Java日志体系(二)log4j
1.1 简介
Log4j是一个由Java编写可靠、灵活的日志框架,是Apache旗下的一个开源项目;
使用Log4j,我们更加方便的记录了日志信息,它不但能控制日志输出的目的地,也能控制日志输出的内容格式;通过定义不同的日志级别,可以更加精确的控制日志的生成过程,从而达到我们应用的需求;这一切,都得益于一个灵活的配置文件,并不需要我们更改代码。
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
Log4j 1.x已达到使用寿命。建议用户使用Log4j 1升级到Apache Log4j 21.2 log4j结构
在Log4j中,主要由三个重要组件构成:
Logger:日志对象,负责捕捉日志记录信息;
Logger对象是用来取代System.out或者System.err的日志输出器,负责日志信息的输出;其中,log4j日志框架提供了info、error、debug等API供Developer使用; 与commons-logging相同,log4j也有日志等级的概念;每一个logger对象都会分配一个等级,未被分配等级的logger则继承根logger的级别,进行日志的输出;每个日志对象方法的请求也有一个等级,如果方法请求的等于大于当前logger对象的等级,则该请求会被处理输出,否则该请求被忽略; log4j在Level类中定义了7个等级,关系如下:
Level.ALL < Level.DEBUG < Level.INFO < Level.WARN < Level.ERROR < Level.FATAL < Level.OFF 每个等级,具体含义如下:
ALL:打开所有日志;
DEBUG:适用于代码调试期间;
INFO:适用于代码运行期间;
WARN:适用于代码会有潜在错误事件;
ERROR:适用于代码存在错误事件;
FATAL:适用于严重错误事件;
OFF:关闭所有日志;
Appender:日志输出目的地,负责把格式好的日志信息输出到指定地方,可以是控制台、磁盘文件等;
每个日志对象,都有一个对应的appender,每个appender代表着一个日志输出目的地; 其中,log4j有以下几种appender可供选择:
ConsoleAppender:控制台;
FileAppender:磁盘文件;
DailyRollingFileAppender:每天产生一个日志磁盘文件;
RollingFileAppender:日志磁盘文件大小达到指定尺寸时产生一个新的文件;
- Layout:日志格式化器,负责发布不同风格的日志信息;
每个appender和一个Layout相对应,appende负责把日志信息输出到指定的地点,而Layout则负责把日志信息按照格式化的要求展示出来; 其中,log4j有以下几种Layout可供选择:
HTMLLayout:以html表格形式布局展示;
PatternLayout:自定义指定格式展示;
SimpleLayout:包含日志信息的级别和信息字符串;
TTCCLayout:包含日志产生的时间、线程、类别等等信息;
1.3 使用
首先,需要在应用的pom.xml中添加依赖:
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
其次,声明测试代码:
public class log4jDemo {
Logger log= Logger.getLogger(log4jDemo.class);
@Test
public void test(){
log.trace("Trace Message!");
log.debug("Debug Message!");
log.info("Info Message!");
log.warn("Warn Message!");
log.error("Error nihao 你好!");
log.fatal("Fatal Message!");
}
}
最后,在classpath下声明配置文件:log4j.properties 或者 log4j.xml;
例1:log4j.properties:
log4j.rootLogger = INFO, FILE, CONSOLE log4j.appender.FILE=org.apache.log4j.FileAppender
log4j.appender.FILE.File=e:/log.out
log4j.appender.FILE.ImmediateFlush=true
log4j.appender.FILE.Threshold = DEBUG
log4j.appender.FILE.Append=true
log4j.appender.FILE.layout=org.apache.log4j.PatternLayout
log4j.appender.FILE.layout.conversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n log4j.appender.CONSOLE=org.apache.log4j.ConsoleAppender
log4j.appender.CONSOLE.Target=System.out
log4j.appender.CONSOLE.ImmediateFlush=true
log4j.appender.CONSOLE.Threshold = DEBUG
log4j.appender.CONSOLE.layout=org.apache.log4j.PatternLayout
log4j.appender.CONSOLE.encoding=UTF-8
log4j.appender.CONSOLE.layout.conversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
例2:log4j.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE log4j:configuration SYSTEM "log4j.dtd">
