JAVAAPI实现血缘关系Rest推送到DataHub V0.12.1版本
DataHub 更青睐于PythonAPI对血缘与元数据操作
虽然开源源码都有Java示例和Python示例:但是这个API示例数量简直是1:100的差距!!不知为何,项目使用Java编写,示例推送偏爱Python的官方;;;搞不懂也许就是开源官方团队写脚本的是Python一哥吧!
显然DataHub 更青睐于Python API对血缘与元数据操作
Java示例:屈指可数
Python示例 就是海量丰富了
目前Java示例就两个好用:
DatasetAdd.java 和 DataJobLineageAdd.java
(一)DatasetAdd.java 是设置元数据到Datahub
private static void extractedTable() {
String token = "";
try (RestEmitter emitter =
RestEmitter.create(b -> b.server("http://10.130.1.49:8080").token(token))) {
MetadataChangeProposal dataJobIOPatch =
new DataJobInputOutputPatchBuilder()
.urn(
UrnUtils.getUrn(
"urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_456)")) //这个是使用的JOB输入表级:中转处理任务
.addInputDatasetEdge(
DatasetUrn.createFromString(
"urn:li:dataset:(urn:li:dataPlatform:mysql,JDK-Name,PROD)")) //这个是使用的JOB输入表级:入口节点
.addOutputDatasetEdge(
DatasetUrn.createFromString(
"urn:li:dataset:(urn:li:dataPlatform:hive,JDK-Name,PROD)")) //这个是使用的JOB输入表级:出口节点
.addInputDatajobEdge(
DataJobUrn.createFromString(
"urn:li:dataJob:(urn:li:dataFlow:(airflow,dag_abc,PROD),task_123)")) // 这里定义字段列级别的血缘关系:中转处理任务
.addInputDatasetField(
UrnUtils.getUrn(
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:hive,JDK-Name,PROD),userName)")) // 列字段的入口节点
.addOutputDatasetField(
UrnUtils.getUrn(
"urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:mysql,JDK-Name,PROD),userName)")) // 列字段的出口节点
.build();
Future<MetadataWriteResponse> response = emitter.emit(dataJobIOPatch);
System.out.println(response.get().getResponseContent());
} catch (Exception e) {
e.printStackTrace();
System.out.println("Failed to emit metadata to DataHub"+ e.getMessage());
throw new RuntimeException(e);
}
}
(二)DataJobLineageAdd.java 是设置元数据带JOB任务的血缘到Datahub
public static void main(String[] args)
throws IOException, ExecutionException, InterruptedException {
// Create a DatasetUrn object from a string
DatasetUrn datasetUrn = UrnUtils.toDatasetUrn("hive", "JDK-Mysql", "PROD");
// Create a CorpuserUrn object from a string
CorpuserUrn userUrn = new CorpuserUrn("ingestion");
// Create an AuditStamp object with the current time and the userUrn
AuditStamp lastModified = new AuditStamp().setTime(1640692800000L).setActor(userUrn);
// Create a SchemaMetadata object with the necessary parameters
SchemaMetadata schemaMetadata =
new SchemaMetadata()
.setSchemaName("customer")
.setPlatform(new DataPlatformUrn("hive"))
.setVersion(0L)
.setHash("")
.setPlatformSchema(
