mysql--简单操作
一、数据库的基本操作
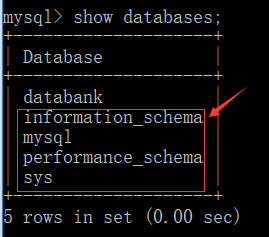
- 查看当前所有存在的数据库
show databases; //mysql 中不区分大小写。(databank 是之前创建的)
- 创建数据库
create database database_name; //database_name 为新建的数据库的名称,该名称不能与已经存在的数据库重名
如:创建一个名为 test_db 的数据库

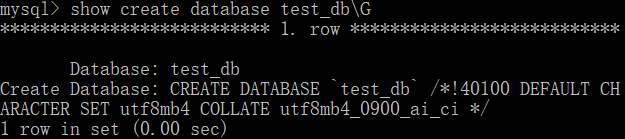
查看数据库 test_db 的定义:
show create database test_db\G //将会显示数据库的创建信息
- 使用数据库
use database_name;
如:使用数据库 test_db

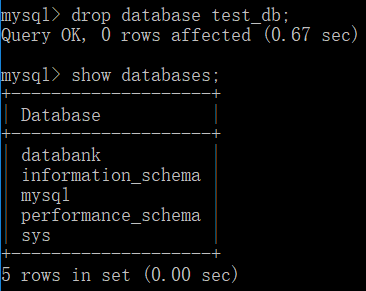
- 删除数据库
drop database database_name;
如:删除数据库 test_db
二、数据表的基本操作(以 stu 表为例)
- 创建数据表
create table stu(
id int(11) primary key auto_increment, //主键 id, id 值自动增加
name varchar(22) not null, //非空
salary float default 1000.00); //默认值为 1000.00 - 查看数据表结构
desc table_name; //describle table_name; 查看表的基本结构

show create table table_name\G //查看表的详细结构

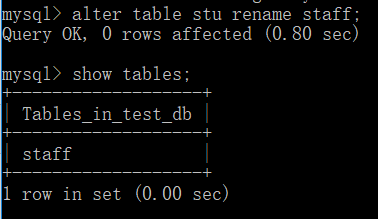
修改数据表
alter table table_oldname rename [to] table_newname; //修改表名。 to 为可选参数,使用与否均不影响结果
alter table table_name modify <字段名> <数据类型>; //修改字段的数据类型。 '表名' 是当前所在表, '字段名' 是目标修改字段, '数据类型' 是新数据类型
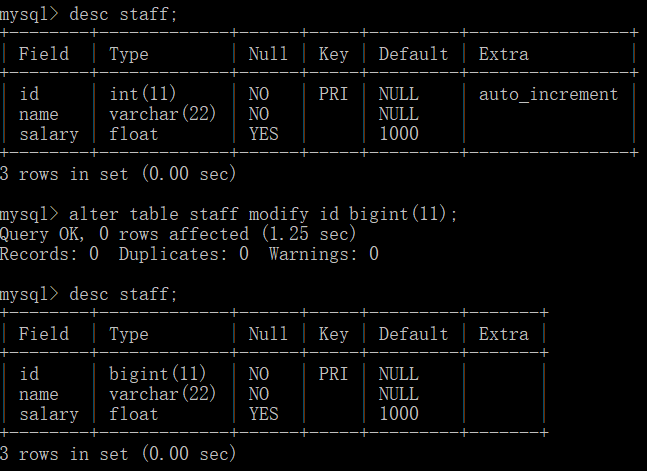
修改字段名
alter table table_name change <旧字段名> <新字段名> <新数据类型>; //修改字段名。 如不需要修改字段的数据类型,须将新数据类型设置成和原来一样。
添加字段
alter table table_name add <新字段名> <数据类型> [约束条件] [first | after 已存在的字段名]; //添加字段 如:
alter table staff add address varchar(55); //无约束条件 alter table staff add address varchar(55) not null; //有约束条件(要求非空) alter table staff add address varchar(55) first; //成为表的第一列 alter table staff add address varchar(55) after name; //在表的某一列之后删除字段
alter table table_name drop <字段名>; //删除字段
修改字段的排列位置
alter table table_name modify <字段1> <数据类型> first | after <字段2>; //修改字段的排列位置。 '数据类型' 是指 '字段1' 的数据类型 如:
alter table staff modify adress varchar(55) first; //修改字段为表的第一个字段 alter table staff modify adress varchar(55) after id; // 'adress' 字段将移至表的 'id' 字段之后- 删除数据表
drop table table_name; //无关联的表
三、插入、更新与删除数据
- 表中插入数据
insert into table_name (column_list) values (value_list); 如:
//建表
create table staff(
id int(11) primary key auto_increment,
name varchar(22) not null,
salary float default 1000); //为所有字段插入数据
insert into staff(id,name,salary)
values(1,'Joan',2000),values(2,'Qwe',900);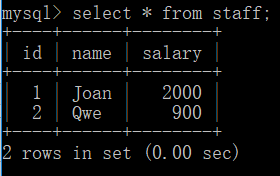
//为表的指定字段插入数据
insert into staff(id,name)
values(3,'Wer'),(4,'andy'); //salary 取默认值 insert into staff(name,salary)
values('Tin',2048),('Jimy',1024); //id 值自动增加 复制表
create table table_new select * from table_old; //全部复制(表的结构会改变) create table table_new select (column_list) from table_old; //部分复制 如:
create table newstaff select * from staff; create table newstaff select id,salary from staff;表中删除数据
delete from table_name [where <condition>]; //删除指定记录 delete from table_name; //删除表中所有记录
