决策树算法的Python实现—基于金融场景实操
决策树是最经常使用的数据挖掘算法,本次分享jacky带你深入浅出,走进决策树的世界
基本概念
决策树(Decision Tree)
- 它通过对训练样本的学习,并建立分类规则,然后依据分类规则,对新样本数据进行分类预测,属于有监督学习。
优点
1)决策树易于理解和实现
- 使用者不需要了解很多的背景知识,通过决策树就能够直观形象的了解分类规则;
2)决策树能够同时处理数值型和非数值型数据
- 在相对短的时间内,能够对大型数据做出可行且效果良好的结果;
逻辑-类比找对象
决策树分类的思想类似于找对象,例如一个女孩的母亲要给这个女孩介绍男朋友,于是母女俩有了下面的对话:
女儿问:“多大年龄了”;母亲答:“26”
女儿接着问:“长得帅不帅?”;母亲答:“挺帅的。”
女儿问:“收入高不?”;母亲答:“不算很高,中等情况”
女儿问:“是公务员吗?”;母亲答:“是,在财政局上班”
最后,女儿做出决定说:“那好,我去见见!”
这个女孩的决策过程就是典型的分类树决策:
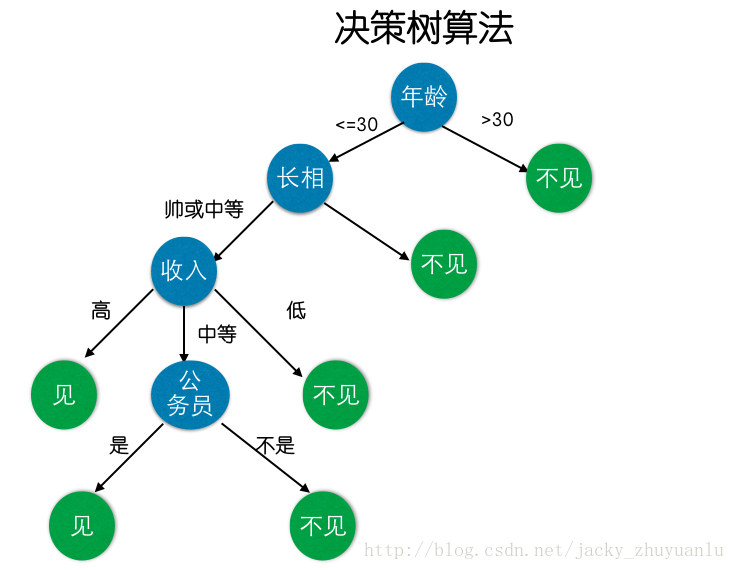
在来看一个金融场景下的举例:客户向银行贷款的时候,银行对用户的贷款资格做一个评估的流程:
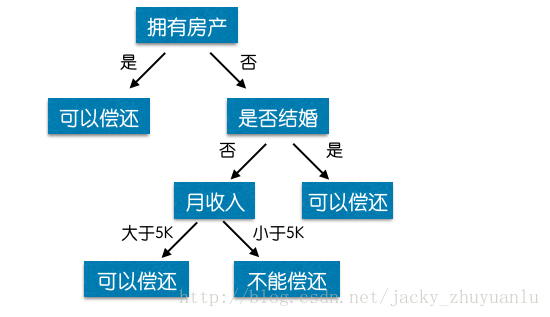
首先银行工作人员询问客户是否有房产,如何回答有,则判断客户可以偿还贷款,如果没有则进入第二层的属性判断询问,是否结婚,如何已婚,两个人可以负担的起贷款,则判断为可以偿还,否则进入第三层的属性判断询问,月薪是否超过五千,如果满足,则判断为可以偿还,否则给出不能偿还贷款的结论。
看完上面两个例子,我们可以看出,决策树是非常实用的,下面我们就进入正式案例的讲解;
案例实操
下面以金融场景举例:
情景铺垫
用户在购买互联网金融产品的过程“类似于”理财,对于P2P平台来说,严格来说,这个过程称之为撮合。
用户金融平台上充值购买相应期限和约定利率的金融产品,产品到期后,用户有两种选择一个是提现(赎回),另一个就是复投。
对于用户到期赎回的理解是比较简单的,比如你在2018年1月1日买了6个月10万定存金融产品,那么在2018年7月1日的时候,你可以选择连本带息全部赎回,当然你也可以在到期日选择在平台还款时,继续投资,这个过程就是复投。
下面,在严谨一点归纳复投的定义就是:
针对按月等额本息还款的用户,还款或,用户自己再投,这个过程就是复投。
需解决的问题
作为金融平台来说,为了把控风险,保证资金的流动性,都一定要提前预测(预判)未来一段时间内的用户充值和提现金额。
那么,准确预测用户到期是否复投,对于我们金融从业者和管理人员来说,就是特别重要了。
那么,我们可以提出我们亟需解决的问题:
- 用户到期是否复投,我们改怎样预判?
