利用Python进行数据分析_Numpy_基础_2
Numpy数据类型包括:
int8、uint8、int16、uint16、int32、uint32、int64、uint64、float16、float32、float64、float128、complex64、complex128、complex256、bool、object、string_、unicode_
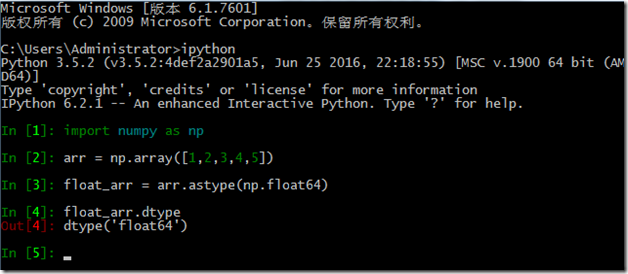
astype
显示转换数组类型的方法
例如:
NumPy数组的索引和切片
索引
和python列表差不多,基本上没啥区别
切片
NumPy数组的切片出来的数值改变,就会改变NumPy数组的源数组的值。NumPy数组的切片是源数组的视图,而不是新复制出来的一个数组。从下面的例子,我们可以看到arr[,]= ,arr的数组变化了,data数组对应位置的数值也变化了。
In []: data = np.random.randn(,) In []: data
Out[]:
array([[-1.68867271, -0.89369286, -0.0288363 , 0.73855122],
[-0.13084603, 0.43972144, 0.73542583, 1.99925332],
[ 0.04291022, -0.91963212, 3.09214837, -0.6070068 ],
[-0.01416294, -1.46576298, 1.42196278, 0.84758994]]) In []: arr = data[:,:] In []: arr
Out[]:
array([[-0.91963212, 3.09214837, -0.6070068 ],
[-1.46576298, 1.42196278, 0.84758994]]) In []: arr = In []: data
Out[]:
array([[-1.68867271, -0.89369286, -0.0288363 , 0.73855122],
[-0.13084603, 0.43972144, 0.73542583, 1.99925332],
[ 0.04291022, -0.91963212, 3.09214837, -0.6070068 ],
[-0.01416294, -1.46576298, 1.42196278, 0.84758994]]) In []: arr
Out[]: In []: arr = data[:,:] In []: arr
Out[]:
array([[-0.91963212, 3.09214837, -0.6070068 ],
[-1.46576298, 1.42196278, 0.84758994]]) In []: arr ==
Out[]:
array([[False, False, False],
[False, False, False]], dtype=bool) In []: arr
Out[]:
array([[-0.91963212, 3.09214837, -0.6070068 ],
[-1.46576298, 1.42196278, 0.84758994]]) In []: arr[,]= In []: arr
Out[]:
array([[-0.91963212, 3.09214837, -0.6070068 ],
[-1.46576298, . , 0.84758994]]) In []: data
Out[]:
array([[-1.68867271, -0.89369286, -0.0288363 , 0.73855122],
[-0.13084603, 0.43972144, 0.73542583, 1.99925332],
[ 0.04291022, -0.91963212, 3.09214837, -0.6070068 ],
[-0.01416294, -1.46576298, . , 0.84758994]]) In []:
如果要复制NumPy数组的切片,则可以使用显示复制方法copy()
In []: data
Out[]:
array([[-1.68867271, -0.89369286, -0.0288363 , 0.73855122],
[-0.13084603, 0.43972144, 0.73542583, 1.99925332],
[ 0.04291022, -0.91963212, 3.09214837, -0.6070068 ],
[-0.01416294, -1.46576298, . , 0.84758994]]) In []: arr = data In []: arr
Out[]:
array([[-1.68867271, -0.89369286, -0.0288363 , 0.73855122],
[-0.13084603, 0.43972144, 0.73542583, 1.99925332],
[ 0.04291022, -0.91963212, 3.09214837, -0.6070068 ],
[-0.01416294, -1.46576298, . , 0.84758994]]) In []: arr = np.copy(data) In []: arr
Out[]:
array([[-1.68867271, -0.89369286, -0.0288363 , 0.73855122],
[-0.13084603, 0.43972144, 0.73542583, 1.99925332],
