Mybatis关联查询(转载)
原文地址: http://www.cnblogs.com/xiaolang8762400/p/7399892.html
mybatis 提供了高级的关联查询功能,可以很方便地将数据库获取的结果集映射到定义的Java Bean 中。下面通过一个实例,来展示一下Mybatis对于常见的一对多和多对一关系复杂映射是怎样处理的。
设计一个简单的博客系统,一个用户可以开多个博客,在博客中可以发表文章,允许发表评论,可以为文章加标签。博客系统主要有以下几张表构成:
Author表:作者信息表,记录作者的信息,用户名和密码,邮箱等。
Blog表 : 博客表,一个作者可以开多个博客,即Author和Blog的关系是一对多。
Post表 : 文章记录表,记录文章发表时间,标题,正文等信息;一个博客下可以有很多篇文章,Blog 和Post的关系是一对多。
Comments表:文章评论表,记录文章的评论,一篇文章可以有很多个评论:Post和Comments的对应关系是一对多。
Tag表:标签表,表示文章的标签分类,一篇文章可以有多个标签,而一个标签可以应用到不同的文章上,所以Tag和Post的关系是多对多的关系;(Tag和Post的多对多关系通过Post_Tag表体现)
Post_Tag表: 记录 文章和标签的对应关系。

一般情况下,我们会根据每一张表的结构 创建与此相对应的JavaBean(或者Pojo),来完成对表的基本CRUD操作。
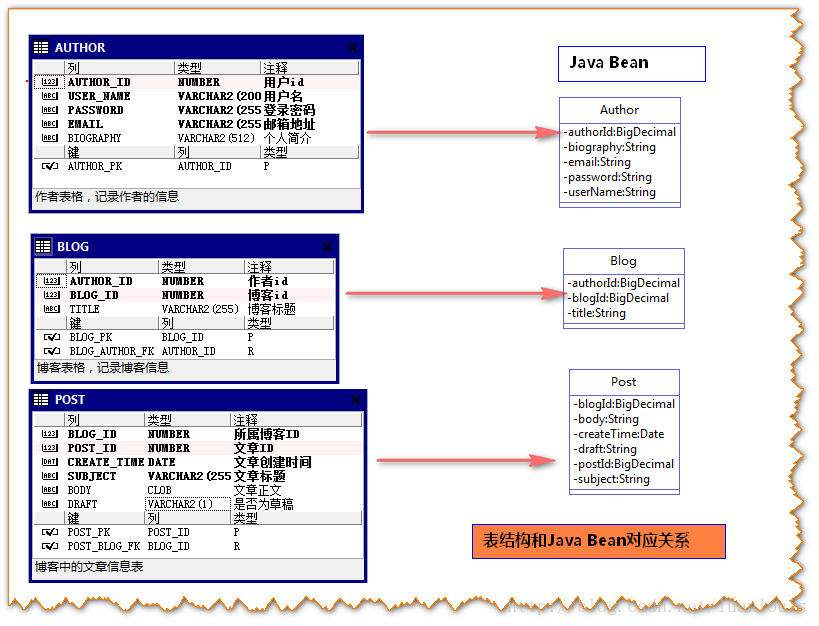
上述对单个表的JavaBean定义有时候不能满足业务上的需求。在业务上,一个Blog对象应该有其作者的信息和一个文章列表,如下图所示:
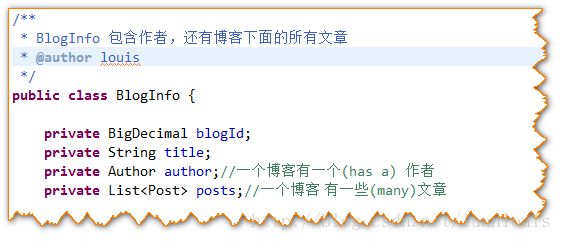
如果想得到这样的类的实例,则最起码要有一下几步:
1. 通过Blog 的id 到Blog表里查询Blog信息,将查询到的blogId 和title 赋到Blog对象内;
2. 根据查询到到blog信息中的authorId 去 Author表获取对应的author信息,获取Author对象,然后赋到Blog对象内;
3. 根据 blogId 去 Post表里查询 对应的 Post文章列表,将List<Post>对象赋到Blog对象中;
这样的话,在底层最起码调用三次查询语句,请看下列的代码:

- /*
- * 通过blogId获取BlogInfo对象
- */
- public static BlogInfo ordinaryQueryOnTest(String blogId)
- {
- BigDecimal id = new BigDecimal(blogId);
- SqlSession session = sqlSessionFactory.openSession();
- BlogInfo blogInfo = new BlogInfo();
- //1.根据blogid 查询Blog对象,将值设置到blogInfo中
- Blog blog = (Blog)session.selectOne("com.foo.bean.BlogMapper.selectByPrimaryKey",id);
- blogInfo.setBlogId(blog.getBlogId());
- blogInfo.setTitle(blog.getTitle());
- //2.根据Blog中的authorId,进入数据库查询Author信息,将结果设置到blogInfo对象中
- Author author = (Author)session.selectOne("com.foo.bean.AuthorMapper.selectByPrimaryKey",blog.getAuthorId());
- blogInfo.setAuthor(author);
- //3.查询posts对象,设置进blogInfo中
- List posts = session.selectList("com.foo.bean.PostMapper.selectByBlogId",blog.getBlogId());
- blogInfo.setPosts(posts);
- //以JSON字符串的形式将对象打印出来
- JSONObject object = new JSONObject(blogInfo);
- System.out.println(object.toString());
- return blogInfo;
- }
- /*
- * 通过blogId获取BlogInfo对象
- */
- public static BlogInfo ordinaryQueryOnTest(String blogId)
- {
- BigDecimal id = new BigDecimal(blogId);
- SqlSession session = sqlSessionFactory.openSession();