一个初步模型的建立
场景:预测用户是否复投
注:以下源数据模拟真实数据编撰
(一)选择特征变量-featureDate
1. 数据源抓取
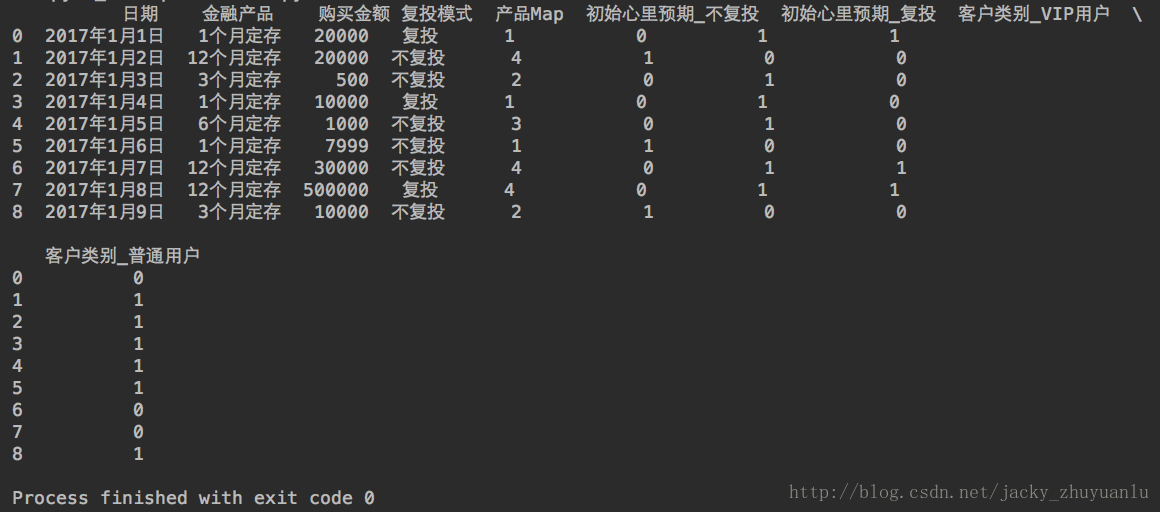
import pandas
data = pandas.read_csv('file:///Users/apple/Desktop/jacky_reinvest.csv',encoding='GBK')
print(data)
jacky注解(1):上面这份数据源其实是经过预处理(或者说是经过初步的数据清理的),我们拿到数据源的第一步一定是做数据清理的,数据科学与传统的统计科学,在实操中,区别最大的可能就是数据清理了,本文的数据源只用于学习举例用,所以数据还是比较规整的,但在实际工作中,一定不要忘了数据清洗这一步。
jacky注解(2): 初始心里预期这列是一个产品概念,就是用户在购买定存金融产品的时候,可以预先设定是否需要复投,当然这只是一个预设定,在用户购买到赎回这个过程中,我们都可以随时变更。复投模式是一个过去式,也是最终的复投结果,所以下面我们会把这列当作目标变量来处理。
2. 哑变量处理(虚拟变量转化)
需处理的特征变量有:
金融产品
初始心里预期
客户类别
#调用Map方法进行可比较大小虚拟变量的转换
productDict={'12个月定存':4,'6个月定存':3,'3个月定存':2,'1个月定存':1}
data['产品Map']=data['金融产品'].map(productDict)
#调用get_dummyColumns方法进行不可比较大小虚拟变量的转换
dummyColumns = ['初始心里预期','客户类别',]
for column in dummyColumns:
data[column]= data[column].astype('category')
dummiesData=pandas.get_dummies(
data,
columns=dummyColumns,prefix=dummyColumns
,prefix_sep='_',dummy_na=False,drop_first=False)
#挑选可以建模的变量 featureData
fData = dummiesData[[
'购买金额','产品Map','初始心里预期_复投','客户类别_VIP用户'
]]
jacky注解(3):关于哑变量更详细的说明,可以参照我《特征工程三部曲》这篇文章,哑变量处理要处理的就是离散变量,购买金额的列,因为都是连续型数据,所以就谈不上虚拟变量处理的。
jacky注解(4):离散变量分为有比较关系的离散变量和无比较关系的离散变量,所以需要用map方法和get_dummyColumns方法分别处理;
(二)选择目标变量-targerDate
#设定目标变量 targetData
tData = dummiesData['复投模式']- jacky注解(5):目标变量是我们分析问题的目标和结果,从目标变量既定的历史数据中,我们可以”喂养”数据,继而训练数据,最终达到洞察预测数据的目的。
(三)决策树问题的求解与建模
#生成决策树
from sklearn.tree import DecisionTreeClassifier
#设置最大叶子数为5