- 表中更新数据
update table_name
set column_name1=values1,... [where <condition>]; //修改指定字段的值 如:
update staff set salary=2048 where id=9; update staff set salary=1024 where id between 5 and 9; 表中查询数据
单表查询
//单表查询 select * from staff; //(*)查询所有字段数据 select 字段名1,字段名2,...字段名n from table_name; //查询指定字段数据(某几列) select 字段名1,字段名2,...字段名n from table_name where 条件; //查询指定记录
where 条件判断符
操作符
说明
= 相等
<> , != 不相等
< 小于
<= 小于或者等于
> 大于
>= 大于或者等于
between 位于两者之间
//带 in 关键字的查询 select * from staff where id in(1,2,8); //id=1、id=2、id=8 select * from staff where id not in(1,2,8); //带 between and 的范围查询 select * from staff where id between 1 and 8; //id-->1至8 的记录 select * from staff where id not between 1 and 8; //id-->1至8 以外的记录 //带 like 的字符匹配查询 select * from staff where name like 't%'; //查询所有名字以 t 开头的记录 select * from staff where name like '%t%'; //查询所有名字中包括 t 的记录 select * from staff where name like 't%y'; //查询所有名字以 t 开头并以 y 结尾的记录 select * from staff where name like '___y'; //查询所有名字以 y 结尾并且前面只有三个字符的记录 //查询空值 select * from staff where salary is null; //查询字段 salary 的值为空的记录 //带 and、or 的多条件查询 select * from staff where id=1 and salary>=1000; //查询结果不重复 select distinct 字段名 from 表名; //distinct 关键字可以消除重复的记录值
对查询结果排序
//order by 默认情况下,升序排 select * from staff order by salary [asc]; select * from staff order by salary desc; //降序排 //group by 该关键字常和集合函数一起用,如: MAX()、MIN()、COUNT()、SUM()、AVG() [group by 字段] [having <条件表达式>] //基本语法格式 如:根据 salary 对 staff 表中的数据进行分组,并显示人员数大于等于1的分组信息
select salary,group_concat(name) as names from staff
group by salary having count(name)>=; select salary,count(*) as total_num from staff
group by salary with rollup; //with rollup 关键字用来统计记录数量 select * from staff group by salary,name; //多字段分组 //group by + order by select name, sum(*salary) as salary_total from staff
group by salary having sum(*salary)>
order by salary_total; //使用 limit 限制查询结果的数量 limit [位置偏移量,] 行数 //基本语法格式 select * from staff limit ; //从第一行开始显示,显示共四行
select * from staff limit ,; //从第5行开始显示,显示共四行使用集合函数查询
// count() 函数 count(*) 计算表中行的总数,不管某列值是否为空
count(字段名) 计算指定列下总的行数,空值的行不被记录 select count(*) as total_num from staff;
select count(salary) as salary_num from staff; // sum()函数。计算时忽略值为 NULL 的行 select sum(salary) as salary_total from staff; // avg()函数 select avg(salary) as avg_salary from staff; // max()函数、min()函数。以 max 为例 select max(salary) as max_salary from staff;
select name,max(salary) as max_salary from staff;qqqqqqq
mysql--简单操作的更多相关文章
- python(pymysql)之mysql简单操作
一.mysql简单介绍 说到数据库,我们大多想到的是关系型数据库,比如mysql.oracle.sqlserver等等,这些数据库软件在windows上安装都非常的方便,在Linux上如果要安装数据库 ...
