高性能图计算系统 Plato 在 Nebula Graph 中的实践
{kind=link}

1.图计算介绍
1.1 图数据库 vs 图计算
图数据库是面向 OLTP 场景,强调增删改查,并且一个查询往往只涉及到全图中的少量数据,而图计算是面向 OLAP 场景,往往是针对全图数据进行分析计算。
1.2 图计算系统分布架构
按照分布架构,图计算系统分为单机和分布式。
单机图计算系统优势在于模型简单,无需考虑分布式通讯,也无需进行图切分,但受制于单机系统资源,无法进行更大规模的图数据分析。
分布式图计算平台将图数据划分到多个机器上,从而处理更大规模的图数据,但不可避免的引入了分布式通讯的开销问题。
1.3 图的划分
图划分主要有两种方式边切割(Edge- Cut)和点切割(Vertex-Cut)。
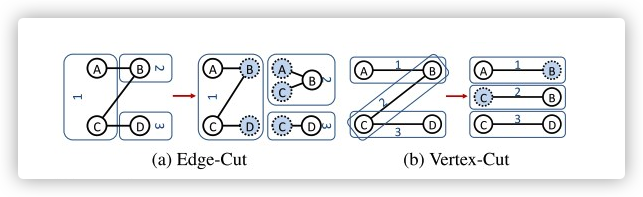
边分割:每个点的数据只会存储在一台机器上,但有的边会被打断分到多台机器上。
如图(a)所示,点 A 的数据只存放在机器 1 上,点B 的数据只存放在机器 2 上。对于边 AB 而言,会存储在机器 1 和机器 2 上。由于点 A 和点 B 分布在不同的机器上,在迭代计算过程中,会带来通讯上的开销。
点分割:每条边只会存储在一台机器上,但有的点有可能分割,分配在多台机器上。
如图(b)所示, 边 AB 存储在机器 1 上,边 BC 存储在机器 2 上,边 CD 存储在机器 3 上,而点 B 被分配到了 1, 2 两台机器上,点 C 被分配到了 2,3 两台机器上。由于点被存储在多台机器上,维护顶点数据的一致性同样也会带来通讯上的开销。
1.4 计算模型
编程模型是针对图计算应用开发者,可分为以节点为中心的编程模型、以边或路径为中心的编程模型、以子图为中心的编程模型。
计算模型是图计算系统开发者面临的问题,主要有同步执行模型和异步执行模型。比较常见的有 BSP 模型(Bulk Synchronous Parallel Computing Model)和 GAS 模型。
BSP 模型:BSP 模型的计算过程是由一系列的迭代步组成,每个迭代步被称为超步。采用 BSP 模型的系统主要有 Pregel、Hama、Giraph 等。
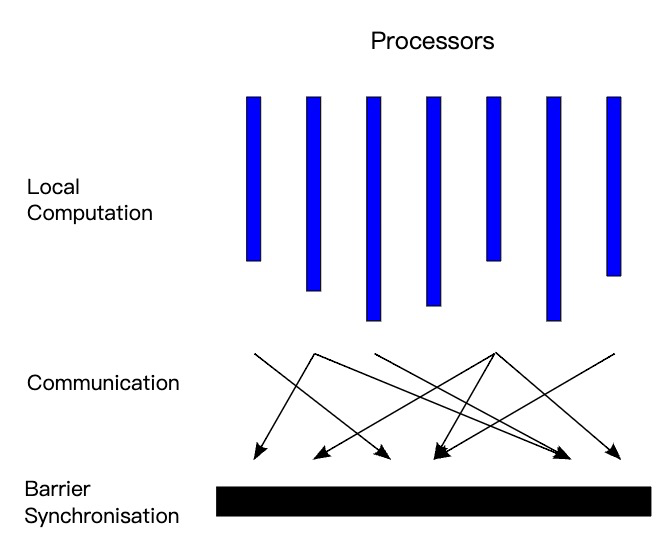
BSP 模型具有水平和垂直两个方面的结构。垂直上看,BSP 模型有一系列串行的超步组成。水平上看(如图所示),一个超步又分三个阶段:
- 本地计算阶段,每个处理器只对存储本地内存中的数据进行计算。
- 全局通信阶段,机器节点之间相互交换数据。
- 栅栏同步阶段,等待所有通信行为的结束。
GAS 模型:GAS 模型是在 PowerGraph 系统提出,分为信息收集阶段(Gather)、应用阶段(Apply)和分发阶段(Scatter)。
- Gather 阶段,负责从邻居顶点收集信息。
- Apply 阶段,负责将收集的信息在本地处理,更新到顶点上。
- Scatter 阶段,负责发送新的信息给邻居顶点。
2. Gemini 图计算系统介绍
Gemini 在工业界较有影响力,它的主要技术点包括:CSR/CSC、push/pull、master 和 mirror、稀疏和稠密图、通信与计算协同工作、chunk-based 式分区、NUMA 感知的子分区等。
Gemini 采用边切割方式将图数据按照 chunk-based 的方式分区,并支持 Numa 结构。分区后的数据,用 CSR 存储出边信息,用 CSC 存储入边信息。在迭代计算过程中,对稀疏图采用 push 的方式更新其出边邻居,对稠密图采用 pull 的方式拉取入边邻居的信息。