dtModel = DecisionTreeClassifier(max_leaf_nodes=5)- jacky注解(6):生成决策树并设置最大叶子树为5,使⽤sklearn的DecisionTreeClassifer类进⾏行决策树问题的求解与建模,关于最大叶子树,可以在看过图形化之后,在反过来理解这部分,就简单的多了,在这里我们可以先理解为是一个很常用的参数即可。
(四)10折交叉验证
#模型检验-交叉验证法
from sklearn.model_selection import cross_val_score
cross_val_score(
dtModel,
fData,tData,cv=10
)
- jacky注解(7):从控制台的输出可以看出,每次验证的评分都超过0.9,是一个非常不错的模型,可以用于实践;
(五)模型训练
#训练模型
dtModel=dtModel.fit(fData,tData)控制台结果输出:

(六)模型可视化
决策树的绘图方法:
sklearn.tree.export_graphviz(… …)
dtModel:决策树模型
out_file:图形数据的输出路径
class_names:目标属性的名称,一般用于中文化
feature_names:特征属性的名称,一般用于种文化
filled= True :是否使用颜色填充
rounded=True:边框是否采用圆角边框
special_characters: 是否有特殊字符
#模型可视化
import pydotplus
from sklearn.externals.six import StringIO #生成StringIO对象
from sklearn.tree import export_graphviz
dot_data = StringIO() #把文件暂时写在内存的对象中
export_graphviz(
dtModel,
out_file=dot_data,
class_names=['复投','不复投'],
feature_names=['购买金额','产品Map','初始心里预期_不复投','客户类别_VIP用户'],
filled=True,rounded=True,special_characters=True
)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('shujudata.png')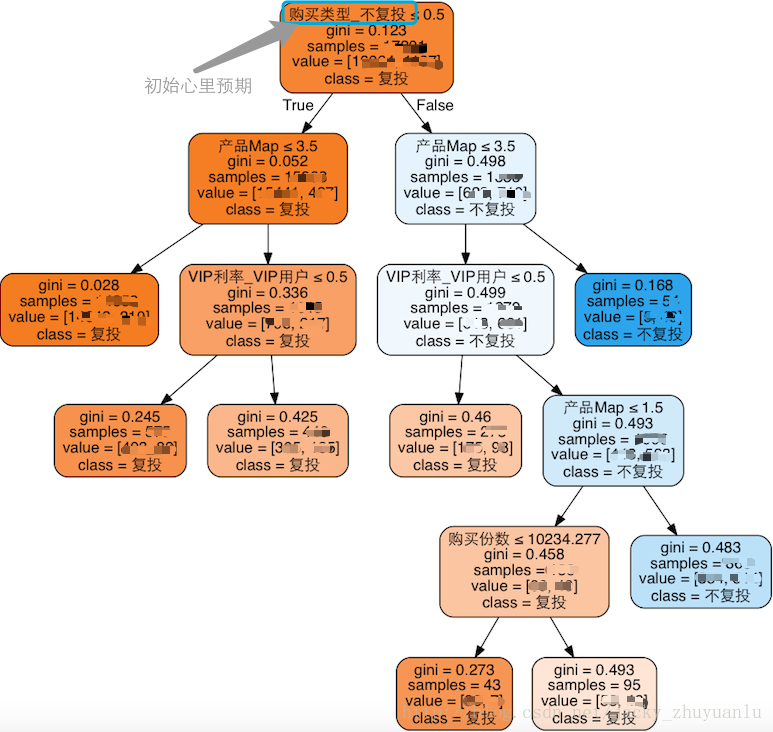
jacky注解(8):需要提前安装graphviz软件
jacky注解(9):最大叶子树,一般设置为8个,因为叶子数太多,决策树的结构越复杂,太复杂的结构就会导致训练过度的问题,因此,在决策树算法中,设置合适叶子数是非常重要的。
jacky注解(10):gini值越接近于0,那么结果就越显而易见,如果越接近于1,那么结果就越难判定;
完整代码展示
#---author:朱元禄---
import pandas
data = pandas.read_csv('file:///Users/apple/Desktop/jacky_reinvest.csv',encoding='GBK')
#调用Map方法进行可比较大小虚拟变量的转换
productDict={'12个月定存':4,'6个月定存':3,'3个月定存':2,'1个月定存':1}
data['产品Map']=data['金融产品'].map(productDict)
#调用get_dummyColumns方法进行可比较大小虚拟变量的转换
