TCP和KCP协议
TCP协议
KCP是一个快速可靠协议,能以比 TCP 浪费 10%-20% 的带宽的代价,换取平均延迟降低 30%-40%,且最大延迟降低三倍的传输效果。纯算法实现,并不负责底层协议(如UDP)的收发,需要使用者自己定义下层数据包的发送方式,以 callback的方式提供给 KCP。 连时钟都需要外部传递进来,内部不会有任何一次系统调用。
TCP 是为流量设计的(每秒钟多少 KB),KCP 是为流速设计的(RTT 时延多少毫秒)。KCP 参考 TCP 做了一些优化, 牺牲了带宽, 以换取更低的时延, 设计上大部分是通用的, 所以这里先介绍 TCP 协议的原理.
假设你已经了解 TCP/IP 的基本概念, UDP 和 TCP 都属于第四层传输层, 完成了进程到另一个进程通信的最后一步, 我们看看 TCP 的协议报
TCP 的协议报
5层网络依次是: 物理层, 链路层, 网络层, 传输层, 应用层
网络上的包都是完整的, 有了上层必须有下层, 所以下面也贴一下第二层链路层和第三层网络层的协议报
第二层链路层的协议报
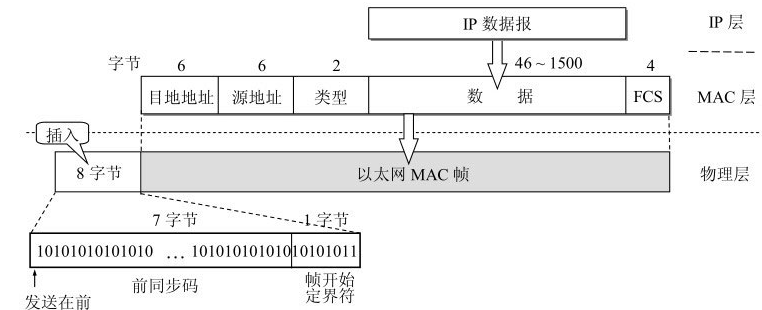
MAC 以 帧 为单位, 包含协议报(18字节), 数据(46-1500字节)
协议报包含了源 MAC 地址(6字节), 目标 MAC 地址(6字节), 以太网类型(2字节), 循环冗余校验码(4字节)
- 以太网类型: 0x0800 表示 IP 协议, 0x0806 表示 ARP 协议, 0x8035 表示 RARP 协议
第三层网络层的协议报
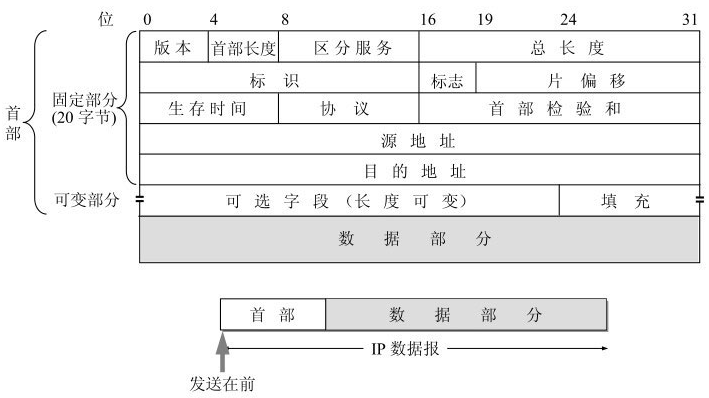
IP 层提供主机到主机之间的通信, 以 包 为单位, 包含协议报(20-60字节), 数据(0-65535 字节)
协议报包含了版本(4位), 首部长度(4位), 服务类型(8位), 总长度(16位), 标识(16位), 标志(3位), 片偏移(13位), 生存时间(8位), 协议(8位), 首部校验和(16位), 源 IP 地址(32位), 目标 IP 地址(32位), 选项(0-40字节)
- 版本: 4位, 4 表示 IPv4, 6 表示 IPv6
- 首部长度: 4位, 表示首部/协议报的长度, 以 32 位(4字节)为单位, 也就是说, 首部的长度最小是 5 个 32 位, 最大是 15 个 32 位, 也就是说, 最小是 20 字节, 最大是 60 字节
- 服务类型/区分服务: 8位, 用来标识服务的类型, 一般不用, 只有在区分服务时候这个字段才有用
- 总长度: 16位, 表示整个包的长度, 以字节为单位, 最小是 20 字节(只包含协议报), 最大是 65535 字节
- 标识: 16位, IP软件在存储器中维持一个计数器,每产生一个数据报,计数器就加1,并将此值赋给标识字段。但这个“标识”并不是序号,因为IP是无连接服务,数据报不存在按序接收的问题。当数据报由于长度超过网络的MTU而必须分片时,这个标识字段的值就被复制到所有的数据报片的标识字段中。相同的标识字段的值使分片后的各数据报片最后能正确地重装成为原来的数据报
- 标志: 3位, 最低位表示是否分片, 0 表示不分片, 1 表示分片, 中间位表示是否是最后一个分片, 0 表示不是, 1 表示是, 最高位保留, 一般为 0
- 片偏移: 片偏移 占13位。片偏移指出:较长的分组在分片后,某片在原分组中的相对位置。也就是说,相对于用户数据字段的起点,该片从何处开始。片偏移以8个字节为偏移单位。这就是说,每个分片的长度一定是8字节(64位)的整数倍。
- 生存时间: 占8位,生存时间字段常用的英文缩写是TTL (Time To Live),表明是数据报在网络中的寿命。由发出数据报的源点设置这个字段。其目的是防止无法交付的数据报无限制地在因特网中兜圈子(例如从路由器R1转发到R2,再转发到R3,然后又转发到R1),因而白白消耗网络资源。最初的设计是以秒作为TTL值的单位。每经过一个路由器时,就把TTL减去数据报在路由器所消耗掉的一段时间。若数据报在路由器消耗的时间小于1秒,就把TTL值减1。当TTL值减为零时,就丢弃这个数据报.
