spark application调度机制(spreadOutApps,oneExecutorPerWorker 算法)
1.要想明白spark application调度机制,需要回答一下几个问题:
1.谁来调度?
2.为谁调度?
3.调度什么?
3.何时调度?
4.调度算法
前四个问题可以用如下一句话里来回答:每当集群资源发生变化时(包含master主备切换),active master 进程为所有已注册的并且没有调度完毕的application调度Worker节点上的Executor进程。
集群资源发生变化是什么意思呢?这里的集群资源指的主要是cores的变化,注册/移除Executor进程使得集群的freeCores变多/变少,添加/移除Worker节点使得集群的freeCores变多/变少......,所有导致集群资源发生变化的操作,都会调用schedule()重新为application和driver进行资源调度。
spark提供了两种资源调度算法:spreadOutApps和非spreadOutApps。spreadOutApps算法可以手动通过SparkConf来配置,默认是使用该算法的,spreadOut算法会尽可能的将一个application 所需要的Executor进程分布在多个worker节点上,从而提高并行度,非spreadOut与之相反,他会把一个worker节点的freeCores都耗尽了才会去下一个worker节点分配。在spark1.3.1版本时基于该机制executor的实际数量以及每个executor的cpu,可能会与配置(spark-submit)的不一样
2.基本概念
每一个application至少包含以下基本属性:
coresPerExecutor:每一个Executor进程的cpu cores个数
memoryPerExecutor:每一个Executor进程的memory大小
maxCores: 这个application最多需要的cpu cores个数。
每一个worker至少包含以下基本属性:
freeCores:worker 节点当前可用的cpu cores个数
memoryFree:worker节点当前可用的memory大小。
假设一个待注册的application如下:
coresPerExecutor:2
memoryPerExecutor:512M
maxCores: 12
这表示这个application 最多需要12个cpu cores,每一个Executor进行都要2个core,512M内存。
假设某一时刻spark集群有如下几个worker节点,他们按照coresFree降序排列:
Worker1:coresFree=10 memoryFree=10G
Worker2:coresFree=7 memoryFree=1G
Worker3:coresFree=3 memoryFree=2G
Worker4:coresFree=2 memoryFree=215M
Worker5:coresFree=1 memoryFree=1G
其中worker5不满足application的要求:worker5.coresFree < application.coresPerExecutor
worker4也不满足application的要求:worker4.memoryFree < application.memoryPerExecutor
因此最终满足调度要求的worker节点只有前三个,我们将这三个节点记作usableWorkers。
3.spreadOut算法
先介绍spreadOut算法吧。上面已经说了,满足条件的worker只有前三个:
Worker1:coresFree=10 memoryFree=10G
Worker2:coresFree=7 memoryFree=1G
Worker3:coresFree=3 memoryFree=2G
第一次调度之后,worker列表如下:
Worker1:coresFree=8 memoryFree=9.5G assignedExecutors=1 assignedCores=2
Worker2:coresFree=7 memoryFree=1G assignedExecutors=0 assignedCores=0
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:1,totalCores=2
可以发现,worker1的coresFree和memoryFree都变小了而worker2,worker3并没有发生改变,这是因为我们在worker1上面分配了一个Executor进程(这个Executor进程占用2个cpu cores,512M memory)而没有在workre2和worker3上分配。
接下来继续循环,开始去worker2上分配:
Worker1:coresFree=8 memoryFree=9.5G assignedExecutors=1 assignedCores=2
Worker2:coresFree=5 memoryFree=512M assignedExecutors=1 assignedCores=2
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:2,totalCores=4
此时已经分配了2个Executor进程,4个core。
接下来去worker3上分配:
Worker1:coresFree=8 memoryFree=9.5G assignedExecutors=1 assignedCores=2
Worker2:coresFree=5 memoryFree=512M assignedExecutors=1 assignedCores=2
Worker3:coresFree=1 memoryFree=1.5G assignedExecutors=1 assignedCores=2
totalExecutors:3,totalCores=6
接下来再去worker1分配,然后worker2...依此类推...以round-robin方式分配,由于worker3.coresFree < application.coresPerExecutor,不会在它上面分配资源了:
Worker1:coresFree=6 memoryFree=9.0G assignedExecutors=2 assignedCores=4
Worker2:coresFree=5 memoryFree=512M assignedExecutors=1 assignedCores=2
Worker3:coresFree=1 memoryFree=1.5G assignedExecutors=1 assignedCores=2
totalExecutors:4,totalCores=8
Worker1:coresFree=6 memoryFree=9.0G assignedExecutors=2 assignedCores=4
Worker2:coresFree=3 memoryFree=0M assignedExecutors=2 assignedCores=4
Worker3:coresFree=1 memoryFree=1.5G assignedExecutors=1 assignedCores=2
totalExecutors:5,totalCores=10
此时worker2也不满足要求了:worker2.memoryFree < application.memoryPerExecutor
因此,下一次分配就去worker1上了:
Worker1:coresFree=4 memoryFree=8.5G assignedExecutors=3 assignedCores=6
Worker2:coresFree=3 memoryFree=0M assignedExecutors=2 assignedCores=4
Worker3:coresFree=1 memoryFree=1.5G assignedExecutors=1 assignedCores=2
totalExecutors:6,totalCores=12
ok,由于已经分配了12个core,达到了application的要求,所以不在为这个application调度了。
4.非spreadOut算法
那么非spraadOut算法呢?他是逮到一个worker如果不把他的资源耗尽了是不会放手的:
Worker1:coresFree=8 memoryFree=9.5G assignedExecutors=1 assignedCores=2
Worker2:coresFree=7 memoryFree=1G assignedExecutors=0 assignedCores=0
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:1,totalCores=2
Worker1:coresFree=6 memoryFree=9.0G assignedExecutors=2 assignedCores=4
Worker2:coresFree=7 memoryFree=1G assignedExecutors=0 assignedCores=0
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:2,totalCores=4
Worker1:coresFree=4 memoryFree=8.5 assignedExecutors=3 assignedCores=6
Worker2:coresFree=7 memoryFree=1G assignedExecutors=0 assignedCores=0
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:3,totalCores=6
Worker1:coresFree=2 memoryFree=8.0G assignedExecutors=4 assignedCores=8
Worker2:coresFree=7 memoryFree=1G assignedExecutors=0 assignedCores=0
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:4,totalCores=8
Worker1:coresFree=0 memoryFree=7.5G assignedExecutors=5 assignedCores=10
Worker2:coresFree=7 memoryFree=1G assignedExecutors=0 assignedCores=0
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:5,totalCores=10
当worker1的coresfree已经耗尽了。由于application需要12个core,而这里才分配了10个,所以还要继续往下分配:
Worker1:coresFree=0 memoryFree=7.5G assignedExecutors=5 assignedCores=10
Worker2:coresFree=5 memoryFree=512G assignedExecutors=1 assignedCores=2
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:6,totalCores=12
ok,最终分配来12个core,满足了application的要求。
对比:
spreadOut算法中,是以round-robin方式,轮询的在worker节点上分配Executor进程,即以如下序列分配:worker1,worker2... ... worker n,worker1... .... worker n
非spreadOut算法中,逮者一个worker就不放手,直到满足一下条件之一:
worker.freeCores < application.coresPerExecutor 或者 worker.memoryFree<application.memoryPerExecutor。