- BlogInfo blogInfo = new BlogInfo();
- //1.根据blogid 查询Blog对象,将值设置到blogInfo中
- Blog blog = (Blog)session.selectOne("com.foo.bean.BlogMapper.selectByPrimaryKey",id);
- blogInfo.setBlogId(blog.getBlogId());
- blogInfo.setTitle(blog.getTitle());
- //2.根据Blog中的authorId,进入数据库查询Author信息,将结果设置到blogInfo对象中
- Author author = (Author)session.selectOne("com.foo.bean.AuthorMapper.selectByPrimaryKey",blog.getAuthorId());
- blogInfo.setAuthor(author);
- //3.查询posts对象,设置进blogInfo中
- List posts = session.selectList("com.foo.bean.PostMapper.selectByBlogId",blog.getBlogId());
- blogInfo.setPosts(posts);
- //以JSON字符串的形式将对象打印出来
- JSONObject object = new JSONObject(blogInfo);
- System.out.println(object.toString());
- return blogInfo;
- }
从上面的代码可以看出,想获取一个BlogInfo对象比较麻烦,总共要调用三次数据库查询,得到需要的信息,然后再组装BlogInfo对象。
mybatis提供了一种机制,叫做嵌套语句查询,可以大大简化上述的操作,加入配置及代码如下:
- <resultMap type="com.foo.bean.BlogInfo" id="BlogInfo">
- <id column="blog_id" property="blogId" />
- <result column="title" property="title" />
- <association property="author" column="blog_author_id"
- javaType="com.foo.bean.Author" select="com.foo.bean.AuthorMapper.selectByPrimaryKey">
- </association>
- <collection property="posts" column="blog_id" ofType="com.foo.bean.Post"
- select="com.foo.bean.PostMapper.selectByBlogId">
- </collection>
- </resultMap>
- <select id="queryBlogInfoById" resultMap="BlogInfo" parameterType="java.math.BigDecimal">
- SELECT
- B.BLOG_ID,
- B.TITLE,
- B.AUTHOR_ID AS BLOG_AUTHOR_ID
- FROM LOULUAN.BLOG B
- where B.BLOG_ID = #{blogId,jdbcType=DECIMAL}
- </select>
- <resultMap type="com.foo.bean.BlogInfo" id="BlogInfo">
- <id column="blog_id" property="blogId" />
- <result column="title" property="title" />
- <association property="author" column="blog_author_id"
- javaType="com.foo.bean.Author" select="com.foo.bean.AuthorMapper.selectByPrimaryKey">
- </association>
- <collection property="posts" column="blog_id" ofType="com.foo.bean.Post"
- select="com.foo.bean.PostMapper.selectByBlogId">
- </collection>
- </resultMap>
- <select id="queryBlogInfoById" resultMap="BlogInfo" parameterType="java.math.BigDecimal">
- SELECT
- B.BLOG_ID,
- B.TITLE,
- B.AUTHOR_ID AS BLOG_AUTHOR_ID
