pandas -- DataFrame的级联以及合并操作
开发环境
- anaconda
- 集成环境:集成好了数据分析和机器学习中所需要的全部环境
- 安装目录不可以有中文和特殊符号
- jupyter
- anaconda提供的一个基于浏览器的可视化开发工具
import pandas as pd
import numpy as np
级联操作 -- 对应表格
- pd.concat
- pd.append
- pandas使用pd.concat函数,与np.concatenate函数类似,只是多了一些参数:
- objs
- axis=0
- keys
- join='outer' / 'inner':表示的是级联的方式,outer会将所有的项进行级联(忽略匹配和不匹配),而inner只会将匹配的项级联到一起,不匹配的不级联
- ignore_index=False
匹配级联
df1 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','B','C'])
df2 = pd.DataFrame(data=np.random.randint(0,100,size=(5,3)),columns=['A','D','C'])
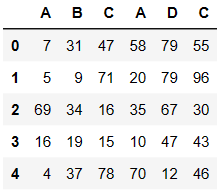
pd.concat((df1,df2),axis=1) # 行列索引都一致的级联叫做匹配级联
不匹配级联
- 不匹配指的是级联的维度的索引不一致。例如纵向级联时列索引不一致,横向级联时行索引不一致
- 有2种连接方式:
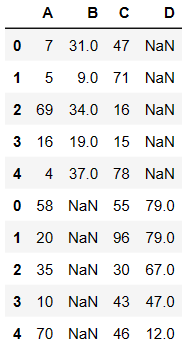
- 外连接:补NaN(默认模式)
- 内连接:只连接匹配的项
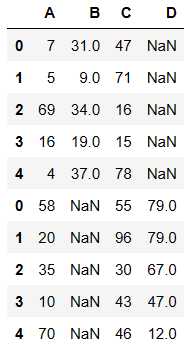
pd.concat((df1,df2),axis=0)
内连接
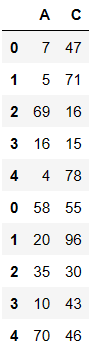
pd.concat((df1,df2),axis=0,join='inner') # inner直把可以级联的级联不能级联不处理
外连接
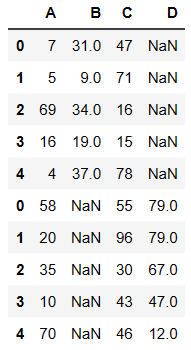
- 如果想要保留数据的完整性必须使用 outer(外连接)
pd.concat((df1,df2),axis=0,join='outer')
- append函数的使用
df1.append(df2)
合并操作 -- 对应数据
- merge与concat的区别在于,merge需要依据某一共同列来进行合并
- 使用pd.merge()合并时,会自动根据两者相同column名称的那一列,作为key来进行合并。
- 注意每一列元素的顺序不要求一致
一对一合并
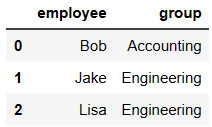
from pandas import DataFrame
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering'],
})
df1
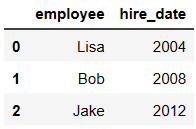
df2 = DataFrame({'employee':['Lisa','Bob','Jake'],
'hire_date':[2004,2008,2012],
})
df2
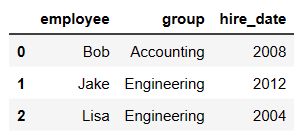
pd.merge(df1,df2,on='employee')
一对多合并
df3 = DataFrame({
'employee':['Lisa','Jake'],
'group':['Accounting','Engineering'],
'hire_date':[2004,2016]})
df3
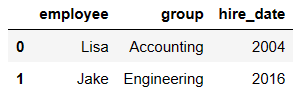
df4 = DataFrame({'group':['Accounting','Engineering','Engineering'],
'supervisor':['Carly','Guido','Steve']
})
df4
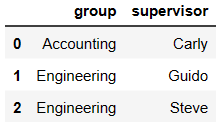
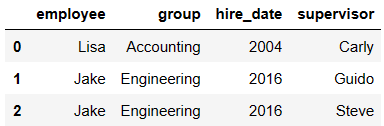
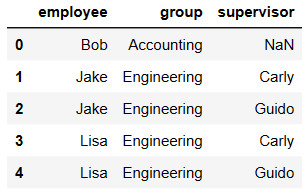
pd.merge(df3,df4) # on如果不写,默认情况下使用两表中公有的列作为合并条件
多对多合并