- 协议: 8位, 表示下一层协议的类型,例如:

注意这里的 IP 指的是再次将 IP 报封装到 IP 报中
- 校验和: 16位, 用来检验 IP 报头的正确性, 由发送方计算, 接收方检验
- 源地址: 32位, 表示发送方的 IP 地址
- 目的地址: 32位, 表示接收方的 IP 地址
- 选项: 可选, 用来扩展 IP 报文, 一般不使用
第四层TCP协议报
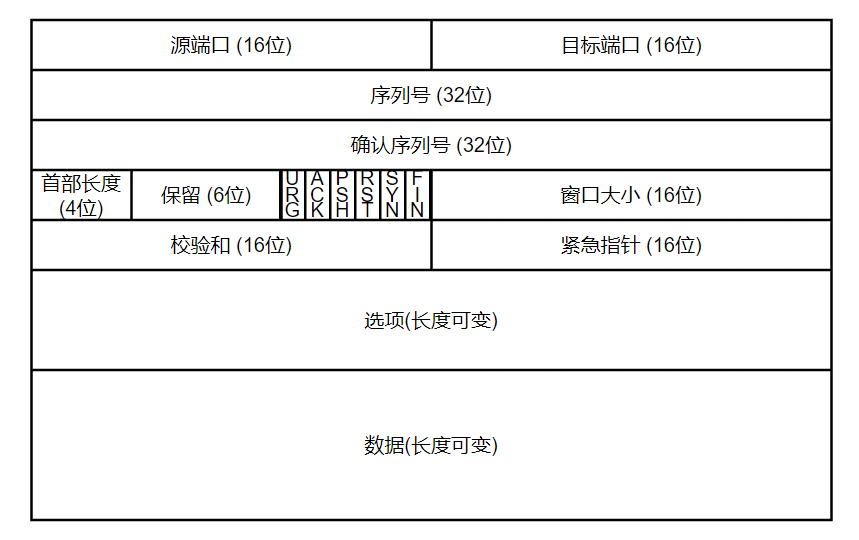
TCP 提供端到端的通信, 是进程之间通信的最后一步, 以 段 为单位, 包含协议报(20-60字节), 数据(0-65535字节)
- 源端口: 16位, 表示发送方的端口号
- 目的端口: 16位, 表示接收方的端口号
- 序列号: 32位, 表示发送方发送的数据的第一个字节的序号
- 确认号: 32位, 表示接收方期望收到的下一个字节的序号
- 部首长度: 4位, 表示 TCP 报头的长度, 一般为 5, 也就是 20 字节
- 保留: 6位, 保留, 一般为 0
- 标志位: 6位, 用来标识 TCP 报文的各种状态, 例如: SYN, ACK, FIN 等
- URG(Urgent) 紧急标志, 表示紧急指针 (16位) 生效 (比如远程ssh的Ctl+C中断命令), 发送端不再按顺序发送, 优先发送和后面的紧急指针配合的紧急数据, 接收端优先接受, 不等待 buffer 满, 读取 start=序列号, offset=紧急指针的数据
- ACK (Acknowledge) 确认标志, 确认序列号 (32位) 生效
- PUSH 推送标志, 起到催促作用, 发送端不再按顺序发送, 优先创建 PUSH 报文, 接收端不等待 buffer 满, 读取整个 buffer + 新报文的数据
- RST (Reset) 重置, 表示需要退出或者重新连接
- SYN (Synchronization) 同步 (3 次握手的 SYN 包)
- FIN (Finish) 结束 (4次挥手的 FIN 包)
- 窗口大小: 16位, 接受方 ACK 发送自己的接受窗口大小, 用来控制发送方的发送速率 (流量控制)
- 校验和: 16位, 用来检验 TCP 报头的正确性, 由发送方计算, 接收方检验
- 紧急指针: 16位, 只有紧急指针标志位 URG 有效时候有效, 表示紧急数据的最后一个字节的序号
- 选项: 可选, 用来扩展 TCP 报文, 比如 SACK(Selective ACK), MSS(Maximum Segment Size), TS(Timestamp), WSOPT(Window Scale Option) 等
可靠传输的工作原理
我们知道,TCP发送的报文段是交给IP层传送的。但IP层只能提供尽最大努力服务,也就是说,TCP下面的网络所提供的是不可靠的传输。因此,TCP必须采用适当的措施才能使得两个运输层之间的通信变得可靠。
理想的传输条件有以下两个特点:
(1) 可靠传输: 传输信道不产生差错。
(2) 不管发送方以多快的速度发送数据,接收方总是来得及处理收到的数据。
可靠传输主要由 ACK + 重传机制 保证, 有 停止等待协议 和 连续ARQ协议 两种实现方式。
最简单的方案就是停止等待协议
停止等待协议
停止等待 就是每发送完一个分组就停止发送,等待对方的确认。在收到确认后再发送下一个分组。
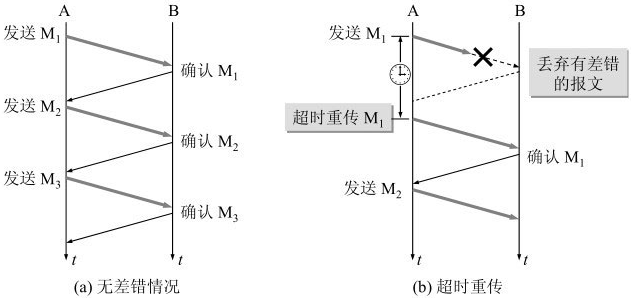
无差错情况
例如: A发送分组M1,发完就暂停发送,等待B的确认。B收到了M1就向A发送确认。A在收到了对M1的确认后,就再发送下一个分组M2。同样,在收到B对M2的确认后,再发送M3。
有差错情况
例如: A发送分组M1,M1丢包了, A等待超时还没有收到 M1 的确认, 就重传 M1
停止等待协议的信道利用率问题
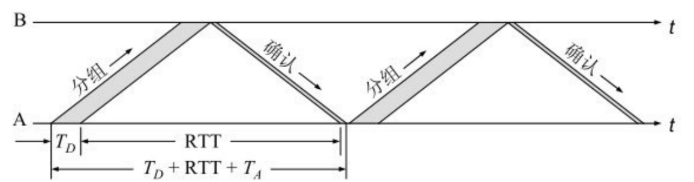
关于停止等待协议的信道利用率, 如果A发送数据的时间是 Td, B接受和处理的时间忽略不计, B 返回 ACK 的时间是 Ta, 数据在网络中传输的时间是 RTT, 那么信道的利用率是 Td/(Td+RTT+Ta)
比如 A, B 距离 200KM, RTT 是 20ms, 发送速率是 1MB/s, 平均 TCP 包的大小 1KB, 用时 1ms 发送 Ta 忽略不计
信道的利用率大概就是 1/21
停止等待协议的信道利用率实在是太低了, 这还没有算上超时丢包等异常情况, 算上的话信道利用率会更低
流水线的传输 (连续的 ARQ 协议) 可以提高信道利用率, 如下图所示

连续的 ARQ 协议(滑动窗口协议)
滑动窗口协议,可以将窗口内的多个分组数据都发送出去, 而不需要等待对方的确认。这样,信道利用率就提高了.
TCP 什么时候发送端什么时候发送数据, 接收端什么时候确认数据呢? 这里也是使用缓存的 累积 的思想, 发送端累积发送, 接收端累积确认
累积发送
应用进程把数据传送到TCP的发送缓存后,剩下的发送任务就由TCP来控制了。可以用不同的机制来控制TCP报文段的发送时机。
- 第一种机制是TCP维持一个变量,它等于最大报文段长度MSS。只要缓存中存放的数据达到MSS字节时,就组装成一个TCP报文段发送出去。
- 第二种机制是由发送方的应用进程指明要求立即发送报文段,比如 PUSH 和 URG 标志位。
- 第三种机制是发送方的一个计时器期限到了,这时就把当前已有的缓存数据装入报文段(但长度不能超过MSS)发送出去。
其实什么时候发送数据是一个复杂的问题, 因为 必须考虑传输效率, 后面会讲到
累积确认
同理累积发送, 接收方的TCP接收到一个报文段后,就把它放入接收缓存中, 剩下的确认任务就由TCP来控制了。可以用不同的机制来控制TCP报文段的确认时机。
- 第一种机制是TCP维持一个变量,它等于最大报文段长度MSS。只要接收缓存中存放的数据达到MSS字节时,就把累积确认标志置1,发送确认报文段。
- 第二种机制是由发送方的应用进程指明要求立即确认的报文段,比如 PUSH 和 URG 标志位。
- 第三种机制是接收方的一个计时器期限到了,这时就把累积确认标志置1,发送确认报文段。
累积确认只需要回复完整连续的数据块的最大序号, 不需要回复每一个数据块的序号, 大大减少了 ack 的数量
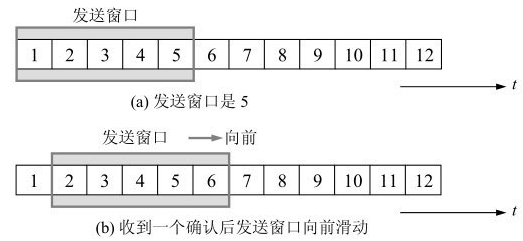
比如上图 (a) 发送端将 1 2 3 4 5 分组都发送出去
- 如果接收端回复了收到了数据 1, 发送端就能将窗口向右移动 1 位, 如上图 (b) 所示
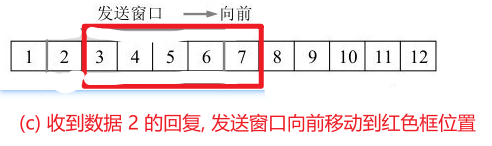
- 如果接收端回复了收到了数据 2, 发送端就能将窗口向右移动 2 位, 如上图 (c) 所示
注意: 上图将窗口和缓存画成线性数组, 其实缓存应该是循环利用的环形 ringbuffer
窗口只能不动或者右移动, 收到 ack 之后就右移, 并且窗口左边的数据都不能再使用
刚刚我们介绍了正常情况下的 ack 机制, 我们再看看 2 种异常情况下重传机制, 超时重传和快重传
超时重传
同理停止等待协议, 如果超时还没有收到 ack (发送的数据包丢包或者 ack 的数据包丢包) 就重传数据
例如: A发送分组M1,M1丢包了, A等待超时还没有收到 M1 的确认, 就重传 M1
超时重传时间是多少呢?