在上面两个例子中,虽然最终都分配了6个Executor进程和12个core,但是spreadOut方式下,6个Executor进程分散在不同的worker节点上,充分利用了spark集群的worker节点,而非spreadOut方式下,只在worker1和worker2上分配了Executor进程,并没有充分利用spark worker节点。
5.小插曲,spreadOut + oneExecutorPerWorker 算法
spark还有一个叫做”oneExecutorPerWorker“机制,即一个worker上启动一个Executor进程,下面只是简单的说一下得了:
Worker1:coresFree=8 memoryFree=9.5G assignedExecutors=1 assignedCores=2
Worker2:coresFree=7 memoryFree=1G assignedExecutors=0 assignedCores=0
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:1,totalCores=2
Worker1:coresFree=8 memoryFree=9.5G assignedExecutors=1 assignedCores=2
Worker2:coresFree=5 memoryFree=512M assignedExecutors=1 assignedCores=2
Worker3:coresFree=3 memoryFree=2G assignedExecutors=0 assignedCores=0
totalExecutors:2,totalCores=4
Worker1:coresFree=8 memoryFree=9.5G assignedExecutors=1 assignedCores=2
Worker2:coresFree=5 memoryFree=512M assignedExecutors=1 assignedCores=2
Worker3:coresFree=1 memoryFree=1.5G assignedExecutors=1 assignedCores=2
totalExecutors:3,totalCores=6
Worker1:coresFree=6 memoryFree=9.0G assignedExecutors=1 assignedCores=4
Worker2:coresFree=3 memoryFree=512M assignedExecutors=1 assignedCores=2
Worker3:coresFree=1 memoryFree=1.5G assignedExecutors=1 assignedCores=2
totalExecutors:3,totalCores=8
Worker1:coresFree=6 memoryFree=9.0G assignedExecutors=1 assignedCores=4
Worker2:coresFree=2 memoryFree=0 M assignedExecutors=1 assignedCores=4
Worker3:coresFree=1 memoryFree=1.5G assignedExecutors=1 assignedCores=2
totalExecutors:3,totalCores=10
Worker1:coresFree=4 memoryFree=9.5G assignedExecutors=1 assignedCores=6
Worker2:coresFree=2 memoryFree=0 M assignedExecutors=1 assignedCores=4
Worker3:coresFree=1 memoryFree=1.5G assignedExecutors=1 assignedCores=2
totalExecutors:3,totalCores=12
spreadOut和oneExecutorPerWorker对比发现,唯一的不同就是Executor进程的数量,一个是6,一个是3。
这里在额外扩展一下,假设application的maxCores=14,而不是12,那么接着上面那个worker列表来:
Worker1:coresFree=4 memoryFree=9.5G assignedExecutors=1 assignedCores=6
Worker2:coresFree=0 memoryFree=0M assignedExecutors=1 assignedCores=6
Worker3:coresFree=1 memoryFree=1.5G assignedExecutors=1 assignedCores=2
totalExecutors:3,totalCores=12
虽然worker2.memoryFree=0,但是仍然可以继续在他上面分配core,因为onExecutorPerWorker机制不检查内存的限制。
6.源码实现
在初始化SparkContext时其中要点之一是:taskScheduler如何注册application,及executor如何反向注册。
在sc中会调用createTaskScheduler(),createTaskScheduler()创建完成后会调用scheduler.start()方法在刚方法中会调用backend.start()方法,最终会通过clientActor()调用registerWithMaster()来注册Application
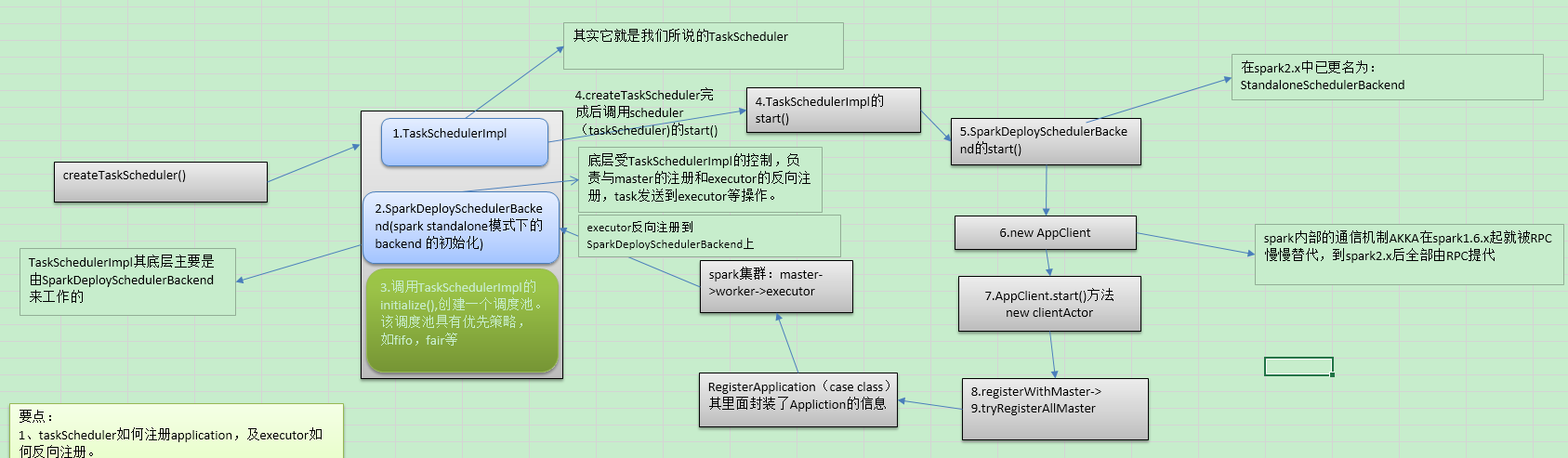
core\src\main\scala\org\apache\spark\deploy\master\Master.scala中的消息接收方法override def receive: PartialFunction[Any, Unit]中使用匹配模式接收客户端中发送来的消息
case RegisterApplication(description, driver) => {
// TODO Prevent repeated registrations from some driver
//standby master不调度
if (state == RecoveryState.STANDBY) {