SchemaMetadata.PlatformSchema.create(
new OtherSchema().setRawSchema("__RawSchemaJDK__")))
.setLastModified(lastModified);
// Create a SchemaFieldArray object
SchemaFieldArray fields = new SchemaFieldArray();
// Create a SchemaField object with the necessary parameters
SchemaField field1 =
new SchemaField()
.setFieldPath("mysqlId")
.setType(
new SchemaFieldDataType()
.setType(SchemaFieldDataType.Type.create(new StringType())))
.setNativeDataType("VARCHAR(50)")
.setDescription(
"Java用户mysqlId名称VARCHAR")
.setLastModified(lastModified);
fields.add(field1);
SchemaField field2 =
new SchemaField()
.setFieldPath("PassWord")
.setType(
new SchemaFieldDataType()
.setType(SchemaFieldDataType.Type.create(new StringType())))
.setNativeDataType("VARCHAR(100)")
.setDescription("Java用户密码VARCHAR")
.setLastModified(lastModified);
fields.add(field2);
SchemaField field3 =
new SchemaField()
.setFieldPath("CreateTime")
.setType(
new SchemaFieldDataType().setType(SchemaFieldDataType.Type.create(new DateType())))
.setNativeDataType("Date")
.setDescription("Java用户创建时间Date")
.setLastModified(lastModified);
fields.add(field3);
// Set the fields of the SchemaMetadata object to the SchemaFieldArray
schemaMetadata.setFields(fields);
// Create a MetadataChangeProposalWrapper object with the necessary parameters
MetadataChangeProposalWrapper mcpw =
MetadataChangeProposalWrapper.builder()
.entityType("dataset")
.entityUrn(datasetUrn)
.upsert()
.aspect(schemaMetadata)
.build();
// Create a token
String token = "";
// Create a RestEmitter object with the necessary parameters
RestEmitter emitter = RestEmitter.create(b -> b.server("http://10.130.1.49:8080").token(token));
// Emit the MetadataChangeProposalWrapper object
Future<MetadataWriteResponse> response = emitter.emit(mcpw, null);
// Print the response content
System.out.println(response.get().getResponseContent());
emitter.close();
}
我们大多数时候不是需要带JOb的血缘关系
例如: 直接是表与表之间有关系
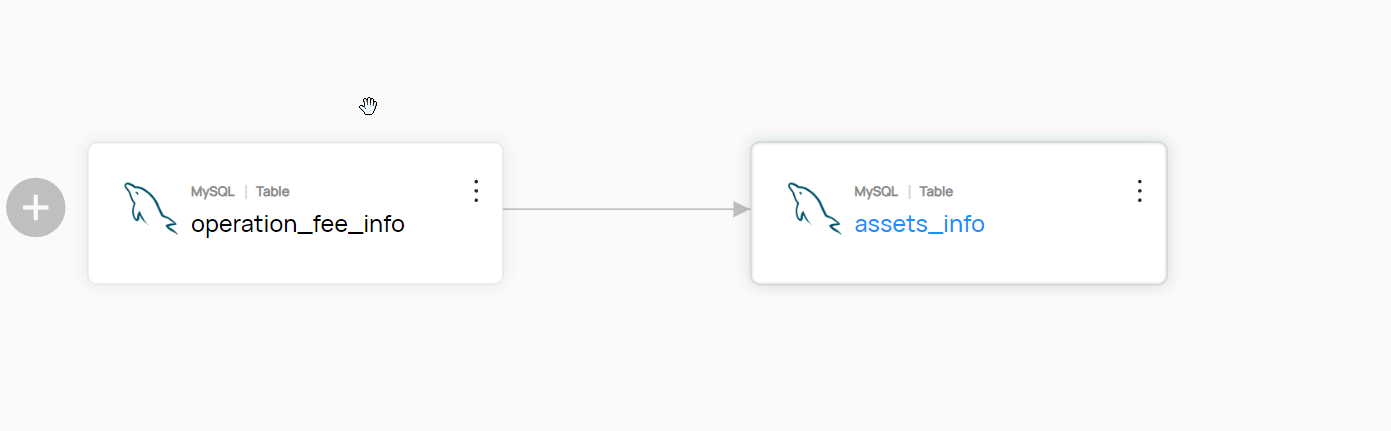
python脚本这里不赘述:太多示例了。重点是Java这边怎么实现这个东西
参考DataJobLineageAdd示例:他这里核心分析
(1.1) 就是把血缘关系提交到Datahub
代码====>
Future<MetadataWriteResponse> response = emitter.emit(dataJobIOPatch);
System.out.println(response.get().getResponseContent());
分析====>
emitter.emit(?) 这个方法就是提交血缘关系;
里面填充好的就是血缘关系数据吧:示例是dataJobIOPatch 就是携带JOB的血缘关系数据; 因为他初始化变量的时候就是DataJobInputOutputPatchBuilder构建的,见名知意就是JOb相关的
MetadataChangeProposal dataJobIOPatch =
new DataJobInputOutputPatchBuilder()......