<log4j:configuration> <appender name="CONSOLE" class="org.apache.log4j.ConsoleAppender">
<param name="target" value="System.out"/>
<param name="immediateFlush" value="true"/>
<param name="threshold" value="DEBUG"/>
<param name="append" value="true"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d - %c -%-4r [%t] %-5p %x - %m%n" />
</layout>
</appender> <appender name="FILE" class="org.apache.log4j.FileAppender">
<param name="File" value="e:/log.out" />
<param name="ImmediateFlush" value="true"/>
<param name="Threshold" value="DEBUG"/>
<param name="Append" value="true"/>
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{ABSOLUTE} %5p %c{1}:%L - %m%n" />
</layout>
</appender> <category name="com.jiaboyan" additivity="false">
<level value="error"></level>
<appender-ref ref="CONSOLE" />
</category> <root>
<priority value="info" />
<appender-ref ref="CONSOLE" />
<appender-ref ref="FILE" />
</root> </log4j:configuration>
通过以上步骤,log4j就可以正常的运行了。
1.4 log4j配置文件详解
接下来,具体讲解下log4j配置文件中的各个属性:(以log4j.properties为例讲解);
Logger
配置根Logger,其语法为:
log4j.rootLogger = [ level ] , appenderName, appenderName, … 其中,level指的是根logger对象的日志等级,Log4j建议只使用4个级别,从高到低分别为ERROR > WARN > INFO > DEBUG;
appenderName指的是根logger对象的日志信息输出目的地,在此可以指定多个输出目的地; 举例:
log4j.rootLogger = INFO, FILE, CONSOLE
- Appender
配置日志信息输出目的地Appender,其语法为:
log4j.appender.appenderName = className 其中,appenderName指的是日志信息输出目的地的名称,可自定义,需要与根Logger中的appenderName一致;
className指的是日志输出目的地处理类,必须为全限定类名; 举例1:
log4j.appender.FILE = org.apache.log4j.FileAppender(将日志信息输出到对应的磁盘文件中);
关于FileAppender的其余选项:
log4j.appender.FILE.Threshold = DEBUG(指定日志输出的最低级别,默认为DEBUG;如果日志请求的级别低于此级别,则不会输出此请求日志信息)
log4j.appender.FILE.File=e:/mylog.log (将日志输出到e盘的mylog.log文件中)
log4j.appender.FILE.Encoding=UTF-8(设置日志输出的编码)
log4j.appender.FILE.Append=false(将新增日志追加到文件中,默认为true,false为覆盖)
log4j.appender.FILE.ImmediateFlush=true(请求的日志消息被立即输出,默认为true)
log4j.appender.FILE.BufferedIO=true(请求的日志消息不会立即输出,存储到缓存当中,当缓存满了后才输出到磁盘文件中,默认为false,此时ImmediateFlush应当设置为false)
log4j.appender.FILE.BufferSize= 8192(缓存大小,默认为8k) 举例2:
log4j.appender.CONSOLE = org.apache.log4j.ConsoleAppender(将日志信息输出到控制台中)
关于ConsoleAppender的其余选项:
log4j.appender.CONSOLE.Target=System.out(将日志信息使用System.out.println输出到控制台)
log4j.appender.CONSOLE.ImmediateFlush=true(同上)
log4j.appender.CONSOLE.Threshold = DEBUG(同上)
log4j.appender.CONSOLE.encoding=UTF-8(设置日志信息输出编码) 举例3:
log4j.appender.DRFILE = org.apache.log4j.DailyRollingFileAppender(将输出的日志信息,每天产生一个日志文件,与上面FileAppender不同)
关于DailyRollingFileAppender的其余选项:
log4j.appender.DRFILE.File=e:/log.out(同上);
log4j.appender.DRFILE.ImmediateFlush=true(同上);