- Linux下的MySQL简单操作(服务启动与关闭、启动与关闭、查看版本)
小弟今天记录一下在Linux系统下面的MySQL的简单使用,如下: 服务启动与关闭 启动与关闭 查看版本 环境 Linux版本:centeros 6.6(下面演示),Ubuntu 12.04(参见文章 ...
- mysql简单操作一
MySQL的一些简单管理: 启动MySQL服务: sudo start mysql 停止MySQL服务: sudo stop mysql 修改 MySQL 的管理员密码: sudo mysqladmi ...
- mysql简单操作
1,mysql 唤醒数据库,mysql -uroot -p11221 2,创建一个数据库: CREATE DATABASE mldn CHARACTER SET UTF8; 也可以写成小写的:crea ...
- mysql简单操作(实时更新)
从表中删除某条记录: delete from table_name where xx=xxxx; 创建数据库(注意不同系统对大小写的敏感性): create database xxx; 查看数据库列表 ...
- Linux上SQL及MYSQL简单操作
Linux上检查MYSQL是否安装: $ sudo service mysql start Ubuntu Linux安装配置MYSQL: $ sudo apt-get install mysql-se ...
- python3 的 mysql 简单操作
一.python 提供的 db 接口 pymysql 两个基本对象: connection.cursor 连接示例 # connect_demo.py import pymysql db = pymy ...
- Node js MySQL简单操作
//win7环境下node要先安装MySQL的相关组件(非安装MySQL数据库),在cmd命令行进入node项目目录后执行以下语句 //npm install mysql var mysql = re ...
- mySQL简单操作(三)
1.事务 (1)ACID 原子性(不可分割性)automicity 一致性 consistency 隔离性 isolation 持久性 durability (2)事务控制语句 begin/start ...
- mySQL简单操作(二)
1.like子句 [where clause like '%com'] '%' '_' 2.正则 3.union操作符 用于连接多个select语句,[distinct]删除重复数据 select c ...
随机推荐
- 使用 ServerSocket 建立聊天服务器-2
1. 从serverListener中可以看出,每一个客户端创建新的请求之后,都会把它分配给一个独立的chatsocket ,但是每一个ChatSocket都是相互独立的,他们之间并不能沟通,所以要新 ...
- webservice的soap
1.soap的定义: 2.使用TCP/IP Monitor监视Soap协议 eclipse工具,show view-->other-->debug-->TCP/IP Monitor ...
- Linux Swap是干嘛的?
swap是干嘛的? 在Linux下,SWAP的作用类似Windows系统下的“虚拟内存”.当物理内存不足时,拿出部分硬盘空间当SWAP分区(虚拟成内存)使用,从而解决内存容量不足的情况. SWAP意思 ...
- Windows10下安装Ubuntu18.04LTS详细教程
这篇文章分享自己在Windows10系统下安装VMware虚拟机,然后在VMware中安装Ubuntu 18.04 LTS的详细过程.之所以选择在虚拟机中安装Ubuntu,主要是可以不影响自己电脑的正 ...
- iptables一些练习
iptables 一些小练习 可以参考之前的一起食用 https://www.cnblogs.com/lovesKey/p/10909633.html 允许来自192.168.0.0/16网段的地址来 ...
- PowerShell中汉字与ASCII码相互转换
function asc($param) { $rtn = '' $list = $param -split '' foreach ($char in $list) { if($char -ne '' ...
- kafka 45个题目介绍
>1.Kafka面试问答 Apache Kafka的受欢迎程度很高,Kafka拥有充足的就业机会和职业前景.此外,在这个时代拥有kafka知识是一条快速增长的道路.所以,在这篇文章中,我们收集了 ...
- 2018-2019-2 20165222《网络对抗技术》Exp9 Web安全基础
1.实践过程记录 1.字符串型注入. 2.整数型注入 3.注入语句查看其他内容 4.xss是一种漏洞,这种漏洞允许用户输入脚本并且浏览器提交的时候不加编码.这种东西是最为流行并且有害的web应用的问题 ...
- php手记之05-tp5模型操作数据库
# 实例化模型 // $user = new User; // $user1 = new User(); // $user2 = model('user'); // 添加一条数据 # 方法1 // $ ...
- MySQL 中视图和表的区别以及联系是什么?
两者的区别: (1)视图是已经编译好的 SQL 语句,是基于 SQL 语句的结果集的可视化的表,而表不是. (2)视图没有实际的物理记录,而基本表有. (3)表是内容,视图是窗口. (4)表占用物理空 ...