所以我们是否是MetadataChangeProposal的实现替换为别的方式:找找源码
类比思想:看看同样的builder实现的地方有别的实现没有

挑出了看着很像的实现:猜一下肯定是和JOB没关系了,而且是直接操作元数据的关系的
DatasetPropertiesPatchBuilder
EditableSchemaMetadataPatchBuilder
UpstreamLineagePatchBuilder
SO 简单改造一下 取名为:DataSetLineageAdd
@Slf4j
class DataSetLineageAdd {
private DataSetLineageAdd() {}
/**
* Adds lineage to an existing DataJob without affecting any lineage
*
* @param args
* @throws IOException
* @throws ExecutionException
* @throws InterruptedException
*/
public static void main(String[] args)
throws IOException, ExecutionException, InterruptedException {
extractedTable();
}
private static void extractedRow() {
// 没有java版本。。。。
}
private static void extractedTable() {
String token = "";
try (RestEmitter emitter =
RestEmitter.create(b -> b.server("http://10.130.1.49:8080").token(token))) {
MetadataChangeProposal mcp =
new UpstreamLineagePatchBuilder().
urn(UrnUtils.getUrn("urn:li:dataset:(urn:li:dataPlatform:mysql,ctmop.assets_info,PROD)"))
.addUpstream(DatasetUrn.createFromString(
"urn:li:dataset:(urn:li:dataPlatform:mysql,ctmop.operation_fee_info,PROD)"), DatasetLineageType.TRANSFORMED)
.build();
Future<MetadataWriteResponse> response = emitter.emit(mcp);
System.out.println(response.get().getResponseContent());
} catch (Exception e) {
e.printStackTrace();
System.out.println("Failed to emit metadata to DataHub"+ e.getMessage());
throw new RuntimeException(e);
}
}
}
表级血缘用JAVA代码就实现了;这是一个简单的Demo;更深入的拓展需要自行挖掘!!!

有人说表级血缘太low了,能不能做到JAVA的字段级血缘关系呢。。。。当然没问题
看我示例用的这个:UpstreamLineagePatchBuilder 他意思没有指定表级还是字段级;API 方法 addUpstream 和 urn都是泛用型,理论上都OK
分析:
表级的元数据: urn:li:dataset:(urn:li:dataPlatform:mysql,ctmop.assets_info,PROD) 这个样子
列级的元数据: urn:li:schemaField:(urn:li:dataset:(urn:li:dataPlatform:mysql,JDK-Name,PROD),userName) 这个样子
发现规律了:表级外面包一层urn:li:schemaField:XXXX,字段名 那不就是列字段了,。。。。。浅谈捯饬结束!!!
有问题还望大家指正:!!!
JAVAAPI实现血缘关系Rest推送到DataHub V0.12.1版本的更多相关文章
- 如何删除远端已经推送的Commit记录???(Git版本回退)
如何删除远端已经推送的Commit记录???(Git版本回退) 简单描述 突然事件:刚刚,就在刚刚,发生误了操作. 操作描述:我把修改的文件保存错分支了,已经commit了.并且还push上去了.对, ...
- 极光推送Jpush(v3)服务端PHP版本的api脚本类
原文地址:http://www.dodobook.net/php/780 关于极光推送的上一篇文章已经说明了,此处就不多说了.使用v3版本的原因是v2使用到2014年年底就停止了.点击查看上一篇的地址 ...
- 极光推送Jpush(v3)服务端PHP版本集成(V3版本只调用推送API)
因为版本升级,极光推送的API也有了V3,功能也更丰富了,但是对于我们有的用户来说,我们还是只需要调用推送的API就够了. 下载了一份PHP服务端的SDK(下载地址:http://docs.jpush ...
- app后端设计(3)--短信,邮件,推送服务(2014.12.05更新)
在app的后端设计中,免不了消息的推送,短信,邮件等服务,下面就个人的开发经验谈谈这方面. (1)最重要的是,各种推送一定要放在队列系统中处理,不然会严重影响api的响应时间. (2)短信方面 以前我 ...
