稳定、省钱的 ClickHouse 读写分离方案:基于 JuiceFS 的主从架构实践
Jerry 是一家位于北美的科技公司,利用人工智能和机器学习技术,简化汽车保险和贷款的比价和购买流程。在美国,Jerry 的应用在其所属领域排名第一。
随着数据规模的增长,Jerry 在使用 AWS Redshift 时遇到了一些性能与成本的挑战。Jerry 重新设计了系统架构,使用 ClickHouse 后,数据查询性能提升了 20 倍,并大幅降低了成本。但在使用过程中也遇到了磁盘损坏和数据恢复等诸多存储挑战。作为初创公司,Jerry 希望避免对 ClickHouse 集群进行大量的维护工作。
于是,Jerry 采纳了 JuiceFS, 并创新性地使用其快照功能实现了 ClickHouse 主从架构。这一架构不仅确保了数据的高可用性和稳定性,还显著提高了系统的性能和数据恢复能力。在超过一年的时间里无停机和无复制错误,并提供了可预期的性能。
01 Jerry 数据架构:从 Redshift 到 ClickHouse
起初,我们很自然地选择使用 Redshift 来满足分析查询的需求。然而,随着数据量的急剧增长,我们开始遭遇严重的性能和成本挑战。例如,在生成漏斗和 AB 测试报表时,我们面临着长达数十分钟的加载等待时间。即便在规模合理的 Redshift 集群上,这些操作也耗时过长,导致数据服务一度陷入不可用状态。
我们需要一个更快、更经济的解决方案,并且我们可以接受其不支持实时的更新和删除操作的特性。基于这些条件,在三四年前的时间背景下,ClickHouse 成为了我们的首选。随后,我们成功切换到 ClickHouse,并引入了全新的数据仓库设计,最终取得的成果如下:
重要报表的加载时间从原先的十几分钟到几十分钟大幅缩短至几秒,显著提升了数据处理的效率。我们的总成本降低至原来的四分之一,甚至更低。这一变革让我们的团队以及其他相关部门倍感欣喜,因为他们现在能够更高效地工作,迭代速度更快,且能够编写直观的 SQL 查询。对于 Jerry 而言,是一次巨大的成功。
Jerry 目前采用的架构以 ClickHouse 为核心,辅以 Snowflake。在大部分场景下,即 99% 的数据应用场景中,都依赖 ClickHouse 的高效处理能力。当面临 ClickHouse 无法处理的 1%的数据任务时,我们采取将数据转移至 Snowflake 进行处理的策略。我们做了一些工作以确保用户平滑地在 ClickHouse 与 Snowflake 之间进行数据交换。
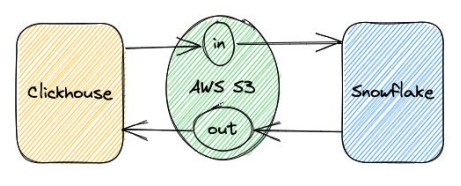
02 ClickHouse 部署方式与挑战
我们预计在较长一段时间内维持单机状态。在决定采用此种方法前,我们审慎地评估了单机部署的可持续性,并非仅着眼于眼前的部署需求,而是基于对未来几年内是否适合我们方案的长期考量。
首要考虑因素是性能。在同等计算资源条件下,由于避免了集群的开销,单机部署表现出色,这也符合官方的推荐。我们可以坚持采用单机部署,直至其无法满足业务需求。
另一重要原因在于单机部署对我们而言具有最低的维护成本。这不仅涵盖了集成维护成本,还涉及应用数据设置以及应用层暴露的维护成本。
我们发现目前的硬件条件已经可以支持很大规模的单机 ClickHouse。例如,现在我们可以在 AWS上 买到 24TB 内存和 488 个 vCPU 的 EC2 实例,这个规模比很多投入部署的 ClickHouse 集群都大,使用最新的硬件技术,硬盘带宽也能达到我们设想的规划容量。
因此,从内存、CPU 和存储带宽等角度考虑,单机 ClickHouse 是一个可行的方案,预计在可预见的未来将继续有效。
当然,ClickHouse 方案亦存在其固有的问题。
