李宏毅 Gradient Descent Demo 代码讲解
何为梯度下降,直白点就是,链式求导法则,不断更新变量值。
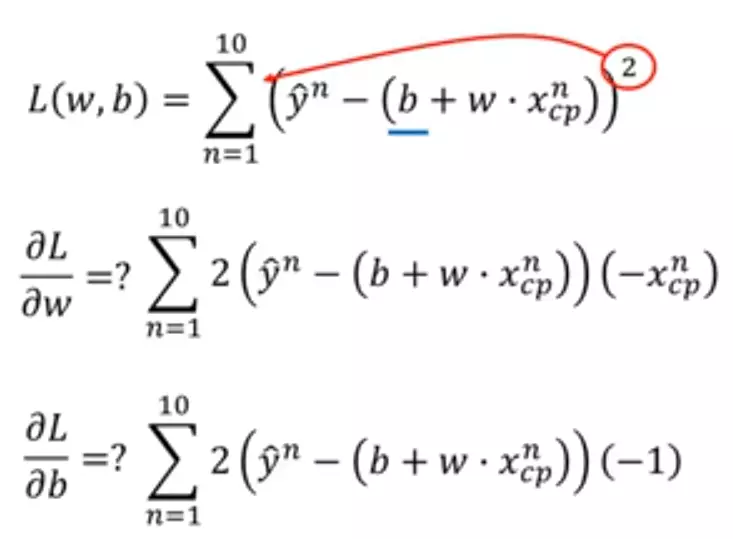
Loss函数
python代码如下
import numpy as np
import matplotlib.pyplot as plt # y_data = b + w * x_data
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.] # 10 个数
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.] # 10 个数 x = np.arange(-200, -100, 1) # bias
y = np.arange(-5, 5, 0.1) # weight
z = np.zeros((len(x), len(y))) # zeros函数表示输出的数组为 100行 100列 #X, Y = np.meshgrid(x, y) 个人感觉这句话没用。。。 for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
z[j][i] = 0
for n in range(len(x_data)):
# z[j][i]为 b=x[i] 及 w=y[j] 时,对应的 Loss Function 的大小
z[j][i] = z[j][i] + (y_data[n] - b - w * x_data[n]) ** 2
z[j][i] = z[j][i] / len(x_data) # 求 loss function 均值 # y_data = b + w * x_data
b = -120 # initial b
w = -4 # initial w
lr = 0.0000001 # learning rate
iteration = 100000 # 迭代运行次数 # store initial values for plotting
b_history = [b]
w_history = [w] # iterations
for i in range(iteration): # 在 100000 次迭代下,看最后结果
b_grad = 0.0 # 对 b_grad 重新赋值为0
w_grad = 0.0 # 对 w_grad 重新赋值为0
for n in range(len(x_data)):
# 此处应该注意的是,求导的是Loss函数,因此对应的变量是w、b,是看w、b在各自的轴上的移动
b_grad = b_grad + 2.0 * (y_data[n] - b - w * x_data[n]) * ( - 1.0)
w_grad = w_grad + 2.0 * (y_data[n] - b - w * x_data[n]) * ( - x_data[n]) # update parameters
b = b - lr * b_grad
w = w - lr * w_grad # store parameters for plotting
b_history.append(b)
w_history.append(w) # plot the figure
plt.contourf(x, y, z, 50, alpha = 0.5, cmap = plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms = 12, markeredgewidth = 3, color = 'orange')
plt.plot(b_history, w_history, 'o-', ms = 3, lw = 1.5, color = 'black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$', fontsize=16)
plt.ylabel(r'$w$', fontsize=16)
plt.show()
当learning rate 即 lr = 0.0000001时
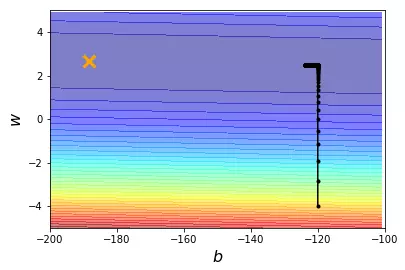
当learning rate 即 lr = 0.000001时

learning rate 即 lr = 0.00001时

可以看到效果不是很好 所以改变learning rate
import numpy as np
import matplotlib.pyplot as plt # y_data = b + w * x_data
x_data = [338., 333., 328., 207., 226., 25., 179., 60., 208., 606.] # 10 个数
