【Flink入门修炼】1-4 Flink 核心概念与架构
前面几篇文章带大家了解了 Flink 是什么、能做什么,本篇将带大家了解 Flink 究竟是如何完成这些的,Flink 本身架构是什么样的,让大家先对 Flink 有整体认知,便于后期理解。
一、Flink 组件栈
Flink是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。Flink分层的组件栈如下图所示:

Deployment 层
该层主要涉及了Flink的部署模式,Flink支持多种部署模式:
- 本地、集群(Standalone/YARN)
- 云(GCE/EC2)
- Standalone部署模式与Spark类似。
我们看一下Flink on YARN的部署模式,如下图所示:

通过上图可以看到,YARN AM 与 Flink JobManager 在同一个 Container 中,这样 AM 可以知道 Flink JobManager 的地址,从而 AM 可以申请 Container 去启动 Flink TaskManager。
待 Flink 成功运行在 YARN 集群上,Flink YARN Client 就可以提交 Flink Job 到 Flink JobManager,并进行后续的映射、调度和计算处理。
Runtime层
Runtime 层提供了支持 Flink 计算的全部核心实现,比如:
- 支持分布式 Stream 处理
- JobGraph 到 ExecutionGraph 的映射、调度等等,为上层API层提供基础服务。
API层
API 层主要实现了面向无界 Stream 的流处理和面向 Batch 的批处理 API。
其中面向流处理对应 DataStream API,面向批处理对应 DataSet API。
Libraries 层
该层也可以称为 Flink 应用框架层,根据 API 层的划分,在 API 层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理和面向批处理两类。
- 面向流处理支持:CEP(复杂事件处理)、基于 SQL-like 的操作(基于 Table 的关系操作);
- 面向批处理支持:FlinkML(机器学习库)、Gelly(图处理)。
二、Flink 集群架构
主要为 Runtime 层细分。
Flink 的通用系统架构如下图所示。
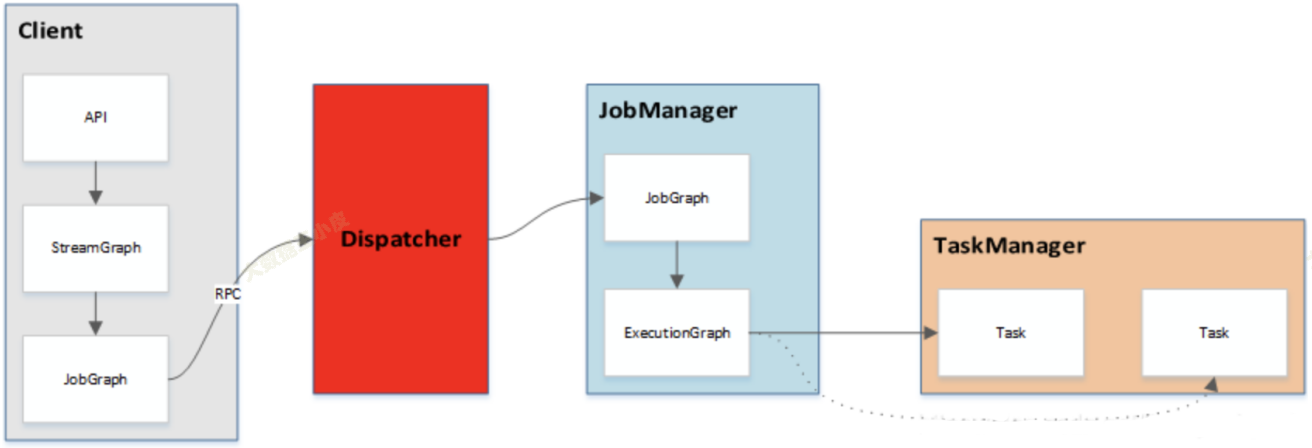
