数据分析基础之pandas & numpy
一、jupyter的常用快捷键
- 插入cell: a, b a是after从后插入 a是before 从前插入
- 删除cell: dd, x 都可以
- 修改cell的模式:m, y
- tab: 自动补全
- 执行cell: shift + enter
- 打开帮助文档:shift + tab
二、 numpy
1. 创建数组
import numpy as np
np.array()
一维数组创建:np.array([1,2,3])
2. 使用matplotlib获取一个numpy的数组,数组来源于一张图片
import matplotlib.pyplot as plt
img_arr = plt.imread('./cat.jpg') 展示一个数组:
plt,imshow(img_arr)
3. 使用np的routines函数创建
np.linspace(0,100,num=50) 返回一个一维的等差数列
np.random.randint(low,high=None,size=None,dtype="1") 返回一个随机数组
4. array的属性
img_arr.shape 返回形状
img_arr.ndim 返回纬度
img_arr.dtype 返回元素的类型
img_arr.size 返回元素有多少个
4.array的基本操作
4.1. 索引 (一维与列表完全一致 多维同理)
arr[0] #arr[行索引]
4.2. 切片 (一维与列表完全一致 多维同理)
arr[0:3] #切前三行
arr[:,0:2] #切前两列
arr[0:2,0:2] #切前两行的前两列
arr[::-1] #行翻转
arr[:,::-1] #列翻转
arr[::-1,::-1] # 全部翻转
4.3. 运算操作
arr.sum(axis=0) 求列和 # axis = 0 表示y轴 1表示x轴
三、Pandas的数据结构 (dataframe只能是二维的)
1. DataFrame是一个[表格型]的数据结构,DataFrame按一定顺序排列的多列数据组成,设计初衷是将Series的使用场景从一维拓展到多维。DataFrame既有行索引,也有列索引。
行索引:index
列索引:columns
值:values
2. 使用nparray创建DataFrame
from pandas import DataFrame,Series
import numpy as np DataFrame(data=np.random.randint(0,100,size=(6,8)))
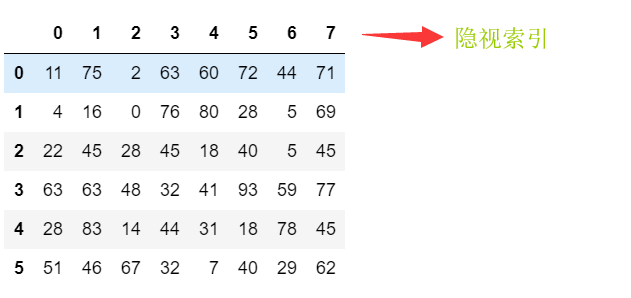
创建DataFrame时指定显示索引
df = DataFrame(data=np.random.randint(0,100,size=(2,3)),index=['a','b'],columns=['A','B','C'])
DataFrame属性
df.values #返回值
df.columns #返回列索引
df.index #返回列索引
df.shape #返回形状 分别对应哪个纬度有几个数据
基于两种方式创建Dataframe表如下:
方法一:通过np实现
df = DataFrame(data=np.random.randint(0,100,size=(2,3)),index=['a','b'],columns=['A','B','C'])
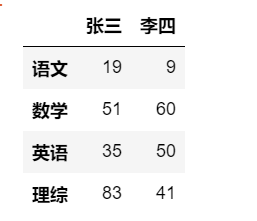
方法二: 字典实现
DataFrame(data=np.random.randint(0,100,size=(4,2)),index=['语文','数学','英语','理综'],columns=['张三','李四'])
3. DataFrame的索引切片
3.1 列索引取值
如果设置了显示索引直接中扩加列索引名
df['张三'] 3.2 对行进行索引
- 使用.loc[] 加index来进行索引
- 使用.iloc[] 加正式来进行索引 3.3 切片
df.iloc[行,列]
如:df.iloc[2,0] df[隐式索引] 行切片 ps:列切片除了显示索引以外 必须加loc或者iloc才行 索引总结:
- 取行:df.loc[行索引]
- 取列:df[列索引]
- 取元素:df:iloc[行索引,列索引]
- iloc[隐式索引]
- loc[显示索引] 切片总结:
- 切行:df[行切片]
- 切列:df.iloc[:,切列]
4. DataFrame的运算
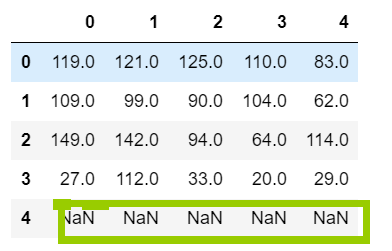
df1 = DataFrame(data=np.random.randint(0,100,size=(4,5)))
df2 = DataFrame(data=np.random.randint(0,100,size=(5,5)))
df1 + df2 相加得来的结果有一行NaN
4. 操作实例 基于Tushare分析某某股票需求如下:
4.1 使用tushare包获取某股票的历史行情数据
4.2 输出该股票所有收盘比开盘上涨3%以上的日期
4.3 输出该股票所有开盘比前日收盘跌幅超过2%的日期
4.4 假如我从2010年1月1日开始,每月第一个交易日买入一首股票,每年最后一个交易日卖出所有股票到今位置,收益如何?