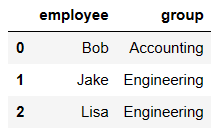
df1 = DataFrame({'employee':['Bob','Jake','Lisa'],
'group':['Accounting','Engineering','Engineering']})
df1
df5 = DataFrame({'group':['Engineering','Engineering','HR'],
'supervisor':['Carly','Guido','Steve']
})
df5
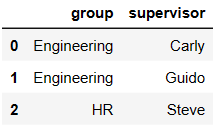
pd.merge(df1,df5,how='right')
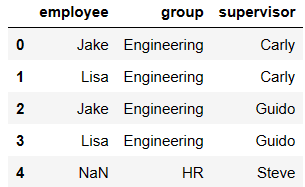
pd.merge(df1,df5,how='left')
key的规范化
- 当两张表没有可进行连接的列时,可使用left_on和right_on手动指定merge中左右两边的哪一列列作为连接的列
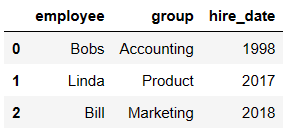
df1 = DataFrame({'employee':['Bobs','Linda','Bill'],
'group':['Accounting','Product','Marketing'],
'hire_date':[1998,2017,2018]})
df1
df5 = DataFrame({'name':['Lisa','Bobs','Bill'],
'hire_dates':[1998,2016,2007]})
df5
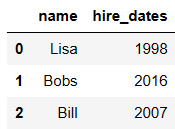
pd.merge(df1,df5,left_on='employee',right_on='name')
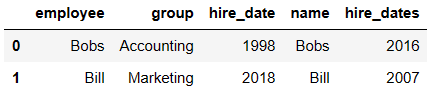
内合并与外合并
- outer取并集
- inner取交集
df6 = DataFrame({'name':['Peter','Paul','Mary'],
'food':['fish','beans','bread']}
)
df7 = DataFrame({'name':['Mary','Joseph'],
'drink':['wine','beer']})
df6
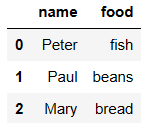
df7

pd.merge(df6,df7,how='outer')
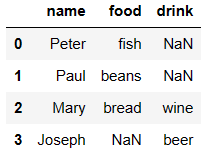
df6 = DataFrame({'name':['Peter','Paul','Mary'],
'food':['fish','beans','bread']}
)
df7 = DataFrame({'name':['Mary','Joseph'],
'drink':['wine','beer']})
df6
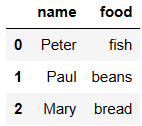
df7

pd.merge(df6,df7,how='inner')

pandas -- DataFrame的级联以及合并操作的更多相关文章
- 数据分析03 /基于pandas的数据清洗、级联、合并
数据分析03 /基于pandas的数据清洗.级联.合并 目录 数据分析03 /基于pandas的数据清洗.级联.合并 1. 处理丢失的数据 2. pandas处理空值操作 3. 数据清洗案例 4. 处 ...
- pandas DataFrame的查询方法(loc,iloc,at,iat,ix的用法和区别)
pandas DataFrame的增删查改总结系列文章: pandas DaFrame的创建方法 pandas DataFrame的查询方法 pandas DataFrame行或列的删除方法 pand ...
- pandas 学习 第7篇:DataFrame - 数据处理(应用、操作索引、重命名、合并)
DataFrame的这些操作和Series很相似,这里简单介绍一下. 一,应用和应用映射 apply()函数对每个轴应用一个函数,applymap()函数对每个元素应用一个函数: DataFrame. ...
- Pandas | Dataframe的merge操作,像数据库一样尽情join
今天是pandas数据处理第8篇文章,我们一起来聊聊dataframe的合并. 常见的数据合并操作主要有两种,第一种是我们新生成了新的特征,想要把它和旧的特征合并在一起.第二种是我们新获取了一份数据集 ...
