redis 简单整理——复制的原理[二十三]
前言
简单介绍一下复制的原理。
正文
在从节点执行slaveof命令后,复制过程便开始运作,下面详细介绍建立 复制的完整流程。
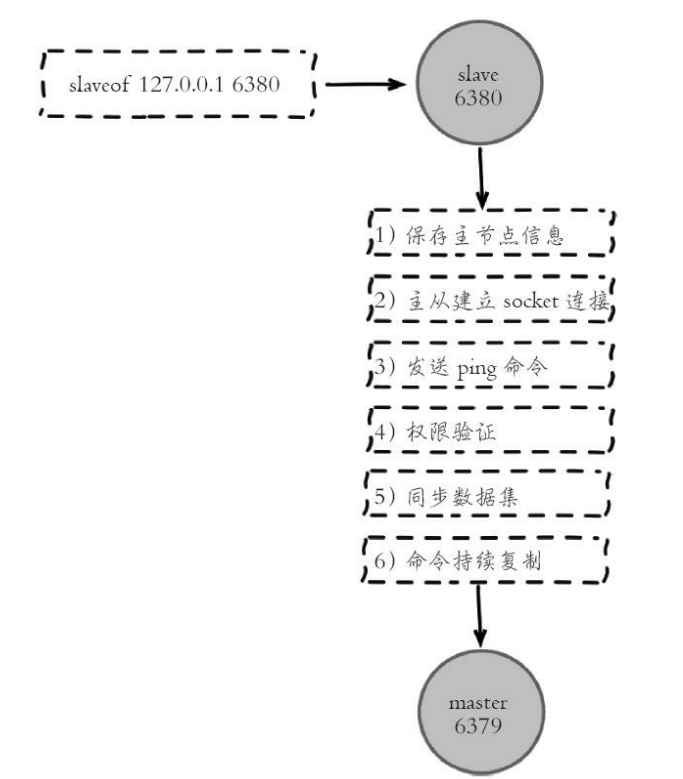
1)保存主节点(master)信息。
执行slaveof后从节点只保存主节点的地址信息便直接返回,这时建立复 制流程还没有开始,在从节点6380执行info replication可以看到如下信息:
master_host:127.0.0.1 master_port:6379 master_link_status:down
从统计信息可以看出,主节点的ip和port被保存下来,但是主节点的连 接状态(master_link_status)是下线状态。执行slaveof后Redis会打印如下日 志:
SLAVE OF 127.0.0.1:6379 enabled (user request from 'id=65 addr=127.0.0.1:58090 fd=5 name= age=11 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free= 32768 obl=0 oll=0 omem=0 events=r cmd=slaveof')
通过该日志可以帮助运维人员定位发送slaveof命令的客户端,方便追踪 和发现问题。
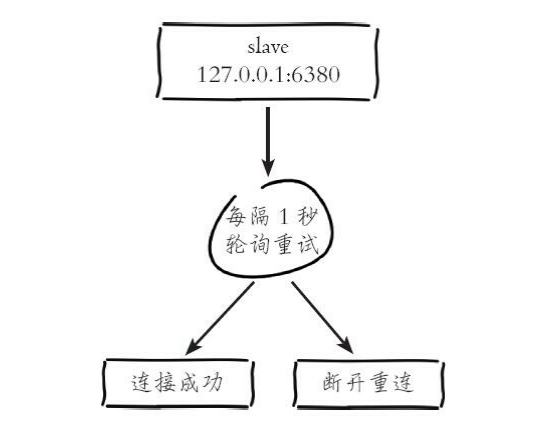
2)从节点(slave)内部通过每秒运行的定时任务维护复制相关逻辑, 当定时任务发现存在新的主节点后,会尝试与该节点建立网络连接.
从节点会建立一个socket套接字,例如图6-8中从节点建立了一个端口为 24555的套接字,专门用于接受主节点发送的复制命令。从节点连接成功后 打印如下日志:
* Connecting to MASTER 127.0.0.1:6379
* MASTER <-> SLAVE sync started
如果从节点无法建立连接,定时任务会无限重试直到连接成功或者执行 slaveof no one取消复制
关于连接失败,可以在从节点执行info replication查看 master_link_down_since_seconds指标,它会记录与主节点连接失败的系统时 间。从节点连接主节点失败时也会每秒打印如下日志,方便运维人员发现问 题:
# Error condition on socket for SYNC: {socket_error_reason}
3)发送ping命令。