log4j.appender.DRFILE.Threshold = DEBUG(同上);
log4j.appender.DRFILE.Append=true(同上);
log4j.appender.DRFILE.DatePattern='.'yyyy-MM-dd(标识每天产生一个新的日志文件,当然也可以指定按月、周、时、分);具体格式如下:
1)'.'yyyy-MM: 每月
2)'.'yyyy-ww: 每周
3)'.'yyyy-MM-dd: 每天
4)'.'yyyy-MM-dd-a: 每天两次
5)'.'yyyy-MM-dd-HH: 每小时
6)'.'yyyy-MM-dd-HH-mm: 每分钟 举例4:
log4j.appender.RFILE = org.apache.log4j.RollingFileAppender(在日志文件达到指定的大小后,再产生新的文件继续记录日志)
关于RollingFileAppender的其余选项:
log4j.appender.RFILE.Threshold = DEBUG(同上)
log4j.appender.RFILE.File=e:/mylog.log (同上)
log4j.appender.RFILE.encoding=UTF-8(同上)
log4j.appender.RFILE.Append=false(同上)
log4j.appender.RFILE.ImmediateFlush=true(同上)
log4j.appender.RFILE.MaxFileSize=100KB(指定日志文件切割大小,默认10MB,单位KB/MB/GB;当日志文件达到指定大小后,将当前日志文件内容剪切到新的日志文件中,新的文件默认以“原文件名+.1”、“原文件名+.2”的形式命名)
log4j.appender.RFILE.MaxBackupIndex=2(产生的切割文件最大数量,如果第二个文件超过了指定大小,那么第一个文件将会被删除)
- Layout
配置日志信息的格式Layout,其语法为:
log4j.appender.appenderName.layout = className 其中,appenderName就是上面所讲的Appender的名称,Appender必须与Layout相互绑定;
而className则是处理日志格式的类,也必须是全限定类名; 举例1:
log4j.appender.FILE.layout = org.apache.log4j.HTMLLayout(以html表格形式布局)
log4j.appender.FILE.layout.LocationInfo = true (输出java文件名称和行号,默认值false) 举例2:
log4j.appender.FILE.layout = org.apache.log4j.SimpleLayout(简单风格布局,只包含日志信息和级别) 举例3:
log4j.appender.FILE.layout = org.apache.log4j.PatternLayout(自定义风格布局,可以包含时间,日志级别,日志类)
log4j.appender.FILE.layout.ConversionPattern = %d{yyyy-MM-dd HH:mm:ss} %5p %c{1}:%L - %m%n (指定怎样格式化的消息)
具体的格式化说明:
%p:输出日志信息的优先级,即DEBUG,INFO,WARN,ERROR,FATAL。
%d:输出日志时间点的日期或时间,默认格式为ISO8601,也可以在其后指定格式,如:%d{yyyy/MM/dd HH:mm:ss,SSS}。
%r:输出自应用程序启动到输出该log信息耗费的毫秒数。
%t:输出产生该日志事件的线程名。
%l:输出日志事件的发生位置,相当于%c.%M(%F:%L)的组合,包括类全名、方法、文件名以及在代码中的行数。例如:test.TestLog4j.main(TestLog4j.java:10)。
%c:输出日志信息所属的日志对象,也就是getLogger()中的内容。
%C:输出日志信息所属的类目;
%logger:log4j中没有此格式;
%M:输出产生日志信息的方法名。
%F:输出日志消息产生时所在的文件名称。
%L::输出代码中的行号。
%m::输出代码中指定的具体日志信息。
%n:输出一个回车换行符,Windows平台为"rn",Unix平台为"n"。
%x:输出和当前线程相关联的NDC(嵌套诊断环境),尤其用到像java servlets这样的多客户多线程的应用中。
%%:输出一个"%"字符。
1.5 性能优化
在我们的应用中,日志操作几乎是每个方法中必备的行为,不管是记录请求的信息,还是辅助问题的定位,日志信息都起着重要的作用,极大的方便了程序开发。
但与之俱来的是,由于频繁的IO和磁盘的读写,应用的性能也随之降低。并且,java的IO是阻塞式,加锁后导致也同样降低性能。因此对于日志的调优,就成了必备功课。
首先,抛开频繁的IO和磁盘读写不谈,就单纯讨论log4j的性能而言,在高并发的情况下,log4j的锁也会导致应用的性能下降,究其原因,还是看以下的代码:
Category类的callAppenders方法:
//日志对象唤起日志输出目的地Appender:进行日志打印
public void callAppenders(LoggingEvent event) {
int writes = 0;
//遍历日志对象集合
for(Category c = this; c != null; c=c.parent) {
//Category是Logger的父类,此处的c就是请求的日志对象本身:
synchronized(c) {
//此处加锁了:
if(c.aai != null) {
writes += c.aai.appendLoopOnAppenders(event);
}
if(!c.additive) {
break;
}
}
}
if(writes == 0) {
repository.emitNoAppenderWarning(this);