如果把超时重传时间设置得太短,就会引起很多报文段的不必要的重传,使网络负荷增大。但若把超时重传时间设置得过长,则又使网络的空闲时间增大,降低了传输效率。
TCP 使用自适应算法(一种动态规划), 动态计算超时重传时间 RTO (RetransmissionTime-Out)
计算超时重传时间 RTO
(1) 首先需要计算平均往返时间, 又叫做平滑往返时间 RTTS (Round Trip Time Smooth)
新RTTS = (1-α) * 旧RTTS + α * 新RTT
α 是平滑因子, 一般取 0.125
(2) 然后计算平均往返时间的偏差, 又叫做平滑往返时间偏差 RTTVAR (Round Trip Time Variation)
新RTTVAR = (1-β) * 旧RTTVAR + β * |新RTTS - 旧RTTS|
β 是平滑因子, 一般取 0.25
(3) 最后计算超时重传时间 RTO
RTO = RTTS + 4 * RTTVAR
一般 RTO 的最小值是 1 秒, 最大值是 60 秒
为什么说往返时间 RTT 是不准确的?
往返时间 RTT 一般计算方式是: 发送端发送数据包, 接收端收到数据包后回复 ack, 发送端收到 ack 后计算时间差, 得到往返时间 RTT
为什么说往返时间 RTT 是不准确的? 主要有 2 个原因:
- 接收端接受数据不会立即回复, 而是等待延迟应答定时器结束后再回复
- 如何判定此确认报文段是对先发送的报文段的确认,还是对后来重传的报文段的确认
针对第 2 点, 比如发送端发送了一个数据包M1, 如果M1丢包了, 发送端会重传M2, 接收端收到M2后, 会回复一个 ack, 但是发送端收到的 ack 可能是对 M1 的确认, 也可能是对重传的 M2 的确认, 如果发送端用重传的 M2 的确认来计算发送时间, 得到的往返时间 RTT 就会比实际的往返时间 RTT 大, 从而导致超时重传时间 RTO 计算不准确
解决方法就是: 重传的往返时间不参与 RTT 计算
只要一个包发生了重传, 这个包就不参与 RTT 计算, 直接 RTO翻倍
也就是说每次发生重传 RTO 都会翻倍, 比如连续重传 3 次, RTO 就会变成 8 倍 (对比 KCP 的翻 1.5 倍, 8 倍的翻倍是非常恐怖的)
快重传
超时重传需要重传丢包位置开始后面的所有数据, 比较浪费资源
比如发送端发送 1 2 3 4 5 6几组数据, 只有 3 丢包了, 超时重传需要重传 3 4 5 6
快重传: 接收方每收到一个失序的报文段后就立即发出重复确认, 发送端收到 3 个重复的确认后立即重传, 而不是等到发送端超时重传 (快重传一般和 TCP 拥塞控制的 快恢复 搭配使用, 后面介绍)
超时重传的情况下: 接收方收到数据一般不会马上回复, TCP 会聚合收到的数据, 比如每 200ms 回复一次
下面举个例子介绍下快重传的流程:
比如发送端发送 1 2 3 4 5 6几组数据, 3 丢包了
接收端收到 1 2 4 后, 因为累积确认只能确认收到完整的数据, 所以立即回复收到了 2
接收端下次再收到数据 5, 还是没有收到 3, 回复收到了 2
接收端下次再收到数据 6, 还是没有收到 3, 回复收到了 2
发送端 3 次收到重复的 ack 后, 立即重传 3
接收端凑齐了 1 2 3 4 5 6, 回复收到了 6
ack 表示了接下来发送的数据, 所以回复收到了 x, 其实 ack=x+1, 例如回复收到了 6, 其实 ack=7
由于发送方能尽早重传未被确认的报文段,因此采用快重传后可以使整个网络的吞吐量提高约20%
SACK 选择性确认
快重传主要是解决 累积确认 如果中间数据包丢了导致的重传丢包后所有数据的资源浪费问题
这主要是因为累积确认只返回收到的完整的最大序号, 例如: 1 2 3 4 5 6, 3 丢了, 累积确认只能返回 2, 所以发送端只能重传 3 4 5 6
其实如果我们能知道 3 丢了, 那么就可以只重传 3, 而不是 3 4 5 6
如何知道 3 丢了呢? 这就是 SACK 选择性确认
SACK 选择性确认: 接收方收到数据后, 不仅仅返回收到的最大序号, 还会在报文的选项部分返回收到的数据块, 例如: 1 2 3 4 5 6, 3 丢了, 在选项部分返回 1-2 4-6 表示收到的数据块, 这样发送端就知道 3 丢了, 只需要重传 3
SACK 处于 TCP 头部的选项部分, 需要发送方和接收方都支持
选项部分最多有 40 字节, 标记一个数据块需要 2 个边界, 也就是 2 * 4 = 8 字节, 因为需要 1 个字节表示选项类型, 1 个字节表示选项长度, 所以 SACK 最多标记 4 个数据块 (4 * 8 + 2 = 34 没超过, 5 * 8 + 2 = 42 超过)
SACK文档并没有指明发送方应当怎样响应SACK。因此大多数的实现还是重传所有未被确认的数据块。
流量控制
区分流量控制和拥塞控制
也许你听说过 TCP 的流量控制, 拥塞控制, 我这里举个例子来区分下他们
流量控制: 比如带宽是 10Gb, A 向 B 以 1Gb 的速度发送数据, 显然网络带宽是足够的不存在拥塞问题, 但是流量控制是必须的, 因为 B 处理不过来, 需要经常停下来 (这个时候 B 可以通过流量控制告诉 A, 你的速度太快了, 我处理不过来, 你慢点)
拥塞控制: 比如带宽是 1Mb, 有 1000 台机器用 100Kb 的速度向服务器发送数据, 网络接受不了这么多的数据, 交换机和路由器处理不过来的数据就会丢弃, 导致大量丢包. (这个时候发送端丢包了就知道网络可能不太好, 就使用拥塞控制减低发送速度)
流量控制防止数据将服务器的撑爆, 拥塞控制防止把网络设备撑爆
基于滑动窗口实现流量控制
流量控制是基于滑动窗口实现的, 每次发送端发送数据后, 接收端会返回一个窗口大小, 发送端根据窗口大小来决定发送的数据量

举个例子

- A 和 B 建立连接的时候 B 告诉 A, 我的接受窗口是 400 字节, 发送端的发送窗口不要大于接收端的接受窗口
- 接收方 B 对于发送方 A 进行了 3 次流量控制, 第一次将窗口减少到 300, 第二次减少到 100, 第三次减少到 0
我们又考虑一种情况, 如果窗口减少到 0 之后, B 将数据处理后又有了空间, 于是 B 向 A 发送窗口有 400 的报文, A 收到后将窗口增加到 400
但是如果 B 向 A 发送窗口有 400 的报文丢包了呢? A一直等待收到B发送的非零窗口的通知,而B也一直等待A发送的数据。如果没有其他措施,这种互相等待的死锁局面将一直延续下去。
为了解决这个问题,TCP为每一个连接设有一个持续计时器(persistence timer)。只要TCP连接的一方收到对方的零窗口通知,就启动持续计时器。若持续计时器设置的时间到期,就发送一个零窗口探测报文段(仅携带1字节的数据),而对方就在确认这个探测报文段时给出了现在的窗口值。如果窗口仍然是零,那么收到这个报文段的一方就重新设置持续计时器。如果窗口不是零,那么死锁的僵局就可以打破了。
