TF-IDF算法之关键词提取
(注:本文转载自阮一峰老师的博文,原文地址:http://www.ruanyifeng.com/blog/2013/03/tf-idf.html)
这个标题看上去好像很复杂,其实我要谈的是一个很简单的问题。
有一篇很长的文章,我要用计算机提取它的关键词(Automatic Keyphrase extraction),完全不加以人工干预,请问怎样才能正确做到?
这个问题涉及到数据挖掘、文本处理、信息检索等很多计算机前沿领域,但是出乎意料的是,有一个非常简单的经典算法,可以给出令人相当满意的结果。它简单到都不需要高等数学,普通人只用10分钟就可以理解,这就是我今天想要介绍的TF-IDF算法。
让我们从一个实例开始讲起。假定现在有一篇长文《中国的蜜蜂养殖》,我们准备用计算机提取它的关键词。
一个容易想到的思路,就是找到出现次数最多的词。如果某个词很重要,它应该在这篇文章中多次出现。于是,我们进行"词频"(Term Frequency,缩写为TF)统计。
结果你肯定猜到了,出现次数最多的词是——"的"、"是"、"在"——这一类最常用的词。它们叫做"停用词"(stop words),表示对找到结果毫无帮助、必须过滤掉的词。
假设我们把它们都过滤掉了,只考虑剩下的有实际意义的词。这样又会遇到了另一个问题,我们可能发现"中国"、"蜜蜂"、"养殖"这三个词的出现次数一样多。这是不是意味着,作为关键词,它们的重要性是一样的?
显然不是这样。因为"中国"是很常见的词,相对而言,"蜜蜂"和"养殖"不那么常见。如果这三个词在一篇文章的出现次数一样多,有理由认为,"蜜蜂"和"养殖"的重要程度要大于"中国",也就是说,在关键词排序上面,"蜜蜂"和"养殖"应该排在"中国"的前面。(注:这里的常见还是不常见是相对于整个文档库,或者说整个语言环境而言的)
所以,我们需要一个重要性调整系数,衡量一个词是不是常见词。如果某个词在一般情况下比较少见,但是它在这篇文章中多次出现,那么它很可能就反映了这篇文章的特性,正是我们所需要的关键词。举个例子,像“氢氦锂铍”这种词,在日常的语言环境中是很少出现的,一般只出现在化学类文章中,所以如果一篇文章中出现了类似词语,我们大可判定其可能是一篇化学类文章,即它的重要性系数较高;而“我们”这一词则是非常常见的,在文章中出现“我们”这种词,无法推测出更多的信息,因此它的重要性系数较低。
用统计学语言表达,就是在词频的基础上,要对每个词分配一个"重要性"权重。最常见的词("的"、"是"、"在")给予最小的权重,较常见的词("中国")给予较小的权重,较少见的词("蜜蜂"、"养殖")给予较大的权重。这个权重叫做"逆文档频率"(Inverse Document Frequency,缩写为IDF),它的大小与一个词的常见程度成反比。
知道了"词频"(TF)和"逆文档频率"(IDF)以后,将这两个值相乘,就得到了一个词的TF-IDF值。某个词对文章的重要性越高,它的TF-IDF值就越大。所以,排在最前面的几个词,就是这篇文章的关键词。
下面就是这个算法的细节。
第一步,计算词频。

考虑到文章有长短之分,为了便于不同文章的比较,进行"词频"标准化。

或者

第二步,计算逆文档频率。
这时,需要一个语料库(corpus),用来模拟语言的使用环境。
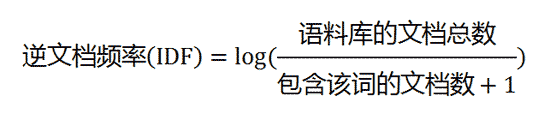
如果一个词越常见,那么分母就越大,逆文档频率就越小越接近0。分母之所以要加1,是为了避免分母为0(即所有文档都不包含该词)。log表示对得到的值取对数。