- FROM LOULUAN.BLOG B
- where B.BLOG_ID = #{blogId,jdbcType=DECIMAL}
- </select>
- /*
- * 通过blogId获取BlogInfo对象
- */
- public static BlogInfo nestedQueryOnTest(String blogId)
- {
- BigDecimal id = new BigDecimal(blogId);
- SqlSession session = sqlSessionFactory.openSession();
- BlogInfo blogInfo = new BlogInfo();
- blogInfo = (BlogInfo)session.selectOne("com.foo.bean.BlogMapper.queryBlogInfoById",id);
- JSONObject object = new JSONObject(blogInfo);
- System.out.println(object.toString());
- return blogInfo;
- }
- /*
- * 通过blogId获取BlogInfo对象
- */
- public static BlogInfo nestedQueryOnTest(String blogId)
- {
- BigDecimal id = new BigDecimal(blogId);
- SqlSession session = sqlSessionFactory.openSession();
- BlogInfo blogInfo = new BlogInfo();
- blogInfo = (BlogInfo)session.selectOne("com.foo.bean.BlogMapper.queryBlogInfoById",id);
- JSONObject object = new JSONObject(blogInfo);
- System.out.println(object.toString());
- return blogInfo;
- }
通过上述的代码完全可以实现前面的那个查询。这里我们在代码里只需要 blogInfo = (BlogInfo)session.selectOne("com.foo.bean.BlogMapper.queryBlogInfoById",id);一句即可获取到复杂的blogInfo对象。
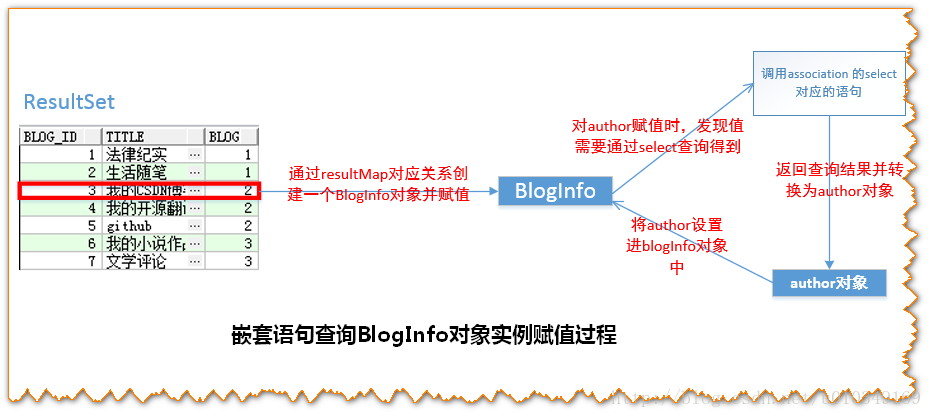
在上面的代码中,Mybatis会执行以下流程:
1.先执行 queryBlogInfoById 对应的语句从Blog表里获取到ResultSet结果集;
2.取出ResultSet下一条有效记录,然后根据resultMap定义的映射规格,通过这条记录的数据来构建对应的一个BlogInfo 对象。
3. 当要对BlogInfo中的author属性进行赋值的时候,发现有一个关联的查询,此时Mybatis会先执行这个select查询语句,得到返回的结果,将结果设置到BlogInfo的author属性上;
4. 对BlogInfo的posts进行赋值时,也有上述类似的过程。
5. 重复2步骤,直至ResultSet. next () == false;
以下是blogInfo对象构造赋值过程示意图:
这种关联的嵌套查询,有一个非常好的作用就是:可以重用select语句,通过简单的select语句之间的组合来构造复杂的对象。上面嵌套的两个select语句com.foo.bean.AuthorMapper.selectByPrimaryKey和com.foo.bean.PostMapper.selectByBlogId完全可以独立使用。
它的弊端也比较明显:即所谓的N+1问题。关联的嵌套查询显示得到一个结果集,然后根据这个结果集的每一条记录进行关联查询。
现在假设嵌套查询就一个(即resultMap 内部就一个association标签),现查询的结果集返回条数为N,那么关联查询语句将会被执行N次,加上自身返回结果集查询1次,共需要访问数据库N+1次。如果N比较大的话,这样的数据库访问消耗是非常大的!所以使用这种嵌套语句查询的使用者一定要考虑慎重考虑,确保N值不会很大。
以上面的例子为例,select 语句本身会返回com.foo.bean.BlogMapper.queryBlogInfoById 条数为1 的结果集,由于它有两条关联的语句查询,它需要共访问数据库 1*(1+1)=3次数据库。
嵌套语句的查询会导致数据库访问次数不定,进而有可能影响到性能。Mybatis还支持一种嵌套结果的查询:即对于一对多,多对多,多对一的情况的查询,Mybatis通过联合查询,将结果从数据库内一次性查出来,然后根据其一对多,多对一,多对多的关系和ResultMap中的配置,进行结果的转换,构建需要的对象。