首先,当遭遇硬件故障时,ClickHouse 的宕机时间相对较长,这对业务的连续性和稳定性构成了威胁。
其次,数据迁移和备份在 ClickHouse 中至今仍是一项具有挑战性的任务,实现良好的数据备份和迁移方案尚显困难。
在我们部署该项目后,还遇到了一些问题。
首要问题是常规的存储扩展和维护需求,由于数据量迅猛增长,保持合理的磁盘利用率变得尤为重要,每次操作都需要我们投入大量精力。
另一问题则是由磁盘故障引发的一系列连锁反应。ClickHouse 被设计为疯狂使用硬件资源以提供最好的查询性能,它对磁盘的读写操作非常频繁,经常接近最高带宽,这就带来更大的硬盘硬件故障的可能性。当发生硬件故障的时候,根据数据量的大小,故障恢复通常需要几小时到十几小时,我们也在一些使用者中听到了类似的情况。虽然数据分析系统通常被看作是其他系统的数据副本,但这带来的影响还是非常大的。因此,我们必须对可能出现的硬件故障做好充分准备,而数据备份、恢复和迁移等任务也极具挑战性,需要我们投入更多的精力和资源来应对。
03 在 JuiceFS 上运行 ClickHouse
因此,我们萌生了一个思路,即考虑将 ClickHouse 迁移到基于 JuiceFS 的共享存储环境中运行。这篇文章当时给我提供了一些参考:ClickHouse 存算分离架构探索。
为了验证此方案的可行性,我们进行了一系列测试。测试结果显示,在启用缓存的情况下,JuiceFS 的读取性能与本地硬盘的性能接近,与 JuiceFS 博客中展示的结果相似。
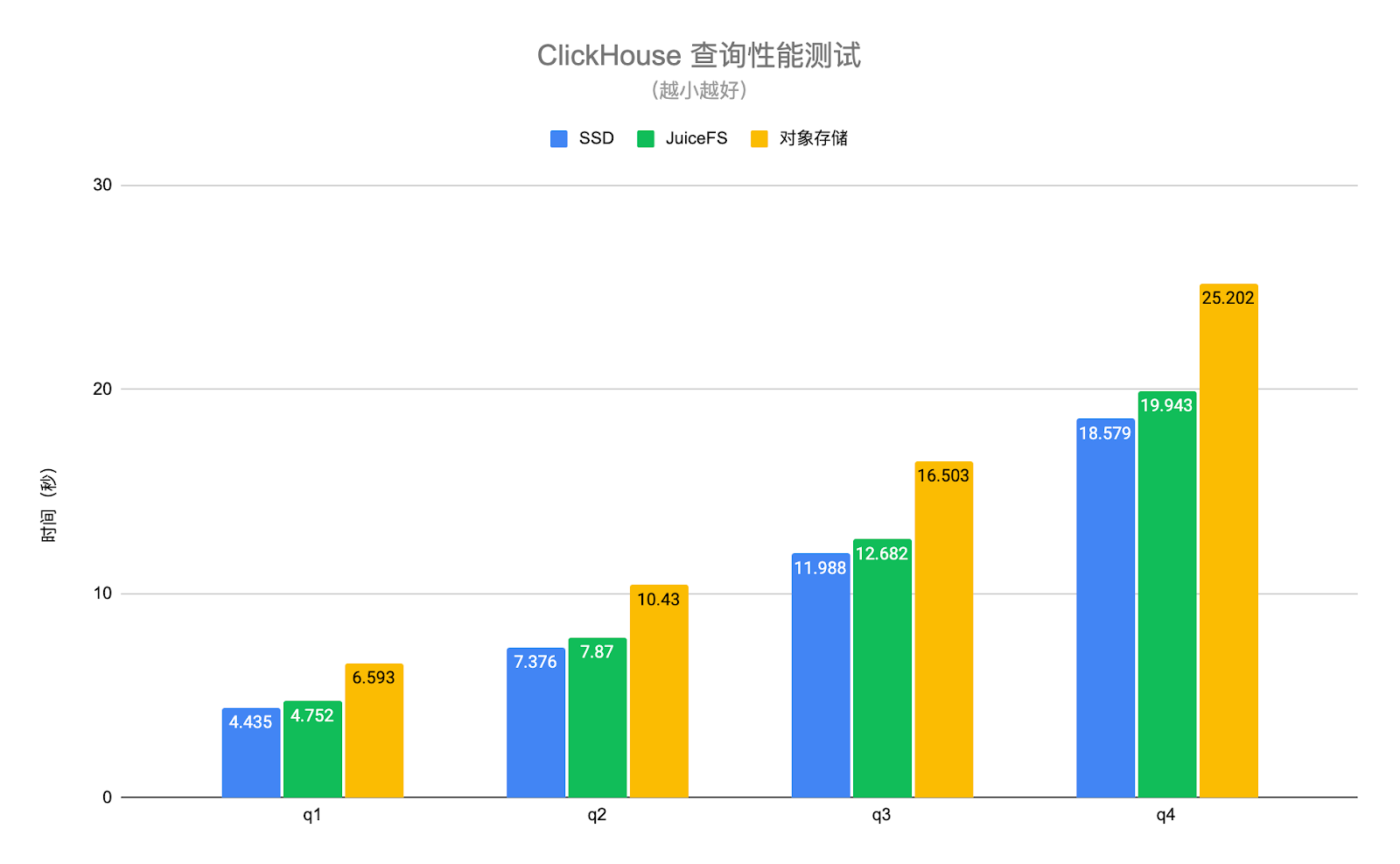
写入性能虽降至写入磁盘速度的 10%至 50% ,但对于我们而言,这是一个可接受的范围。
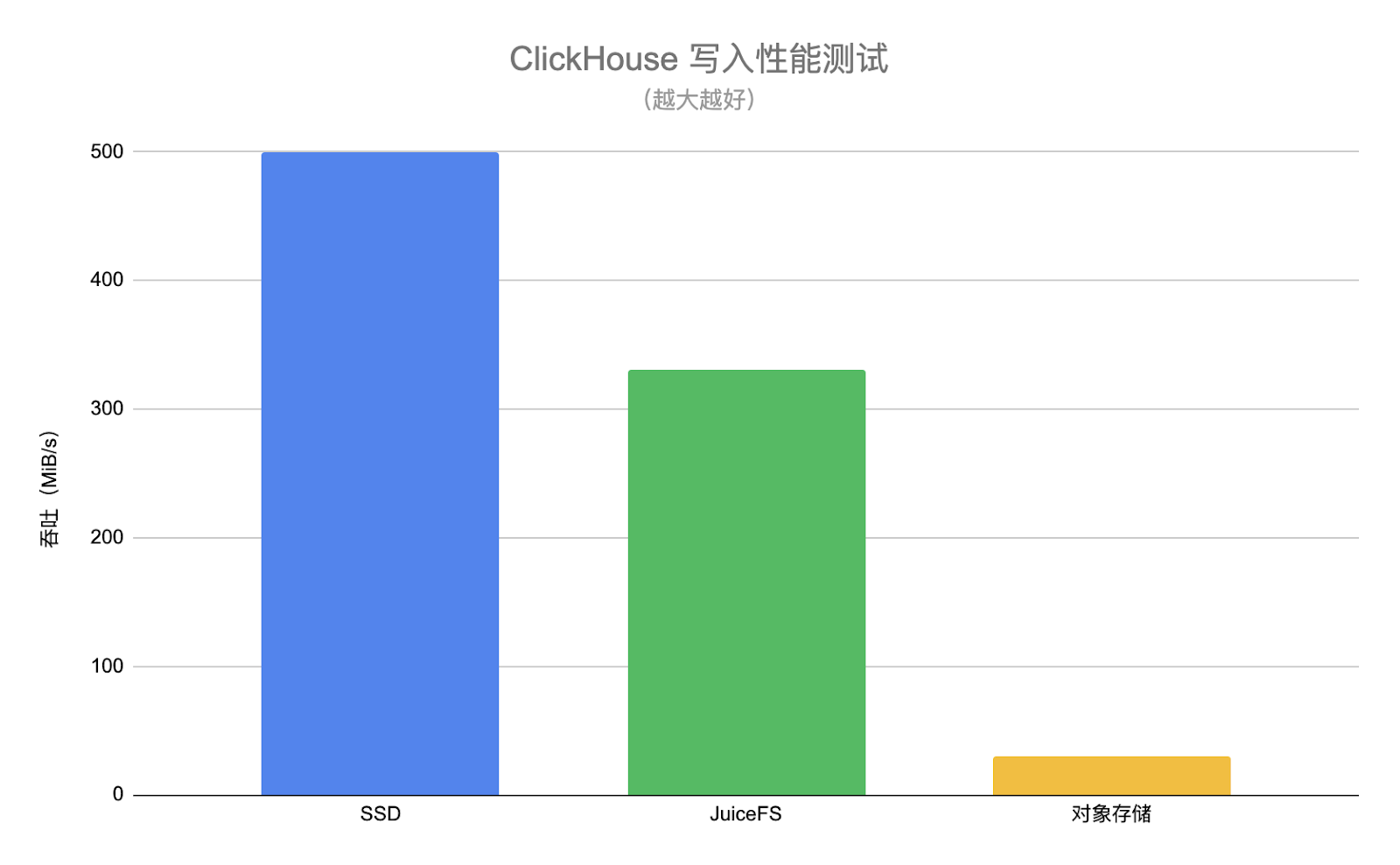
