deep_learning_neural network梯度下降
神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识。关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结。吴恩达的深度学习课程放在了网易云课堂上,链接如下(免费):
https://mooc.study.163.com/smartSpec/detail/1001319001.htm
神经网络最基本的优化算法是反向传播算法加上梯度下降法。通过梯度下降法,使得网络参数不断收敛到全局(或者局部)最小值,但是由于神经网络层数太多,需要通过反向传播算法,把误差一层一层地从输出传播到输入,逐层地更新网络参数。由于梯度方向是函数值变大的最快的方向,因此负梯度方向则是函数值变小的最快的方向。沿着负梯度方向一步一步迭代,便能快速地收敛到函数最小值。这就是梯度下降法的基本思想,从下图可以很直观地理解其含义。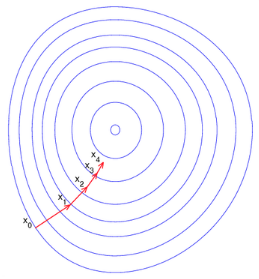
梯度下降法的迭代公式如下:
其中w是待训练的网络参数,αα是学习率,是一个常数,dw是梯度。以上是梯度下降法的最基本形式,在此基础上,研究人员提出了其他多种变种,使得梯度下降法收敛更加迅速和稳定,其中最优秀的代表便是Mommentum, RMSprop和Adam等。
Momentum算法
Momentum算法又叫做冲量算法,其迭代更新公式如下:
光看上面的公式有些抽象,我们先介绍一下指数加权平均,再回过头来看这个公式,会容易理解得多。
指数加权平均
假设我们有一年365天的气温数据θ1,θ2,...,θ365θ1,θ2,...,θ365,把他们化成散点图,如下图所示: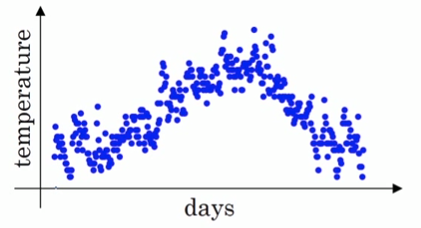
这些数据有些杂乱,我们想画一条曲线,用来表征这一年气温的变化趋势,那么我们需要把数据做一次平滑处理。最常见的方法是用一个华东窗口滑过各个数据点,计算窗口的平均值,从而得到数据的滑动平均值。但除此之外,我们还可以使用指数加权平均来对数据做平滑。其公式如下:
v就是指数加权平均值,也就是平滑后的气温。ββ的典型值是0.9,平滑后的曲线如下图所示: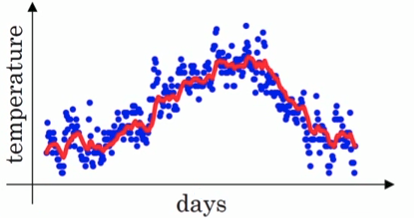
对于vk=βvk−1+(1−β)θkvk=βvk−1+(1−β)θk,我们把它展开,可以得到如下形式:
可见,平滑后的气温,是以往每一天原始气温的加权平均值,只是这个权值是随时间的远近而变化的,离今天越远,权值越小,且呈指数衰减。从今天往前数k天,它的权值为βk(1−β)βk(1−β)。当β=11−ββ=11−β时,由于limβ→1βk(1−β)=e−1limβ→1βk(1−β)=e−1,权重已经非常小,更久远一些的气温数据权重更小,可以认为对今天的气温没有影响。因此,可以认为指数加权平均计算的是最近11−β11−β个数据的加权平均值。通常ββ取值为0.9,相当于计算10个数的加权平均值。但是按照原始的指数加权平均公式,还有一个问题,就是当k比较小时,其最近的数据太少,导致估计误差比较大。例如v1=0.9v0+(1−0.9)θ1=0.1θ1v1=0.9v0+(1−0.9)θ1=0.1θ1。为了减小最初几个数据的误差,通常对于k比较小时,需要做如下修正:
1−βk1−βk是所有权重的和,这相当于对权重做了一个归一化处理。下面的图中,紫色的线就是没有做修正的结果,修正之后就是绿色曲线。二者在前面几个数据点之间相差较大,后面则基本重合了。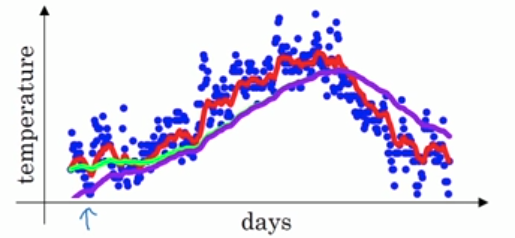
回看Momentum算法
现在再回过头来看Momentum算法的迭代更新公式:
dwdw是我们计算出来的原始梯度,vv则是用指数加权平均计算出来的梯度。这相当于对原始梯度做了一个平滑,然后再用来做梯度下降。实验表明,相比于标准梯度下降算法,Momentum算法具有更快的收敛速度。为什么呢?看下面的图,蓝线是标准梯度下降法,可以看到收敛过程中产生了一些震荡。这些震荡在纵轴方向上是均匀的,几乎可以相互抵消,也就是说如果直接沿着横轴方向迭代,收敛速度可以加快。Momentum通过对原始梯度做了一个平滑,正好将纵轴方向的梯度抹平了(红线部分),使得参数更新方向更多地沿着横轴进行,因此速度更快。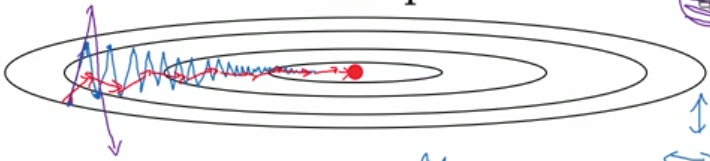
RMSprop算法
对于上面的这个椭圆形的抛物面(图中的椭圆代表等高线),沿着横轴收敛速度是最快的,所以我们希望在横轴(假设记为w1)方向步长大一些,在纵轴(假设记为w2)方向步长小一些。这时候可以通过RMSprop实现,迭代更新公式如下:
观察上面的公式可以看到,s是对梯度的平方做了一次平滑。在更新w时,先用梯度除以s1+ϵ−−−−−√s1+ϵ,相当于对梯度做了一次归一化。如果某个方向上梯度震荡很大,应该减小其步长;而震荡大,则这个方向的s也较大,除完之后,归一化的梯度就小了;如果某个方向上梯度震荡很小,应该增大其步长;而震荡小,则这个方向的s也较小,归一化的梯度就大了。因此,通过RMSprop,我们可以调整不同维度上的步长,加快收敛速度。把上式合并后,RMSprop迭代更新公式如下:
ββ的典型值是0.999。公式中还有一个ϵϵ,这是一个很小的数,典型值是10−810−8。
Adam算法
Adam算法则是以上二者的结合。先看迭代更新公式:
典型值:β1=0.9,β2=0.999,ϵ=10−8β1=0.9,β2=0.999,ϵ=10−8。Adam算法相当于先把原始梯度做一个指数加权平均,再做一次归一化处理,然后再更新梯度值。
deep_learning_neural network梯度下降的更多相关文章
- 深度学习必备:随机梯度下降(SGD)优化算法及可视化
补充在前:实际上在我使用LSTM为流量基线建模时候,发现有效的激活函数是elu.relu.linear.prelu.leaky_relu.softplus,对应的梯度算法是adam.mom.rmspr ...
- 梯度下降(Gradient Descent)小结
在求解机器学习算法的模型参数,即无约束优化问题时,梯度下降(Gradient Descent)是最常采用的方法之一,另一种常用的方法是最小二乘法.这里就对梯度下降法做一个完整的总结. 1. 梯度 在微 ...
- 从梯度下降到Fista
前言: FISTA(A fast iterative shrinkage-thresholding algorithm)是一种快速的迭代阈值收缩算法(ISTA).FISTA和ISTA都是基于梯度下降的 ...