第三步,计算TF-IDF。
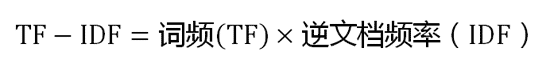
可以看到,TF-IDF值与一个词在文档中的出现次数成正比,与该词在整个语言环境中的出现次数成反比。所以,自动提取关键词的算法就很清楚了,就是计算出文档的每个词的TF-IDF值,然后按降序排列,取排在最前面的几个词。
还是以《中国的蜜蜂养殖》为例,假定该文长度为1000个词,"中国"、"蜜蜂"、"养殖"各出现20次,则这三个词的"词频"(TF)都为0.02。然后,搜索Google发现,包含"的"字的网页共有250亿张,假定这就是中文网页总数。包含"中国"的网页共有62.3亿张,包含"蜜蜂"的网页为0.484亿张,包含"养殖"的网页为0.973亿张。则它们的逆文档频率(IDF)和TF-IDF如下:
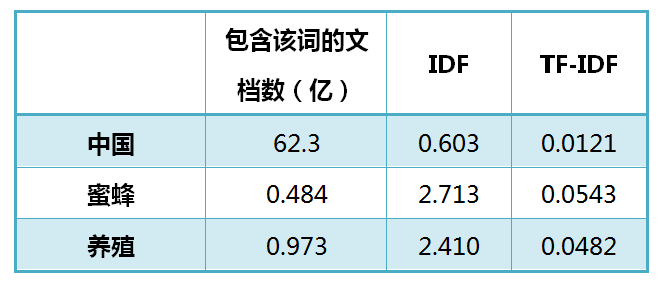
从上表可见,"蜜蜂"的TF-IDF值最高,"养殖"其次,"中国"最低。(如果还计算"的"字的TF-IDF,那将是一个极其接近0的值。)所以,如果只选择一个词,"蜜蜂"就是这篇文章的关键词。
除了自动提取关键词,TF-IDF算法还可以用于许多别的地方。比如,信息检索时,对于每个文档,都可以分别计算一组搜索词("中国"、"蜜蜂"、"养殖")的TF-IDF,将它们相加,就可以得到整个文档的TF-IDF。这个值最高的文档就是与搜索词最相关的文档。
TF-IDF算法的优点是简单快速,结果比较符合实际情况。缺点是,单纯以"词频"衡量一个词的重要性,不够全面,有时重要的词可能出现次数并不多。而且,这种算法无法体现词的位置信息,出现位置靠前的词与出现位置靠后的词,都被视为重要性相同,这是不正确的。(一种解决方法是,对全文的第一段和每一段的第一句话,给予较大的权重。)
TF-IDF算法之关键词提取的更多相关文章
- tf–idf算法解释及其python代码实现(下)
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- tf–idf算法解释及其python代码实现(上)
tf–idf算法解释 tf–idf, 是term frequency–inverse document frequency的缩写,它通常用来衡量一个词对在一个语料库中对它所在的文档有多重要,常用在信息 ...
- 55.TF/IDF算法
主要知识点: TF/IDF算法介绍 查看es计算_source的过程及各词条的分数 查看一个document是如何被匹配到的 一.算法介绍 relevance score算法,简单来说 ...
- Elasticsearch由浅入深(十)搜索引擎:相关度评分 TF&IDF算法、doc value正排索引、解密query、fetch phrase原理、Bouncing Results问题、基于scoll技术滚动搜索大量数据
相关度评分 TF&IDF算法 Elasticsearch的相关度评分(relevance score)算法采用的是term frequency/inverse document frequen ...
- tf–idf算法解释及其python代码
tf–idf算法python代码实现 这是我写的一个tf-idf的简单实现的代码,我们知道tfidf=tf*idf,所以可以分别计算tf和idf值在相乘,首先我们创建一个简单的语料库,作为例子,只有四 ...