dummyColumns = ['初始心里预期','客户类别',]
for column in dummyColumns:
data[column]= data[column].astype('category')
dummiesData=pandas.get_dummies(
data,
columns=dummyColumns,prefix=dummyColumns
,prefix_sep='_',dummy_na=False,drop_first=False)
#挑选可以建模的变量 featureData
fData = dummiesData[[
'购买金额','产品Map','初始心里预期_复投','客户类别_VIP用户'
]]
#设定目标变量 targetData
tData = dummiesData['复投模式']
#生成决策树
from sklearn.tree import DecisionTreeClassifier
#设置最大叶子数为8
dtModel = DecisionTreeClassifier(max_leaf_nodes=8)
'''
#模型检验-交叉验证法
from sklearn.model_selection import cross_val_score
cross_val_score(
dtModel,
fData,tData,cv=10
)
'''
#训练模型
dtModel=dtModel.fit(fData,tData)
#模型可视化
import pydotplus
from sklearn.externals.six import StringIO #生成StringIO对象
from sklearn.tree import export_graphviz
dot_data = StringIO() #把文件暂时写在内存的对象中
export_graphviz(
dtModel,
out_file=dot_data,
class_names=['复投','不复投'],
feature_names=['购买金额','产品Map','初始心里预期_不复投','客户类别_VIP用户'],
filled=True,rounded=True,special_characters=True
)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_png('shujudata.png')
决策树算法的Python实现—基于金融场景实操的更多相关文章
- Python相关分析—一个金融场景的案例实操
哲学告诉我们:世界是一个普遍联系的有机整体,现象之间客观上存在着某种有机联系,一种现象的发展变化,必然受与之关联的其他现象发展变化的制约与影响,在统计学中,这种依存关系可以分为相关关系和回归函数关系两 ...
- Kaggle竞赛入门:决策树算法的Python实现
本文翻译自kaggle learn,也就是kaggle官方最快入门kaggle竞赛的教程,强调python编程实践和数学思想(而没有涉及数学细节),笔者在不影响算法和程序理解的基础上删除了一些不必要的 ...
- 机器学习-决策树算法+代码实现(基于R语言)
分类树(决策树)是一种十分常用的分类方法.核心任务是把数据分类到可能的对应类别. 他是一种监管学习,所谓监管学习就是给定一堆样本,每个样本都有一组属性和一个类别,这些类别是事先确定的,通过学习得到一个 ...
