就是当数据在磁盘和网络进行传输时避免昂贵的内核态数据拷贝从而实现快速的数据传输。linux平台实现了这样的零拷贝机制,但有些遗憾的是在Windows平台上必须等到java8的60更新版本才能享受这个福利。一句话总结一下,在linux部署kafka能够享受到零拷贝技术所带来的快速数据传输特性。
社区支持度最后是社区支持度,这一点虽然不是什么明显的差别,但如果不了解的话,所造成的影响可能会比前两个因素更大。简单的来说,就是社区目前对Windows平台上发现的bug不做任何承诺。因此Windows平台上部署kafka只适合于个人测试或用于功能验证,千万不要用于生产环境。
磁盘:
如果要问哪种资源对kafka性能最重要,磁盘无疑是要排名靠前的。在对kafka集群进行磁盘规划时经常要面对的问题是,我应该选择普通的机械磁盘还是固态硬盘?前者成本低且容量大,但易损坏;后者性能优势大,不过单价高。个人建议:使用普通的机械硬盘即可。
kafka大量使用磁盘不假,可它使用的方式是多顺序读写操作,一定程度上规避了机械磁盘最大的劣势,即随机读写操作慢。从这一点上,使用ssd似乎没有太大的性能优势,毕竟从性价比是哪个来说,机械磁盘物美价廉,而它因易损坏而造成的可靠性差等缺陷,又有kafka在软件层面提供机制来保证,故使用普通机械磁盘是很划算的
关于磁盘选择另一个常常讨论的话题,到底是否应该使用磁盘阵列(raid)。使用磁盘阵列的两个优势在于:
提供冗余的磁盘存储空间提供负载均衡
以上两个优势对于任何一个分布式系统都很有吸引力。不过就kakfa而言,一方面kafka自己实现了冗余机制来提供高可靠性;另一方面通过分区的概念,kafka也能在软件层面自行实现负载均衡。如此一来磁盘阵列的优势就没有那么明显了,当然并不是说磁盘阵列不好,实际上依然有很多大厂是把确实是把kafka底层的存储交给磁盘阵列的,只是目前kafka在存储这方面提供了越来越便捷的高可靠性方案,因此在线上环境使用磁盘阵列似乎变得不那么重要了。综合以上的考量,个人给出的建议是:
追求性价比的公司可以不搭建磁盘阵列,使用普通磁盘组成存储空间即可。使用机械磁盘完全能够胜任kafka线上环境。
磁盘容量:
kafka集群到底需要多大的存储空间,这是一个非常经典的规划问题。kafka需要将消息保存在底层的磁盘上,这些消息默认会被保存一段时间然后自动被删除。虽然这段时间是可以配置的,但你应该如何结合自身业务场景和存储需求来规划kafka集群的存储容量呢?
我举一个简单的例子来说明如何思考这个问题,假设你所在公司有个业务每天需要向kafka集群发送1亿条消息,每条消息保存两份以防止数据丢失,另外消息默认保存两周时间。现在假设消息的平均大小是1KB,那么你能说出你的kafka集群需要为这个业务预留多少磁盘空间吗?
我们来计算一下,每天1亿条1KB大小的消息,保存两份且存两周的时间,那么总的空间大小就等于1亿 * 1KB * 2/ 1024 / 1024 。一般情况下,kafka集群除了消息数据还有其他类型的数据,比如索引数据等,因此我们需要再为这些数据预留出10%的磁盘空间,因此我们在原来的基础上乘上1.1,既然要保存两周,那么再乘上14,那么整体容量大概为21.5TB左右。由于kafka支持数据的压缩 ,假设数据的压缩比是0.75,那么最后你需要规划的存储空间是21.5 * 0.75=16.14TB左右。
总之在规划磁盘容量时你需要考虑下面这几个元素:
新增消息数消息留存时间平均消息大小备份数是否启用压缩
带宽:
对于kafka这种通过网络进行大量数据传输的框架而言,带宽特别容易成为瓶颈。事实上,在真实案例当中,带宽资源不足导致kafka出现性能问题的比例至少占60%以上。如果你的环境中还要涉及跨机房传输,那么情况情况可能更糟糕了。
如果你不是超级土豪的话,我会认为你使用的是普通的以太网,带宽也主要有两种:1Gbps的千兆网络,和10Gbps的万兆网络,特别是千兆网络应该是一般公司网络的标准配置了。下面我就以千兆网举一个实际的例子,来说明一下如何进行带宽资源的规划。
与其说是带宽资源的规划,其实真正要规划的是所需的kafka服务器的数量。假设你公司的机房环境是千兆网络,即1Gps,现在你有个业务,其业务目标或SLA是在1小时内处理1TB的业务数据。那么问题来了,你到底需要多少台kafka服务器来完成这个业务呢?