连接建立成功后从节点发送ping请求进行首次通信,ping请求主要目的 如下:
·检测主从之间网络套接字是否可用。
·检测主节点当前是否可接受处理命令.
如果发送ping命令后,从节点没有收到主节点的pong回复或者超时,比如网络超时或者主节点正在阻塞无法响应命令,从节点会断开复制连接,下次定时任务会发起重连
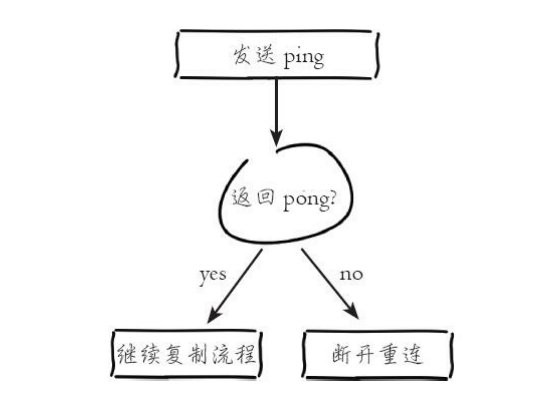
从节点发送的ping命令成功返回,Redis打印如下日志,并继续后续复制 流程:
Master replied to PING, replication can continue...
4)权限验证。如果主节点设置了requirepass参数,则需要密码验证, 从节点必须配置masterauth参数保证与主节点相同的密码才能通过验证;如 果验证失败复制将终止,从节点重新发起复制流程。
5)同步数据集。主从复制连接正常通信后,对于首次建立复制的场 景,主节点会把持有的数据全部发送给从节点,这部分操作是耗时最长的步 骤。Redis在2.8版本以后采用新复制命令psync进行数据同步,原来的sync命 令依然支持,保证新旧版本的兼容性。
6)命令持续复制。当主节点把当前的数据同步给从节点后,便完成了 复制的建立流程。接下来主节点会持续地把写命令发送给从节点,保证主从 数据一致性。
数据同步
Redis在2.8及以上版本使用psync命令完成主从数据同步,同步过程分 为:全量复制和部分复制。
·全量复制:一般用于初次复制场景,Redis早期支持的复制功能只有全 量复制,它会把主节点全部数据一次性发送给从节点,当数据量较大时,会 对主从节点和网络造成很大的开销。
·部分复制:用于处理在主从复制中因网络闪断等原因造成的数据丢失 场景,当从节点再次连上主节点后,如果条件允许,主节点会补发丢失数据 给从节点。因为补发的数据远远小于全量数据,可以有效避免全量复制的过 高开销。
部分复制是对老版复制的重大优化,有效避免了不必要的全量复制操 作。因此当使用复制功能时,尽量采用2.8以上版本的Redis。
psync命令运行需要以下组件支持:
·主从节点各自复制偏移量。
·主节点复制积压缓冲区。
·主节点运行id。
1.复制偏移量
参与复制的主从节点都会维护自身复制偏移量。主节点(master)在处理完写入命令后,会把命令的字节长度做累加记录,统计信息在inforelication中的master_repl_offset指标中:

从节点(slave)每秒钟上报自身的复制偏移量给主节点,因此主节点 也会保存从节点的复制偏移量,统计指标如下:

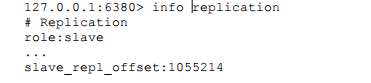
从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量。统 计信息在info relication中的slave_repl_offset指标中:
通过对比主从节点的复制偏移量,可以判断主从节点数据是否一致。
可以通过主节点的统计信息,计算出master_repl_offset-slave_offset字节 量,判断主从节点复制相差的数据量,根据这个差值判定当前复制的健康 度。如果主从之间复制偏移量相差较大,则可能是网络延迟或命令阻塞等原因引起。
2.复制积压缓冲区
复制积压缓冲区是保存在主节点上的一个固定长度的队列,默认大小为 1MB,当主节点有连接的从节点(slave)时被创建,这时主节点(master) 响应写命令时,不但会把命令发送给从节点,还会写入复制积压缓冲区.

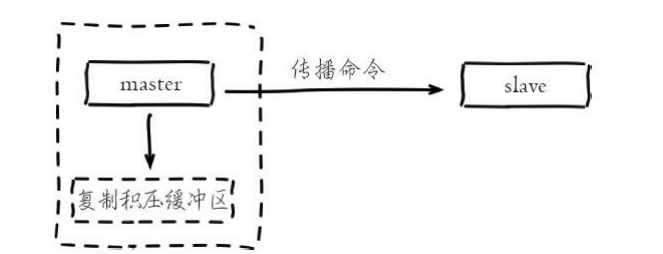
由于缓冲区本质上是先进先出的定长队列,所以能实现保存最近已复制 数据的功能,用于部分复制和复制命令丢失的数据补救。复制缓冲区相关统计信息保存在主节点的info replication中:

根据统计指标,可算出复制积压缓冲区内的可用偏移量范围: [repl_backlog_first_byte_offset, repl_backlog_first_byte_offset+repl_backlog_histlen]。
每个Redis节点启动后都会动态分配一个40位的十六进制字符串作为运 行ID。
运行ID的主要作用是用来唯一识别Redis节点,比如从节点保存主节 点的运行ID识别自己正在复制的是哪个主节点。
如果只使用ip+port的方式识 别主节点,那么主节点重启变更了整体数据集(如替换RDB/AOF文件), 从节点再基于偏移量复制数据将是不安全的,因此当运行ID变化后从节点将 做全量复制。
可以运行info server命令查看当前节点的运行ID:
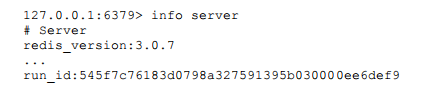
需要注意的是Redis关闭再启动后,运行ID会随之改变,例如执行如下 命令:
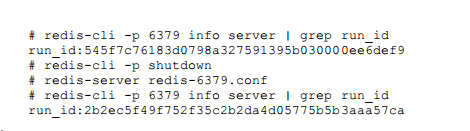
如何在不改变运行ID的情况下重启呢?
当需要调优一些内存相关配置,例如:hash-max-ziplist-value等,这些配 置需要Redis重新加载才能优化已存在的数据,这时可以使用debug reload命 令重新加载RDB并保持运行ID不变,从而有效避免不必要的全量复制。命令 如下:

提示:debug reload命令会阻塞当前Redis节点主线程,阻塞期间会生成本地 RDB快照并清空数据之后再加载RDB文件。因此对于大数据量的主节点和无 法容忍阻塞的应用场景,谨慎使用。
从节点使用psync命令完成部分复制和全量复制功能,命令格式: psync{runId}{offset},参数含义如下:
runId:从节点所复制主节点的运行id。
offset:当前从节点已复制的数据偏移量。
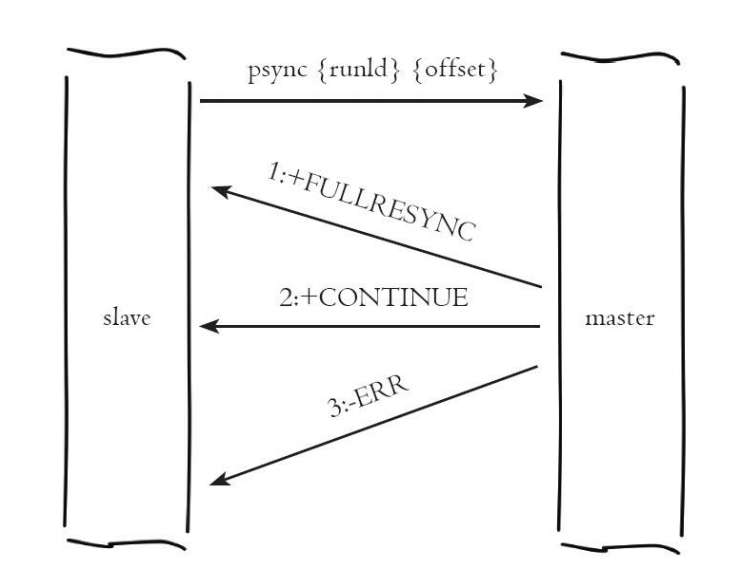
1)从节点(slave)发送psync命令给主节点,参数runId是当前从节点保 存的主节点运行ID,如果没有则默认值为,参数offset是当前从节点保存的 复制偏移量,如果是第一次参与复制则默认值为-1。
2)主节点(master)根据psync参数和自身数据情况决定响应结果:
·如果回复+FULLRESYNC{runId}{offset},那么从节点将触发全量复制流程。
·如果回复+CONTINUE,从节点将触发部分复制流程。
·如果回复+ERR,说明主节点版本低于Redis2.8,无法识别psync命令, 从节点将发送旧版的sync命令触发全量复制流程。
全量复制
全量复制是Redis最早支持的复制方式,也是主从第一次建立复制时必 须经历的阶段。触发全量复制的命令是sync和psync.
这里主要介绍psync全量复制流程,它与2.8以前的sync全量复制机制基 本一致。
流程说明:
1)发送psync命令进行数据同步,由于是第一次进行复制,从节点没有复制偏移量和主节点的运行ID,所以发送psync-1。
2)主节点根据psync-1解析出当前为全量复制,回复+FULLRESYNC响 应。
3)从节点接收主节点的响应数据保存运行ID和偏移量offset,执行到当 前步骤时从节点打印如下日志:
Partial resynchronization not possible (no cached master) Full resync from master: 92d1cb14ff7ba97816216f7beb839efe036775b2:216789
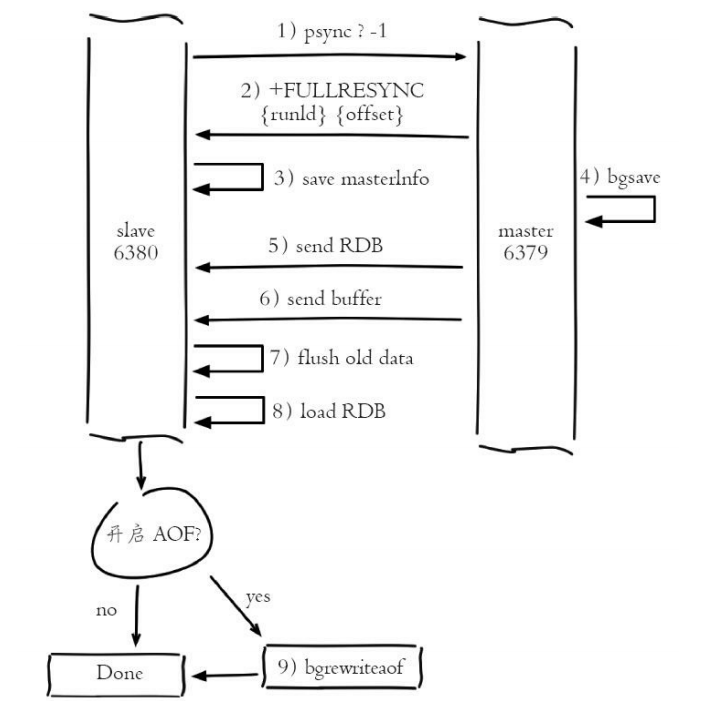
4)主节点执行bgsave保存RDB文件到本地
主节点bgsave相关日志如下:

Redis3.0之后在输出的日志开头会有M、S、C等标识,对应的含义是: M=当前为主节点日志,S=当前为从节点日志,C=子进程日志,我们可以根 据日志标识快速识别出每行日志的角色信息。
5)主节点发送RDB文件给从节点,从节点把接收的RDB文件保存在本 地并直接作为从节点的数据文件,接收完RDB后从节点打印相关日志,可以 在日志中查看主节点发送的数据量:
16:24:03.057 * MASTER <-> SLAVE sync: receiving 24777842 bytes from master
需要注意,对于数据量较大的主节点,比如生成的RDB文件超过6GB以 上时要格外小心。传输文件这一步操作非常耗时,速度取决于主从节点之间 网络带宽,通过细致分析Full resync和MASTER<->SLAVE这两行日志的时间 差,可以算出RDB文件从创建到传输完毕消耗的总时间。如果总时间超过 repl-timeout所配置的值(默认60秒),从节点将放弃接受RDB文件并清理已 经下载的临时文件,导致全量复制失败,此时从节点打印如下日志:

针对数据量较大的节点,建议调大repl-timeout参数防止出现全量同步数 据超时。例如对于千兆网卡的机器,网卡带宽理论峰值大约每秒传输 100MB,在不考虑其他进程消耗带宽的情况下,6GB的RDB文件至少需要60秒传输时间,默认配置下,极易出现主从数据同步超时。
关于无盘复制:为了降低主节点磁盘开销,Redis支持无盘复制,生成 的RDB文件不保存到硬盘而是直接通过网络发送给从节点,通过repl- diskless-sync参数控制,默认关闭。无盘复制适用于主节点所在机器磁盘性 能较差但网络带宽较充裕的场景。注意无盘复制目前依然处于试验阶段,线 上使用需要做好充分测试。
6)对于从节点开始接收RDB快照到接收完成期间,主节点仍然响应读 写命令,因此主节点会把这期间写命令数据保存在复制客户端缓冲区内,当 从节点加载完RDB文件后,主节点再把缓冲区内的数据发送给从节点,保证 主从之间数据一致性。如果主节点创建和传输RDB的时间过长,对于高流量 写入场景非常容易造成主节点复制客户端缓冲区溢出。
默认配置为client- output-buffer-limit slave256MB64MB60,如果60秒内缓冲区消耗持续大于 64MB或者直接超过256MB时,主节点将直接关闭复制客户端连接,造成全 量同步失败。对应日志如下:

因此,运维人员需要根据主节点数据量和写命令并发量调整client- output-buffer-limit slave配置,避免全量复制期间客户端缓冲区溢出。
对于主节点,当发送完所有的数据后就认为全量复制完成,打印成功日 志:Synchronization with slave127.0.0.1:6380succeeded,但是对于从节点全 量复制依然没有完成,还有后续步骤需要处理。
7)从节点接收完主节点传送来的全部数据后会清空自身旧数据,该步 骤对应如下日志:

8)从节点清空数据后开始加载RDB文件,对于较大的RDB文件,这一 步操作依然比较耗时,可以通过计算日志之间的时间差来判断加载RDB的总 耗时,对应如下日志:

对于线上做读写分离的场景,从节点也负责响应读命令。如果此时从节 点正出于全量复制阶段或者复制中断,那么从节点在响应读命令可能拿到过 期或错误的数据。
对于这种场景,Redis复制提供了slave-serve-stale-data参 数,默认开启状态。
如果开启则从节点依然响应所有命令。
对于无法容忍不 一致的应用场景可以设置no来关闭命令执行,此时从节点除了info和slaveof 命令之外所有的命令只返回“SYNC with master in progress”信息。
9)从节点成功加载完RDB后,如果当前节点开启了AOF持久化功能, 它会立刻做bgrewriteaof操作,为了保证全量复制后AOF持久化文件立刻可用
通过分析全量复制的所有流程,读者会发现全量复制是一个非常耗时费 力的操作。它的时间开销主要包括:
·主节点bgsave时间。
·RDB文件网络传输时间。
·从节点清空数据时间。
·从节点加载RDB的时间。
·可能的AOF重写时间
例如我们线上数据量在6G左右的主节点,从节点发起全量复制的总耗 时在2分钟左右。因此当数据量达到一定规模之后,由于全量复制过程中将 进行多次持久化相关操作和网络数据传输,这期间会大量消耗主从节点所在 服务器的CPU、内存和网络资源。所以除了第一次复制时采用全量复制在所 难免之外,对于其他场景应该规避全量复制的发生。正因为全量复制的成本 问题,Redis实现了部分复制功能。
部分复制
部分复制主要是Redis针对全量复制的过高开销做出的一种优化措施, 使用psync{runId}{offset}命令实现。当从节点(slave)正在复制主节点 (master)时,如果出现网络闪断或者命令丢失等异常情况时,从节点会向 主节点要求补发丢失的命令数据,如果主节点的复制积压缓冲区内存在这部 分数据则直接发送给从节点,这样就可以保持主从节点复制的一致性。补发 的这部分数据一般远远小于全量数据,所以开销很小。
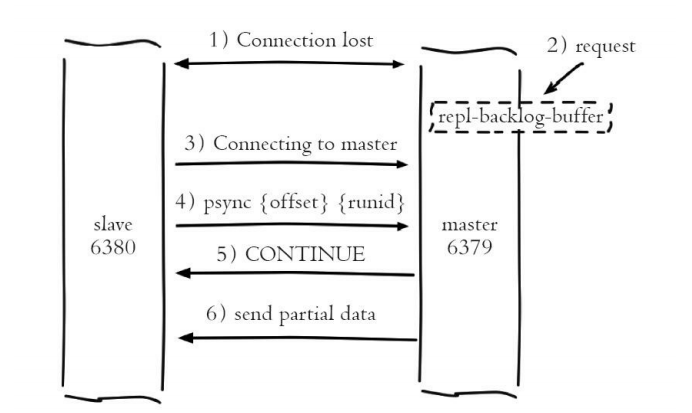
1)当主从节点之间网络出现中断时,如果超过repl-timeout时间,主节点会认为从节点故障并中断复制连接,打印如下日志:

如果此时从节点没有宕机,也会打印与主节点连接丢失日志:

2)主从连接中断期间主节点依然响应命令,但因复制连接中断命令无 法发送给从节点,不过主节点内部存在的复制积压缓冲区,依然可以保存最 近一段时间的写命令数据,默认最大缓存1MB。
3)当主从节点网络恢复后,从节点会再次连上主节点,打印如下日志

4)当主从连接恢复后,由于从节点之前保存了自身已复制的偏移量和 主节点的运行ID。因此会把它们当作psync参数发送给主节点,要求进行部 分复制操作。该行为对应从节点日志如下:

5)主节点接到psync命令后首先核对参数runId是否与自身一致,如果一 致,说明之前复制的是当前主节点;之后根据参数offset在自身复制积压缓 冲区查找,如果偏移量之后的数据存在缓冲区中,则对从节点发送
+CONTINUE响应,表示可以进行部分复制。从节点接到回复后打印如下日志:

6)主节点根据偏移量把复制积压缓冲区里的数据发送给从节点,保证 主从复制进入正常状态。发送的数据量可以在主节点的日志获取,如下所 示:

从日志中可以发现这次部分复制只同步了78字节,传递的数据远远小于全量数据。
心跳
主从节点在建立复制后,它们之间维护着长连接并彼此发送心跳命令.
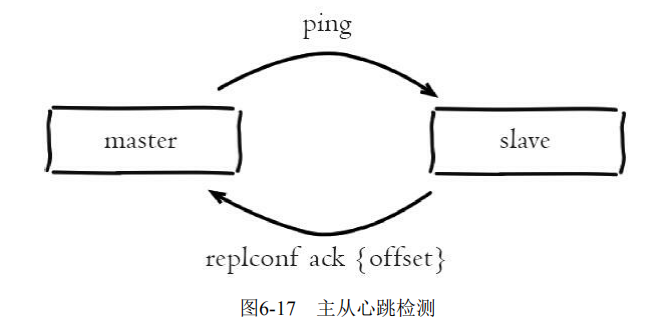
主从心跳判断机制:
1)主从节点彼此都有心跳检测机制,各自模拟成对方的客户端进行通 信,通过client list命令查看复制相关客户端信息,主节点的连接状态为 flags=M,从节点连接状态为flags=S。
2)主节点默认每隔10秒对从节点发送ping命令,判断从节点的存活性 和连接状态。可通过参数repl-ping-slave-period控制发送频率。
3)从节点在主线程中每隔1秒发送replconf ack{offset}命令,给主节点 上报自身当前的复制偏移量。replconf命令主要作用如下:
·实时监测主从节点网络状态。
·上报自身复制偏移量,检查复制数据是否丢失,如果从节点数据丢失,再从主节点的复制缓冲区中拉取丢失数据。
·实现保证从节点的数量和延迟性功能,通过min-slaves-to-write、min- slaves-max-lag参数配置定义。
主节点根据replconf命令判断从节点超时时间,体现在info replication统计中的lag信息中,lag表示与从节点最后一次通信延迟的秒数,正常延迟应 该在0和1之间。
如果超过repl-timeout配置的值(默认60秒),则判定从节点 下线并断开复制客户端连接。即使主节点判定从节点下线后,如果从节点重新恢复,心跳检测会继续进行。
注意:为了降低主从延迟,一般把Redis主从节点部署在相同的机房/同城机 房,避免网络延迟和网络分区造成的心跳中断等情况。
主节点不但负责数据读写,还负责把写命令同步给从节点。写命令的发送过程是异步完成,也就是说主节点自身处理完写命令后直接返回给客户 端,并不等待从节点复制完成
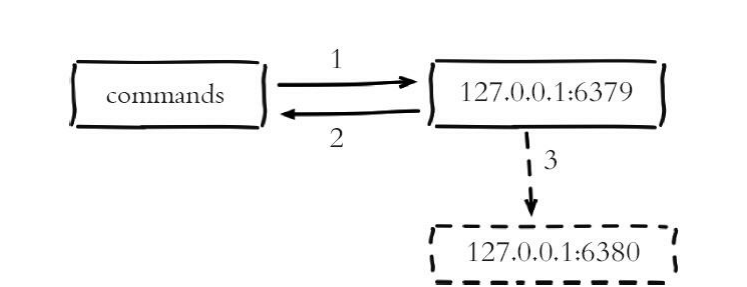
主节点复制流程:
1)主节点6379接收处理命令。
2)命令处理完之后返回响应结果。
3)对于修改命令异步发送给6380从节点,从节点在主线程中执行复制 的命令
由于主从复制过程是异步的,就会造成从节点的数据相对主节点存在延 迟。具体延迟多少字节,我们可以在主节点执行info replication命令查看相关指标获得。