# 使用tushare包获取某股票的历史行情数据
import tushare as ts
df = ts.get_k_data(code='600519',start='2000-01-01')
df.to_csv('./moutai.csv') #将股票数据写入到本地
#从本地文件中读取数据到df并删除多余的列
df = pd.read_csv('./moutai.csv')
df.drop(labels='Unnamed: 0',axis=1,inplace=True)
# 将元数据中date这一列作为行索引,且将date中的数据类型转成时间序列
df = pd.read_csv('./moutai.csv',index_col='date',parse_dates=['date'])
df.drop(labels='Unnamed: 0',axis=1,inplace=True)
df.head(5)
#输出该股票所有收盘比开盘上涨3%以上的日期
#(收盘-开盘)/开盘 >0.03
(df['close']-df['open'])/df['open'] > 0.03
#看到布尔类型的数据,马上将该组数据作为行数据的索引(值保留True对应的行数据)
df.loc[(df['close']-df['open'])/df['open'] > 0.03] #符合要求的行数据
df.loc[(df['close']-df['open'])/df['open'] > 0.03].index
#输出该股票所有开盘比前日收盘跌幅超过2%的日期
#(开盘-前日收盘)/前日收盘 < -0.02
df.loc[(df['open']-df['close'].shift(1))/df['close'].shift(1)< -0.02].index
#假如我从2010年1月1日开始,每月第一个交易日买入一首股票,每年最后一个交易日卖出所有股票到今位置,收益如何
data = df['2010':'2019']
#买股票 resample 数据的重新取样
df_monthly = data.resample('M').first()
cost = df_monthly['open'].sum()*100
#卖股票
df_yearly = data.resample('A').last()[:-1]
recv = df_yearly['open'].sum()*1200
#19年剩余股票的价值
last = 1100 * data.iloc[-1]['open']
#总收益
(recv + last)-cost
四、DataFrame 空值清洗
有两种丢失数据:
- None
- np.nan(NaN)
1. None 是python自带的,不能参与到任何计算中
2.na.nan(NaN) 是浮点类型,能参与计算中,但计算结果总是NaN
ps:pandas中的None与np.nan都视作np.nan
模拟空数据并做清洗
#模拟数据: #导包
import numpy as np
from pandas import DataFrame,Series
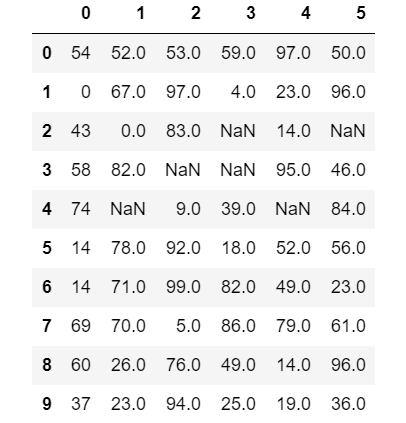
import pandas as pd df = DataFrame(data=np.random.randint(0,100,size=(10,6)))
#将某些数据元素赋值为nan
df.iloc[3,2] = None
df.iloc[3,3] = None
df.iloc[2,3] = None
df.iloc[4,4] = None
df.iloc[2,5] = None
df.iloc[4,1] = np.nan #结果如下:
#判断函数
isnul()
#df.isnull().all(axis=1) all() 如果所对应的行有false就返回false
#df.isnull().any(axis=1) any() 如果所对应的行含有true就返回true
notnull()
#将空所对应的行删除
#方法一:
df.loc[df.notnull().all(axis=1)]
#方法二:
drop_index = df.loc[df.isnull().any(axis=1)].index
df.drop(labels=drop_index,axis=0)
方法三: 直接通过dropna() 函数删除
df.dropna(axis=0)
x和y轴 跟drop相关的方法里面 行用0表示 列用1表示 其它地方行用1表示 列用0表示
#填充函数 fillna()
df.fillna(value=-999) #把所有的控制都填充成-999
df.fillna(method='ffill',axis=0) #向前填充
df.fillna(method='bfill',axis=0) #向后填充
五、pandas的拼接操作
概述:pandas的拼接分为两种:
级联:pd.cancat, pd.append
合并:pd.merge, pd.join
import numpy as np
import pandas as pd
from pandas import DataFrame