y_data = [640., 633., 619., 393., 428., 27., 193., 66., 226., 1591.] # 10 个数 x = np.arange(-200, -100, 1) # bias
y = np.arange(-5, 5, 0.1) # weight
z = np.zeros((len(x), len(y))) # zeros函数表示输出的数组为 100 行 100 列 # X, Y = np.meshgrid(x, y) for i in range(len(x)):
for j in range(len(y)):
b = x[i]
w = y[j]
z[j][i] = 0
for n in range(len(x_data)):
# z[j][i]为 b=x[i] 及 w=y[j] 时,对应的 Loss Function 的大小
z[j][i] = z[j][i] + (y_data[n] - b - w * x_data[n]) ** 2
z[j][i] = z[j][i] / len(x_data) # 求 loss function 均值 # ydata = b + w * xdata
b = -120 # initial b
w = -4 # initial w
lr = 1 # learning rate
iteration = 100000 # 迭代运行次数 # store initial values for plotting
b_history = [b]
w_history = [w] # 个性化 w 和 b 的 learning rate
lr_b = 0
lr_w = 0 # iterations
for i in range(iteration): # 在 100000 次迭代下,看最后结果
b_grad = 0.0 # 对 b_grad 重新赋值为0
w_grad = 0.0 # 对 w_grad 重新赋值为0
for n in range(len(x_data)):
# 此处应该注意的是,求导的是L函数,因此对应的变量是w、b,是看w、b在各自的轴上的移动
b_grad = b_grad + 2.0 * (y_data[n] - b - w * x_data[n]) * (- 1.0)
w_grad = w_grad + 2.0 * (y_data[n] - b - w * x_data[n]) * (- x_data[n]) lr_b = lr_b + b_grad ** 2
lr_w = lr_w + w_grad ** 2 # update parameters
b = b - lr / np.sqrt(lr_b) * b_grad
w = w - lr / np.sqrt(lr_w) * w_grad # store parameters for plotting
b_history.append(b)
w_history.append(w) # plot the figure
plt.contourf(x, y, z, 50, alpha=0.5, cmap=plt.get_cmap('jet'))
plt.plot([-188.4], [2.67], 'x', ms=12, markeredgewidth=3, color='orange')
plt.plot(b_history, w_history, 'o-', ms=3, lw=1.5, color='black')
plt.xlim(-200, -100)
plt.ylim(-5, 5)
plt.xlabel(r'$b$', fontsize=16)
plt.ylabel(r'$w$', fontsize=16)
plt.show()
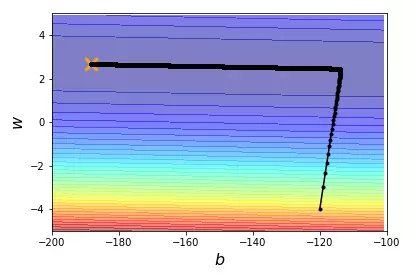
结果展示
一些说明:
np.array np.asarray的区别
array和asarry都可以将结构数据转换为ndarray类型
但是主要的区别在于当数据源是ndarray时,array仍会copy出一个副本,占用新的内存,但asarray不会。
np.meshgrid的作用
生成网格点坐标矩阵
李宏毅 Gradient Descent Demo 代码讲解的更多相关文章
- 几种梯度下降方法对比(Batch gradient descent、Mini-batch gradient descent 和 stochastic gradient descent)
https://blog.csdn.net/u012328159/article/details/80252012 我们在训练神经网络模型时,最常用的就是梯度下降,这篇博客主要介绍下几种梯度下降的变种 ...
- 李宏毅机器学习笔记2:Gradient Descent(附带详细的原理推导过程)
李宏毅老师的机器学习课程和吴恩达老师的机器学习课程都是都是ML和DL非常好的入门资料,在YouTube.网易云课堂.B站都能观看到相应的课程视频,接下来这一系列的博客我都将记录老师上课的笔记以及自己对 ...