// ignore, don't send response
} else {
logInfo("Registering app " + description.name)
// 用ApplicationDescription创建ApplicationInfo
val app = createApplication(description, driver)
// 注册app,即将其加入到waitingApps中
registerApplication(app)
logInfo("Registered app " + description.name + " with ID " + app.id)
// 将app加入持久化引擎,主要是为了故障恢复
persistenceEngine.addApplication(app)
// 向driver反向注册其实是发送RegisteredApplication消息给StandaloneSchedulerBackend的
// StandaloneAppClient的ClientEndpoint表明master已经注册了这个app
driver.send(RegisteredApplication(app.id, self))
// 为waitingApps中的app调度资源
schedule()
}
}
/**
* Schedule the currently available resources among waiting apps. This method will be called
* every time a new app joins or resource availability changes.
*/
// 调用schedule()从所有可用的worker中找出可以运行该driver的worker,然后将driver和worker建立联系,然后启动driver
private def schedule() {
// 如果说master 的状态不是ALIVE的话就直接返回,也就是说master standby是不会对Application等资源进行调度
if (state != RecoveryState.ALIVE) { return }
// First schedule drivers, they take strict precedence over applications
// Randomization helps balance drivers
// Random.shuffle的原理就是对传入的集合的元素进行随机的打乱
// 取出workers中所有之前注册上来的worker,进行过滤,必须是状态为ALIVE的worker
val shuffledAliveWorkers = Random.shuffle(workers.toSeq.filter(_.state == WorkerState.ALIVE))
val numWorkersAlive = shuffledAliveWorkers.size
var curPos = 0
// 首先,调度driver,为什么要调度?什么情况下会注册driver?并导致driver会被调度
// 其实只有用yarn-cluster模式提交的时候,才会注册driver;因为standalone client和yarn-client模式,都会在本地直接
// 启动driver,而不会来注册driver,就更不可能让master调度driver了
// driver的调度机制
// 遍历waitingDrivers的ArrayBuffer
for (driver <- waitingDrivers.toList) { // iterate over a copy of waitingDrivers
// We assign workers to each waiting driver in a round-robin fashion. For each driver, we
// start from the last worker that was assigned a driver, and continue onwards until we have
// explored all alive workers.
var launched = false
var numWorkersVisited = 0
// 只要还有活着的Workers就继续遍历,而且当前这个driver还没有启动,即launched为false
while (numWorkersVisited < numWorkersAlive && !launched) {
val worker = shuffledAliveWorkers(curPos)
numWorkersVisited += 1
// 如果当前的这个worker的空闲内存量大于等于driver需要的内存
// 并且worker的空闲cpu数量,大于等于driver需要的cpu数量
if (worker.memoryFree >= driver.desc.mem && worker.coresFree >= driver.desc.cores) {
// 启动driver
launchDriver(worker, driver)
// 并将driver从waitingDrivers队列中移除
waitingDrivers -= driver
launched = true
}
curPos = (curPos + 1) % numWorkersAlive
}
}
// 启动所有在worker上的executor --- 即为application调度资源
startExecutorsOnWorkers()
}
/**
* Schedule and launch executors on workers
*/
private def startExecutorsOnWorkers(): Unit = {
// Right now this is a very simple FIFO scheduler. We keep trying to fit in the first app
// in the queue, then the second app, etc.