- 用户在客户端提交作业(Job)到服务端。
- 服务端为分布式的主从架构。
- Dispatcher 服务负责提供 REST 接口来接收 Client 提交的 Job,运行 Web UI,并负责启动和派发 Job 给 JobManager。
- Resource Manager 负责计算资源(TaskManager)的管理,其调度单位是 slots。
- JobManager 负责整个集群的任务管理、资源管理、协调应用程序的分布执行,将任务调度到 TaskManager 执行、检查点(checkpoint)的创建等工作。
- TaskManager(worker)负责 SubTask 的实际执行,提供一定数量的 Slots,Slots 数就是 TM 可以并发执行的task数。当服务端的 JobManager 接收到一个 Job 后,会按照各个算子的并发度将 Job 拆分成多个 SubTask,并分配到 TaskManager 的 Slot 上执行。

任务的提交流程如下所示:
三、编程模型(API层次结构)
主要为 API & Library 层细分。
Flink提供了不同层次的接口,方便开发者灵活的开发流处理、批处理应用,根据接口使用的便捷性、表达能力的强弱分为四层:

- 最底层提供了有状态流:可以自定义状态信息和处理逻辑,但是也需要你自己管理状态的生命周期,容错,一致性等问题。
- 核心开发层:包括 DataStream API 和 DataSet API,它们提供了常见的数据转换,分组,聚合,窗口,状态等操作。这个层级的 api 适合大多数的流式和批式处理的场景。
- 声明式 DSL 层:是以表为中心的声明式 DSL,其中表可能会动态变化(在表达流数据时)。Table API 提供了例如 select、project、join、group-by、aggregate 等操作
- 结构化层:SQL API,它是最高层的 api,可以直接使用 SQL 语句进行数据处理,无需编写 Java 或 Scala 代码。这个层级的 api 适合需要快速响应业务需求,缩短上线周期,和自动调优的场景,但也最不灵活和最不具有表现力。
四、Flink 数据流图
前一篇《WordCount 实现》文章中,我们写了一个入门程序,那么代码中的输入、输出、计算等算子是如何与上面的概念对应起来的呢?
程序由多个 DataStream API 组成,这些 API,又被称为算子 (Operator),共同组成了逻辑视角。在实际执行过程中,逻辑视角会被计算引擎翻译成可并行的物理视角。