让我们来计算一下,由于带宽是1Gps,即每秒处理1Gb的数据,假设每台kafka服务器都是安装在专属的机器上,也就是说每台kafka机器上没有混布其他服务,但是真实环境中不建议这么做。通常情况下你只能假设kafka会用到70%的资源,因为总要为其他应用或者进程留一些资源。根据实际使用经验,超过70%的阈值就有网络丢包的可能性了,故70%的设定是一个比较合理的值,也就是说单台kafka服务器最多也就能使用700Mb的带宽资源。
稍等,这只是它能使用的最大带宽资源,你不能让kafka服务器常规性地使用这么多资源,故通常要再额外留出2/3的资源,即单台服务器使用带宽为700/3≈233MBps。需要提示的是,这里的2/3是相当保守的,你可以结合自己机器的使用情况酌情减少此值。
好了,有了240MBps,我们就可以计算1小时内处理1TB数据所需要的服务器数量了。根据这个目标,我们每秒需要处理1TB / 3600s * 8 ≈ 2336MB的数据,除以240,约等于10台服务器。如果消息还需要额外复制两份,那么总的服务器台数还要乘以3,即30台。
kafka的安装&启动&关闭
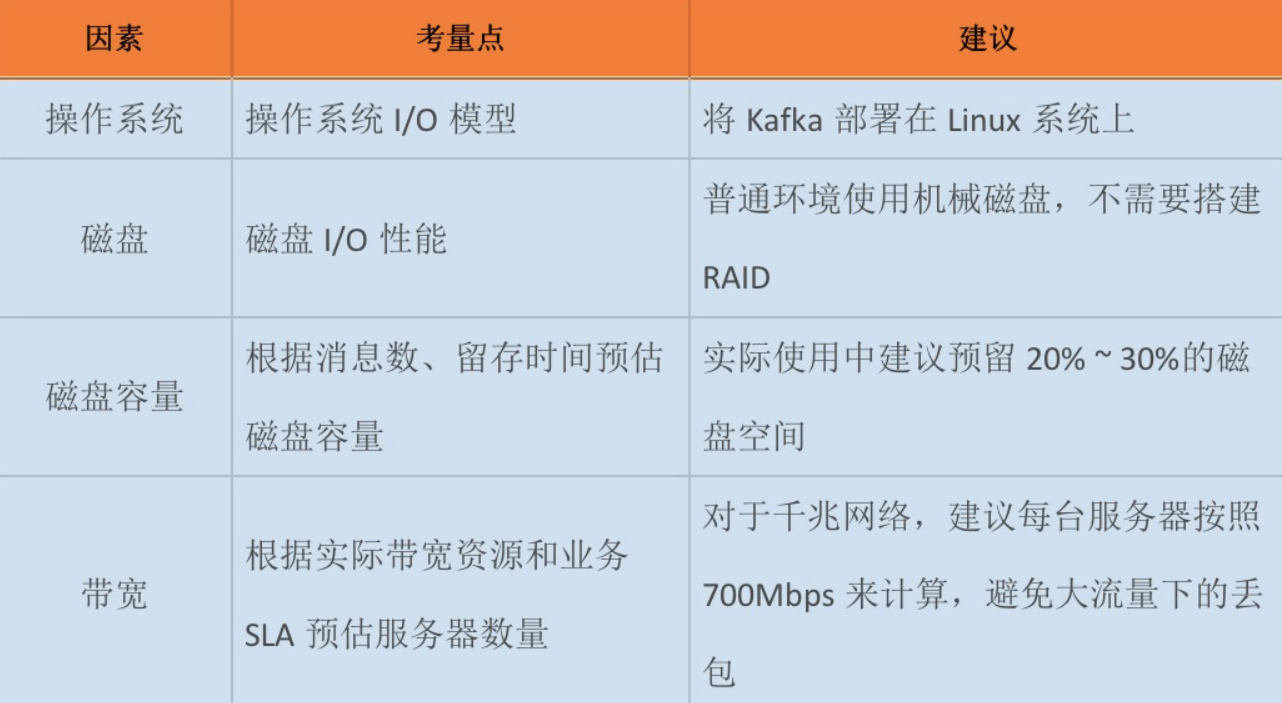
下面我们就来安装kafka,这里我们选择的版本为kafka_2.12-2.2.1,安装在/opt/kafka目录下,然后配置环境变量,source一下
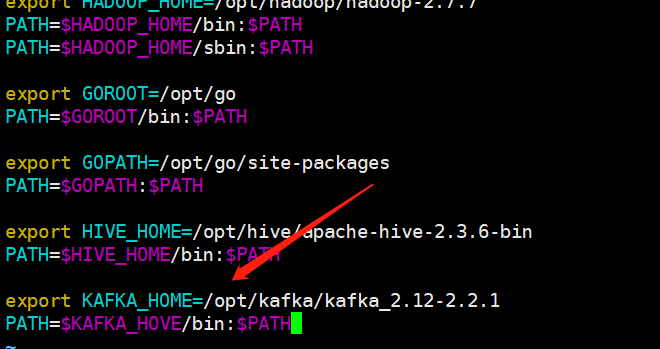

kafka的目录结构如下
先来看看kafka的配置文件吧
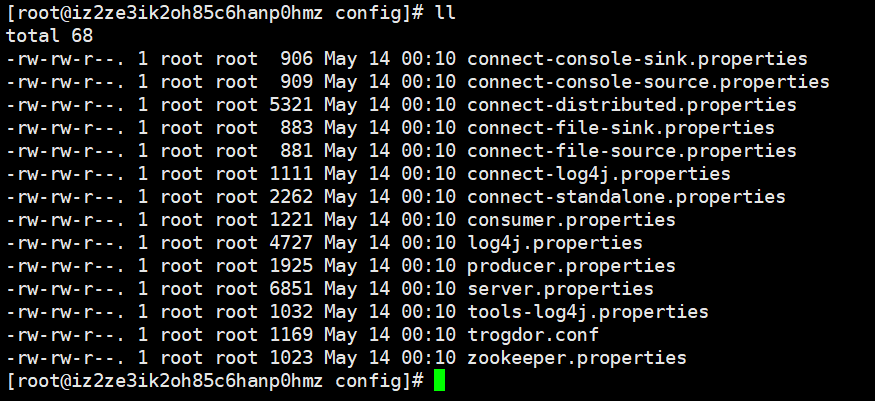
sink、source显然是和flume有关的。consumer、producer则是通过命令行启动消费者、生产者,这个是做测试用的,但是我们一般都在代码中写配置。下面还有一个zookeeper,不过这个zookeeper我们不用管,因为这是kafka自带的zookeeper,我们都用自己的zookeeper。比较重要的是,那么server.properities,我们来看一下。