在统计信息中可以看到从节点slave0信息,分别记录了从节点的ip和port,从节点的状态,offset表示当前从节点的复制偏移量, master_repl_offset表示当前主节点的复制偏移量,两者的差值就是当前从节点复制延迟量。
Redis的复制速度取决于主从之间网络环境,repl-disable- tcp-nodelay,命令处理速度等。正常情况下,延迟在1秒以内。
结
下一节开发运维中的问题。
redis 简单整理——复制的原理[二十三]的更多相关文章
- Redis哨兵、复制、集群的设计原理与区别
一 前言 谈到Redis服务器的高可用,如何保证备份的机器是原始服务器的完整备份呢?这时候就需要哨兵和复制. 哨兵(Sentinel):可以管理多个Redis服务器,它提供了监控,提醒以及自动的故障转 ...
- Redis复制实现原理
摘要 我的前一篇文章<Redis 复制原理及特性>已经介绍了Redis复制相关特性,这篇文章主要在理解Redis复制相关源码的基础之上介绍Redis复制的实现原理. Redis复制实现原理 ...
- Redis 入门到分布式 (七)Redis复制的原理与优化
一.目录 Redis复制的原理与优化 什么是主从复制 全量复制和部分复制 复制的配置 故障处理 开发运维常见问题 二. 什么是主从复制 1.单机有什么问题? 单机如果机器故障,那么久无法及时提供服务: ...
- Redis的高可用详解:Redis哨兵、复制、集群的设计原理,以及区别
谈到Redis服务器的高可用,如何保证备份的机器是原始服务器的完整备份呢?这时候就需要哨兵和复制. 哨兵(Sentinel):可以管理多个Redis服务器,它提供了监控,提醒以及自动的故障转移的功能. ...
- Redis哨兵、复制、集群的设计原理,以及区别
广西SEO:谈到Redis服务器的高可用,如何保证备份的机器是原始服务器的完整备份呢?这时候就需要哨兵和复制. **哨兵(Sentinel):**可以管理多个Redis服务器,它提供了监控,提醒以及自 ...
- 性能测试二十三:环境部署之Redis安装和配置
redis:非关系型数据库,内存数据库,no-sql典型, 数据存放在内存中,一断电或者关闭就没有了 mysql.oracle.sqlserver···是关系型数据库,数据存放在磁盘中 一个Red ...
- Redis实现之复制(二)
PSYNC命令的实现 在Redis实现之复制(一)这一章中,我们介绍了PSYNC命令和它的工作机制,但一直没有说明PSYNC命令的参数以及返回值.现在,我们了解了运行ID.复制偏移量.复制积压缓冲区以 ...
- 重新整理 .net core 实践篇—————路由和终结点[二十三]
前言 简单整理一下路由和终节点. 正文 路由方式主要有两种: 1.路由模板方式 2.RouteAttribute 方式 路由约束: 1.类型约束 2.范围约束 3.正则表达式 4.是否必选 5.自定义 ...
- Redis 知识 整理
简介 安装 启动 注意事项 使用命令 通用命令 数据结构 字符串(string) 哈希(hash) 队列(list) 集合(set) 有序集合(zset) 位图(bitcount) 事务 订阅与发布 ...
- redis 系列21 复制Replication (上)