重新定义BlogInfo的结果映射 resultMap
- <resultMap type="com.foo.bean.BlogInfo" id="BlogInfo">
- <id column="blog_id" property="blogId"/>
- <result column="title" property="title"/>
- <association property="author" column="blog_author_id" javaType="com.foo.bean.Author">
- <id column="author_id" property="authorId"/>
- <result column="user_name" property="userName"/>
- <result column="password" property="password"/>
- <result column="email" property="email"/>
- <result column="biography" property="biography"/>
- </association>
- <collection property="posts" column="blog_post_id" ofType="com.foo.bean.Post">
- <id column="post_id" property="postId"/>
- <result column="blog_id" property="blogId"/>
- <result column="create_time" property="createTime"/>
- <result column="subject" property="subject"/>
- <result column="body" property="body"/>
- <result column="draft" property="draft"/>
- </collection>
- </resultMap>
- <resultMap type="com.foo.bean.BlogInfo" id="BlogInfo">
- <id column="blog_id" property="blogId"/>
- <result column="title" property="title"/>
- <association property="author" column="blog_author_id" javaType="com.foo.bean.Author">
- <id column="author_id" property="authorId"/>
- <result column="user_name" property="userName"/>
- <result column="password" property="password"/>
- <result column="email" property="email"/>
- <result column="biography" property="biography"/>
- </association>
- <collection property="posts" column="blog_post_id" ofType="com.foo.bean.Post">
- <id column="post_id" property="postId"/>
- <result column="blog_id" property="blogId"/>
- <result column="create_time" property="createTime"/>
- <result column="subject" property="subject"/>
- <result column="body" property="body"/>
- <result column="draft" property="draft"/>
- </collection>
- </resultMap>
对应的sql语句如下:
- <select id="queryAllBlogInfo" resultMap="BlogInfo">
- SELECT
- B.BLOG_ID,
- B.TITLE,
- B.AUTHOR_ID AS BLOG_AUTHOR_ID,
- A.AUTHOR_ID,
- A.USER_NAME,
- A.PASSWORD,
- A.EMAIL,
- A.BIOGRAPHY,
- P.POST_ID,
- P.BLOG_ID AS BLOG_POST_ID ,
- P.CREATE_TIME,
- P.SUBJECT,
- P.BODY,
- P.DRAFT
- FROM BLOG B
- LEFT OUTER JOIN AUTHOR A
- ON B.AUTHOR_ID = A.AUTHOR_ID