必须考虑传输效率
其实什么时候发送数据是一个复杂的问题, 在 累积发送 的基础上, 必须考虑传输效率
我们来看一种极端情况
一个交互式用户使用一条 ssh 连接(运输层为TCP协议)。假设用户只发1个字符。加上20字节的首部后,得到21字节长的TCP报文段。再加上20字节的IP首部,形成41字节长的IP数据报。在接收方TCP立即发出确认,构成的数据报是40字节长(假定没有数据发送)。若用户要求远地主机回送这一字符,则又要发回41字节长的IP数据报和40字节长的确认IP数据报。这样,用户仅发1个字符时线路上就需传送总长度为162字节共4个报文段。当线路带宽并不富裕时,这种传送方法的效率的确不高。因此应适当推迟发回确认报文,并尽量使用捎带确认的方法。
在TCP的实现中广泛使用Nagle算法。算法如下:若发送应用进程把要发送的数据逐个字节地送到TCP的发送缓存,则发送方就把第一个数据字节先发送出去,把后面到达的数据字节都缓存起来。当发送方收到对第一个数据字符的确认后,再把发送缓存中的所有数据组装成一个报文段发送出去,同时继续对随后到达的数据进行缓存。只有在收到对前一个报文段的确认后才继续发送下一个报文段。当数据到达较快而网络速率较慢时,用这样的方法可明显地减少所用的网络带宽。Nagle算法还规定,当到达的数据已达到发送窗口大小的一半或已达到报文段的最大长度时,就立即发送一个报文段。这样做,就可以有效地提高网络的吞吐量。
我们再来看一种极端情况, 叫做 "糊涂窗口综合症"
TCP接收方的缓存已满,而交互式的应用进程一次只从接收缓存中读取 1 个字节, 接受方有 1 个接受窗口空余的时候, 向发送端告知还有一个接受窗口空余, 这样发送方的发送窗口为 1, 发送端再发 1 个字节的数据, 接受端收到数据后窗口又满了... 这样下去, 传输效率就很低了
要解决这个问题, 可以有下面的方案
- 接收方的接受窗口有空余时候, 不要立即回复发送端, 等待一段时间累积回复
- 接收方的接受窗口有空余时候, 立即回复发送端, 累积一定数量再恢复 (最大报文长度 MSS)
- 发送端有发送数据的时候不要立即发送, 参考 累积发送 的机制
上述两种方法可配合使用。使得在发送方不发送很小的报文段的同时,接收方也不要在缓存刚刚有了一点小的空间就急忙把这个很小的窗口大小信息通知给发送方。
拥塞控制
拥塞控制和流量控制都可以减低发送端的发送速度, 他们的区别参考 区分流量控制和拥塞控制
拥塞控制是基于拥塞窗口实现的, 发送方维持一个叫做拥塞窗口 cwnd (congestion window)的状态变量, 所以发送窗口的计算方式如下
发送窗口 = min(接收窗口, 拥塞窗口)
拥塞控制有四种算法,即慢开始(slow-start)、拥塞避免(congestion avoidance)、快重传(fast retransmit)和快恢复(fast recovery)
我们先假设接收窗口是无限大, 不会被流量控制限制, 我们只考虑网络拥塞的情况
慢开始和拥塞避免
首先在 3 次握手建立连接的时候通信获得最大报文段 MSS (Max Segment Size), 以及阈值 ssthresh (slow start threshold)的大小
- 如果 cwnd < sshthresh, 慢开始算法, 拥塞窗口指数递增,
cwnd = cwnd * 2 - 如果 cwnd > sshthresh, 拥塞避免算法, 拥塞窗口线性递增,
cwnd = cwnd + 1 - 如果 cwnd = sshthresh, 2 种算法都可以
举个例子, 比如一开始的 ssthresh = 12 个 MSS
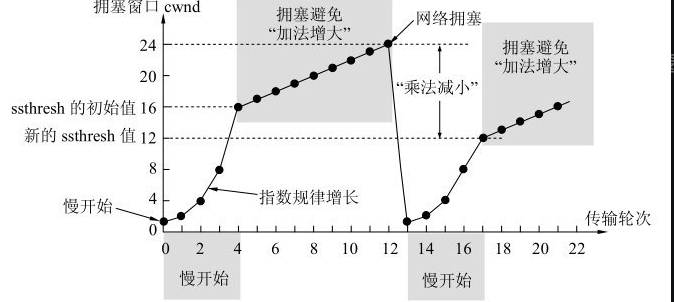
- 刚开始发送数据时, 先把拥塞窗口 cwnd 设置为 1
- 然后开始慢开始算法, 拥塞窗口指数递增, 1 2 4 8 16 ...
- 当递增到 16 之后, cwnd > sshthresh, 拥塞避免算法, 拥塞窗口线性递增
- 当递增到 24 之后丢包了, 发生了 超时重传, 降低拥塞窗口
ssthresh = cwnd / 2 = 12, cwnd = 1, 重新开始慢开始策略
快重传和快恢复
快重传和快恢复一般搭配使用, 可以参考上面的 快重传, 快重传算法首先要求接收方每收到一个失序的报文段后就立即发出重复确认
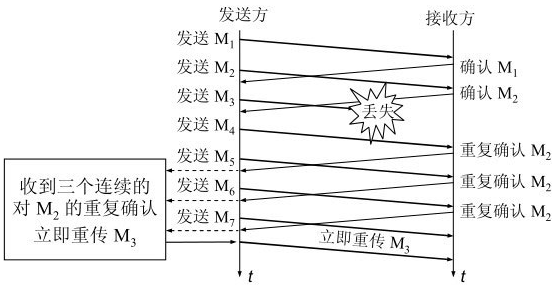
发送端接受到 3 次相同的 ack 之后就马上重传确实的数据, 然后执行 快恢复算法 , 拥塞窗口 ssthresh = cwnd / 2 = 1, cwnd = ssthresh = 12, 然后开始拥塞避免算法
第三层网络层的随机早期检测RED
前面我们介绍的都是第四层 TCP 解决网络拥塞的策略, 并没有和第三层网络层结合起来, 但是其实他们有着密切的联系.
举个极端的例子:
- 路由器对于数据一般是采用 FIFO 的方式进行转发, 新来的数据储存到队列中, 队列满了就丢弃数据
- 路由器一般有很多 TCP 连接, 所以丢弃数据的时候可能会影响大量的 TCP 连接
- 这些 TCP 群体超时重传, 进入慢开始, 网络负载重很高突然变得很低, 然后又逐渐增加, 负载又很高...(称之为 TCP 的全局同步)
如何能解决这种全局同步的现象呢?
思路就是在可能要网络拥塞的时候就开始随机丢包, 让一部分 TCP 先慢下来, 这就是随机早起检测 RED 的基本思想
比如当队列长度达到一半(最小门限)时候就开始随机丢包, 丢包概率和随长度线性递增, 如下图所示
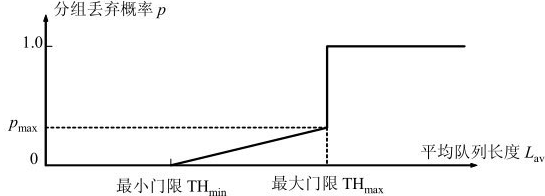
具体计算方法这里就不赘述了
建立连接和断开连接
TCP 运输连接有 3 个阶段
- 3 次握手建立连接
- 数据传输
- 4 次挥手断开连接
刚刚介绍了第二个阶段数据传输, 我们来看看其他两个阶段
3次握手建立连接
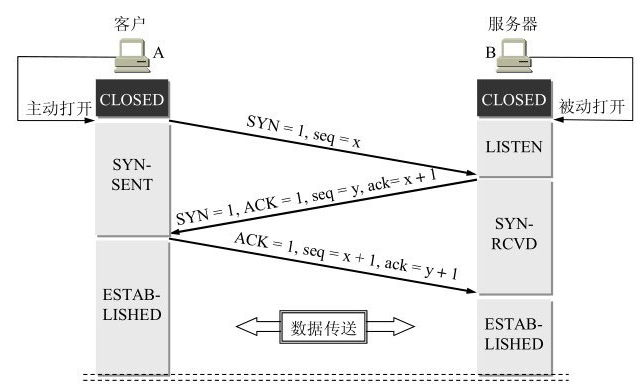
我们首先要知道
(1) SYN 包即使不携带数据也要占一个序列号, 比如发送第一个 SYN 包, 序列号为 1, 发送第二个包, 序列号为 2
(2) ACK 包返回的是期望的下一个数据, 所以 ACK号 = 收到的序列号 + 1
- 客户端 SYN 包(标记 SYN 为1), 选择一个初始序列号 seq = x
- 服务端 SYN/ACK 包(标记 SYN 为1, ACK 为1), 选择一个初始序列号 seq = y, 确认号 ack = x + 1
- 客户端 ACK 包(标记 ACK 为1), seq = x + 1, 确认号 ack = y + 1
- 如果客户端要继续发送数据, 应该从 x + 1 开始发送, 服务端应该从 y + 1 开始发送
为什么一定要三次握手呢? 为什么不是两次或者四次呢?