- 线性回归、梯度下降(Linear Regression、Gradient Descent)
转载请注明出自BYRans博客:http://www.cnblogs.com/BYRans/ 实例 首先举个例子,假设我们有一个二手房交易记录的数据集,已知房屋面积.卧室数量和房屋的交易价格,如下表: ...
- 随机梯度下降(Stochastic gradient descent)和 批量梯度下降(Batch gradient descent )的公式对比、实现对比[转]
梯度下降(GD)是最小化风险函数.损失函数的一种常用方法,随机梯度下降和批量梯度下降是两种迭代求解思路,下面从公式和实现的角度对两者进行分析,如有哪个方面写的不对,希望网友纠正. 下面的h(x)是要拟 ...
- 为什么是梯度下降?SGD
在机器学习算法中,为了优化损失函数loss function ,我们往往采用梯度下降算法来进行优化.举个例子: 线性SVM的得分函数和损失函数分别为: ...
- Stanford大学机器学习公开课(二):监督学习应用与梯度下降
本课内容: 1.线性回归 2.梯度下降 3.正规方程组 监督学习:告诉算法每个样本的正确答案,学习后的算法对新的输入也能输入正确的答案 1.线性回归 问题引入:假设有一房屋销售的数据如下: 引 ...
- Matlab梯度下降解决评分矩阵分解
for iter = 1:num_iters %梯度下降 用户向量 for i = 1:m %返回有0有1 是逻辑值 ratedIndex1 = R_training(i,:)~=0 ; %U(i,: ...
- 机器学习(一):梯度下降、神经网络、BP神经网络
这几天围绕论文A Neural Probability Language Model 看了一些周边资料,如神经网络.梯度下降算法,然后顺便又延伸温习了一下线性代数.概率论以及求导.总的来说,学到不少知 ...
随机推荐
- 建立Maven工程时出错,Failure to transfer
建立Maven工程时出错,Failure to transfer com.thoughtworks.xstream:xstream:jar:1.3.1 Failure to transfer com. ...
- 代码托管至Github
昨天突然之间觉得作为一个iOS程序员,没有在github上提交过自己的代码真是一大遗憾,不管是自己写的优秀的代码还是刚开始学习,用来学习练手的项目.然后我就很想要学习怎么往github上提交代码,很不 ...
- iOS开发UIkit动力学UIDynamicAnimator一系列动画
UIDynamicAnimator类,通过这个类中的不同行为来实现一些动态特性. UIAttachmentBehavior(吸附),UICollisionBehavior(碰撞),UIGravityB ...
- Exchange2010---反垃圾邮件配置
Exchange2010---反垃圾邮件配置 Exchange2010---反垃圾邮件配置 本文以Exchange Server 2010作为反垃圾邮件配置实例为例. 其实,在微软发布的Exc ...
- jquery-validation JQ 表单验证
jquery-validation是一款前端验证js插件,可以验证必填字段.邮件.URL.数字范围等,在表单中应用非常广泛. 官方网站 https://jqueryvalidation.org/ 下载 ...
- 学习笔记:CentOS 7学习之十二:查找命令
目录 1.which-whereis-locate-grep-find查找命令 1.1 which 1.2 whereis 1.3 locate 1.4 grep 1.5 find命令 2. 命令的判 ...
- 选择排序的Python代码实现
对于a[0]~a[n]的数组, 默认a[i]最小,和后面的a[i+1]~a[n]进行比较,把最小的和a[i]交换位置,保证本次循环结束后a[i]是上一次未排序的数据中最小的 写法1 a=[12,2,2 ...
- mybatis-plus 错误 java.lang.NoClassDefFoundError
错误 java.lang.NoClassDefFoundError: org/apache/velocity/context/Context 使用mybatis-plus自动生成文件的时候,报下面的错 ...
- django 路由层 伪静态网页 虚拟环境 视图层
路由层 无名分组 有名分组 反向解析 路由分发 名称空间 伪静态网页 虚拟环境 视图层 JsonResponse FBV与CBV 文件上传 项目urls.py下面 from app01 import ...
- Fullscreen API:全屏操作
function launchFullscreen(element) { if(element.requestFullscreen) { element.requestFullscreen(); } ...