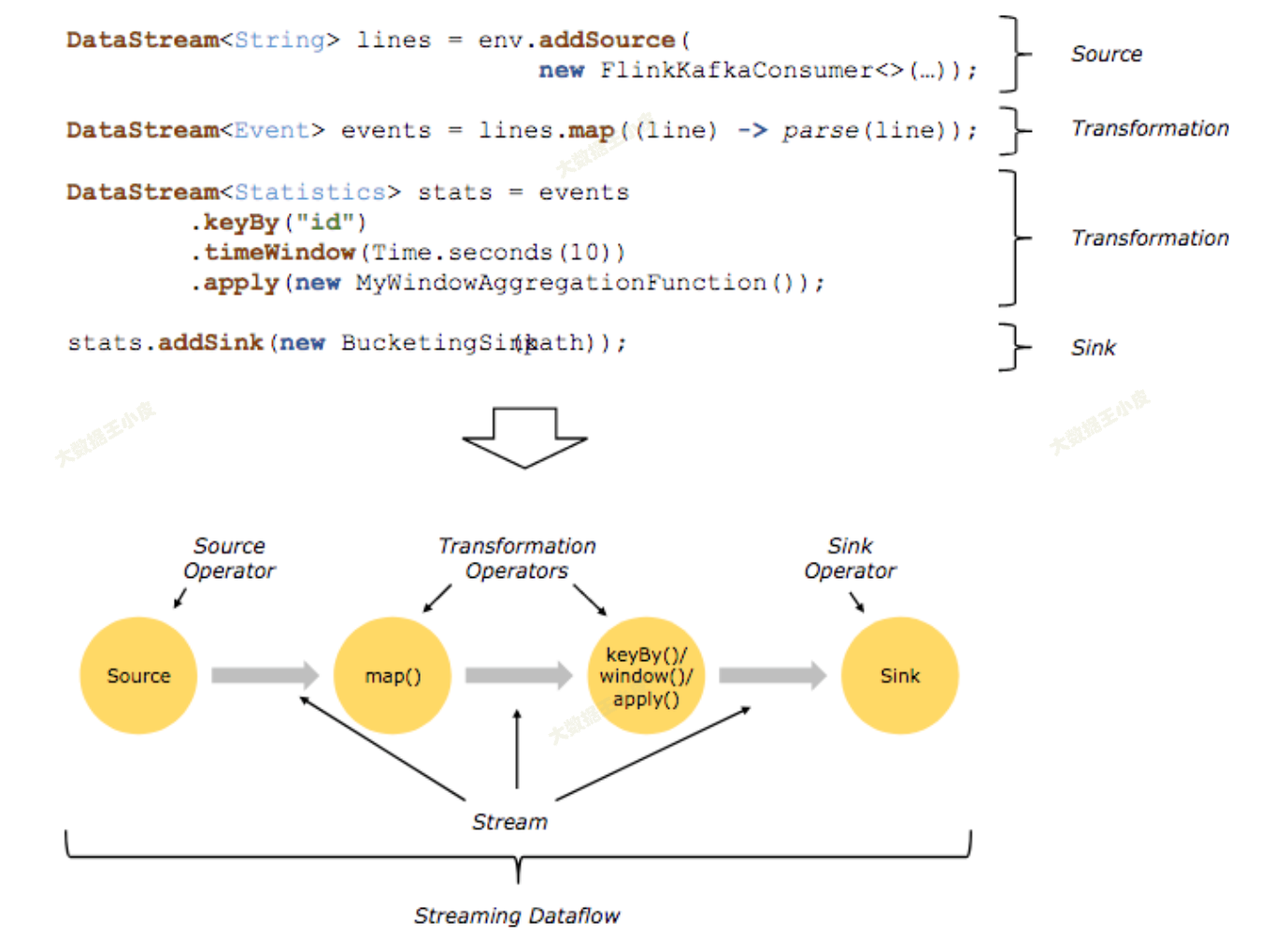
在实际执行过程中,这些 API 或者说这些算子是并行地执行的。
- 分区:在大数据领域,当数据量大到超过单台机器处理能力时,就将一份数据切分到多个分区(pattition)上,每个分区分布在一个虚拟机或物理机。
- 并行:从物理视角上看,每个算子是并行的,一个算子有一个或多个算子子任务(Subtask),每个算子子任务只处理一小部分数据,所有算子子任务共同组成了一个算子。根据算子所做的任务不同,算子子任务的个数可能也不同。
- 独立:算子子任务是相互独立的,一个算子子任务有自己的线程,不同算子子任务可能分布在不同的物理机或虚拟机上。
- 数据交换:
- 直传:source -> map,数据完全传递
- 重分配:map -> keyBy,数据按照一定方式重新分配到多个算子中
- 聚合:keyBy -> sink,多个算子的输出数据合并到一个算子中

五、小结
本篇文章从 Flink 组件栈开始,介绍 Flink 的分层架构,然后对每一层(Deploment、Runtime、API)进行了细致的讲解,说明每一层的作用和架构。最后对 Flink 数据流图进行了讲解,说明 Flink 代码是如何对应到具体执行的 task 的。
通过本篇讲解带大家了解了 Flink 整体架构,对 Flink 工作结构有了一个基础的认知,后面将会对每个 Flink 核心概念和组件进行细致的讲解。
参考文章:
Flink CookBook—Apach Flink核心知识介绍
Flink架构及工作原理介绍 - Workspace of LionHeart
Flink 架构 - 官方文档
God-Of-BigData/大数据框架学习/Flink核心概念综述.md at master · wangzhiwubigdata/God-Of-BigData
【Flink入门修炼】1-4 Flink 核心概念与架构的更多相关文章
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
- Elasticsearch入门教程(二):Elasticsearch核心概念
原文:Elasticsearch入门教程(二):Elasticsearch核心概念 版权声明:本文为博主原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接和本声明. 本文链接:ht ...
