用ufile和S3代替hdfs存储数据
一,添加ufile需在配置中添加:
core-site.xml
添加如下配置:
<property>
<name>fs.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFileSystem</value>
</property>
<property>
<name>ufile.properties.file</name>
<value>/data/ufile.properties</value>
</property>
<property>
<name>fs.AbstractFileSystem.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFs</value>
</property>
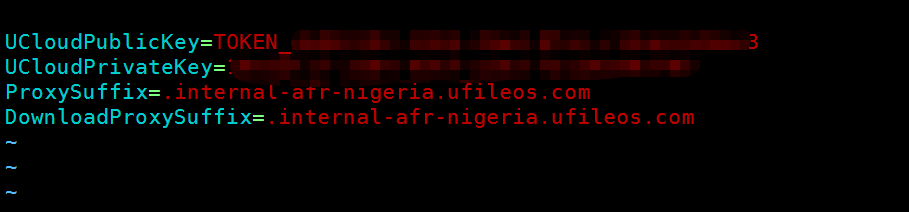
ufile.properties:
格式如下:
UCloudPublicKey=${API公钥或者TOKEN公钥}
UCloudPrivateKey=${API私钥或者TOKEN私钥}
ProxySuffix=${域名后缀} // ⻅见下⾯面域名后缀说明
DownloadProxySuffix=${域名后缀} // ⻅见下⾯面域名后缀说明
ls /data/ufile.properties
例子:
操作ufile测试:
hdfs dfs -put test.txt ufile://<bucket名>/test.txt
hdfs dfs -ls ufile://opay-datalake
<bucket名>是整段名字最前面的一段,也可点域名管理看

jar包放的目录:
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib |grep uhadoop*
uhadoop-1.0-SNAPSHOT.jar
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib |grep ufile
ufilesdk-1.0-SNAPSHOT.jar
如要使用impala,还需要在impala下放置:
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/ufile*
ls /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/uhadoop*
scp ufilesdk-1.0-SNAPSHOT.jar 10.52.172.232:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib
scp uhadoop-1.0-SNAPSHOT.jar 10.52.172.232:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib
要hive使用ufile还需要拷到这些位置:
scp /opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/udf-1.0-SNAPSHOT-jar-with-dependencies.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/
scp uhadoop-1.0-SNAPSHOT.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/
scp ufilesdk-1.0-SNAPSHOT.jar 10.52.96.106:/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib
#要用beeline,还得在下面的位置都放置两个jar包:
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/impala/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/auxlib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hive/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/sqoop/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop-hdfs/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/hadoop/lib/ufilesdk-1.0-SNAPSHOT.jar
/opt/cloudera/parcels/CDH-6.2.0-1.cdh6.2.0.p0.967373/lib/spark/jars/ufilesdk-1.0-SNAPSHOT.jar
理论上讲:
读: 5G B /s 40G b/s
写: 0.56G B/s 1TB 30min
问题:
1/ 当用 orc格式插入数据,起初是14万条,后来是140万条,报错如下:

改为stored as parquet格式正常
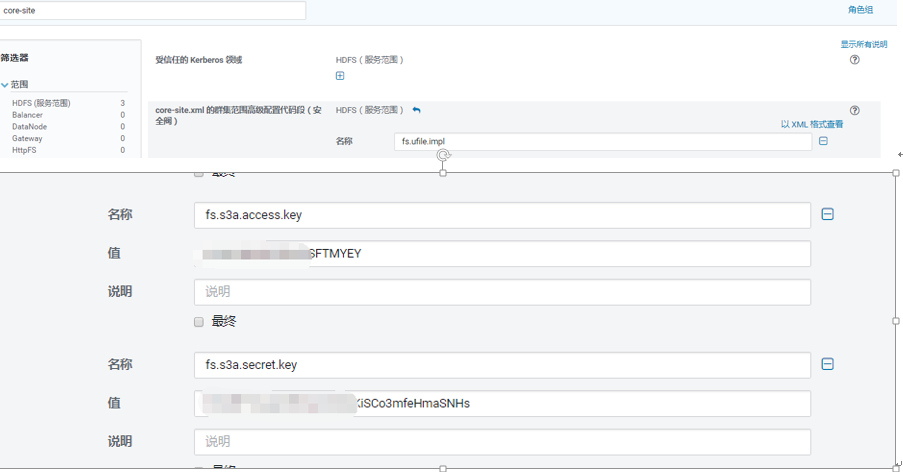
二, 添加s3的访问,因为aws的jar已经内置到了CDH,所以只需要改core-site.xml就可以了
<property>
<name>fs.AbstractFileSystem.ufile.impl</name>
<value>org.apache.hadoop.fs.UFileFs</value>
</property>
<property>
<name>fs.s3a.access.key</name>
<value>AKI</value>
</property>
<property>
<name>fs.s3a.secret.key</name>
<value>l8IvM8s</value>
</property>
</configuration>
hadoop dfs -ls s3a://opay-bi/
#CDH要在配置中加:
参考:
https://www.cloudera.com/documentation/enterprise/6/6.2/topics/admin_s3_docs_ref.html
https://www.cloudera.com/documentation/enterprise/6/6.2/topics/admin_s3_docs_ref.html
用ufile和S3代替hdfs存储数据的更多相关文章
- Hadoop第三天---分布式文件系统HDFS(大数据存储实战)
1.开机启动Hadoop,输入命令: 检查相关进程的启动情况: 2.对Hadoop集群做一个测试: 可以看到新建的test1.txt和test2.txt已经成功地拷贝到节点上(伪分布式只有一个节 ...