}
}
通过以上代码,我们可以发现,为了获得对应日志对象的Appender,会在每次获取之前都加上synchronized同步锁。无论多少个线程进行请求,到此处都需要进行获取锁的操作,才可以进行日志的打印。这也就是说,线程越多,并发越大,此处的锁的竞争越激烈,进而导致系统性能的降低。
其次,我们再回过头来看下IO和磁盘读写的问题。在实际的生产环境下,系统所产生的日志信息需要保存在磁盘文件中,以便日后进行系统分析,或者系统问题的查找。
之前,我们说过Java的IO是阻塞式的,下面就来看下实际的代码:
JDK1.7中的sun.nio.cs.StreamEncoder类:
public void write(char cbuf[], int off, int len) throws IOException {
synchronized (lock) {
ensureOpen();
if ((off < 0) || (off > cbuf.length) || (len < 0) ||
((off + len) > cbuf.length) || ((off + len) < 0)) {
throw new IndexOutOfBoundsException();
} else if (len == 0) {
return;
}
implWrite(cbuf, off, len);
}
}
可以看到,在java-IO流最终输出阶段,也同样加了synchronized同步锁。这也就是我们所说的java阻塞式IO。
1.5.1 log4j性能测试
在2.3节中,笔者提到了FileAppender,该类主要功能就是将日志信输出到磁盘文件中。其中,有ImmediateFlush、BufferedIO、BufferSize这三个属性尤为值得关注;
当ImmediateFlush=true时候,表示每一条打印日志请求都会被立即输出,也就是立刻同步到磁盘中去。在高并发下,系统性能受到很大的影响,IO和磁盘读写数大大提升。
当ImmediateFlush=false时候,与上面正好相反,表示每一条打印日志请求不会被立即输出,会使用java.io.OutputStreamWriter的缓存,缓存大小为1024字节。
当ImmediateFlush=false、BufferedIO=true、BufferSize=8192时候,表示使用java.io.BufferedWriter缓存,缓存大小为默认8192字节,每一条打印请求不会立即输出,当缓存
达到8192字节后才会落盘操作。这样一来,大大减少了IO和磁盘读写操作,提升了系统的性能。
测试代码:
public class log4jDemo {
Logger log = Logger.getLogger(log4jDemo.class);
@Test
public void test() throws InterruptedException {
for(int x=0;x<20;x++) {
long start = System.currentTimeMillis();
for (int y = 0; y < 50; y++) {
log.info("Info Message!");
}
long time = System.currentTimeMillis() - start;
System.out.println(time);
}
}
}
例子1:当ImmediateFlush=true时,测试结果(单位毫秒):
931 631 372 371 374 371 371 383 376 439 376 383 372 416 393 368 368 366 376 376 394 384 373 396 371 380 368 382 373 369 373 379 374 370 381 367 371 379 372 385 381 379 375 398 409 415 392 371 403 406
例子2:当ImmediateFlush=false时,测试结果(单位毫秒):
845 693 344 338 353 340 372 373 345 337 332 341 345 352 346 332 336 333 379 359 333 330 356 338 333 341 346 331 341 337 339 329 341 339 339 334 341 328 331 329 328 330 329 336 334 332 332 331 333 330
例子3:当ImmediateFlush=false、BufferedIO=true、BufferSize=8192时,测试结果(单位毫秒):
731 853 356 332 336 334 334 334 334 331 332 344 331 330 332 332 330 331 340 334 329 333 331 335 334 334 332 331 336 335 331 354 334 333 334 354 331 333 334 332 333 331 347 332 333 330 332 330 333 331
例子4:使用AsyncAppender异步处理,测试结果(单位毫秒):
292 178 146 177 216 278 215 147 136 102 92 96 97 93 93 95 93 94 92 93 97 93 94 93 95 94 96 107 94 91 93 94 99 98 96 95 95 98 102 95 93 92 91 107 155 137 110 98 93 93
通过以上4个例子,我们可以看出,性能最差的是ImmediateFlush=true的时候,而性能最好的就是开启日志异步AsyncAppender处理的时候;
1.5.2 log4j钩子程序
上一小节,我们提到了log4j的缓存,通过测试结果来看,在开启缓存的情况下,log4j的性能得到了大幅度提升。既然缓存的优势这么明显,为什么log4j不默认开启缓存呢?