// 为waitingApps中的app调度资源,app.coresLeft是app还有多少core没有分配
for (app <- waitingApps if app.coresLeft > 0) {
val coresPerExecutor: Option[Int] = app.desc.coresPerExecutor
// Filter out workers that don't have enough resources to launch an executor
// 筛选出状态为ALIVE并且这个worker剩余内存,剩余core都大于等于app的要求,然后按照coresFree降序排列
val usableWorkers = workers.toArray.filter(_.state == WorkerState.ALIVE)
.filter(worker => worker.memoryFree >= app.desc.memoryPerExecutorMB &&
worker.coresFree >= coresPerExecutor.getOrElse(1))
.sortBy(_.coresFree).reverse
//在usableWorkers上为app分配Executor
val assignedCores = scheduleExecutorsOnWorkers(app, usableWorkers, spreadOutApps)
// Now that we've decided how many cores to allocate on each worker, let's allocate them
// 在worker上启动Executor进程
for (pos <- 0 until usableWorkers.length if assignedCores(pos) > 0) {
allocateWorkerResourceToExecutors(
app, assignedCores(pos), coresPerExecutor, usableWorkers(pos))
}
}
}
这个方法做了如下事情:
1.筛选出可用的worker,即usableWorkers,如果一个worker满足以下所有条件,那么这个worker就被添加到usableWorkers中:
Alive
worker.memoryFree >= app.desc.memoryPerExecutorMB
worker.coresFree >= coresPerExecutor
2.assignedCores是一个数组,assignedCores[i]里面存储了需要在usableWorkers[i]上分配的core个数,譬如如果assingedCores[1]=2,那么就需要在usableWorkers[1]上分配2个core。
spreadOutApps算法的具体实现如下代码:
/**
* Schedule executors to be launched on the workers.
* Returns an array containing number of cores assigned to each worker.
*
* There are two modes of launching executors. The first attempts to spread out an application's
* executors on as many workers as possible, while the second does the opposite (i.e. launch them
* on as few workers as possible). The former is usually better for data locality purposes and is
* the default.
*
* The number of cores assigned to each executor is configurable. When this is explicitly set,
* multiple executors from the same application may be launched on the same worker if the worker
* has enough cores and memory. Otherwise, each executor grabs all the cores available on the
* worker by default, in which case only one executor may be launched on each worker.
*
* It is important to allocate coresPerExecutor on each worker at a time (instead of 1 core
* at a time). Consider the following example: cluster has 4 workers with 16 cores each.
* User requests 3 executors (spark.cores.max = 48, spark.executor.cores = 16). If 1 core is
* allocated at a time, 12 cores from each worker would be assigned to each executor.
* Since 12 < 16, no executors would launch [SPARK-8881].
*/
private def scheduleExecutorsOnWorkers(
app: ApplicationInfo,
usableWorkers: Array[WorkerInfo],
spreadOutApps: Boolean): Array[Int] = {
val coresPerExecutor = app.desc.coresPerExecutor
val minCoresPerExecutor = coresPerExecutor.getOrElse(1)
val oneExecutorPerWorker = coresPerExecutor.isEmpty
val memoryPerExecutor = app.desc.memoryPerExecutorMB
val numUsable = usableWorkers.length
val assignedCores = new Array[Int](numUsable) // Number of cores to give to each worker
val assignedExecutors = new Array[Int](numUsable) // Number of new executors on each worker
var coresToAssign = math.min(app.coresLeft, usableWorkers.map(_.coresFree).sum)
/** Return whether the specified worker can launch an executor for this app. */
//是否可以在一个worker上分配Executor
def canLaunchExecutor(pos: Int): Boolean = {
val keepScheduling = coresToAssign >= minCoresPerExecutor
val enoughCores = usableWorkers(pos).coresFree - assignedCores(pos) >= minCoresPerExecutor
// If we allow multiple executors per worker, then we can always launch new executors.