- 25.TF&IDF算法以及向量空间模型算法
主要知识点: boolean model IF/IDF vector space model 一.boolean model 在es做各种搜索进行打分排序时,会先用boolean mo ...
- Gradle +HanLP +SpringBoot 构建关键词提取,摘要提取 。入门篇
前段时间,领导要求出一个关键字提取的微服务,要求轻量级. 对于没写过微服务的一个小白来讲.有点赶鸭子上架,但是没办法,硬着头皮上也不能说不会啊. 首先了解下公司目前的架构体系,发现并不是分布式开发,只 ...
- Elasticsearch学习之相关度评分TF&IDF
relevance score算法,简单来说,就是计算出,一个索引中的文本,与搜索文本,他们之间的关联匹配程度 Elasticsearch使用的是 term frequency/inverse doc ...
- 关键词提取TF-IDF算法/关键字提取之TF-IDF算法
TF-IDF(term frequency–inverse document frequency)是一种用于信息检索与信息探勘的常用加权技术.TF的意思是词频(Term - frequency), ...
随机推荐
- deferred.pipe([doneFilter],[failFilter],[progressFilter])
deferred.pipe([doneFilter],[failFilter],[progressFilter]) 概述 筛选器和/或链Deferreds的实用程序方法. deferred.pipe( ...
- js里url里有特殊字符(如&)情况,后台request.getParameter("url")里&变成&
js:encodeURIComponent(url) //用encodeURIComponent转码 java后台:用java.net.URLDecoder.decode((request.getPa ...
- ueditor粘贴从word中copy的图片和文字 图片无法显示的问题
我司需要做一个需求,就是使用富文本编辑器时,不要以上传附件的形式上传图片,而是以复制粘贴的形式上传图片. 在网上找了一下,有一个插件支持这个功能. WordPaster 安装方式如下: 直接使用Wor ...
- [POI2010]MOT-Monotonicity 2
洛谷题目链接 动态规划$+$线段树 题目链接(洛谷) 首先,先要明确一点,当我们填了第$i$位时,自然下一位的符号也就出来了 那么我们可以分情况讨论: $1.$当下一位是$>$时:我们可以建一棵 ...
- linux中fork--子进程是从哪里开始运行
转自 http://blog.csdn.net/koches/article/details/7787468 fork调用的一个奇妙之处就是它仅仅被调用一次,却能够返回两次,它可能有三种不同的返回值 ...
- vue中插槽(slot)的使用
刚学vue的时候,曾经学习过slot插槽的使用,但是后面接触的不多,因为之前我还没使用element-ui... 但是使用了element-ui之后,里面的许多组件,有时候会使用插槽,为了巩固一下插槽 ...
- MySQL数据分析-(8)SQL基础操作之库操作
前面我们讲了学习SQL的两个逻辑框架,jacky说了这样一个逻辑:库是为了存储表的,所以一定是先有库才有表:同样的道理,有表才有表中的数据,是吧,肯定是这个逻辑:那么,今天jacky就捋着这个逻辑从库 ...
- Egyptian Collegiate Programming Contest (ECPC 2015) C题 Connecting Graph
这题上次用的是线性求LCA过的,数据比较水,当时没有被T掉(不过线性的做法是在线的).现在重新的分析一下这个问题.在所有的操作都进行完毕以后,这个图形肯定会变成一棵树,而我们的要求是在这棵树上的一条链 ...
- elasticsearch java client
1.集群名相同,且机器处于同一局域网同一网段,es会自动去发现其他的节点.2.集群不在同一局域网同一网段时,只需要在 elasticsearch.yml 中配置目标机器和端口即可discovery.z ...
- linux 后台 运行
但是如果终端关闭的话,程序也会终止,那么就要涉及到linux的一个十分强大的命令:screen. 按照我个人的理解,这个命令就是能够在linux中创造出多个终端,在已有的窗口内部再创造更多的窗口,结合 ...