这主要是为了防止已失效的连接请求报文段突然又传送到了B,因而产生错误
- A 发送了连接请求1, 连接请求1在网络中滞留, A超时重传连接请求2, B收到连接请求2建立连接, 传输数据后断开连接
- 连接请求1在网络中滞留结束, 传送到了B, B误认为是A发出的新的连接请求, 于是向A发出确认, 但是A并没有发出连接请求, 所以不会理睬B的确认, B就会一直等待A的确认, 造成资源浪费
4次挥手断开连接
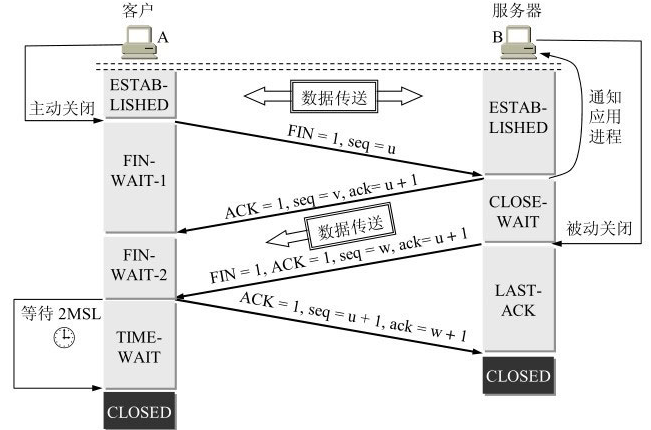
我们首先要知道
(1) FIN 包即使不携带数据也要占一个序列号, 比如发送第一个 FIN 包, 序列号为 1, 发送第二个包, 序列号为 2
- A的应用进程先向其TCP发出连接释放报文段,并停止再发送数据,主动关闭TCP连接。A把连接释放报文段首部的终止控制位FIN置1,其序号seq =u,它等于前面已传送过的数据的最后一个字节的序号加1。这时A进入FIN-WAIT-1(终止等待1)状态,等待B的确认。
- B收到连接释放报文段后即发出确认,确认号是ack = u + 1,而这个报文段自己的序号是v,等于B前面已传送过的数据的最后一个字节的序号加1。然后B就进入CLOSE-WAIT(关闭等待)状态。TCP服务器进程这时应通知高层应用进程,因而从A到B这个方向的连接就释放了,这时的TCP连接处于半关闭(half-close)状态,即A已经没有数据要发送了,但B若发送数据,A仍要接收。也就是说,从B到A这个方向的连接并未关闭,这个状态可能会持续一些时间。
A收到来自B的确认后,就进入FIN-WAIT-2(终止等待2)状态,等待B发出的连接释放报文段。
- 若B已经没有要向A发送的数据,其应用进程就通知TCP释放连接。这时B发出的连接释放报文段必须使FIN = 1。现假定B的序号为w(在半关闭状态B可能又发送了一些数据)。B还必须重复上次已发送过的确认号ack = u + 1。这时B就进入LAST-ACK(最后确认)状态,等待A的确认。
- A在收到B的连接释放报文段后,必须对此发出确认。在确认报文段中把ACK置1,确认号ack = w + 1,而自己的序号是seq = u + 1(根据TCP标准,前面发送过的FIN报文段要消耗一个序号)。然后进入到TIME-WAIT(时间等待)状态。请注意,现在TCP连接还没有释放掉。必须经过时间等待计时器(TIME-WAIT timer)设置的时间2MSL后,A才进入到CLOSED状态。
为什么A在TIME-WAIT状态必须等待2MSL的时间呢?这有两个理由:
第一,为了保证A发送的最后一个ACK报文段能够到达B。这个ACK报文段有可能丢失,因而使处在LAST-ACK状态的B收不到对已发送的FIN + ACK报文段的确认。B会超时重传这个FIN + ACK报文段,而A就能在2MSL时间内收到这个重传的FIN + ACK报文段。接着A重传一次确认,重新启动2MSL计时器。最后,A和B都正常进入到CLOSED状态。如果A在TIME-WAIT状态不等待一段时间,而是在发送完ACK报文段后立即释放连接,那么就无法收到B重传的FIN + ACK报文段,因而也不会再发送一次确认报文段。这样,B就无法按照正常步骤进入CLOSED状态。
第二,防止上一节提到的“已失效的连接请求报文段”出现在本连接中。A在发送完最后一个ACK报文段后,再经过时间2MSL,就可以使本连接持续的时间内所产生的所有报文段都从网络中消失。这样就可以使下一个新的连接中不会出现这种旧的连接请求报文段。
reference
计算机网络-谢希仁: https://weread.qq.com/web/bookDetail/af532c005a007caf51371b1
kcp协议
TCP是为流量设计的(每秒内可以传输多少KB的数据),讲究的是充分利用带宽。而 KCP是为流速设计的(单个数据包从一端发送到一端需要多少时间),以10%-20%带宽浪费的代价换取了比 TCP快30%-40%的传输速度。
KCP 是基于 UDP 协议实现的, 我们看看 UPD 的协议报
UDP协议报
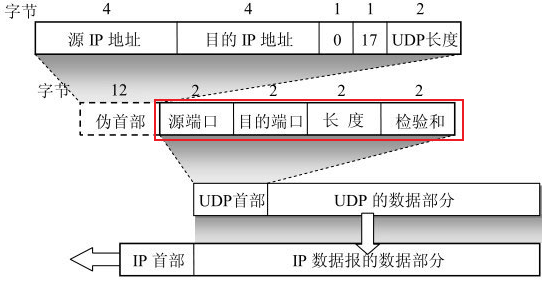
- 源端口 源端口号。在需要对方回信时选用。不需要时可用全0。
- 目的端口 目的端口号。这在终点交付报文时必须要使用到。
- 长度 UDP用户数据报的长度,其最小值是8(仅有首部)。
- 检验和 检测UDP用户数据报在传输中是否有错。有错就丢弃。
KCP协议报
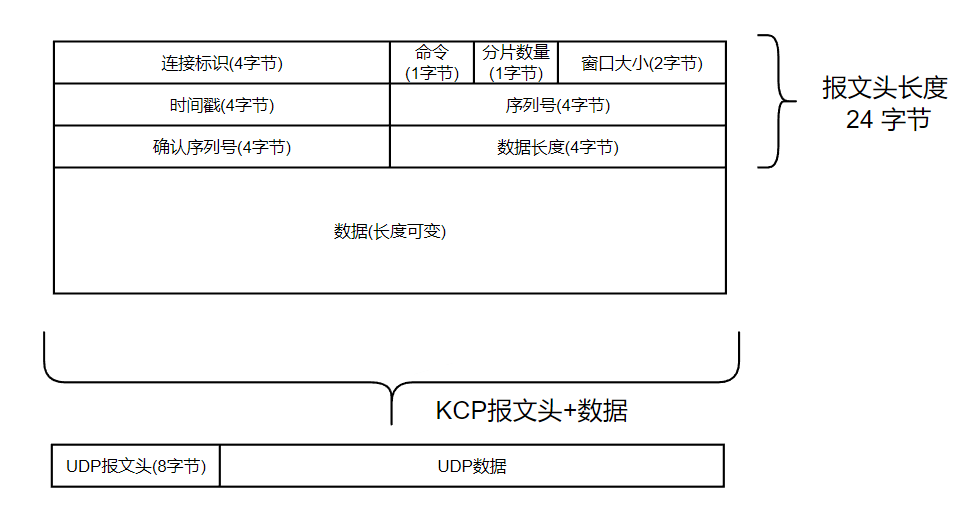
- 连接标识 (4 字节): 这个连接发出去的每个报文段都会带上
conv, 它也只会接收conv与之相等的报文段. 通信的双方必须先协商一对相同的conv. KCP 本身不提供任何握手机制, 协商conv交给使用者自行实现, 比如说通过已有的 TCP 连接协商 - 命令类型 (1字节)
- 分片数量 (1字节): 表示随后还有多少个报文属于同一个包. (数据包的大小可能会超过一个 MSS (Maximum Segment Size, 最大报文段大小). 这个时候需要进行分片, 分片数量表示随后还有多少个报文属于同一个包.)