// Otherwise, if there is already an executor on this worker, just give it more cores.
val launchingNewExecutor = !oneExecutorPerWorker || assignedExecutors(pos) == 0
if (launchingNewExecutor) {
//在这里,需要检查worker的空闲core和内存是否够用
val assignedMemory = assignedExecutors(pos) * memoryPerExecutor
val enoughMemory = usableWorkers(pos).memoryFree - assignedMemory >= memoryPerExecutor
val underLimit = assignedExecutors.sum + app.executors.size < app.executorLimit
keepScheduling && enoughCores && enoughMemory && underLimit
} else {
// We're adding cores to an existing executor, so no need
// to check memory and executor limits
//尤其需要注意的是,oneExecutorPerWorker机制下,不检测内存限制,很重要。
keepScheduling && enoughCores
}
}
// Keep launching executors until no more workers can accommodate any
// more executors, or if we have reached this application's limits
var freeWorkers = (0 until numUsable).filter(canLaunchExecutor)
while (freeWorkers.nonEmpty) {
freeWorkers.foreach { pos =>
var keepScheduling = true
while (keepScheduling && canLaunchExecutor(pos)) {
//要分配的cores
coresToAssign -= minCoresPerExecutor
//已分配的cores
assignedCores(pos) += minCoresPerExecutor
// If we are launching one executor per worker, then every iteration assigns 1 core
// to the executor. Otherwise, every iteration assigns cores to a new executor.
//一个worker只启动一个Executor
if (oneExecutorPerWorker) {
assignedExecutors(pos) = 1
} else {
assignedExecutors(pos) += 1
}
// Spreading out an application means spreading out its executors across as
// many workers as possible. If we are not spreading out, then we should keep
// scheduling executors on this worker until we use all of its resources.
// Otherwise, just move on to the next worker.
//如果没有开启spreadOUt算法,就一直在一个worker上分配,直到不能再分配为止。
if (spreadOutApps) {
keepScheduling = false
}
}
}
freeWorkers = freeWorkers.filter(canLaunchExecutor)
}
assignedCores
}
/**
* Allocate a worker's resources to one or more executors.
* @param app the info of the application which the executors belong to
* @param assignedCores number of cores on this worker for this application
* @param coresPerExecutor number of cores per executor
* @param worker the worker info
*/
private def allocateWorkerResourceToExecutors(
app: ApplicationInfo,
assignedCores: Int,
coresPerExecutor: Option[Int],
worker: WorkerInfo): Unit = {
// If the number of cores per executor is specified, we divide the cores assigned
// to this worker evenly among the executors with no remainder.
// Otherwise, we launch a single executor that grabs all the assignedCores on this worker.
//计算要创建多少个Executor进程,默认值是1.
val numExecutors = coresPerExecutor.map { assignedCores / _ }.getOrElse(1)
val coresToAssign = coresPerExecutor.getOrElse(assignedCores)
for (i <- 1 to numExecutors) {
val exec = app.addExecutor(worker, coresToAssign)
//真正的启动Executor进程了。
launchExecutor(worker, exec)
app.state = ApplicationState.RUNNING
}
}
spark application调度机制(spreadOutApps,oneExecutorPerWorker 算法)的更多相关文章
- Spark Application的调度算法
要想明白spark application调度机制,需要回答一下几个问题: 1.谁来调度? 2.为谁调度? 3.调度什么? 3.何时调度? 4.调度算法 前四个问题可以用如下一句话里来回答:每当集群资 ...
- 【Spark 深入学习 04】再说Spark底层运行机制
本节内容 · spark底层执行机制 · 细说RDD构建过程 · Job Stage的划分算法 · Task最佳计算位置算法 一.spark底层执行机制 对于Spark底层的运行原理,找到了一副很好的 ...
