什么是Familywise Error Rate
1.什么是Familywise Error Rate(FWE or FWER)
定义:在一系列假设检验中,至少得出一次错误结论的概率。
换句话说,是造成至少一次Type I Error的概率。术语FWE来自测试系列,这是一系列数据测试的技术定义
2.估计FWE的公式
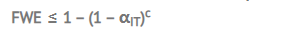
- αIT:一个独立测试的显著水平
- c : 对比次数
举个例子,对于一个10次试验的的序列,显著水平5%,FWE = ≤ 1 – (1 – .05)^10 = 0.401 ,这意味着Type I Error 发生的概率超过了40%,对于只有10次试验而言,是非常高的
3.控制FWE
单步执行,Bonferroni校正
单步程序对每个p值进行相同的调整。这保持了整个alpha水平保持在期望值(例如..05)。该方法被称为被称为Bonferroni校正。
1. 将alpha级别除以正在运行的测试的数量,并将该alpha级别应用于每个单独的测试。例如,如果您的整体alpha水平是.05,并且您正在运行5个测试,那么每个测试的alpha水平将是.05/5=.01。
2. 在每个测试中应用新的alpha级别来查找p值。在本例中,p值必须小于或等于0.01才具有统计意义。
多步执行
Similar to Bonferroni, but makes adaptive adjustments to each p-value. Several sequential methods exist. The easiest is probably the Holm-Bonferroni Method, but several others have been developed including the Sidak-Bonferroni and Holland-Copenhaver.
- Holm-Bonferroni: tests are run and then ordered from lowest to highest p-values. The individual tests are then tested (starting with the one with the lowest p-value) with an overall Bonferroni correction for all tests. See: Holm-Bonferroni Method for a step-by-step example.
- Sidak-Bonferroni (sometimes called the Boole or Dunn approximation): a variant of Bonferroni which uses a Taylor expansion (from calculus)
Type I Error
Type I Error 就是错误地拒绝了一个真实的零假设Ho(null hypothesis)(应该接受的)
null hypothesis :普遍接受的假设
Ho是一个普遍接受的假设;它与备择假设相反。研究人员提出了另一种假设,他们认为这种假设解释了一种现象,然后努力拒绝零假设。
Type II Error
Il型错误(有时称为2型错误)是拒绝虚假零假设的失败。类型ll错误的概率用符号B表示。
reference:https://www.statisticshowto.datasciencecentral.com/familywise-error-rate/
什么是Familywise Error Rate的更多相关文章
- [ZZ] Equal Error Rate (EER)
这篇博客很全面 http://www.cnblogs.com/cdeng/p/3471527.html ROC曲线 1.混淆矩阵(confusion matrix) 针对预测值和真实值之间的关系,我们 ...
- ImageNet: what is top-1 and top-5 error rate?
https://stats.stackexchange.com/questions/156471/imagenet-what-is-top-1-and-top-5-error-rate Your cl ...
- 一张图,关于 Bayes error rate,贝叶斯错误率等的分析
造轮子是那帮搞研究的“科学家”干的事情(类似E&E里的explore),“工程师”的职责是利用已有的东西解决问题(类似E&E里的exploit). 其次,即使以工程师的角色解决业务问题 ...
- 假设检验:p-value,FDR,q-value
来源:http://blog.sina.com.cn/s/blog_6b1c9ed50101l02a.html,http://wenku.baidu.com/link?url=3mRTbARl0uPH ...
- FDR
声明: 网上摘抄 False discovery rate (FDR) control is a statistical method used in multiple hypothesis test ...
- Omnibus test
sklearn实战-乳腺癌细胞数据挖掘(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005269003&a ...
- P<0.05就够了?还要校正!校正!3个方法献上
P<0.05就够了?还要校正!校正!3个方法献上 (2017-01-03 17:55:12) 转载▼ 分类: 数理统计 (转 医生科研助手 解螺旋 微信公众号) 当有多组数据要比较时, ...
- Holm–Bonferroni method
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
- Turkey HSD检验法/W法
sklearn实战-乳腺癌细胞数据挖掘(博主亲自录视频) https://study.163.com/course/introduction.htm?courseId=1005269003&u ...
随机推荐
- 1. Tomcat之startup.sh
#判断操作系统os400=falsecase "`uname`" inOS400*) os400=true;;esac # 取脚本名称PRG="$0" # 判断 ...
- QML按键
1.普通用法 import QtQuick 2.9 import QtQuick.Window 2.2 import QtQuick.Controls 2.2 ApplicationWindow { ...
- 安卓 android studio 报错 Could not find com.android.tools.build:gradle:3.2.1.
报错截图如下: 解决方法:在project的builde.gradle做如下操作分别加上google()
- DEBUG技巧里的问题1 双击某个变量不能显示
DEBUG模式 双击 ls_return-type 变量不能显示,提示警告消息 好像说明的不是这个问题, 把字段复制到右边的变量框里可以显示 这个确实有点奇怪了
- 【翻译】Flink Table Api & SQL ——Streaming 概念
本文翻译自官网:Streaming 概念 https://ci.apache.org/projects/flink/flink-docs-release-1.9/dev/table/streamin ...
- Python - Django - 静态文件相关
静态文件的路径设置在 settings.py 中 如果该路径发生更改的话,html 中相关路径也要进行修改 CSS: <link href="/static/dashboard.css ...
- (十四)访问标志 Access_flags
一.概念 上一章节讲到了常量池,如下图,常量池之后便是访问标志acess_flags,占2个字节(u2). 二.例子 编写一个接口. public interface Test{ public fin ...
- MySQL修改表名示例
首先,我们新建一个名为test_table的表: drop table if exists test_table; create table test_table select TABLE_SCHEM ...
- LODOP打印超文本保留背景色带平铺水印
前面的博文:LODOP中设置设置图片平铺水印,超文本透明. 介绍过 ,如果不想去掉超文本的背景色,想在超文本背景色和超文本内容文字之间加上水印,让水印在背景色上面,文字下面,是不行的,因为平铺的图片和 ...
- python 爬虫实例(四)
环境: OS:Window10 python:3.7 爬取链家地产上面的数据,两个画面上的数据的爬取 效果,下面的两个网页中的数据取出来 代码 import datetime import threa ...