[ 0.04291022, -0.91963212, 3.09214837, -0.6070068 ],
[-0.01416294, -1.46576298, . , 0.84758994]])
布尔类型索引
假设每个字符串对应data数组一行数据。需要注意布尔型数组的长度必须与被索引的轴长度一致。
通过布尔型索引查找数组数值的方式如下:
In [140]: names = np.array(['aaa','bbb','ccc','ddd','eee','fff'])
In [141]: data = np.random.randn(6,4)
In [142]: names
Out[142]:
array(['aaa', 'bbb', 'ccc', 'ddd', 'eee', 'fff'],
dtype='<U3')
In [143]: data
Out[143]:
array([[ 0.49394026, -0.65887621, -0.26946242, 0.22042355],
[-1.11606179, -1.94945158, -0.4866134 , 0.67712409],
[-2.33792045, 0.01639887, -0.46020647, 0.84180777],
[-1.99622938, 1.937877 , -0.17134376, 0.56915872],
[ 1.50980905, 0.07244016, -0.95650922, 1.23508517],
[ 0.74706519, -0.03149619, -0.38235363, 0.69786257]])
In [144]: names == 'aaa'
Out[144]: array([ True, False, False, False, False, False], dtype=bool)
In [145]: data[names=='aaa']
Out[145]: array([[ 0.49394026, -0.65887621, -0.26946242, 0.22042355]])
In [146]: names =='ccc'
Out[146]: array([False, False, True, False, False, False], dtype=bool)
In [147]: data[names=='ccc']
Out[147]: array([[-2.33792045, 0.01639887, -0.46020647, 0.84180777]])
布尔数组索引结合切片进行查找数组的数值:
In []: data[names=='aaa',]
Out[]: array([-0.26946242]) In []: data[names=='aaa',:]
Out[]: array([[-0.26946242, 0.22042355]]) In []: data[names=='aaa',:]
Out[]: array([[-0.65887621, -0.26946242, 0.22042355]])
反向查找
In []: names !='aaa'
Out[]: array([False, True, True, True, True, True], dtype=bool) In []: data[names!='aaa']
Out[]:
array([[-1.11606179, -1.94945158, -0.4866134 , 0.67712409],
[-2.33792045, 0.01639887, -0.46020647, 0.84180777],
[-1.99622938, 1.937877 , -0.17134376, 0.56915872],
[ 1.50980905, 0.07244016, -0.95650922, 1.23508517],
[ 0.74706519, -0.03149619, -0.38235363, 0.69786257]])
组合查找
In []: mask = (names == 'aaa')|(names == 'ccc') In []: mask
Out[]: array([ True, False, True, False, False, False], dtype=bool) In []: data[mask]
Out[]:
array([[ 0.49394026, -0.65887621, -0.26946242, 0.22042355],
[-2.33792045, 0.01639887, -0.46020647, 0.84180777]])
花式索引
其实就是利用整数列表或数组进行索引查找。花式索引与数组切片不同,花式索引会将数据复制到新的数组。
整数列表
创建一个二维数组arr,然后传入[3,1],意思就是按 arr [3,:]、arr[1,:]的顺序显示出来。
In []: arr = np.array(([,,,],[,,,],[,,,],[,,,])) In []: arr
Out[]:
array([[ , , , ],
[ , , , ],
[ , , , ],
[ , , , ]]) In []: arr[[,]]
Out[]:
array([[ , , , ],
[ , , , ]])
传入多个整数数组
一次传入多个整数数组,返回的是一个一维数组。
数组转置对轴对换
数组转置,是指将原数组A的行与列交换得到的一个新数组。
比如:
 的转置是