- 窗口大小 (2 字节): 发送方剩余接收窗口的大小. (类似 TCP 流量控制)
- 时间戳 (4 字节): TCP 使用往返时间计算 RTT 的, KCP 的时间需要重外部传进来
- 序列号 (4 字节): 类似 TCP 的 seq 序列号
- 确认序列号 (4 字节): 类似 TCP 的 seq 序列号, 发送方的接收缓冲区中最小还未收到的报文段的编号. 也就是说, 编号比它小的报文段都已全部接收.
- 数据长度 (4 字节): 数据的长度 (TCP 没有数据长度, TCP 是面向流的)
- 数据 (长度可变)
kcp 协议报的结构体
type segment struct {
// 连接标识
conv uint32
// 命令号
cmd uint8
// 分片数量
frg uint8
// 窗口大小
wnd uint16
// 时间戳
ts uint32
// 序列号
sn uint32
// 确认序列号
una uint32
// 超时时间, 通过来回 ts 计算的 RTT 进而计算出来的 RTO 和 TCP 的 RTO 类似
rto uint32
// 该报文传输的次数
xmit uint32
// 下次重发的时间戳, 初始值为: current + rto
resendts uint32
// ACK 失序次数. 也就是 KCP Readme 中所说的 "跳过" 次数
fastack uint32
// 是否确认
acked uint32 // mark if the seg has acked
// 数据
data []byte
}
KCP 实例
type KCP struct {
// conv 连接标识
// mtu 最大传输单元
// mss 最大报文段大小
// state 状态, 0 表示连接建立, -1 表示连接断开. (注意 state 是 unsigned int, -1 实际上是 0xffffffff)
conv, mtu, mss, state uint32
// snd_una 发送缓冲区中最小还未确认送达的报文段的编号. 也就是说, 编号比它小的报文段都已确认送达.
// snd_nxt 下一个等待发送的报文段的编号
// rcv_nxt 下一个等待接收的报文段的编号
snd_una, snd_nxt, rcv_nxt uint32
// ts_recent 时间戳
ssthresh uint32
// rx_rttval 用于计算 rx_rto 的变量
// rx_srtt 用于计算 rx_rto 的变量
rx_rttvar, rx_srtt int32
// rx_rto 重传超时时间, 通过来回 ts 计算的 RTT 进而计算出来的 RTO 和 TCP 的 RTO 类似
// rx_minrto 最小重传超时时间
rx_rto, rx_minrto uint32
// snd_wnd 发送窗口大小
// rcv_wnd 接收窗口大小
// rmt_wnd 远端窗口大小
// cwnd 拥塞窗口大小
// probe 拥塞探测标识
snd_wnd, rcv_wnd, rmt_wnd, cwnd, probe uint32
// interval 间隔时间, 用于更新 KCP 内部的时间戳
// ts_flush 下次刷新的时间戳
interval, ts_flush uint32
// nodelay 是否启用 nodelay 模式
// updated 是否更新了 nodelay 模式
nodelay, updated uint32
// ts_probe 下次探测的时间戳
// probe_wait 探测等待时间
ts_probe, probe_wait uint32
// dead_link 下次检测 dead link 的时间戳
// incr 拥塞窗口大小增量
dead_link, incr uint32
// fastresend 快速重传模式, ACK 失序 fastresend 次时触发快速重传
fastresend int32
// nocwnd 没有拥塞控制的模式
// stream 流模式
nocwnd, stream int32
// snd_queue 发送队列
snd_queue []segment
// rcv_queue 接收队列
rcv_queue []segment
// snd_buf 发送缓冲区
snd_buf []segment
// rcv_buf 接收缓冲区
rcv_buf []segment
// acklist 确认列表
acklist []ackItem
// buffer flush 时候的临时缓冲区
buffer []byte
// reserved 保留字段
reserved int
// output 输出的回调函数 func(buf []byte, size int)
output output_callback
}
队列和缓冲区
我们先来看 snd_queue, rcv_queue, snd_buf 和 rcv_buf 这四个字段. 它们分别是发送队列, 接收队列, 发送缓冲区和接收缓冲区. 队列和缓冲区其实都是循环双链表, 链表节点的类型都是 struct IKCPSEG.
调用 ikcp_send 发送数据时会先将数据加入 snd_queue 中, 然后再伺机加入 snd_buf. 每次调用 ikcp_flush 时都将 snd_buf 中满足条件的报文段都发送出去. 之所以不将报文直接加入 snd_buf 是为了防止一次发送过多的报文导致拥塞, 需要再拥塞算法的控制下伺机加入 snd_buf 中.
调用 ikcp_input 收到的数据解包后会先放入 rcv_buf 中, 再在合适的情况下转移到 rcv_queue 中. 调用 ikcp_recv 接收数据时会从 rcv_queue 取出数据返回给调用者. 这样做是因为报文传输的过程中会出现丢包, 失序等情况. 为了保证顺序, 需要将收到的报文先放入 rcv_buf 中, 只有当 rcv_buf 中的报文段顺序正确才能将其移动到 rcv_queue 中供调用者接收. 如下图所示, rcv_buf 中节点为灰色表示可以移动到 rcv_queue 中. 只有当 2 号报文重传成功后, 才能将 2, 3, 4 号报文移动到 rcv_queue 中.
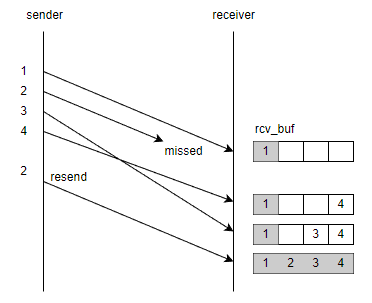
总结如下
- 发送数据: 创建报文实例后添加到 snd_queue 中, 然后再伺机添加到 snd_buf 中, 最后调用 ikcp_flush 发送出去.
- 接受数据: 收到数据后添加到 rcv_buf 中, 然后再将 顺序正确 的报文伺机添加到 rcv_queue 中, 最后调用 ikcp_recv 接收数据.