- Flink项目实战(一)---核心概念及基本使用
前言.flink介绍: Apache Flink 是一个分布式处理引擎,用于在无界和有界数据流上进行有状态的计算.通过对时间精确控制以及状态化控制,Flink能够运行在任何处理无界流的应用中,同时对有 ...
- Flink入门(二)——Flink架构介绍
1.基本组件栈 了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富 ...
- flink 入门
http://ifeve.com/flink-quick-start/ http://vinoyang.com/2016/05/02/flink-concepts/ http://wuchong.me ...
- Flink入门(四)——编程模型
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink的编程模型. 数据集类型: 无穷数据集:无穷的持续集成的数据集合 有界数据集:有 ...
- Flink入门(三)——环境与部署
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行,包括本地调试环境,集群 ...
- Flink入门(五)——DataSet Api编程指南
Apache Flink Apache Flink 是一个兼顾高吞吐.低延迟.高性能的分布式处理框架.在实时计算崛起的今天,Flink正在飞速发展.由于性能的优势和兼顾批处理,流处理的特性,Flink ...
- 入门大数据---Flink核心概念综述
一.Flink 简介 Apache Flink 诞生于柏林工业大学的一个研究性项目,原名 StratoSphere .2014 年,由 StratoSphere 项目孵化出 Flink,并于同年捐赠 ...
- Flink SQL 核心概念剖析与编程案例实战
本次,我们从 0 开始逐步剖析 Flink SQL 的来龙去脉以及核心概念,并附带完整的示例程序,希望对大家有帮助! 本文大纲 一.快速体验 Flink SQL 为了快速搭建环境体验 Flink SQ ...
随机推荐
- python pip手动安装二进制包
python中使用pip安装扩展包的时候,有时候会遇到如下类似报错: Running setup.py install for mysqlclient ... error ...(中间报错信息省略) ...
- 8. exporter
一.已经实现的收集器 1.1 可收集的内存指标 1.2 可收集的jetty指标 二.自定义收集 2.1 summer 2.2 histogram 三.架构设计 exporter作为Prometheus ...
- AMBA总线介绍-02
AMBA总线介绍 1 HSIZE AHB总线的地址位宽和数据位宽一般都是32bit,一个字节8bit,一个字节占用一个地址空间,但当一个32bit的数据写入一个存储器中或者从一个存储器中读取,32bi ...
- 2023 SHCTF-校外赛道 PWN WP
WEEK1 nc 连接靶机直接梭 hard nc 同样是nc直接连,但是出题人利用linux命令的特性,将部分flag放在了特殊文件中 利用ls -a查看所有文件,查看.gift,可以得到前半段 然后 ...
- JMS微服务开发示例(五)生成短token,实现用户无状态登录
用户token,也可以利用第三方框架生成,JMS也包含了自己的token服务器. 部署TokenServer 到这里下载 tokenserver.zip,然后部署运行TokenServer. 微服务中 ...
- [转帖]Nginx access log 按日期保存记录
https://cloud.tencent.com/developer/article/1958304 $time_iso8601 生成格式:2021-09-18T15:16:35+08:00 ...
- [转帖]解Bug之路-记一次中间件导致的慢SQL排查过程
https://zhuanlan.zhihu.com/p/242265937 解Bug之路-记一次中间件导致的慢SQL排查过程 前言 最近发现线上出现一个奇葩的问题,这问题让笔者定位了好长时间,期间排 ...
- [转帖]CTF -bugku-misc(持续更新直到全部刷完)
CTF -bugku-misc(持续更新直到全部刷完) https://www.cnblogs.com/cat47/p/11432475.html 1.签到题 点开可见.(这题就不浪费键盘了) CTF ...
- [转帖]龙芯3A5000评测 国产自主指令集架构实战
https://tieba.baidu.com/p/8297036384?pid=147031768904&cid=#147031768904 芯片,是世界一大难题,很多人难以想象电子硬件 ...
- Ubuntu2204设置固定IP地址
前言 Ubuntu每次升级都会修改一部分组件. 从1804开始Ubuntu开始使用netplan的方式进行网络设置. 但是不同版本的配置一直在升级与变化. 今天掉进坑里折腾了好久. 所以这边总结一下, ...