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df2 = df1
#数据结果
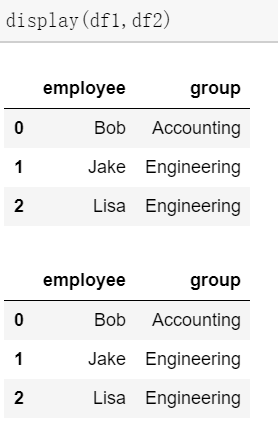
#列级联
pd.concat((df1,df2),axis=0)
#数据不一样的时候级联 数据对不上的地方默认NaN
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df2 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df2.columns = ['employee','groups']
df2['salary'] = [1000,2000,3000]
#级联的结果
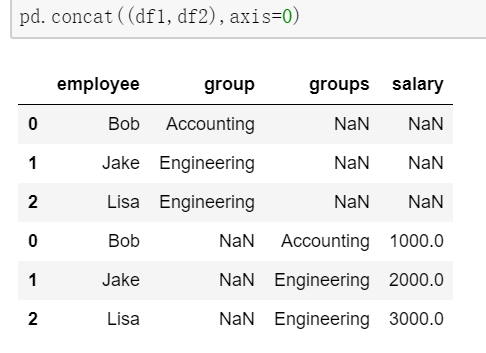
pd.concat((df1,df2),axis=0,join='inner') #只能级联能级联的项
pd.concat((df1,df2),axis=0,join='outer') #你那个不能级联的都级联,保证数据的完整性
2. 合并pd.merge()
把两张表里面的数据整合, 一般两张表要有一列数据是一致的
默认以两张表相同的列作为合并条件,也可以自己指定,how指定合并条件,on指定哪一列作为合并条件
如果两张表没有共同列也可以用left_on=左表列或者right_on=右表列作为合并条件 ,
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':['2004','2008','2012']})
六、pandas 高级操作
1. replace()函数:替代元素
# replace 基本操作 #造数据
import numpy as np
import pandas as pd
from pandas import DataFrame,Series df = DataFrame(data=np.random.randint(0,100,size=(10,8)))
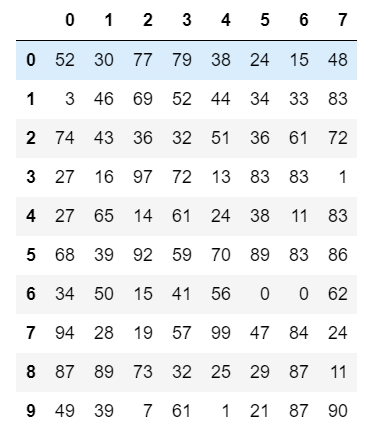
# 把1替换成one
df.replace(to_replace=1,value='one')
# 把第7列的1 替换成one
df.replace(to_replace={7:1},value='one')
2. map() 映射
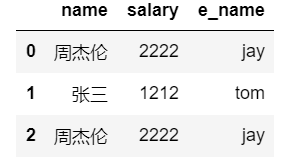
# 映射小案例
dic = {
'name':['周杰伦','张三','周杰伦'],
'salary':[2222,1212,2222]
}
df = DataFrame(data=dic)
df
打印结果:
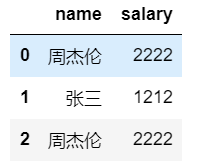
# 映射关系表
dic= {
'周杰伦':'jay',
'张三':'tom'
}
df['e_name'] = df['name'].map(dic)
df
实例2:用map结合函数充当一种运算工具
def after_salary(s):
return s-(s-3000)*0.5
#超过3000部分的钱缴纳50%的税a
df['after_salary'] = df['salary'].map(after_salary)
3.使用集合函数对数据异常值检测和过滤
使用df.std()函数可以求得DataFrame对象每一列的标准差
# 创建一个1000行3列的df范围(0~1),要求每一列的标准差
df = DataFrame(data=np.random.random(size=(1000,3)),columns=('A','B','C'))
#去除C列两倍的标准差
double_std = df['C'].std()*2
df['C'] > double_std
indexes = df.loc[df['C'] > double_std].index
df.drop(labels=indexes,axis=0)
4. 数据分类处理
4.1 分组 group_by 和mean() .to_dict()
from pandas import DataFrame,Series #造数据
df = DataFrame({'item':['Apple','Banana','Orange','Banana','Orange','Apple'],
'price':[4,3,3,2.5,4,2],
'color':['red','yellow','yellow','green','green','green'],
'weight':[12,20,50,30,20,44]}) # 分组
df.groupby(by='item',axis=0).groups # 给df创建一个新列,内容为各种水果的平均价格
df.groupby(by='item').mean()
s_price = df.groupby(by='item')['price'].mean()
dic = s_price.to_dict()
df['mean_price'] = df['item'].map(dic)
未完待续......