如果一条边被切割,边的一端顶点为 master,另一端顶点则为 mirror。mirror 被称为占位符(placeholder) ,在 pull 的计算过程中,各个机器上的 mirror 顶点会拉取其入边邻居 master 顶点的信息进行一次计算,在 BSP 的计算模型下通过网络同步给其 master 顶点。在 push 的计算过程中,各个机器的 master 顶点会将其信息先同步给它的 mirror 顶点,再由 mirror 更新其出边邻居。
在 BSP 的通信阶段,每台机器 Node_i 发送给它的下一个机器 Node_i+1,最后一个机器会发送给第一个机器。在每台机器发送的同时也会收到 Node_i-1 的信息,收到信息后会立即执行本地计算。通讯和计算的重叠可以隐藏通信时间,提升整体的效率。
更多细节可以参考论文《Gemini: A Computation-Centric Distributed Graph Processing System》。
3. Plato 图计算系统与 Nebula Graph 的集成
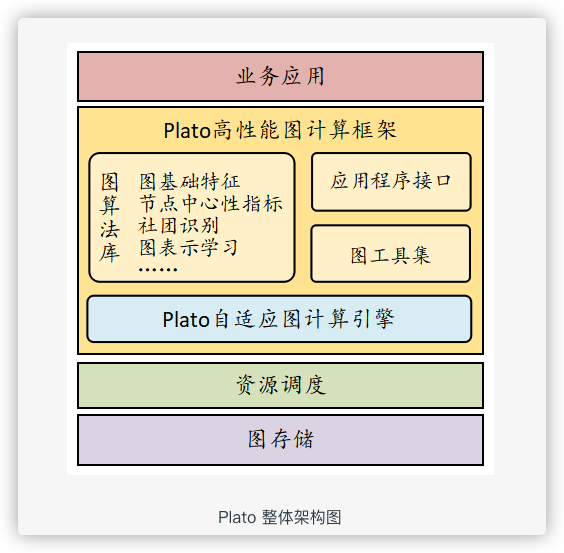
3.1 Plato 图计算系统介绍
Plato 是腾讯开源的基于 Gemni 论文实现的工业级图计算系统。Plato 可运行在通用的 x86 集群,如 Kubernetes 集群、Yarn 集群等。在文件系统层面,Plato 提供了多种接口支持主流的文件系统,如 HDFS、Ceph 等等。
3.2 与 Nebula Graph 的集成
我们基于 Plato 做了二次开发,以接入 Nebula Graph 数据源。
3.2.1 Nebula Graph 作为输入和输出数据源
增加 Plato 的数据源,支持将 Nebula Graph 作为输入和输出数据源,直接从 Nebula Graph 中读取数据进行图计算,并将计算结果直接写回到 Nebula Graph 中。
Nebula Graph 的存储层提供了针对 partition 的 scan 接口,很容易通过该接口批量扫出顶点和边数据:
ScanEdgeIter scanEdgeWithPart(std::string spaceName,
int32_t partID,
std::string edgeName,
std::vector<std::string> propNames,
int64_t limit = DEFAULT_LIMIT,
int64_t startTime = DEFAULT_START_TIME,
int64_t endTime = DEFAULT_END_TIME,
std::string filter = "",
bool onlyLatestVersion = false,
bool enableReadFromFollower = true);
ScanVertexIter scanVertexWithPart(std::string spaceName,
int32_t partId,
std::string tagName,
std::vector<std::string> propNames,
int64_t limit = DEFAULT_LIMIT,
int64_t startTime = DEFAULT_START_TIME,
int64_t endTime = DEFAULT_END_TIME,
std::string filter = "",
bool onlyLatestVersion = false,
bool enableReadFromFollower = true);
实践中,我们首先获取指定 space 下的 partition 分布情况,并将每个 partition 的 scan 任务分别分配给 Plato 集群的各个节点上,每个节点再进一步将 partition 的 scan 任务分配给运行在该节点的各个线程上,以达到并行快速的读取数据。图计算完成之后,将计算结果通过 Nebula client 并行写入 Nebula Graph。