缓存的存在,有利有弊。利,提升系统响应性能;弊,当系统因为异常而崩溃,又或者jvm被强行关闭,从而导致缓存中的数据丢失,日志不存在,无法及时确定异常原因。我想,这个才是log4j并没有默认开启缓存的原因!
日志的存在,一方面为了记录系统请求的信息;另一方面,帮助develpoer及时发现、排除错误原因。如果连日志的完整性都不能保留,那么日志存在的意义又是什么?所以,log4j并没有将缓存设置为默认开启,只是提供了一个选项;
那么,我们如何使鱼和熊掌可以兼得呢?在log4j提供的api中暂时无法实现此需求,不过jvm向我们提供了一个方法,可以帮助我们实现,这就是jvm关闭钩子程序;
在jvm中注册一个钩子程序,当jvm关闭的时候,会执行系统中已经设置的所有通过方法addShutdownHook添加的钩子,当系统执行完这些钩子后,jvm才会关闭。
那么,在我们的日志中,如何实现钩子程序呢?请看下面的实现:
测试代码:
public class log4jDemo {
Logger log = Logger.getLogger(log4jDemo.class);
@Test
public void test() throws InterruptedException {
log.info("Info Message!");
}
}
配置文件:(没有开启缓存,立即刷入磁盘)
<appender name="FILE" class="org.apache.log4j.FileAppender">
<param name="File" value="e:/log.out" />
<param name="ImmediateFlush" value="true"/> 关闭缓存
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{ABSOLUTE} %5p %c{1}:%L - %m%n" />
</layout>
</appender>
结果:(程序运行结束后,生成日志文件信息)
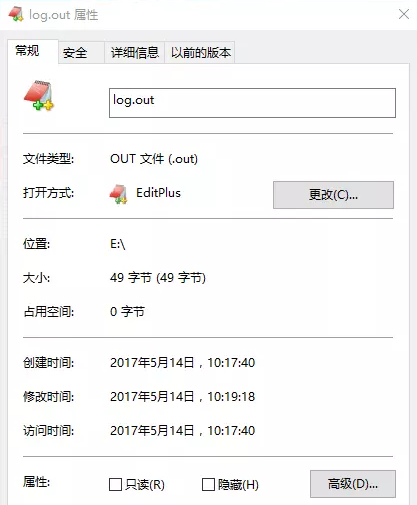
立刻刷入,日志信息落盘;
接下来,修改配置文件信息,开启缓存,不立刻刷入磁盘;
<appender name="FILE" class="org.apache.log4j.FileAppender">
<param name="File" value="e:/log.out" />
<param name="ImmediateFlush" value="false"/> 开启缓存
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{ABSOLUTE} %5p %c{1}:%L - %m%n" />
</layout>
</appender>
结果:(程序运行结束后,生成日志文件信息)
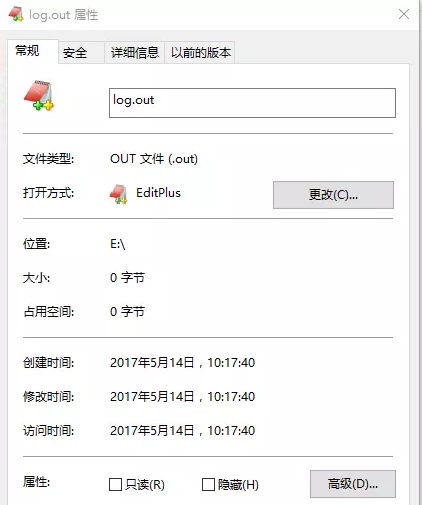
jvm运行结束,日志信息没有保存到磁盘中来,日志丢失;
最后,我们添加钩子程序,看看结果如何?