以下是我们对 JuiceFS 挂载进行了针对性的调优操作:
- 首先,我们启用了 writrback 功能,以实现异步写入,从而避免潜在的阻塞问题。
- 其次,在缓存设置方面,我们设定了 attrcacheto 为 3600.0 秒,cache-size 为 2300000,并启用了 metacache 功能。
- 此外,针对 JuiceFS 上 IO 运行时间可能较长于本地磁盘的情况,我们调整了相应策略,引入了 block-interrupt 功能。
最主要的调优目标是提高缓存命中率。由于我们使用的是 JuiceFS 云服务版,我们成功将缓存命中率提升至 95%。若仍需进一步提高,我们将考虑增加硬盘资源。
ClickHouse 结合 JuiceFS 的方案显著减少了运维工作。我们不再需要频繁进行硬盘扩展,而是着重监控缓存命中率,从而大大减轻了扩展硬盘的紧迫性。其次,在硬件故障发生时,我们无需进行数据迁移,这极大地减少了潜在的风险和损失。
JuiceFS 快照(snapshot)功能提供了方便的数据备份与恢复手段,这对我们来说非常有价值。使用快照功能,我可以在未来某个时刻再次运行在数据快照上运行数据库服务,以查看其原始状态,这在文件系统层面上解决了以往需要在应用层面解决的问题。(社区版用户使用克隆功能,实现类似功能,点击此处了解。)
此外,由于无需进行数据迁移,宕机时间得到了大幅减少。我们能够迅速应对故障,或者让自动化系统在另一台机器上挂载目录,确保业务的连续性。值得一提的是,ClickHouse 的启动时间仅需几分钟,这进一步提升了系统的故障恢复速度。
再者,我们的读取性能在迁移后保持稳定,整个公司都未察觉到任何变化,这充分证明了该方案在性能方面的稳定性。
最后,我们的成本也得到了大幅下降。通过将昂贵的云存储产品替换为廉价的对象存储,我们实现了成本的优化,进一步提升了整体效益。
为何要搭建主从架构?