的转置是 ,
, 的转置是
的转置是
方法1:T
In []: arr = np.random.randn() In []: arr
Out[]:
array([-1.42853867, 1.54300781, -0.74079757, -1.20272388, -1.00416459,
-0.59571731, 1.16744662, 0.05739806, 1.01660691, -0.84625494]) In []: arr.T
Out[]:
array([-1.42853867, 1.54300781, -0.74079757, -1.20272388, -1.00416459,
-0.59571731, 1.16744662, 0.05739806, 1.01660691, -0.84625494]) In []: arr = np.random.randn(,) In []: arr
Out[]:
array([[ 1.36114118, 0.48455027, 0.64847485, 0.01691785, -0.03622465],
[-2.31302164, 1.14992892, -1.47836923, 1.08003907, -1.33663009],
[-0.38005499, 1.3517217 , 2.52024026, -0.3576492 , 0.46016645]]) In []: arr.T
Out[]:
array([[ 1.36114118, -2.31302164, -0.38005499],
[ 0.48455027, 1.14992892, 1.3517217 ],
[ 0.64847485, -1.47836923, 2.52024026],
[ 0.01691785, 1.08003907, -0.3576492 ],
[-0.03622465, -1.33663009, 0.46016645]])
方法2:transpose
三维数组 arr:4个3*4的数组
In [275]: arr = np.arange(48).reshape(4,3,4)
In [276]: arr
Out[276]:
array([[[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]],
[[12, 13, 14, 15],
[16, 17, 18, 19],
[20, 21, 22, 23]],
[[24, 25, 26, 27],
[28, 29, 30, 31],
[32, 33, 34, 35]],
[[36, 37, 38, 39],
[40, 41, 42, 43],
[44, 45, 46, 47]]])
transpose参数的真正意义在于这个shape元组的索引(轴编号)。
In []: arr.shape
Out[]: (, , )
arr数组的索引(轴编号):0、1、2
下面是按索引 2、0、1进行对换
In []: arr.transpose(,,)
Out[]:
array([[[ , , ],
[, , ],
[, , ],
[, , ]], [[ , , ],
[, , ],
[, , ],
[, , ]], [[ , , ],
[, , ],
[, , ],
[, , ]], [[ , , ],
[, , ],
[, , ],
[, , ]]])
然后,我们再按(轴编号)0、1、2 对换回到原来的样子
In []: arr.transpose(,,)
Out[]:
array([[[ , , , ],
[ , , , ],
[ , , , ]], [[, , , ],
[, , , ],
[, , , ]], [[, , , ],
[, , , ],
[, , , ]], [[, , , ],
[, , , ],
[, , , ]]])
方法3:swapaxes
swapaxes返回的是源数组的视图。
相比于transpose是需要传入一个索引元组(轴编号),swapaxes只需要一对索引元组(轴编号)。
swapaxes只需要一对索引元组(轴编号)。In []: arr.swapaxes(,)
Out[]:
array([[[ , , ],
[ , , ],
[ , , ],
[ , , ]], [[, , ],
[, , ],
[, , ],
[, , ]], [[, , ],
[, , ],
[, , ],
[, , ]], [[, , ],
[, , ],
[, , ],
[, , ]]])
利用Python进行数据分析_Numpy_基础_2的更多相关文章
- 利用Python进行数据分析_Numpy_基础_3
通用函数:快速的元素级数组函数 通用函数,是指对数组中的数据执行元素级运算的函数:接受一个或多个标量值,并产生一个或多个标量值. sqrt 求平方根 np.sqrt(arr) exp 计算各元素指数 ...
- 利用Python进行数据分析_Numpy_基础_1
ndarray:多维数组 ndarray 每个数组元素必须是相同类型,每个数组都有shape和dtype对象. shape 表示数组大小 dtype 表示数组数据类型 array 如何创建一个数组? ...
- 利用Python进行数据分析——Numpy基础:数组和矢量计算
利用Python进行数据分析--Numpy基础:数组和矢量计算 ndarry,一个具有矢量运算和复杂广播能力快速节省空间的多维数组 对整组数据进行快速运算的标准数学函数,无需for-loop 用于读写 ...