- Spark的调度
作业调度简介 设计者将资源进行不同粒度的抽象建模,然后将资源统一放入调度器,通过一定的算法进行调度,最终要达到高吞吐或者低访问延时的目的. Spark在各种运行模式中各个角色实现的功能基本一致,只不过 ...
- 通过案例对 spark streaming 透彻理解三板斧之三:spark streaming运行机制与架构
本期内容: 1. Spark Streaming Job架构与运行机制 2. Spark Streaming 容错架构与运行机制 事实上时间是不存在的,是由人的感官系统感觉时间的存在而已,是一种虚幻的 ...
- 通过案例对 spark streaming 透彻理解三板斧之二:spark streaming运行机制
本期内容: 1. Spark Streaming架构 2. Spark Streaming运行机制 Spark大数据分析框架的核心部件: spark Core.spark Streaming流计算. ...
- quartz集群调度机制调研及源码分析---转载
quartz2.2.1集群调度机制调研及源码分析引言quartz集群架构调度器实例化调度过程触发器的获取触发trigger:Job执行过程:总结:附: 引言 quratz是目前最为成熟,使用最广泛的j ...
- 定时组件quartz系列<三>quartz调度机制调研及源码分析
quartz2.2.1集群调度机制调研及源码分析引言quartz集群架构调度器实例化调度过程触发器的获取触发trigger:Job执行过程:总结:附: 引言 quratz是目前最为成熟,使用最广泛的j ...
- (1)quartz集群调度机制调研及源码分析---转载
quartz2.2.1集群调度机制调研及源码分析 原文地址:http://demo.netfoucs.com/gklifg/article/details/27090179 引言quartz集群架构调 ...
- 【Spark】Spark的Shuffle机制
MapReduce中的Shuffle 在MapReduce框架中,shuffle是连接Map和Reduce之间的桥梁,Map的输出要用到Reduce中必须经过shuffle这个环节,shuffle的性 ...
随机推荐
- 【English】What is a Java StringWriter, and when should I use it?(转帖)
转帖地址:http://www.it1352.com/989366.html Question: What is a Java StringWriter, and when should I use ...
- JMeter-正则表达式(取出银行卡号后4位)
{ : "custName":"奚红艳", : "banks": : [ : : { : : : "id":" ...
- 深入理解Flink ---- End-to-End Exactly-Once语义
上一篇文章所述的Exactly-Once语义是针对Flink系统内部而言的. 那么Flink和外部系统(如Kafka)之间的消息传递如何做到exactly once呢? 问题所在: 如上图,当sink ...
- shell脚本中用到的计算
在shell脚本中计算一般会涉及到let.$(()).$[].bc(另扩展expr).其中let.$(()).$[]都是用来做基本整数运算,bc可以用来做浮点运算. (1).let.$(()).$[] ...
- python函数,定义,参数,返回值
python中可以将某些具备一定功能的代码写成一个函数,通过函数可以在一定程度上减少代码的冗余,节约书写代码的时间.因为有一些代码实现的功能我们可能会在很多地方用到. 1.函数的声明与定义 通过def ...
- swift 第二课 基础知识-2
setter 和getter 的使用--> 适合计算使用 struct Point { var x = 0.0, y=0.0 } struct Size { var width = 0.0, h ...
- WordPress自定义循环
我们在学WordPress的时候,最常用到的就是循环了.写模板的时候,多数的时间都是和循环打交道的.如果你不能很详细的了解WordPress的循环,是很难写出模板来的. 而WordPress自定义循环 ...
- Go单引号和双引号区别
首先做个测试,看下面那个选项是正确的: A. str:='abc'+'123'B. str:="abc"+"123"C. str:='123'+"ab ...
- Python绘制可爱的卡通人物 | 【turtle使用】
Turtle库 简介 什么是Turtle 首先,turtle库是一个点线面的简单图像库,能够完成一些比较简单的几何图像可视化.它就像一个小乌龟,在一个横轴为x.纵轴为y的坐标系原点,(0,0)位置开始 ...
- spring效验
相关依赖 如果开发普通 Java 程序的的话,你需要可能需要像下面这样依赖: <dependency> <groupId>org.hibernate.validator< ...