数据的特征预处理?(归一化)&(标准化)&(缺失值)
特征处理是什么:
通过特定的统计方法(数学方法)将数据转化成为算法要求的数据
sklearn特征处理API:
sklearn.preprocessing
代码示例: 文末!
归一化:

公式: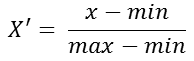
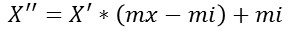
注意:作用于每一列,max为一列的最大值,min为一列的最小值,那么X''为最终结果,mx、mi分别为指定区间,默认mx为1,mi为0
sklearn归一化API:
sklearn.preprocessing.MinMaxScaler
归一化总结:
注意在特定场景下最大值与最小值是变化的,另外,最大值与最小值非常容易受到异常点的影响,所以这种方法鲁棒性较差,只适合传统精确小数据场景
标准化:

公式: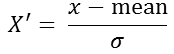


对于归一化来说,如果出现异常点,影响了最大值和最小值,那么结果显然会发生改变
对于标准化来说,如果出现异常点,由于具有一定数据量,少量的异常点对于平均值的影响并不大,从而方差改变较小
sklearn标准化API:
sklearn.preprocessing.StandardScaler
标准化总结:
在已有样本足够多情况下比较稳定,适合现在嘈杂的大数据
缺失值:

sklearn缺失值API:
sklearn.preprocessing.imputer
代码示例:
from sklearn.preprocessing import MinMaxScaler, StandardScaler, Imputer
import numpy as np def mm():
"""归一化处理
X' = (x-min)/(max-min)
X'' = X'*(mx-mi)+mi
"""
m = MinMaxScaler(feature_range=(5,10)) # 默认范围为0-1
array = [[90,2,10,40],[60,4,15,45],[75,3,13,46]]
data = m.fit_transform(array)
print(data) def standard():
"""标准化缩放
相比于归一化,标准化对于存在异常值而对结果的影响不大,适合大数据
而归一化,由于受异常点的影响,所以......
"""
s = StandardScaler()
array = [[1,-1,3], [2,4,2], [4,6,-1]]
data = s.fit_transform(array)
print(data) def im():
"""缺失值处理"""
im = Imputer(missing_values='NaN', strategy='mean', axis=0) # nan 或 NaN都可以,固定写法,填补策略(平均值),按列填充
data = im.fit_transform([[1,2],[np.nan,3],[7,6]])
print(data) if __name__ == '__main__':
mm()
standard()
im()
数据的特征预处理?(归一化)&(标准化)&(缺失值)的更多相关文章
- 什么是机器学习的特征工程?【数据集特征抽取(字典,文本TF-Idf)、特征预处理(标准化,归一化)、特征降维(低方差,相关系数,PCA)】
2.特征工程 2.1 数据集 2.1.1 可用数据集 Kaggle网址:https://www.kaggle.com/datasets UCI数据集网址: http://archive.ics.uci ...
- 关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
一.标准化(Z-Score),或者去除均值和方差缩放 公式为:(X-mean)/std 计算时对每个属性/每列分别进行. 将数据按期属性(按列进行)减去其均值,并处以其方差.得到的结果是,对于每个属 ...
- 【原】关于使用sklearn进行数据预处理 —— 归一化/标准化/正则化
一.标准化(Z-Score),或者去除均值和方差缩放 公式为:(X-mean)/std 计算时对每个属性/每列分别进行. 将数据按期属性(按列进行)减去其均值,并处以其方差.得到的结果是,对于每个属 ...
- 使用sklearn进行数据预处理 —— 归一化/标准化/正则化
一.标准化(Z-Score),或者去除均值和方差缩放 公式为:(X-mean)/std 计算时对每个属性/每列分别进行. 将数据按期属性(按列进行)减去其均值,并除以其方差.得到的结果是,对于每个属 ...
- [Scikit-Learn] - 数据预处理 - 归一化/标准化/正则化
reference: http://www.cnblogs.com/chaosimple/p/4153167.html 一.标准化(Z-Score),或者去除均值和方差缩放 公式为:(X-mean)/ ...
- 特征预处理之归一化&标准化
写在前面 这篇博客的主要内容 应用MinMaxScaler实现对特征数据进行归一化 应用StandardScaler实现对特征数据进行标准化 特征预处理 定义 通过一些转换函数将特征数据转换成更加 ...
- 使用Tensorflow搭建回归预测模型之二:数据准备与预处理
前言: 在前一篇中,已经搭建好了Tensorflow环境,本文将介绍如何准备数据与预处理数据. 正文: 在机器学习中,数据是非常关键的一个环节,在模型训练前对数据进行准备也预处理是非常必要的. 一.数 ...
- AI学习---特征工程【特征抽取、特征预处理、特征降维】
学习框架 特征工程(Feature Engineering) 数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已 什么是特征工程: 帮助我们使得算法性能更好发挥性能而已 sklearn主 ...
- Alink漫谈(十) :特征工程 之 特征哈希/标准化缩放
Alink漫谈(十) :特征工程之特征哈希/标准化缩放 目录 Alink漫谈(十) :特征工程之特征哈希/标准化缩放 0x00 摘要 0x01 相关概念 1.1 特征工程 1.2 特征缩放(Scali ...
随机推荐
- cdh版hbase构建Phoenix 遇到的坑
Phoenix 构建cdh版hbase遇到的坑 1. 安装phoenix 下载:在github上下载对应版本https://github.com/apache/phoenix 解压:略 编译: 修改根 ...
- hive安装常见错误
hive编译出错 mvn clean package -DskipTests -Phadoop-2 -Pdist 失败日志1 Failed to execute goal on project hiv ...
- 格符\b的使用示例:每隔1秒消去1个字符
/* 退格符\b的使用示例:每隔1秒消去1个字符 */ #include <time.h> #include <stdio.h> /*--- 等待x毫秒 ---*/ int s ...
- Vue图片浏览组件v-viewer,支持旋转、缩放、翻转等操作
v-viewer 用于图片浏览的Vue组件,支持旋转.缩放.翻转等操作,基于viewer.js. 从0.x迁移 你需要做的唯一改动就是手动引入样式文件: 1 import 'viewerjs/dist ...
- 【原创】FltSendMessage蓝屏分析
INVALID_PROCESS_DETACH_ATTEMPT (6)Arguments:Arg1: 00000000Arg2: 00000000Arg3: 00000000Arg4: 00000000 ...
- qDebug() << currentThreadId();
从 dbzhang800 的博客中转载两篇关于事件循环的文章,放在一起,写作备忘. 再次提到的一点是:事件循环和线程没有必然关系. QThread 的 run() 方法始终是在一个单独线程执行的,但只 ...
- php 的生命周期
1.PHP的运行模式: PHP两种运行模式是WEB模式.CLI模式.无论哪种模式,PHP工作原理都是一样的,作为一种SAPI运行. 1.当我们在终端敲入php这个命令的时候,它使用的是CLI. 它就像 ...
- Flume-自定义 Source 读取 MySQL 数据
开源实现:https://github.com/keedio/flume-ng-sql-source 这里记录的是自己手动实现. 测试中要读取的表 CREATE TABLE `student` ( ` ...
- Xshell查看日志
查询日志命令(复制后鼠标右键粘贴): tail -1000f /mnt/logs/SMFManagement/SMFManagement_info.log
- 2.4 Go语言基础之切片
本文主要介绍Go语言中切片(slice)及它的基本使用. 一.引子 因为数组的长度是固定的并且数组长度属于类型的一部分,所以数组有很多的局限性. 例如: func arraySum(x [3]int) ...