- python机器学习笔记 ID3决策树算法实战
前面学习了决策树的算法原理,这里继续对代码进行深入学习,并掌握ID3的算法实践过程. ID3算法是一种贪心算法,用来构造决策树,ID3算法起源于概念学习系统(CLS),以信息熵的下降速度为选取测试属性 ...
- day-8 python自带库实现ID3决策树算法
前一天,我们基于sklearn科学库实现了ID3的决策树程序,本文将基于python自带库实现ID3决策树算法. 一.代码涉及基本知识 1. 为了绘图方便,引入了一个第三方treePlotter模块进 ...
- 吴裕雄--天生自然python机器学习:决策树算法
我们经常使用决策树处理分类问题’近来的调查表明决策树也是最经常使用的数据挖掘算法. 它之所以如此流行,一个很重要的原因就是使用者基本上不用了解机器学习算法,也不用深究它 是如何工作的. K-近邻算法可 ...
- 转载:scikit-learn学习之决策树算法
版权声明:<—— 本文为作者呕心沥血打造,若要转载,请注明出处@http://blog.csdn.net/gamer_gyt <—— 目录(?)[+] ================== ...
- 决策树算法——ID3
决策树算法是一种有监督的分类学习算法.利用经验数据建立最优分类树,再用分类树预测未知数据. 例子:利用学生上课与作业状态预测考试成绩. 上述例子包含两个可以观测的属性:上课是否认真,作业是否认真,并以 ...
- scikit-learn决策树算法类库使用小结
之前对决策树的算法原理做了总结,包括决策树算法原理(上)和决策树算法原理(下).今天就从实践的角度来介绍决策树算法,主要是讲解使用scikit-learn来跑决策树算法,结果的可视化以及一些参数调参的 ...
随机推荐
- java包装类的缓存机制(转)
出处: java包装类的缓存机制 java 包装类的缓存机制,是在Java 5中引入的一个有助于节省内存.提高性能的功能,只有在自动装箱时有效 Integer包装类 举个栗子: Integer a = ...
- Spring实战(四)Spring高级装配中的bean profile
profile的原意为轮廓.剖面等,软件开发中可以译为“配置”. 在3.1版本中,Spring引入了bean profile的功能.要使用profile,首先要将所有不同的bean定义整理到一个或多个 ...
- WebApi 空项目生成帮助文档
1.创建一个WebApi的空项目 2.写一些接口,在接口文档中忽略某个方法可以使用 [ApiExplorerSettings(IgnoreApi = true)] 特性 3.在Nuget中添加 Mi ...
- 【ES6 】ES6 字符串扩展及新增方法
模板字符串 传统写法 var str = 'There are <b>' + basket.count + '</b> ' + 'items in your basket, ' ...
- CSS精灵技术(sprite)
CSS技术的使用场景:有效的减少了服务器接收和发送请求的次数,css精灵是一种出来网页背景图像的方式,将一个页面设计到的所有零星背景图集中到一张大图中去,然后将大图应用于网页 .通过backgroun ...
- 这段时间大量网站被k的原因分析
百度这次更新的K站幅度比较大,通过对被k网站的分析,没有发现文章类型网站有降权现象,主要集中在企业网站上.分析大约30发个网站发现共同明显的特征就是这样的网站有大量的页面只有一张或者两张图片,而这些网 ...
- DbHelper简单的使用
using System; using System.Windows.Forms; using System.Data.SqlClient; namespace WindowsFormsApp3 { ...
- Mysql(五):索引原理与慢查询优化
一 介绍 为何要有索引? 一般的应用系统,读写比例在10:1左右,而且插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句 ...
- Caffe---Pycaffe转换均值文件:xxx_mean.binaryproto成为xxx_mean.npy
Pycaffe转换均值文件:xxx_mean.binaryproto成为xxx_mean.npy 为什么需要mean.binaryproto转mean.npy? 使用Caffe的C++接口进行操作时, ...
- C++-cin与scanf cout与printf效率问题
http://blog.csdn.net/l2580258/article/details/51319387 void cin_read_nosync() { freopen("data.t ...