在迁移 ClickHouse 后,我们遇到了如下问题,这些问题最终促使我们考虑构建主从架构。
第一:资源竞争所引发的性能下降。在当前的 ClickHouse 使用方式中,我们把所有的任务都放在了这个架构中,当时 ETL 任务与报表任务之间时常发生冲突,影响了整体性能。
第二:硬件故障导致的宕机问题。对于需要随时查看数据的公司而言,长期的宕机是不可接受的。因此,我们考虑在现有基础上寻找解决方案,从而引出了构建主从架构的构想。
JuiceFS 支持在不同地点挂载多个挂载点。于是我们尝试在其他地方直接挂载 JuiceFS 文件系统,并在相同位置运行 ClickHouse。然而,在实施过程中我们遇到了一些问题。
首先,ClickHouse 通过文件锁机制限制同一份文件只能由一个实例运行,这确实带来了一些挑战。但幸运的是,这个问题相对容易解决,我们只需修改 ClickHouse 的源代码并对其进行锁定即可。
其次,即便在应用过程中仅进行只读操作,ClickHouse 仍会保留一些状态信息,如写入时的缓存。
最后,元数据同步也是一个问题。当 JuiceFS 上运行多个 ClickHouse 实例时,写入实例的部分数据可能无法被其他实例感知,这需要我们重启实例以解决问题。
这当然是不理想的,所以我们决定利用 JuiceFS snapshot 功能来实现主从架构。这个架构的使用方式与常规理解的主从架构并无显著差异。所有的数据更新操作均发生在主实例上,包括数据同步和 ETL 等任务;而从实例则专注于为用户提供查询能力。
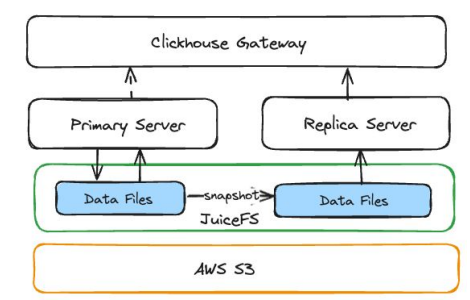
怎样创建 ClickHouse 从实例?
使用 JuiceFS 的快照功能命令:从主实例的 ClickHouse 数据目录创建出一个快照目录,并在此目录上部署一个 ClickHouse 服务。
暂停 Kafka 消费队列:在启动可用于 ClickHouse 的实例之前,必须确保停止对其他数据源的有状态内容的消费。对于我们而言,这意味着暂停 Kafka 消息队列的运行,以避免与主实例竞争 Kafka 数据。
在快照目录上运行 ClickHouse: 启动 ClickHouse 服务后,我们还将注入一些元数据,以向访问者提供关于 ClickHouse 创建时间等信息。
删除 ClickHouse data mutation:在从实例上删除所有的 data mutation,这有助于提升系统性能。
如何进行连续复制:值得注意的是,快照仅保留创建时的状态,为了让“从实例”读到最新的数据,我们定期重新创建副本实例,并替换原有实例。这种方法直观且高效,每个副本实例都从两个副本开始,并有一个指向某个副本的指针。我们可以根据时间间隔或特定条件来重新创建另一个副本,并将指针指向新创建的副本实例,从而无需停机更新。我们设定的最小时间间隔为 10 分钟,通常每小时运行一次即可满足需求。
ClickHouse 的主从架构已稳定运行超过一年,期间完成了超过 2 万次的复制操作而未曾失败,展现了其极高的可靠性。工作负载隔离和数据副本的稳定性是提升性能的关键。我们成功地将整体报表的可用性从不足 95% 提升至 99% ,而且这一提升无需任何应用层面的优化。此外,该架构支持弹性扩展,极大地增加了灵活性,使我们能够根据需求随时开发和部署新的 ClickHouse 服务,而无需额外的复杂操作。
未来展望
我们期望开发一个更为优化的控制界面,以实现自动化实例的生命周期管理、创建操作以及缓存管理功能。
在运行主从架构的过程中,我们观察到主实例在 JuiceFS 上相较于本地硬盘更易发生崩溃现象。尽管大多数情况下可以同步数据,并且同步的数据通常随时可由其他副本访问,但在处理失败时仍需考虑这一特殊情况。尽管我们从概念和原则上对崩溃原因有所了解,但至今仍未完全解决这一问题。简而言之,由于文件系统上的 I/O 系统调用时间较本地硬盘更长,这些异常情况可能会传导至其他组件,进而引发主实例的崩溃。
优化写入性能。主要涉及两个方面。首先,从应用层面来看,由于当前对 Parquet 开放格式的支持已经相当完善,因此,对于大部分负载,我们可以在 ClickHouse 之外将其直接写入 JuiceFS,以便于访问。这样,我们可以采用传统方式实现并行写入,从而提高写入性能。