# The id of the broker. This must be set to a unique integer for each broker.
# broker的唯一id,对于每一个broker都必须设置为唯一的"整数",另一台broker的话,broker.id=1
broker.id=0
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
# 监听端口9092
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
# 服务用于接收来自网络的请求以及向网络发送响应的线程数
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
# 服务用于处理请求的线程数、可能包含磁盘IO
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
# socket服务端用于发送数据的缓存,意思是当数据到达指定的缓存之后才发送
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
# socket服务端用于接收数据的缓存,意思是当数据达到指定的缓存之后才读取
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
# socket服务允许接收的请求的最大字节数
socket.request.max.bytes=104857600
# 以上都是默认配置,我们就不改了
# A comma separated list of directories under which to store log files
# 用逗号分隔的一系列文件路径,用于存储日志文件
# 注意:其实不止日志文件,还有暂存数据,也存在这里面。都叫做log,这一点容易混淆,务必记住
log.dirs=/tmp/kafka-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
# 每一个注意的分区数,下面都不用管
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
# 用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended for to ensure availability such as 3.
# 副本系数等等
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
# 每一个日志段的最大字节,换算之后是一个G
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
# segment保留的最长时间,超时将被删除
log.retention.check.interval.ms=300000
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
# 配置连接zookeeper的地址,如果多个zookeeper的话,那么就用逗号分割
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
# 连接zookeeper的最大超时时间
zookeeper.connection.timeout.ms=6000
我们再来看一下,bin目录
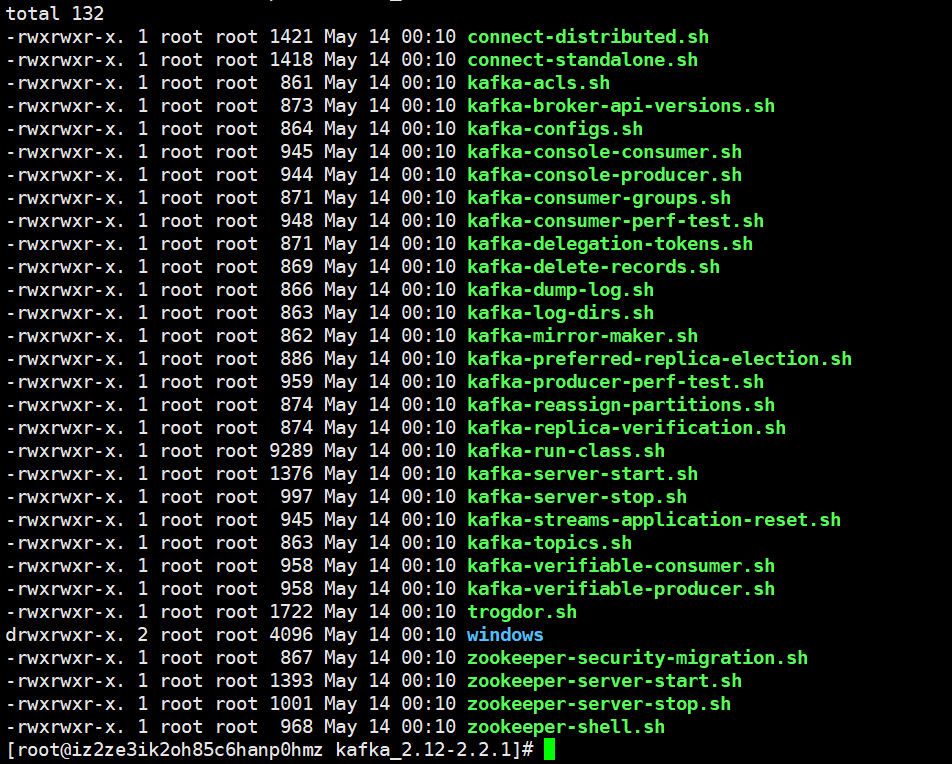
有五个sh脚本是比较常用的,kafka-console-consumer.sh、kafka-console-producer.sh,这两个是在控制台启动的,用于测试。kafka-server-start.sh、kafka-server-stop.sh,这两个是启动kafka集群的。kafka-topics.sh,这个是与主题相关的,可以对主题进行相关操作。