3.2.2 分布式 ID 编码器
Gemini 和 Plato 的要求顶点 ID 从 0 开始连续递增,但绝大多数的真实数据顶点 ID 并不满足这个需求,尤其是 Nebula Graph 从 2.0 版本开始支持 string 类型 ID。
因此,在计算之前,我们需要将原始的 ID 从 int 或 string 类型转换为从 0 开始连续递增的 int。Plato 内部实现了一个单机版的 ID 编码器,即 Plato 集群的每台机器均冗余存储所有 ID 的映射关系。当点的数量比较多时,每台机器仅 ID 映射表的存储就需上百 GB 的内存,因为我们需要实现分布式的 ID 映射器,将 ID 映射关系切成多份,分开存储。
我们通过哈希将原始 ID 打散在不同的机器,并行地分配全局从 0 开始连续递增的 ID。生成 ID 映射关系后,每台机器都会存有 ID 映射表的一部分。随后再将边数据分别按起点和终点哈希,发送到对应的机器进行编码,最终得到的数据即为可用于计算的数据。当计算运行结束后,需要数据需要映射回业务 ID,其过程和上述也是类似的。
3.2.3 补充算法
我们在 Plato 的基础上增加了 sssp、apsp、jaccard similarity、三角计数等算法,并为每个算法增加了输入和输出到 Nebula Graph 数据源的支持。目前支持的算法有:
| 文件名 | 算法名称 | 分类 |
|---|---|---|
| apsp.cc | 全对最短路径 | 路径 |
| sssp.cc | 单源最短路径 | 路径 |
| tree_stat.cc | 树深度/宽度 | 图特征 |
| nstepdegrees.cc | n阶度 | 图特征 |
| hyperanf.cc | 图平均距离估算 | 图特征 |
| triangle_count.cc | 三角计数 | 图特征 |
| kcore.cc | 节点中心性 | |
| pagerank.cc | Pagerank | 节点中心性 |
| bnc.cc | Betweenness | 节点中心性 |
| cnc.cc | 接近中心性(Closeness Centrality) | 节点中心性 |
| cgm.cc | 连通分量计算 | 社区发现 |
| lpa.cc | 标签传播 | 社区发现 |
| hanp.cc | HANP | 社区发现 |
| metapath_randomwalk.cc | 图表示学习 | |
| node2vec_randomwalk.cc | 图表示学习 | |
| fast_unfolding.cc | louvain | 聚类 |
| infomap_simple.cc | 聚类 | |
| jaccard_similarity.cc | 相似度 | |
| mutual.cc | 其他 | |
| torch.cc | 其他 | |
| bfs.cc | 广度优先遍历 | 其他 |
4. Plato 部署安装与运行
4.1 集群部署
Plato 采用 MPI 进行进程间通信,在集群上部署 Plato 时,需要将 Plato 安装在相同的目录下,或者使用 NFS。操作方法见:https://mpitutorial.com/tutorials/running-an-mpi-cluster-within-a-lan/
4.2 运行算法的脚本及配置文件
scripts/run_pagerank_local.sh
#!/bin/bash
PROJECT="$(cd "$(dirname "$0")" && pwd)/.."