- Nginx 学习笔记(十)介绍HTTP / 2服务器推送(译)
原文地址:https://www.nginx.com/blog/nginx-1-13-9-http2-server-push/ 我们很高兴地宣布,2018年2月20日发布的NGINX 1.13.9支持 ...
- 魅族推送 简介 集成 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- iOS推送(利用极光推送)
本文主要是基于极光推送的SDK封装的一个快速集成极光推送的类的封装(不喜勿喷) (1)首先说一下推送的一些原理: Push的原理: Push 的工作机制可以简单的概括为下图 图中,Provider是指 ...
- iOS开发 iOS10推送必看
iOS10更新之后,推送也是做了一些小小的修改,下面我就给大家仔细说说.希望看完我的这篇文章,对大家有所帮助. 一.简单入门篇---看完就可以简单适配完了 相对简单的推送证书以及环境的问题,我就不在这 ...
- Git 直接推送到生产服务器
假设路径为/project/path/ 设定git仓库可以直接被远程推送(需要较新的git版本,比如2.7) cd /project/path git config receive.denyCurre ...
- 将本地项目推送至gitee或者github
将本地项目推送到Git github上的版本和本地版本冲突的解决方法 初始化项目时,在git中新建项目. 在Github中创建了一个Repository之后,会给你列出如何将自己本地项目Push到Gi ...
随机推荐
- Solution -「BZOJ 3771」Triple
Description Link. 给你一个序列,你每次可以取 \(1\sim3\) 个数然后计算和,问你对于每一种和,方案数是多少. Solution 设一个 OGF \(A(x)=\sum_{i= ...
- Solution Set -「ARC 113」
「ARC 113A」A*B*C Link. 就是算 \(\sum_{i=1}^{k}\sum_{j=1}^{\lfloor\frac{k}{i}\rfloor}\lfloor\frac{k}{j\ti ...
- 2023版:深度比较几种.NET Excel导出库的性能差异
引言 背景和目的 本文介绍了几个常用的电子表格处理库,包括EPPlus.NPOI.Aspose.Cells和DocumentFormat.OpenXml,我们将对这些库进行性能测评,以便为开发人员提供 ...
- md5sum 文件一致性校验
1. 背景 在网络传输.设备之间转存.复制大文件等时,可能会出现传输前后数据不一致的情况.这种情况在网络这种相对更不稳定的环境中,容易出现.那么校验文件的完整性,也是势在必行的. md5sum命令用于 ...
- Oracle 高可用 阅读笔记
1 个人理解概述 1.1 Oracle dg Oracle Data Guard通过从主数据库传输redo data,然后将apply redo到备用数据库,自动维护每个备用数据库.DG分为3个 ...
- 算法修养--广度优先搜索BFS
广度优先算法(BFS) 广度优先算法(Breadth-First Search)是在图和树领域的搜索方法,其核心思想是从一个起始点开始,访问其所有的临近节点,然后再按照相同的方式访问这些临近节点的节点 ...
- C# WebBrowser document.execCommand()解析
// // Summary: // 对文档执行指定的命令. // // Parameters: ...
- http1.x,http2.0,https分别介绍以及他们的区别
一.HTTP/1.x Http1.x 缺陷:线程阻塞,在同一时间,同一域名的请求有一定数量限制,超过限制数目的请求会被阻塞 http1.0 缺陷:浏览器与服务器只保持短暂的连接,浏览器的每次请求都需要 ...
- Apollo 配置中心的部署与使用经验
前言 Apollo(阿波罗)是携程开源的分布式配置管理中心. 本文主要介绍其基于 Docker-Compose 的部署安装和一些使用的经验 特点 成熟,稳定 支持管理多环境/多集群/多命名空间的配置 ...
- XML文件的解析--libxml库函数解释
[c语言]XML文件的解析--libxml库函数解释 2009-09-02 13:12 XML文件的解析--libxml库函数解释 libxml(一) ...