启动kafka:bin]# ./kafka-server-start.sh ../config/server.properties,我是在bin目录下启动的,注意启动的时候需要指定配置文件,就是我们刚才配的server.properties。但是注意的是,这样启动的话,进程是一个阻塞的,如果想进行别的操作,只能单独开一个终端了,因此我们可以以守护进程的方式启动:bin]# ./kafka-server-start.sh -daemon ../config/server.properties。不过还有一点需要注意:那就是我们指定了zookeeper,是不是要先启动zookeeper呢?没错,zkServer.sh start,启动之后才能启动kafka,否则就会连接zookeeper超时,从而导致启动失败
关闭kafka:bin]# ./kafka-server-stop.sh ../config/server.properties,关闭的时候就不需要指定-daemon这个参数了。
命令行操作topic增删查
查看所有topic
kafka-topics.sh --list --zookeeper localhost:2181

可以看到,由于我们还没有创建,所以此时还没有主题。
创建topic:
kafka-topics.sh --create --zookeeper localhost:2181 --topic 主题名 --partitions 分区数 --replication-factor 副本数
注意:副本数不能超过你broker的数量,因为我们只有一台机器,所以副本数是1,但是分区在一台broker上是可以有多个的

删除topic:
kafka-topics.sh --delete --zookeeper localhost:2181 --topic 主题名

这里提示我们,如果没有将delete.topic.enable设置为true,那么这个分区不会被删除,但是satori这个主题已经被标记为删除了。我们看看,就知道了,或者说再创建一个satori,如果存在会报错的。

可以看到,这个分区是真的被删除了。
查看topic信息:
kafka-topics.sh --describe --zookeeper localhost:2181 --topic 主题名

命令行控制台生产者消费者测试
启动生产者:
kafka-console-producer.sh --topic 主题 --broker-list localhost:9092,注意这里是--broker-list,也就是broker的地址

启动消费者:
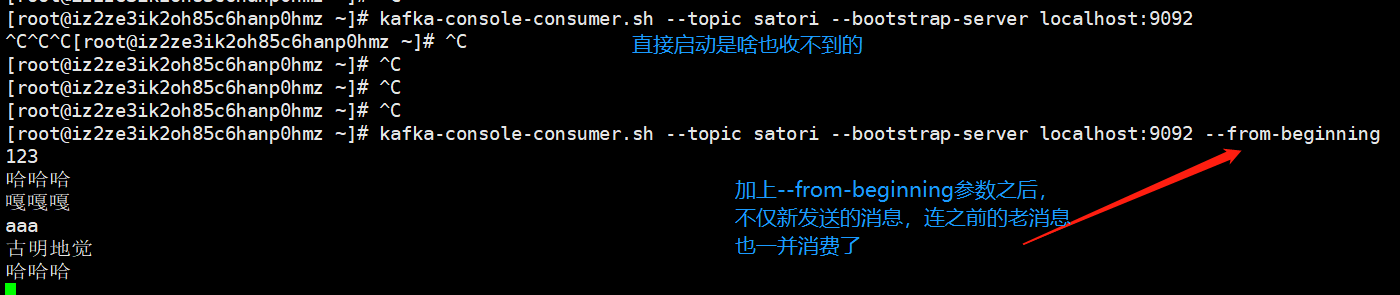
kafka-console-consumer.sh --topic 主题 --bootstrap-server localhost:9092

此时消费者卡在了这个地方,等待生产者生产数据。


数据默认保留7天,超过7天就会删除。但是还有一个问题,要是消费者启动之前,生产生产消息了,怎么办?显然此时的消费者是接收不到的,因此我们可以加上一个--from-beginning参数,这样的话就可以把消息全部消费掉。

关闭消费者之后,生产者又生产了两条消息,然后启动消费者。
(持续更新中~~~)kafka--消息引擎与分布式流处理平台的更多相关文章
- 史上最全的spark面试题——持续更新中
史上最全的spark面试题——持续更新中 2018年09月09日 16:34:10 为了九亿少女的期待 阅读数 13696更多 分类专栏: Spark 面试题 版权声明:本文为博主原创文章,遵循C ...
- java视频教程 Java自学视频整理(持续更新中...)
视频教程,马士兵java视频教程,java视频 1.Java基础视频 <张孝祥JAVA视频教程>完整版[RMVB](东西网) 历经5年锤炼(史上最适合初学者入门的Java基础视频)(传智播 ...
- 《WCF技术剖析》博文系列汇总[持续更新中]
原文:<WCF技术剖析>博文系列汇总[持续更新中] 近半年以来,一直忙于我的第一本WCF专著<WCF技术剖析(卷1)>的写作,一直无暇管理自己的Blog.在<WCF技术剖 ...
- 中国.NET:各地微软技术俱乐部汇总(持续更新中...)
中国.NET:各地微软技术俱乐部汇总(持续更新中...) 本文是转载文,源地址: https://www.cnblogs.com/panchun/p/JLBList.html by 史记微软. ...