我们注意到一个新项目 chDB,该项目允许用户在 Python 环境中直接嵌入 ClickHouse 功能,无需 ClickHouse Server。结合 CHDB 和 JuiceFS 我们可以实现完全 serverless 的 ClickHouse。这是一个我们在探索的方向。
04 为什么选择 JuiceFS
第一个原因十分明确,JuiceFS 在当时是我们唯一可选的能在对象存储上运行的 POSIX 文件系统。
第二个原因在于其无限的容量特性。自我们使用以来,基本上无需再为容量问题而担忧。
第三个原因则是其成本优势显著,相较于其他方案,JuiceFS 的成本大幅降低。
第四个令人称道的功能是其强大的快照(snapshot) 能力。它巧妙地将 Git 分支的思维模型引入文件系统层面,并正确、高效地实现了这一模型。当两个不同层面的概念结合得如此完美时,往往能带来极具创意的解决方案,使得之前需要付出巨大努力才能解决的问题变得轻而易举。正如我们之前所面临的主从架构问题,若在其他层面处理,无疑会是一个庞大的项目。
05 JuiceFS 在各场景的应用
数据交换:我们聚焦于 ClickHouse 的应用。利用其访问共享存储的特性进行数据交换,为我们提供了诸多有趣的场景。其中,将 JuiceFS 挂载在 JupyterHub 上尤为引人注目。一些数据科学家将数据输出到特定目录中,这使得在编写报表时,我们可以用这个数据直接对所有 ClickHouse 中的表进行联合查询,极大地优化了整个工作流程。尽管许多工程师认为将数据同步写入并不困难,但长期累积下来,若每日都能省去这一步骤,将极大地减轻心智负担。
机器学习管线:在 JuiceFS 上存储所有机器学习管线所需的数据,包括训练数据等,JuiceFS 为我们打通工作流提供了便捷的途径。通过这种方式,我们可以轻松地将训练时的 notebook 输出放置到指定位置,从而在 JupyterHub 上实现快速访问,使得整个管线流畅无阻。
Kafka + JuiceFS:我们将 Kafka 存储在 JuiceFS 上,尽管我们直接访问 Kafka的应用场景并不多,但考虑到其作为数据资产的长期存储价值,我们仍选择采用这种方式。相较于使用 AWS 相应产品,我们通过这种方式保守估计节省了约 10-20 倍的成本。经过性能测试,我们发现单机性能有所下降,但是这个方案具备良好的水平扩展能力,可以通过添加节点获得我们所需要的吞吐量。该方案的信息延迟相较于本地存储稍大,且存在某些不稳定问题,不适合用在需要实时流处理的场景。
最初,我作为个人用户开始使用 JuiceFS, 在我看来,JuiceFS 的设计优雅、是一个能让开发者的生活变得简单的产品,这一点非常重要。当我在工作中引入 JuiceFS 时,它也总能把事情变得简单。希望这篇文章能给创业型公司,或者大公司里的小型业务,带来有价值的参考。
稳定、省钱的 ClickHouse 读写分离方案:基于 JuiceFS 的主从架构实践的更多相关文章
- SpringBoot数据库读写分离之基于Docker构建主从数据库同步实例
看了好久的SpringBoot结合MyBatista实现读写,但是一直没有勇气实现他,今天终于接触到了读写分离的东西,读写分离就是讲读操作执行在Slave数据库(从数据库),写操作在Master数据库 ...
- mysql 官方读写分离方案
mysql 8.0 集群模式下的自动读写分离方案 问题 多主模式下的组复制,看起来挺好,起始问题和限制很多.而且中断一个复制就无法配置了 多主模式下,innodbcluster 等于是无用的,不需要自 ...
- Oceanbase读写分离方案探索与优化
[作者] 许金柱,携程资深DBA,专注于分布式数据库研究及运维. 台枫,携程高级DBA,主要负责MySQL和OceanBase的运维. [前言] 读写分离,是一种将数据库的查询操作和写入操作分离 ...
- sql server几种读写分离方案的比较
在生产环境中我们经常会遇到这种情况: 前端的oltp业务很繁忙,但是需要对这些运营数据进行olap,为了不影响前端正常业务,所以需要将数据库进行读写分离. 这里我将几种可以用来进行读写分离的方案总结一 ...