- LEFT OUTER JOIN POST P
- ON P.BLOG_ID = B.BLOG_ID
- </select>
- <select id="queryAllBlogInfo" resultMap="BlogInfo">
- SELECT
- B.BLOG_ID,
- B.TITLE,
- B.AUTHOR_ID AS BLOG_AUTHOR_ID,
- A.AUTHOR_ID,
- A.USER_NAME,
- A.PASSWORD,
- A.EMAIL,
- A.BIOGRAPHY,
- P.POST_ID,
- P.BLOG_ID AS BLOG_POST_ID ,
- P.CREATE_TIME,
- P.SUBJECT,
- P.BODY,
- P.DRAFT
- FROM BLOG B
- LEFT OUTER JOIN AUTHOR A
- ON B.AUTHOR_ID = A.AUTHOR_ID
- LEFT OUTER JOIN POST P
- ON P.BLOG_ID = B.BLOG_ID
- </select>

- /*
- * 获取所有Blog的所有信息
- */
- public static BlogInfo nestedResultOnTest()
- {
- SqlSession session = sqlSessionFactory.openSession();
- BlogInfo blogInfo = new BlogInfo();
- blogInfo = (BlogInfo)session.selectOne("com.foo.bean.BlogMapper.queryAllBlogInfo");
- JSONObject object = new JSONObject(blogInfo);
- System.out.println(object.toString());
- return blogInfo;
- }
- /*
- * 获取所有Blog的所有信息
- */
- public static BlogInfo nestedResultOnTest()
- {
- SqlSession session = sqlSessionFactory.openSession();
- BlogInfo blogInfo = new BlogInfo();
- blogInfo = (BlogInfo)session.selectOne("com.foo.bean.BlogMapper.queryAllBlogInfo");
- JSONObject object = new JSONObject(blogInfo);
- System.out.println(object.toString());
- return blogInfo;
- }
嵌套结果查询的执行步骤:
1.根据表的对应关系,进行join操作,获取到结果集;
2. 根据结果集的信息和BlogInfo 的resultMap定义信息,对返回的结果集在内存中进行组装、赋值,构造BlogInfo;
3. 返回构造出来的结果List<BlogInfo> 结果。
对于关联的结果查询,如果是多对一的关系,则通过形如 <association property="author" column="blog_author_id" javaType="com.foo.bean.Author"> 进行配置,Mybatis会通过column属性对应的author_id 值去从内存中取数据,并且封装成Author对象;
如果是一对多的关系,就如Blog和Post之间的关系,通过形如 <collection property="posts" column="blog_post_id" ofType="com.foo.bean.Post">进行配置,MyBatis通过 blog_Id去内存中取Post对象,封装成List<Post>;
对于关联结果的查询,只需要查询数据库一次,然后对结果的整合和组装全部放在了内存中。
Mybatis关联查询(转载)的更多相关文章
- Mybatis关联查询和数据库不一致问题分析与解决
Mybatis关联查询和数据库不一致问题分析与解决 本文的前提是,确定sql语句没有问题,确定在数据库中使用sql和项目中结果不一致. 在使用SpringMVC+Mybatis做多表关联时候,发现也不 ...
- MyBatis基础:MyBatis关联查询(4)
1. MyBatis关联查询简介 MyBatis中级联分为3中:association.collection及discriminator. ◊ association:一对一关联 ◊ collecti ...
- MyBatis关联查询,一对多关联查询
实体关系图,一个国家对应多个城市 一对多关联查询可用三种方式实现: 单步查询,利用collection标签为级联属性赋值: 分步查询: 利用association标签进行分步查询: 利用collect ...