技术特性
TCP是为流量设计的(每秒内可以传输多少KB的数据),讲究的是充分利用带宽。而 KCP是为流速设计的(单个数据包从一端发送到一端需要多少时间),以10%-20%带宽浪费的代价换取了比 TCP快30%-40%的传输速度。TCP信道是一条流速很慢,但每秒流量很大的大运河,而KCP是水流湍急的小激流。KCP有正常模式和快速模式两种,通过以下策略达到提高流速的结果:
RTO翻倍vs不翻倍:
TCP超时计算是RTOx2,这样连续丢三次包就变成RTOx8了,十分恐怖,而KCP启动快速模式后不x2,只是x1.5(实验证明1.5这个值相对比较好),提高了传输速度。
选择性重传 vs 全部重传:
TCP丢包时会全部重传从丢的那个包开始以后的数据,KCP是选择性重传,只重传真正丢失的数据包。
快速重传:
发送端发送了1,2,3,4,5几个包,然后收到远端的ACK: 1, 3, 4, 5,当收到ACK3时,KCP知道2被跳过1次,收到ACK4时,知道2被跳过了2次,此时可以认为2号丢失,不用等超时,直接重传2号包,大大改善了丢包时的传输速度。(TCP 的快速重传写死了是 3 次, KCP 可以自己设置, 一般是是 2 次)
延迟ACK vs 非延迟ACK:
TCP为了充分利用带宽,延迟发送ACK(NODELAY都没用),这样超时计算会算出较大 RTT时间,延长了丢包时的判断过程。KCP的ACK是否延迟发送可以调节。
UNA vs ACK+UNA:
ARQ模型响应有两种,UNA(此编号前所有包已收到,如TCP)和ACK(该编号包已收到),光用UNA将导致全部重传,光用ACK则丢失成本太高,以往协议都是二选其一,而 KCP协议中,除去单独的 ACK包外,所有包都有UNA信息。
非退让流控:
KCP正常模式同TCP一样使用公平退让法则,即发送窗口大小由:发送缓存大小、接收端剩余接收缓存大小、丢包退让及慢启动这四要素决定。但传送及时性要求很高的小数据时,可选择通过配置跳过后两步,仅用前两项来控制发送频率。以牺牲部分公平性及带宽利用率之代价,换取了开着BT都能流畅传输的效果。
KCP 最佳实践
前向纠错
为了进一步提高传输速度,下层协议也许会使用前向纠错技术。需要注意,前向纠错会根据冗余信息解出原始数据包。相同的原始数据包不要两次input到KCP,否则将会导致 kcp以为对方重发了,这样会产生更多的ack占用额外带宽。
比如下层协议使用最简单的冗余包:单个数据包除了自己外,还会重复存储一次上一个数据包,以及上上一个数据包的内容:
Fn = (Pn, Pn-1, Pn-2)
P0 = (0, X, X)
P1 = (1, 0, X)
P2 = (2, 1, 0)
P3 = (3, 2, 1)
这样几个包发送出去,接收方对于单个原始包都可能被解出3次来(后面两个包任然会重复该包内容),那么这里需要记录一下,一个下层数据包只会input给kcp一次,避免过多重复ack带来的浪费。
管理大规模连接
如果需要同时管理大规模的 KCP连接(比如大于3000个),比如你正在实现一套类 epoll的机制,那么为了避免每秒钟对每个连接调用大量的调用 ikcp_update,我们可以使用 ikcp_check 来大大减少 ikcp_update调用的次数。 ikcp_check返回值会告诉你需要在什么时间点再次调用 ikcp_update(如果中途没有 ikcp_send, ikcp_input的话,否则中途调用了 ikcp_send, ikcp_input的话,需要在下一次interval时调用 update)
标准顺序是每次调用了 ikcp_update后,使用 ikcp_check决定下次什么时间点再次调用 ikcp_update,而如果中途发生了 ikcp_send, ikcp_input 的话,在下一轮 interval 立马调用 ikcp_update和 ikcp_check。 使用该方法,原来在处理2000个 kcp连接且每
个连接每10ms调用一次update,改为 check机制后,cpu从 60%降低到 15%。
避免缓存积累延迟
不管是 TCP/KCP,信道能力在那里放着,让你没法无限制的调用 send,请阅读:“如何避免缓存积累延迟” 这篇 wiki。
协议栈分层组装
不要试图将任何加密或者 FEC相关代码实现到 KCP里面,请实现成不同协议单元并组装成你的协议栈,具体请看:协议栈分层组装
如何支持收发可靠和非可靠数据?
有的产品可能除了需要可靠数据,还需要发送非可靠数据,那么 KCP 如何支持这种需求呢?很简单,你自己实现:
connection.send(channel, pkt, size);
channel == 0 使用 kcp 发送可靠包,channel == 1 使用 udp 发送非可靠包。
因为传输是你自己实现的,你可以在发送UDP包的头部加一个字节,来代表这个 channel,收到远程来的 UDP以后,也可以判断 channel==0 的话,把剩下的数据给 ikcp_input,否则剩下的数据为远程非可靠包。
这样你得到了一个新的发送函数,用channel来区别你想发送可靠数据还是非可靠数据。再统一封装一个 connection.recv 函数,先去 ikcp_recv 那里尝试收包,收不到的话,看刚才有没有收到 channel=1 的裸UDP包,有的话返回给上层用户。
如果你的服务端是混用 tcp/udp 的话,你还可以设计个 channel=2 使用 TCP 发送数据,针对一些比较大的,延迟不敏感的东西。
重设窗口大小
要解决上面的问题首先对你的使用带宽有一个预计,并根据上面的公式重新设置发送窗口和接收窗口大小,你写后端,想追求tcp的性能,也会需要重新设置tcp的 sndbuf, rcvbuf 的大小,KCP 默认发送窗口和接收窗口大小都比较小而已(默认32个包),你可以朝着 64, 128, 256, 512, 1024 等档次往上调,kcptun默认发送窗口 1024,用来传高清视频已经足够,游戏的话,32-256 应该满足。
不设置的话,如果默认 snd_wnd 太小,网络不是那么顺畅,你越来越多的数据会滞留在 snd_queue里得不到发送,你的延迟会越来越大。
设定了 snd_wnd,远端的 rcv_wnd 也需要相应扩大,并且不小于发送端的 snd_wnd 大小,否则设置没意义。
其次对于成熟的后端业务,不管用 TCP还是 KCP,你都需要实现相关缓存控制策略:
缓存控制:传送文件
你用 tcp传文件的话,当网络没能力了,你的 send调用要不就是阻塞掉,要不就是 EAGAIN,然后需要通过 epoll 检查 EPOLL_OUT事件来决定下次什么时候可以继续发送。
KCP 也一样,如果 ikcp_waitsnd 超过阈值,比如2倍 snd_wnd,那么停止调用 ikcp_send,ikcp_waitsnd的值降下来,当然期间要保持 ikcp_update 调用。
缓存控制:实时视频直播
视频点播和传文件一样,而视频直播,一旦 ikcp_waitsnd 超过阈值了,除了不再往 kcp 里发送新的数据包,你的视频应该进入一个 “丢帧” 状态,直到 ikcp_waitsnd 降低到阈值的 1/2,这样你的视频才不会有积累延迟。
这和使用 TCP推流时碰到 EAGAIN 期间,要主动丢帧的逻辑时一样的。
同时,如果你能做的更好点,waitsnd 超过阈值了,代表一段时间内网络传输能力下降了,此时你应该动态降低视频质量,减少码率,等网络恢复了你再恢复。
缓存控制:游戏控制数据
大部分逻辑严密的 TCP游戏服务器,都是使用无阻塞的 tcp链接配套个 epoll之类的东西,当后端业务向用户发送数据时会追加到用户空间的一块发送缓存,比如 ring buffer 之类,当 epoll 到 EPOLL_OUT 事件时(其实也就是tcp发送缓存有空余了,不会EAGAIN/EWOULDBLOCK的时候),再把 ring buffer 里面暂存的数据使用 send 传递给系统的 SNDBUF,直到再次 EAGAIN。
那么 TCP SERVER的后端业务持续向客户端发送数据,而客户端又迟迟没能力接收怎么办呢?此时 epoll 会长期不返回 EPOLL_OUT事件,数据会堆积再该用户的 ring buffer 之中,如果堆积越来越多,ring buffer 会自增长的话就会把 server 的内存给耗尽。因此成熟的 tcp 游戏服务器的做法是:当客户端应用层发送缓存(非tcp的sndbuf)中待发送数据超过一定阈值,就断开 TCP链接,因为该用户没有接收能力了,无法持续接收游戏数据。
使用 KCP 发送游戏数据也一样,当 ikcp_waitsnd 返回值超过一定限度时,你应该断开远端链接,因为他们没有能力接收了。
但是需要注意的是,KCP的默认窗口都是32,比tcp的默认窗口低很多,实际使用时应提前调大窗口,但是为了公平性也不要无止尽放大(不要超过1024)。
累积缓存: 总结
缓存积累这个问题,不管是 TCP还是 KCP你都要处理,因为TCP默认窗口比较大,因此可能很多人并没有处理的意识。
当你碰到缓存延迟时:
- 检查 snd_wnd, rcv_wnd 的值是否满足你的要求,根据上面的公式换算,每秒钟要发多少包,当前 snd_wnd满足条件么?