- 重新学习Mysql数据13:Mysql主从复制,读写分离,分表分库策略与实践
一.MySQL扩展具体的实现方式 随着业务规模的不断扩大,需要选择合适的方案去应对数据规模的增长,以应对逐渐增长的访问压力和数据量. 关于数据库的扩展主要包括:业务拆分.主从复制.读写分离.数据库分库 ...
- mycat(读写分离、负载均衡、主从切换)
博主本人平和谦逊,热爱学习,读者阅读过程中发现错误的地方,请帮忙指出,感激不尽 1.环境准备 1.1新增两台虚拟机 mycat01:192.168.247.81 mycat02:192.168.247 ...
- MySQL高可用读写分离方案预研
目前公司有需求做MySQL高可用读写分离,网上搜集了不少方案,都不尽人意,下面是我结合现有组件拼凑的实现方案,亲测已满足要求,希望各位多提建议 :) 一. 网上方案整理(搜集地址不详...) 1 ...
- Mysql读写分离方案-Amoeba环境部署记录
Mysql的读写分离可以使用MySQL Proxy,也可以使用Amoeba.Amoeba(变形虫)项目是一个类似MySQL Proxy的分布式数据库中间代理层软件,是由陈思儒开发的一个开源的java项 ...
- Spring+MyBatis实现数据库读写分离方案
推荐第四种:https://github.com/shawntime/shawn-rwdb 方案1 通过MyBatis配置文件创建读写分离两个DataSource,每个SqlSessionFactor ...
- 用mycat做读写分离:基于 MySQL主从复制
版权声明:本文为博主原创文章,未经博主允许不得转载. mycat是最近很火的一款国人发明的分布式数据库中间件,它是基于阿里的cobar的基础上进行开发的 搭建之前我们先要配置MySQL的主从复制,这个 ...
随机推荐
- Python 集合(Sets)3
Python - 合并集合 在 Python 中,有几种方法可以合并两个或多个集合.您可以使用union()方法,该方法返回一个包含两个集合中所有项的新集合,或使用update()方法,将一个集合中的 ...
- 【编译原理】Antlr 入门使用
前面文章我们学习了编译器前端的词法和语法分析工具,本篇我们来看看如何借助 Antlr 工具,快速生成词法和语法分析代码. 一.安装 mac 环境: 1)安装 brew install antlr 2) ...
- MogDB/OpenGauss数据库中通过参数控制抓取慢sql
MogDB/OpenGauss 数据库中通过参数控制抓取慢 sql 本文出处:https://www.modb.pro/db/221556 mogdb 数据库中可以通过打开相应的参数抓取慢 sql,该 ...
- 「译文」深入了解Kubernetes和Nomad
️原文链接: https://www.cncf.io/blog/2023/10/23/introduction-a-closer-look-at-kubernetes-and-nomad/ ✍️作者: ...
- 历时 4 个月,CabloyJS 4.21震撼发布,应对大型项目开发
引言 凡是可以用 JavaScript 来写的应用,最终都会用 JavaScript 来写 | Atwood 定律 目前市面上出现的大多数与 NodeJS 相关的框架,基本都将 NodeJS 定位在工 ...
- 1、android Studio 打Jar包
1.创建一个AndroidStudio 工程 注意下面这个Package Name 2.进入Android Studio工程中 选择Project Flies 选项 然后找到 app->src- ...
- Gin
0x01 准备 (1)概述 定义:一个 golang 的微框架 特点:封装优雅,API 友好,源码注释明确,快速灵活,容错方便 优势: 对于 golang 而言,web 框架的依赖要远比 Python ...
- mysql 重新整理——索引优化explain字段介绍一 [九]
前言 在七种介绍了explain这东西,那么具体来看下它是如何来运行的吧. 正文 id 来看一条语句:EXPLAIN select * from departments,dept_emp,employ ...
- ORA-29278: SMTP transient error: 421 Service not available
ORA-29278: SMTP transient error: 421 Service not available 一般来说,很可能是邮件服务器连接不上 p_conn := utl_smtp.ope ...
- 阿里云张新涛:连接产业上下游,构建XR协作生态
简介: 用交互技术辅以澎湃的算力带给大家最真实的"沉浸式体验" 2022年9月2日,在世界人工智能大会"区块新生 数字宇宙--元宇宙技术与生态合作"分论坛上,阿 ...