数据分析基础之pandas & numpy的更多相关文章
- 最直白、最易懂的话带你认识和学会---数据分析基础包之numpy的使用
前言 numpy是一个很基础很底层的模块,其重要性不言而喻,可以说对于新手来说是最基础的入门必须要学习的其中之一.在很多数据分析,深度学习,机器学习亦或是人工智能领域的模块中,很多的底层都会用到这个模 ...
- python数据分析---第04章 NumPy基础:数组和矢量计算
NumPy(Numerical Python的简称)是Python数值计算最重要的基础包.大多数提供科学计算的包都是用NumPy的数组作为构建基础. NumPy的部分功能如下: ndarray,一个具 ...
- 动态可视化 数据可视化之魅D3,Processing,pandas数据分析,科学计算包Numpy,可视化包Matplotlib,Matlab语言可视化的工作,Matlab没有指针和引用是个大问题
动态可视化 数据可视化之魅D3,Processing,pandas数据分析,科学计算包Numpy,可视化包Matplotlib,Matlab语言可视化的工作,Matlab没有指针和引用是个大问题 D3 ...
- Python数据分析入门之pandas基础总结
Pandas--"大熊猫"基础 Series Series: pandas的长枪(数据表中的一列或一行,观测向量,一维数组...) Series1 = pd.Series(np.r ...
- python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20 python中pandas数据分析基础(数据重塑与轴向转化.数据分组与分组运算.离散化处理.多数据文件合并操作) 3.1 数据重塑与轴向转换1.层次化索引使得一个轴上拥 ...
- pyhton pandas数据分析基础入门(一文看懂pandas)
//2019.07.17 pyhton中pandas数据分析基础入门(一文看懂pandas), 教你迅速入门pandas数据分析模块(后面附有入门完整代码,可以直接拷贝运行,含有详细的代码注释,可以轻 ...
- Numpy使用大全(python矩阵相关运算大全)-Python数据分析基础2
//2019.07.10python数据分析基础——numpy(数据结构基础) import numpy as np: 1.python数据分析主要的功能实现模块包含以下六个方面:(1)numpy—— ...
- 利用Python进行数据分析 基础系列随笔汇总
一共 15 篇随笔,主要是为了记录数据分析过程中的一些小 demo,分享给其他需要的网友,更为了方便以后自己查看,15 篇随笔,每篇内容基本都是以一句说明加一段代码的方式, 保持简单小巧,看起来也清晰 ...
- python及pandas,numpy等知识点技巧点学习笔记
python和java,.net,php web平台交互最好使用web通信方式,不要使用Jypython,IronPython,这样的好处是能够保持程序模块化,解耦性好 python允许使用'''.. ...
随机推荐
- 最新react-native(Expo)安装使用antd-mobile-rn组件库
1\安装antd-mobile-rn 库 npm install antd-mobile-rn --save 2.按需加载 npm install babel-plugin-import --save ...
- ubuntu Tensorflow object detection API 开发环境搭建
https://blog.csdn.net/dy_guox/article/details/79111949 luo@luo-All-Series:~$ luo@luo-All-Series:~$ s ...
- centos 7设置limit,不生效问题
1:记录未修改之前的ulimit值 [root@bogon ~]# ulimit -a 2:修改配置文件 vim /etc/security/limits.conf 在后面添加 * s ...
- 【c++基础】二进制格式输出char类型
前言 使用CAN通信时将信号转换为char类型进行传输,要查看传输的信息是否正确需要将char类型数据以二进制格式输出: code #include <iostream> int main ...
- Spring Boot后台运行
#!/bin/bash nohup java -jar -Dspring.profiles.active=prop app-0.0.1.jar > app.log 2>&1 &am ...
- Tomcat 部署方式
显示 部署 1.添加context元素方式(server.xml) <Host appBase="webapps" autoDeploy="true" n ...
- 集群架构05·备份服务rsync
初识 开源,多功能,全量和增量的本地或远程数据同步备份的优秀工具,remote synchronization 俩服务器定/实时备份cron+rsync,数据同步,全网备份 一个rsync相当于scp ...
- AnroidStudio gradle版本和android插件的版本依赖
- 最新 巨人网络java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.巨人网络等10家互联网公司的校招Offer,因为某些自身原因最终选择了巨人网络.6.7月主要是做系统复习.项目复盘.Leet ...
- mysql常用引擎
经常用MySQL数据库,但是,你在用的时候注意过没有,数据库的存储引擎,可能有注意但是并不清楚什么意思,可能根本没注意过这个问题,使用了默认的数据库引擎,当然我之前属于后者,后来成了前者,然后就有了这 ...