- 确认打开了 ikcp_nodelay,让各项加速特性得以运转,并确认 nc参数是否设置,以关闭默认的类 tcp保守流控方式。
- 确认 ikcp_update 调用频率是否满足要求(比如10ms一次)。
如果你还想更激进:
- 确认 minrto 是否设置,比如设置成 10ms, nodelay 只是设置成 30ms,更激进可以设置成 10ms 或者 5ms。
- 确认 interval是否设置,可以更激进的设置成 5ms,让内部始终循环更快。
- 每次发送完数据包后,手动调用 ikcp_flush
- 降低 mtu 到 470,同样数据虽然会发更多的包,但是小包在路由层优先级更高。
如果你还想更快,可以在 KCP下层增加前向纠错协议。详细见:协议分层,最佳实践。
如何使用
贴一个快速开始的示例
package main
import (
"crypto/sha1"
"io"
"log"
"testing"
"time"
"github.com/xtaci/kcp-go/v5"
"golang.org/x/crypto/pbkdf2"
)
func TestServer(t *testing.T) {
main()
}
func TestClient(t *testing.T) {
client()
}
func main() {
key := pbkdf2.Key([]byte("demo pass"), []byte("demo salt"), 1024, 32, sha1.New)
block, _ := kcp.NewAESBlockCrypt(key)
if listener, err := kcp.ListenWithOptions("127.0.0.1:12345", block, 10, 3); err == nil {
// spin-up the client
go client()
for {
s, err := listener.AcceptKCP()
if err != nil {
log.Fatal(err)
}
go handleEcho(s)
}
} else {
log.Fatal(err)
}
}
// handleEcho send back everything it received
func handleEcho(conn *kcp.UDPSession) {
buf := make([]byte, 4096)
for {
n, err := conn.Read(buf)
if err != nil {
log.Println(err)
return
}
n, err = conn.Write(buf[:n])
if err != nil {
log.Println(err)
return
}
}
}
func client() {
key := pbkdf2.Key([]byte("demo pass"), []byte("demo salt"), 1024, 32, sha1.New)
block, _ := kcp.NewAESBlockCrypt(key)
// wait for server to become ready
time.Sleep(time.Second)
// dial to the echo server
if sess, err := kcp.DialWithOptions("127.0.0.1:12345", block, 10, 3); err == nil {
for {
data := time.Now().String()
buf := make([]byte, len(data))
log.Println("sent:", data)
if _, err := sess.Write([]byte(data)); err == nil {
// read back the data
if _, err := io.ReadFull(sess, buf); err == nil {
log.Println("recv:", string(buf))
} else {
log.Fatal(err)
}
} else {
log.Fatal(err)
}
time.Sleep(time.Second)
}
} else {
log.Fatal(err)
}
}
reference
kcp Wiki: https://github.com/skywind3000/kcp/wiki
kcp: https://luyuhuang.tech/2020/12/09/kcp.html
TCP和KCP协议的更多相关文章
- Kcptun 是一个非常简单和快速的,基于KCP 协议的UDP 隧道,它可以将TCP 流转换为KCP+UDP 流
本博客曾经发布了通过 Finalspeed 加速 Shadowsocks 的教程,大家普遍反映能达到一个非常不错的速度.Finalspeed 虽好,就是内存占用稍高,不适合服务器内存本来就小的用户:而 ...
- KCP协议:从TCP到UDP家族QUIC/KCP/ENET
行文前先安利下<再深谈TCP/IP三步握手&四步挥手原理及衍生问题-长文解剖IP >.<再谈UDP协议-浅入理解深度记忆> KCP协议科普 KCP是一个快速可靠协议,能 ...
- kcp协议详解
kcp协议是传输层的一个具有可靠性的传输层ARQ协议.它的设计是为了解决在网络拥堵情况下tcp协议的网络速度慢的问题.kcp力求在保证可靠性的情况下提高传输速度.kcp协议的关注点主要在控制数据的可靠 ...
- 可靠UDP,KCP协议快在哪?
WeTest 导读 云真机已经支持手机端的画面投影.云真机实时操作,对延迟的要求比远程视频对话的要求更高(100ms以内).在无线网络下,如何更实时.更可靠的传输视频流就成了一个挑战.通过websoc ...
- KCP协议浅析
概述 KCP协议结合了TCP和UDP协议的特点,是一个快速可靠的协议. 引述官方介绍: KCP是一个快速可靠协议,能以比 TCP浪费10%-20%的带宽的代价,换取平均延迟降低 30%-40%,且最大 ...
- 对TCP/IP网络协议的深入浅出归纳
前段时间做了一个开发,涉及到网络编程,开发过程比较顺利,但任务完成后始终觉得有一些疑惑.主要是因为对网络协议不太熟悉,对一些概念也没弄清楚.后来 我花了一些时间去了解这些网络协议,现在对TCP/IP网 ...
- TCP与UDP协议
传输控制协议(Transmission Control Protocol, TCP)和用户数据报协议(User Datagram Protocol, UDP)是典型的传输层协议. 传输层协议基于网络层 ...
- 转:对TCP/IP网络协议的深入浅出归纳
转自:http://blog.jobbole.com/74795/ 前段时间做了一个开发,涉及到网络编程,开发过程比较顺利,但任务完成后始终觉得有一些疑惑.主要是因为对网络协议不太熟悉,对一些概念也没 ...
- 对TCP/IP网络协议的深入浅出归纳(转)
前段时间做了一个开发,涉及到网络编程,开发过程比较顺利,但任务完成后始终觉得有一些疑惑.主要是因为对网络协议不太熟悉,对一些概念也没弄清楚.后来 我花了一些时间去了解这些网络协议,现在对TCP/IP网 ...
- 关于tcp封装http协议
如果tcp中没有上层协议,那么就是简单的数据包的传输,如果tcp中有上层协议,那么,当客户端把tcp包发给server的时候,server端的socket收到数据包后,从中分离出应用层协议,交给上层继 ...
随机推荐
- Qt-FFmpeg开发-打开本地摄像头(6)
音视频/FFmpeg #Qt Qt-FFmpeg开发-打开本地摄像头[软解码+ OpenGL显示YUV] 目录 音视频/FFmpeg #Qt Qt-FFmpeg开发-打开本地摄像头[软解码+ Open ...
- OOP课第一阶段总结
前三次OOP作业总结Blog 前言 作为第一次3+1的总结,这次题目集的难度逐渐升高,题量.阅读量和测试点的数量变化都很大,所以对我们的编程和理解能力提出了更高的要求.要求我们能够熟练的掌握正则表达式 ...
- php简单登录
<?php // 1,php接收参数 $userName = $_POST['userName']; $userPwd = $_POST['userPwd']; // 2,PHP需要操作数据库 ...
- DP Record
从 2024/5/4 往后开始记录捏. T1. 给你一棵树,定义一个集合的权值为 \(\dfrac{\sum_{x\in S}V_x}{\sum_{x\in S}C_x}\).若一个点 \(\in S ...
- nordic的nrf52系列——ADC在使用时如何校准增益误差(基于SDK)
简介:ADC在实际使用的时候都要进行误差校准,那Nordic的nrf52系列如何进行校准,如果不校准又有什么影响尼,接下来我将通过实验进行测试,验证不校准和校准的影响(本测试的基础是,默认输入阻抗和采 ...
- CloseableHttpClient 连接超时导致XxlJob调度阻塞,影响调度任务的执行
CloseableHttpClient 连接超时导致XxlJob调度阻塞,影响调度任务的执行 问题原因1.分析日志发现,xxlJob后台界面没有执行时间和执行结果,在某一个时间点之后,某一个任务因为阻 ...
- nginx轮询负载均衡演示demo
1.nginx /conf/nginx.conf配置文件 #user nobody; worker_processes auto; #error_log logs/error.log; #error_ ...
- gradle打包命令含离线模式
gradle打包命令gradlew clean 清理gradlew clean build -x test --refresh-dependencies 离线方式: gradlew --offline ...
- .NET使用原生方法实现文件压缩和解压
前言 在.NET中实现文件或文件目录压缩和解压可以通过多种方式来完成,包括使用原生方法(System.IO.Compression命名空间中的类)和第三方库(如:SharpZipLib.SharpCo ...
- 基于MCU的SD卡fat文件系统读写移植
背景 https://blog.csdn.net/huang20083200056/article/details/78508490 SD卡(Secure Digital Memory Card)具有 ...