- pandas之合并操作
Pandas 提供的 merge() 函数能够进行高效的合并操作,这与 SQL 关系型数据库的 MERGE 用法非常相似.从字面意思上不难理解,merge 翻译为"合并",指的是将 ...
- pandas DataFrame 数据处理常用操作
Xgboost调参: https://wuhuhu800.github.io/2018/02/28/XGboost_param_share/ https://blog.csdn.net/hx2017/ ...
- Python pandas DataFrame操作
1. 从字典创建Dataframe >>> import pandas as pd >>> dict1 = {'col1':[1,2,5,7],'col2':['a ...
- Python时间处理,datetime中的strftime/strptime+pandas.DataFrame.pivot_table(像groupby之类 的操作)
python中datetime模块非常好用,提供了日期格式和字符串格式相互转化的函数strftime/strptime 1.由日期格式转化为字符串格式的函数为: datetime.datetime.s ...
- pandas.DataFrame的pivot()和unstack()实现行转列
示例: 有如下表需要进行行转列: 代码如下: # -*- coding:utf-8 -*- import pandas as pd import MySQLdb from warnings impor ...
- 如何迭代pandas dataframe的行
from:https://blog.csdn.net/tanzuozhev/article/details/76713387 How to iterate over rows in a DataFra ...
随机推荐
- php发起支付加密数据供获取订单状态使用
<?php//作者主页: https://www.bz80.comnamespace Index\Controller; class PayController extends BaseCont ...
- 国标GB28181协议客户端开发(四)实时视频数据传输
国标GB28181协议客户端开发(四)实时视频数据传输 本文是<国标GB28181协议设备端开发>系列的第四篇,介绍了实时视频数据传输的过程.通过解读INVITE报文中的SDP信息,读取和 ...
- 与 AI 同行,利用 ChatGLM 构建知识图谱
大家好,我是东方财富的一名算法工程师,这里分享一些利用大模型赋能知识图谱建设的一些实践. 为什么知识图谱需要大模型 在金融场景中,天然会有大量结构化的数据需要投入大量的人力去生产和维护,而这样的数据又 ...
- Ubuntu DC + Samba4 AD 实现双域控主机模
文章将讲解如何使用 Ubuntu 16.04 服务器版系统来创建第二台 Samba4 域控制器,并将其加入到已创建好的 Samba AD DC 林环境中,以便为一些关键的 AD DC 服务提供负载均衡 ...
- .Net FrameWork下面如何生成AOT呢?
前言 其实AOT预编译,在.Net FrameWorker1.0里面就有了.它叫做Ngen,只不过当时叫做生成本机映像,实际上还是一个东西,也就是预编译.本篇来看下. 概括 1.介绍 现在的现代化的. ...
- 【Python】从同步到异步多核:测试桩性能优化,加速应用的开发和验证
测试工作中常用到的测试桩mock能力 在我们的测试工作过程中,可能会遇到多个项目并行开发的时候,后端服务还没有开发完成,或者我们需要压测某个服务,这个服务测在试环境的依赖组件(如 MQ) 无法支撑我们 ...
- IoTOS-v1.5.3 新增 智能诊断&会话记录导出
IoTOS v1.5.3 一.新增智能诊断 智能诊断功能: 智能诊断会根据不同上游接口能力开放提供接近官方甚至比官方更加完善的智能诊断功能. 目前还原OneLink官方智能诊断功能包括动效.诊断建议等 ...
- 正确处理 CSV 文件的引号和逗号
CSV(Comma-Separated Values,逗号分割值),就是用纯文本的形式存储表格数据,最大的特点就是方便. 作为开发,我们经常面临导数据的问题,特别是后台系统,产品或者运营的同事常常会提 ...
- Python数据分析易错知识点归纳(二):Numpy
二.numpy 不带括号的基本属性 arr.dtype arr.shape # 返回元组 arr.size arr.ndim # 维度 arr.reshape/arr.resize/np.resize ...
- 并发编程-FutureTask解析
1.FutureTask对象介绍 Future对象大家都不陌生,是JDK1.5提供的接口,是用来以阻塞的方式获取线程异步执行完的结果. 在Java中想要通过线程执行一个任务,离不开Runnable与C ...