- 李宏毅机器学习课程---4、Gradient Descent (如何优化 )
李宏毅机器学习课程---4.Gradient Descent (如何优化) 一.总结 一句话总结: 调整learning rates:Tuning your learning rates 随机Grad ...
- Logistic Regression Using Gradient Descent -- Binary Classification 代码实现
1. 原理 Cost function Theta 2. Python # -*- coding:utf8 -*- import numpy as np import matplotlib.pyplo ...
- Linear Regression Using Gradient Descent 代码实现
参考吴恩达<机器学习>, 进行 Octave, Python(Numpy), C++(Eigen) 的原理实现, 同时用 scikit-learn, TensorFlow, dlib 进行 ...
- 【笔记】机器学习 - 李宏毅 - 4 - Gradient Descent
梯度下降 Gradient Descent 梯度下降是一种迭代法(与最小二乘法不同),目标是解决最优化问题:\({\theta}^* = arg min_{\theta} L({\theta})\), ...
- 【论文翻译】An overiview of gradient descent optimization algorithms
这篇论文最早是一篇2016年1月16日发表在Sebastian Ruder的博客.本文主要工作是对这篇论文与李宏毅课程相关的核心部分进行翻译. 论文全文翻译: An overview of gradi ...
- 梯度下降算法实现原理(Gradient Descent)
概述 梯度下降法(Gradient Descent)是一个算法,但不是像多元线性回归那样是一个具体做回归任务的算法,而是一个非常通用的优化算法来帮助一些机器学习算法求解出最优解的,所谓的通用就是很 ...
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
随机推荐
- 19-SQLServer定期自动导入数据的dtsx部署
一.注意点 1.登录Integration Service必须使用windows用户,并且只能在本地服务器登录. 2.SQLServer2000以前,叫dts,全程Data Transformatio ...
- 2018多校第九场 HDU 6416 (DP+前缀和优化)
转自:https://blog.csdn.net/CatDsy/article/details/81876341 #include <bits/stdc++.h> using namesp ...
- [Javascript] Customize Behavior when Accessing Properties with Proxy Handlers
A Proxy allows you to trap what happens when you try to get a property value off of an object and do ...
- 智能指针weak_ptr记录
智能指针weak_ptr为弱共享指针,实际上是share_ptr的辅助指针,不具备指针的功能.主要是为了协助 shared_ptr 工作,可用来观测资源的使用情况.weak_ptr 只对 shared ...
- Mybatis的mapper接口在Spring中实例化过程
在spring中使用mybatis时一般有下面的配置 <bean id="mapperScannerConfigurer" class="org.mybatis.s ...
- react-native-pg-utils(对react-native全局进行配置,对内置对象原型链增加方法,增加常用全局方法.)
react-native-pg-utils 对react-native全局进行配置,对内置对象原型链增加方法,增加常用全局方法. 每次新建react-native项目之后都会发现有一些很常用的方法在这 ...
- Java进阶知识12 Hibernate多对多双向关联(Annotation+XML实现)
1.Annotation 注解版 1.1.应用场景(Student-Teacher):当学生知道有哪些老师教,老师也知道自己教哪些学生时,可用双向关联 1.2.创建Teacher类和Student类 ...
- 【luoguP2675】《瞿葩的数字游戏》T3-三角圣地
题目背景 国王1带大家到了数字王国的中心:三角圣地. 题目描述 不是说三角形是最稳定的图形嘛,数字王国的中心便是由一个倒三角构成.这个倒三角的顶端有一排数字,分别是1~N.1~N可以交换位置.之后的每 ...
- I am coming..
It's so great to start the blog here since it's been a long time that I want to start such kind of l ...
- Neo4j 简介 2019
Neo4j是一个世界领先的开源图形数据库,由 Java 编写.图形数据库也就意味着它的数据并非保存在表或集合中,而是保存为节点以及节点之间的关系. Neo4j 的数据由下面几部分构成: 节点边属性Ne ...