- 用hdfs存储海量的视频数据的设计思路
用hdfs存储海量的视频数据 存储海量的视频数据,主要考虑两个因素:如何接收视频数据和如何存储视频数据. 我们要根据数据block在集群上的位置分配计算量,要充分利用带宽的优势. 1.接收视频数据 将 ...
- hdfs冷热数据分层存储
hdfs如何让某些数据查询快,某些数据查询慢? hdfs冷热数据分层存储 本质: 不同路径制定不同的存储策略. hdfs存储策略 hdfs的存储策略 依赖于底层的存储介质. hdfs支持的存储介质: ...
- HDFS读写数据块--${dfs.data.dir}选择策略
最近工作需要,看了HDFS读写数据块这部分.不过可能跟网上大部分帖子不一样,本文主要写了${dfs.data.dir}的选择策略,也就是block在DataNode上的放置策略.我主要是从我们工作需要 ...
- 【漫画解读】HDFS存储原理(转载)
以简洁易懂的漫画形式讲解HDFS存储机制与运行原理. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下: Client:客户端,系统使用者,调用HDFS API操作文件;与NN交互获取文件元数 ...
- QString内部仍采用UTF-16存储数据且不会改变(一共10种不同情况下的编码)
出处:https://blog.qt.io/cn/2012/05/16/source-code-must-be-utf-8-and-qstring-wants-it/ 但是注意,这只是QT运行(Run ...
- 【转】【漫画解读】HDFS存储原理
根据Maneesh Varshney的漫画改编,以简洁易懂的漫画形式讲解HDFS存储机制与运行原理. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下: Client:客户端,系统使用者,调用 ...
- 【漫画解读】HDFS存储原理
根据Maneesh Varshney的漫画改编,以简洁易懂的漫画形式讲解HDFS存储机制与运行原理,非常适合Hadoop/HDFS初学者理解. 一.角色出演 如上图所示,HDFS存储相关角色与功能如下 ...
- Hadoop -- HDFS 读写数据
一.HDFS读写文件过程 1.读取文件过程 1) 初始化FileSystem,然后客户端(client)用FileSystem的open()函数打开文件 2) FileSyst ...
随机推荐
- Vue:选中商品规格改变字体和边框颜色(默认选中第一种规格)
效果图: CSS: <div class="label"> <p>标签类别</p> <ul> <li v-for=" ...
- python- www.thisamericanlife.org转pdf
环境安装 pip install requests pip install beautifulsoup4 pip install pdfkit $ sudo apt-get install wkhtm ...
- HZOJ 20190722 visit (组合数学+数论)
考试T2,考试时打了个$O(n^3)$dp暴力,思路还是很好想的,但细节也不少,然后滚动数组没清空,而且题又看错了,只得了10pts,真是血的教训. 题解: 其实看数据范围,给出了模数是否为质数,其实 ...
- Java线程之如何分析死锁及避免死锁
什么是死锁 java中的死锁是一种编程情况,其中两个或多个线程被永久阻塞,Java死锁情况出现至少两个线程和两个或更多资源. 在这里,我们将写了一个简单的程序,它将导致java死锁场景,然后我们将分析 ...
- 服务器上class文件是新的,但就是执行的老代码
故事是这样的. 上周末回老家,n个测试和开发找我,说我写的代码哪儿哪儿不行,吓得我赶紧打开电脑,连上阿里云数据库,修改了代码,测试们拉包重新测试后,还是不行,通过看打出的日志,还是执行的修改之前的代码 ...
- 微信小程序_(组件)view视图容器
微信小程序view组件官方文档 传送门 Learn 一.hover-class属性 二.hover-start-time与hover-stay-time属性 三.hover-stop-propagat ...
- python配置文件
python有两种配置文件,file.ini和file.json 一.ini文件如下: db_config.ini [baseconf] host=127.0.0.1 port=3306 user=r ...
- java多线程编程详细总结
一.多线程的优缺点 多线程的优点: 1)资源利用率更好2)程序设计在某些情况下更简单3)程序响应更快 多线程的代价: 1)设计更复杂虽然有一些多线程应用程序比单线程的应用程序要简单,但其他的一般都更复 ...
- iOS 修改打包后的.ipa应用名字
一.修改应用的名字 二.重新签名 下面详细介绍介绍两个步骤: 1.修改应用的名字: 1).解压.ipa文件,在Payload文件夹下有一个.app文件(如下图:)选中.app文件,右键点击“显示包内容 ...
- golang 性能剖析pprof
作为一个golang coder,使用golang编写代码是基本的要求. 能够写出代码,并能够熟悉程序执行过程中各方面的性能指标,则是更上一层楼. 如果在程序出现性能问题的时候,可以快速定位和解决问题 ...