创建新的Appender,继承FileAppender,在构造中添加钩子程序代码:
public class HookFileAppender extends FileAppender {
public HookFileAppender(){
super();
//添加钩子程序:
Runtime.getRuntime().addShutdownHook(new Log4jHockThread());
}
public HookFileAppender(Layout layout, String filename) throws IOException {
super(layout,filename);
//添加钩子程序:
Runtime.getRuntime().addShutdownHook(new Log4jHockThread());
}
public HookFileAppender(Layout layout, String filename, boolean append) throws IOException {
super(layout,filename,append);
//添加钩子程序:
Runtime.getRuntime().addShutdownHook(new Log4jHockThread());
}
public HookFileAppender(Layout layout, String filename, boolean append, boolean bufferedIO,
int bufferSize) throws IOException {
super(layout,filename,append,bufferedIO,bufferSize);
Runtime.getRuntime().addShutdownHook(new Log4jHockThread());
} class Log4jHockThread extends Thread{
@Override
public void run() {
//jvm结束之前,运行flush操作,将日志落盘;
if(qw != null){
qw.flush();
}
}
} }
配置文件修改:(新的appender,开启缓存)
<appender name="HOOKFILE" class="com.jiaboyan.logDemo.HookFileAppender">
<param name="File" value="e:/log.out" />
<param name="ImmediateFlush" value="false"/>
<!--<param name="bufferedIO" value="true"/>-->
<!--<param name="bufferSize" value="8192"/>-->
<layout class="org.apache.log4j.PatternLayout">
<param name="ConversionPattern" value="%d{ABSOLUTE} %5p %c{1}:%L - %m%n" />
</layout>
</appender>
<root>
<priority value="info" />
<appender-ref ref="HOOKFILE" />
</root>
结果为:
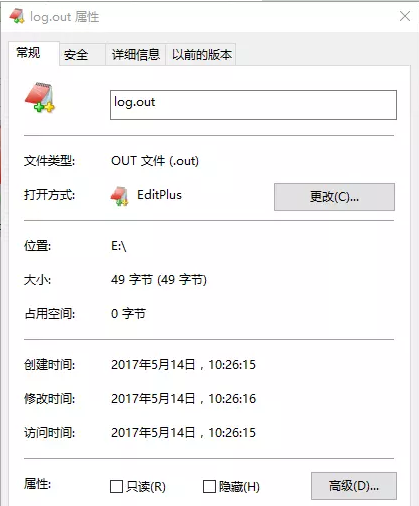
在jvm结束之前,开启了Log4jHockThread线程,将缓存中的日志进行落盘操作,避免了日志的丢失。
Java日志体系(二)log4j的更多相关文章
- java 日志体系(四)log4j 源码分析
java 日志体系(四)log4j 源码分析 logback.log4j2.jul 都是在 log4j 的基础上扩展的,其实现的逻辑都差不多,下面以 log4j 为例剖析一下日志框架的基本组件. 一. ...
- java 日志体系(三)log4j从入门到详解
java 日志体系(三)log4j从入门到详解 一.Log4j 简介 在应用程序中添加日志记录总的来说基于三个目的: 监视代码中变量的变化情况,周期性的记录到文件中供其他应用进行统计分析工作: 跟踪代 ...
- Java 日志体系(二)jcl 和 slf4j
Java 日志体系(二)jcl 和 slf4j <java 日志体系(一)统一日志>:https://www.cnblogs.com/binarylei/p/9828166.html &l ...