- mybatis 关联查询实现一对多
场景:最近接到一个项目是查询管理人集合 同时每一个管理人还存在多个出资人 要查询一个管理人列表 每个管理人又包含了出资人列表 采用mybatis关联查询实现返回数据. 实现方式: 1 .在实体 ...
- MyBatis关联查询、多条件查询
MyBatis关联查询.多条件查询 1.一对一查询 任务需求; 根据班级的信息查询出教师的相关信息 1.数据库表的设计 班级表: 教师表: 2.实体类的设计 班级表: public class Cla ...
- Mybatis关联查询之二
Mybatis关联查询之多对多 多对多 一.entity实体类 public class Student { private Integer stuid; private String stuname ...
- mybatis关联查询基础----高级映射
本文链接地址:mybatis关联查询基础----高级映射(一对一,一对多,多对多) 前言: 今日在工作中遇到了一个一对多分页查询的问题,主表一条记录对应关联表四条记录,关联分页查询后每页只显示三条记录 ...
- MyBatis关联查询和懒加载错误
MyBatis关联查询和懒加载错误 今天在写项目时遇到了个BUG.先说一下背景,前端请求更新生产订单状态,后端从前端接收到生产订单ID进行查询,然后就有问题了. 先看控制台报错: org.apache ...
- Spring+SpringMVC+MyBatis深入学习及搭建(六)——MyBatis关联查询
转载请注明出处:http://www.cnblogs.com/Joanna-Yan/p/6923464.html 前面有将到:Spring+SpringMVC+MyBatis深入学习及搭建(五)--动 ...
随机推荐
- linux下nginx的学习
安装参考菜鸟教程:https://www.runoob.com/linux/nginx-install-setup.html nginx文档官网: http://nginx.org nginx社区:h ...
- Linux Pycharm 添加图标到root账户桌面
1. 去官网下载pycharm程序 2. 解压缩下载到的tar包 3. 在/usr/share/applications目录下新建一个pycharm.desktop, 写入内容如下, 注意红色字体需要 ...
- 终于有人把“TCC分布式事务”实现原理讲明白了
所以这篇文章,就用大白话+手工绘图,并结合一个电商系统的案例实践,来给大家讲清楚到底什么是 TCC 分布式事务. 首先说一下,这里可能会牵扯到一些 Spring Cloud 的原理,如果有不太清楚的同 ...
- Mysql中多表删除
1.从MySQL数据表A中把那些id值在数据表B里有匹配的记录全删除掉 DELETE t2 FROM A t1,B t2 WHERE t1.id = t2.id DELETE FROM t2 USIN ...
- 【xlwings】 wps 和 office 的excel creat_sheet区别
最近在学习 xlwings,参考学习的网址:https://www.jianshu.com/p/b534e0d465f7 写得很棒,学到了很多. 在新建sheet表单, 发现一个问题. import ...
- jmeter 工具学习 未完待续
about Apache JMeter是Apache组织的开源项目,是 一个纯Java桌面应用,用于压力测试和性能测试,它最初被设计用于 web应用测试,后来逐渐的扩展到其他领域 jmeter可以用于 ...
- 植物大战僵尸:寻找阳光掉落Call调用
实验目标:通过遍历阳光产生的时间,寻找阳光产生的本地Call,使用代码注入器注入,自定义生成阳光 阳光CALL遍历技巧: 进入植物大战僵尸-> 当出现阳光后->马上搜索未知初始数值 返回游 ...
- 搭建自己的框架WedeNet(四)
WedeNet2018.Web-UI层:结构如下: 首先,在Controller中定义BaseController,以便加入统一处理逻辑,如下: using log4net; using System ...
- opencv 单目标模板匹配(只适用于模板与目标尺度相同)
#include <iostream> #include "opencv/cv.h" #include "opencv/cxcore.h" #inc ...
- arcgisJs之featureLayer中feature的获取
arcgisJs之featureLayer中feature的获取 在featureLayer中source可以获取到一个Graphic数组,但是这个数组属于原数据数组.当使用 applyEdits修改 ...