一. 概述 使用和配置主从复制非常简单,每次当 slave 和 master 之间的连接断开时, slave 会自动重连到 master 上,并且无论这期间 master 发生了什么, slave ...
随机推荐
- MySQL---面经
如果想要对 MySQL 的索引树有更深入的了解,掘金的小册子:<MySQL 是怎样运行的> MySQL 是怎样运行的 以下是常见面试题 MySQL日志 MySQL日志系统 redo_log ...
- 使用LabVIEW打开默认应用程序中的文档(PDF,Word,Excel,Html)
问题详情 我想让我的LabVIEW VI使用默认应用程序打开硬盘上的文档.如何实现? 解决方案 有一个名为 "Open a Document on Disk.vi" 的 VI,它可 ...
- 提升地理空间分析效率,火山引擎ByteHouse上线GIS能力
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 在数字化时代,地理空间分析(Geospatial Analytics)成为辅助企业市场策略洞察的重要手段.无论是广 ...
- ACER 宏碁 笔记本无法进入 grub 引导 + 安全启动失败(security boot fail ) 解决办法
主要介绍让BIOS首先引导grub的方法 加一点:添加完新的启动选项以后,如果看不到添加的启动项,就先保存重启,再进 BIOS 就可以看到了 我是宏碁的笔记本,装了双系统.之前无意间进了一次 BIOS ...
- Linux Daemon & 单例模式 设计与实现
PS:要转载请注明出处,本人版权所有. PS: 这个只是基于<我自己>的理解, 如果和你的原则及想法相冲突,请谅解,勿喷. 前置说明 本文作为本人csdn blog的主站的备份.(Bl ...
- Java反序列化学习
前言 早知前路多艰辛,仙尊悔而我不悔.Java反序列化,免费一位,开始品鉴,学了这么久web,还没深入研究Java安全,人生一大罪过.诸君,请看. 序列化与反序列化 简单demo: import ja ...
- 直播预约 | 邀您共同探讨“云XR技术如何改变元宇宙的虚拟体验”
随着数字化时代的到来,元宇宙成为了人们关注的焦点.它是一个虚拟的世界,融合了现实与虚拟的元素,让人们可以以全新的方式进行交互.创作和体验. 云XR技术是元宇宙建设的重要支撑技术之一,元宇宙需要具备高度 ...
- 记一次 .NET某施工建模软件 卡死分析
一:背景 1. 讲故事 前几天有位朋友在微信上找到我,说他的软件卡死了,分析了下也不知道是咋回事,让我帮忙看一下,很多朋友都知道,我分析dump是免费的,当然也不是所有的dump我都能搞定,也只能尽自 ...
- 性能测试系列:高可用测试linux常用命令
一 linux常用 df –h 看磁盘 du –h –max-depth=1 查看当前目录下,各个文件夹大小 ls –lht 查看当前目录下,各个文件大小 top –H –p pid 看进程下线程的资 ...
- C# WinForm 获取执行路径的几种常见方法
//1.获取模块的完整路径. string path1 = System.Diagnostics.Process.GetCurrentProcess().MainModule.FileName; Co ...