- java 日志体系目录
java 日志体系目录 1.1 java 日志体系(一)log4j1.log4j2.logback.jul.jcl.slf4j 1.2 java 日志体系(二)jcl 和 slf4j 2.1 java ...
- Java 日志体系
Java 日志体系 <java 日志和 SLF4J 随想>:http://ifeve.com/java-slf4j-think/ 一.常用的日志组件 名称 jar 描述 log4j log ...
- 混乱的 Java 日志体系
混乱的 Java 日志体系 2016/09/10 | 分类: 基础技术 | 0 条评论 | 标签: LOG 分享到: 原文出处: xirong 一.困扰的疑惑 目前的日志框架有 jdk 自带的 log ...
- Java日志体系居然这么复杂?——架构篇
本文是一个系列,欢迎关注 日志到底是何方神圣?为什么要使用日志框架? 想必大家都有过使用System.out来进行输出调试,开发开发环境下这样做当然很方便,但是线上这样做就有麻烦了: 系统一直运行,输 ...
- java日志体系的思考(转)
Java 日志缓存机制的实现 Java 日志管理最佳实践 混乱的 Java 日志体系 log日志远程统一记录 浅谈后端日志系统 Java异常处理和接口约定 用SLF4j/Logback打印日志-1 用 ...
- java 日志技术汇总(log4j , Commons-logging,.....)
前言 在Tomcat 与weblogic 中的 日志(log4j) 配置系列一 在系列一 中, 有一个问题一直没有解决,就是部署到weblogic 中应用程序如何通过log4j写日志到文件中? 这里仅 ...
随机推荐
- 小白学习MongoDB笔记(一)·下载及安装MongoDB
下载地址:http://dl.mongodb.org/downloads.我选的64位的 windows64-bit 2008 R2.当时版本为3.0.7 文件格式为.msi 借用“一线码农”的话: ...
- rac 数组之遍历
rac的数组遍历其实很简单.但是有个点需要注意. 以下先举个例子说明遍历的用法 NSArray *temArr = @["]; [temArr.rac_sequence.signal sub ...
- 完整开发vue后台管理系统小结
最近业余帮朋友做两个vue项目,一个是面向用户纯展示系列的(后统称A项目),一个是后端管理系统类的(后统称B项目).两者在技术上都没难度,这里对开发过程遇到的问题.取舍等做一个小节. 关于项目搭建 目 ...
- JSP大文件分片上传
核心原理: 该项目核心就是文件分块上传.前后端要高度配合,需要双方约定好一些数据,才能完成大文件分块,我们在项目中要重点解决的以下问题. * 如何分片: * 如何合成一个文件: * 中断了从哪个分片开 ...
- SpringMVC——文件上传下载
一.单文件上传 1.导入依赖 <dependency> <groupId>commons-io</groupId> <artifactId>common ...
- 预处理、const、static与sizeof-sizeof与strlen有哪些区别
1:它们的区别如下: (1)sizeof是操作符,strlen是函数. (2)sizeof操作符的结果类型是size_t,它在头文件中typedef为unsignedint类型,该类型保证能容纳实现所 ...
- Netfilter 之 钩子函数注册
通过注册流程代码的分析,能够明确钩子函数的注册流程,理解存储钩子函数的数据结构,如下图(点击图片可查看原图): 废话不多说,开始分析: nf_hook_ops是注册的钩子函数的核心结构,字段含义如下所 ...
- cvxpy给的ADMM_example报错
x = Variable((3, 1), name="x") ValueError: Cannot broadcast dimensions (3, 1) (3, ) 解决方案: ...
- 【软件工程】Beta冲刺(4/5)
链接部分 队名:女生都队 组长博客: 博客链接 作业博客:博客链接 小组内容 恩泽(组长) 过去两天完成了哪些任务 描述 新增数据分析展示等功能API 服务器后端部署,API接口的beta版实现 展示 ...
- polya定理,环形涂色
环形涂色裸题 #include<iostream> #include<cstdio> #include<algorithm> #include<vector& ...