- 利用python进行数据分析--numpy基础
随书练习,第四章 NumPy基础:数组和矢量运算 # coding: utf-8 # In[1]: # 加注释的三个方法1.用一对"""括起来要注释的代码块. # 2. ...
- 利用Python进行数据分析(12) pandas基础: 数据合并
pandas 提供了三种主要方法可以对数据进行合并: pandas.merge()方法:数据库风格的合并: pandas.concat()方法:轴向连接,即沿着一条轴将多个对象堆叠到一起: 实例方法c ...
- 利用Python进行数据分析(5) NumPy基础: ndarray索引和切片
概念理解 索引即通过一个无符号整数值获取数组里的值. 切片即对数组里某个片段的描述. 一维数组 一维数组的索引 一维数组的索引和Python列表的功能类似: 一维数组的切片 一维数组的切片语法格式为a ...
- 利用Python进行数据分析(9) pandas基础: 汇总统计和计算
pandas 对象拥有一些常用的数学和统计方法. 例如,sum() 方法,进行列小计: sum() 方法传入 axis=1 指定为横向汇总,即行小计: idxmax() 获取最大值对应的索 ...
- 利用Python进行数据分析(8) pandas基础: Series和DataFrame的基本操作
一.reindex() 方法:重新索引 针对 Series 重新索引指的是根据index参数重新进行排序. 如果传入的索引值在数据里不存在,则不会报错,而是添加缺失值的新行. 不想用缺失值,可以用 ...
- 利用Python进行数据分析(7) pandas基础: Series和DataFrame的简单介绍
一.pandas 是什么 pandas 是基于 NumPy 的一个 Python 数据分析包,主要目的是为了数据分析.它提供了大量高级的数据结构和对数据处理的方法. pandas 有两个主要的数据结构 ...
随机推荐
- resin初识
Resin初识 1. resin简介 刚入职的公司用的后台服务器是resin,故因此学习记录一下. resin是一个非常流行的web引用服务器,对servlet和jsp提供了良好的支持,自身采用jav ...
- sql server management studio 连接时指定非默认端口 ,port
- 中间件 | mq消息队列解说
消息队列 1.1 什么是消息队列 我们可以把消息队列比作是一个存放消息的容器,当我们需要使用消息的时候可以取出消息供自己使用.消息队列是分布式系统中重要的组件,使用消息队列主要是为了通过异步处理提高系 ...
- Linux工程管理器——make
一.定义 工程管理器,顾名思义,是指管理较多的文件 Make工程管理器也就是个“自动编译管理器”,这里的“自动”是指它能构根据文件时间戳自动发现更新过的文件而减少编译的工作量,同时,它通过读入Make ...
- 关于form与表单提交操作的一切
原文链接:http://caibaojian.com/form.html 你知道,一个表单里面只要有form元素,如果没有给action加一个默认值,为空白的时候,当你刷新页面时,会弹出一个警告框提示 ...
- 一个link加载多个css文件
细看正则时匹配慕课网链接时发现的,一个link加载多个css文件 http://static.mukewang.com/static/css/??base.css,common/common-less ...
- plupload上传大文件
大容量文件上传早已不是什么新鲜问题,在.net 2.0时代,HTML5也还没有问世,要实现这样的功能,要么是改web.config,要么是用flash,要么是用一些第三方控件,然而这些解决问题的方法要 ...
- SpringBoot集成tk mybatis插入数据,回显主键为null
实体信息如下 @Data public class ApiCertificate{ @Id @GeneratedValue(generator = "JDBC") private ...
- redis配置用户认证密码
1,下载安装 Download, extract and compile Redis with: $ wget http://download.redis.io/releases/redis-3.2. ...
- Python3之高阶函数sorted
排序算法 Python内置的sorted()函数可以对list进行排序 >>> sorted([36,5,-12,9,-21]) [-21, -12, 5, 9, 36] 此外,so ...