- Pig基础学习【持续更新中】
*本文参考了Pig官方文档以及已有的一些博客,并加上了自己的一些知识性的理解.目前正在持续更新中.* Pig作为一种处理大规模数据的高级查询语言,底层是转换成MapReduce实现的,可以作为MapR ...
- Pig语言基础-【持续更新中】
***本文参考了Pig官方文档以及已有的一些博客,并加上了自己的一些知识性的理解.目前正在持续更新中.*** Pig作为一种处理大规模数据的高级查询语言,底层是转换成MapReduce实现的, ...
- 【前端】Util.js-ES6实现的常用100多个javaScript简短函数封装合集(持续更新中)
Util.js (持续更新中...) 项目地址: https://github.com/dragonir/Util.js 项目描述 Util.js 是对常用函数的封装,方便在实际项目中使用,主要内容包 ...
- 白话kubernetes的十万个为什么(持续更新中...) - kubernetes
Kubernetes简称? 答:k8s或kube. Kubernetes是什么? 答:由Google开发的一个强大的平台,可以在集群环境中管理容器化应用程序.本质上是一种特殊的数据库,里面存储的是能够 ...
- PTA|团体程序设计天梯赛-练习题目题解锦集(C/C++)(持续更新中……)
PTA|团体程序设计天梯赛-练习题目题解锦集(持续更新中) 实现语言:C/C++: 欢迎各位看官交流讨论.指导题解错误:或者分享更快的方法!! 题目链接:https://pintia.cn/ ...
随机推荐
- 阶段3 3.SpringMVC·_03.SpringMVC常用注解_8 SessionAttributes注解
SpringMvc提供的Model类 ModelMap继承LinkedHashMap 页面取值 把request这个对象全部输出了. SessionAttribute 取值 从sessionAttri ...
- 重置csr
重置csr 注意:下面操作仅在刚安装k8s后24小时内有效 分析:kubelet启动后会生成如下文件.kubelet.conf文件决定了csr的存在,如果要想重新获取csr,可以停掉kubelet,删 ...
- python定位隐藏元素
定位隐藏要素的原理: 页面主要通过“display:none”来控制元素不可见.所以我们需要通过javaScript修改display的值得值为display="block,来实现元素定位的 ...
- 如何在robotframework基础上使用数据驱动测试
一.写在前面 robotframework是很好用的关键字驱动测试框架,但是在实际工作中也有些地方使用不便,比如在我们设计参数校验测试case时,往往只是想修改校验参数类型而不得不做大量复制粘贴操作, ...
- 守护进程,互斥锁, IPC ,Queue队列,生产消费着模型
1.守护进程 什么是守护进程? 进程是一个正在运行的程序 守护进程也是一个普通进程,意思是一个进程可以守护另一个进程,比如如果b是a的守护进程,a是被守护的进程,如果a进程结束,b进程也会随之结束. ...
- 应用安全 - JavaScript - 框架 - Jquery - 漏洞 - 汇总
jQuery CVE-2019-11358 Date 类型 原型污染 影响范围 CVE-2015-9251 Date 类型跨站 影响范围<jQuery 3.0.0
- mybatis学习(一)不使用 XML 构建 SqlSessionFactory
如果使用 Maven 来构建项目,则需将下面的 dependency 代码置于 pom.xml 文件中: <dependency> <groupId>org.mybatis&l ...
- Python 入门 之 print带颜色输出
Python 入门 之 print带颜色输出 1.print带颜色输出书写格式: 开头部分: \033[显示方式; 前景色 ; 背景色 m 结尾部分: \033[0m 详解: 开头部分的三个参数: 显 ...
- VUE(下)
VUE(下) VUE指令 表单指令 数据的双向指令 v-model = "变量" model绑定的变量,控制的是表单元素的value值 普通表单元素用v-model直接绑定控制va ...
- JS中this的4种绑定规则
this ES6中的箭头函数采用的是词法作用域. 为什么要使用this:使API设计得更简洁且易于复用. this即不指向自身,也不指向函数的词法作用域. this的指向只取决于函数的调用方式 thi ...