MAIN="./bazel-bin/example/pagerank" # process name
WNUM=3
WCORES=8
#INPUT=${INPUT:="$PROJECT/data/graph/v100_e2150_ua_c3.csv"}
INPUT=${INPUT:="nebula:${PROJECT}/scripts/nebula.conf"}
#OUTPUT=${OUTPUT:='hdfs://192.168.8.149:9000/_test/output'}
OUTPUT=${OUTPUT:="nebula:$PROJECT/scripts/nebula.conf"}
IS_DIRECTED=${IS_DIRECTED:=true} # let plato auto add reversed edge or not
NEED_ENCODE=${NEED_ENCODE:=true}
VTYPE=${VTYPE:=uint32}
ALPHA=-1
PART_BY_IN=false
EPS=${EPS:=0.0001}
DAMPING=${DAMPING:=0.8}
ITERATIONS=${ITERATIONS:=5}
export MPIRUN_CMD=${MPIRUN_CMD:="${PROJECT}/3rd/mpich-3.2.1/bin/mpiexec.hydra"}
PARAMS+=" --threads ${WCORES}"
PARAMS+=" --input ${INPUT} --output ${OUTPUT} --is_directed=${IS_DIRECTED} --need_encode=${NEED_ENCODE} --vtype=${VTYPE}"
PARAMS+=" --iterations ${ITERATIONS} --eps ${EPS} --damping ${DAMPING}"
# env for JAVA && HADOOP
export LD_LIBRARY_PATH=${JAVA_HOME}/jre/lib/amd64/server:${LD_LIBRARY_PATH}
# env for hadoop
export CLASSPATH=${HADOOP_HOME}/etc/hadoop:`find ${HADOOP_HOME}/share/hadoop/ | awk '{path=path":"$0}END{print path}'`
export LD_LIBRARY_PATH="${HADOOP_HOME}/lib/native":${LD_LIBRARY_PATH}
chmod 777 ./${MAIN}
${MPIRUN_CMD} -n ${WNUM} -f ${PROJECT}/scripts/cluster ./${MAIN} ${PARAMS}
exit $?
参数说明
INPUT参数和OUPUT参数分别指定算法的输入数据源和输出数据源,目前支持本地 csv 文件、HDFS文件、 Nebula Graph。当输入输出数据源为 Nebula Graph 时,INPUT和OUPUT形式为nebula:/path/to/nebula.conf- WNUM 为集群所有机器所运行的进程数之和,推荐每台机器运行为 1 或者 NUMA node 数个进程,WCORE 为每个进程的线程数,推荐最大设置为机器的硬件线程数。
scripts/nebula.conf
## read/write
--retry=3 # 连接 Nebula Graph 时的重试次数
--space=sf30 # 要读取或写入的 space 名称
## read from nebula
--meta_server_addrs=192.168.8.94:9559 # Nebula Graph 的 metad 服务地址
--edge=LIKES # 要读取的边的名称
#--edge_data_field # 要读取的作为边的权重属性的名称
--read_batch_size=10000 # 每次 scan 时的 batch 的大小
## write to nebula
--graph_server_addrs=192.168.8.94:9669 # Nebula Graph 的 graphd 服务地址
--user=root # graphd 服务的登陆用户名
--password=nebula # graphd 服务的登陆密码
# insert or update
--mode=insert # 写回 Nebula Graph 时采用的模式: insert/update
--tag=pagerank # 写回到 Nebula Graph 的 tag 名称
--prop=pr # 写回到 Nebula Graph 的 tag 对应的属性名称
--type=double # 写回到 Nebula Graph 的 tag 对应的属性的类型
--write_batch_size=1000 # 写回时的 batch 大小
--err_file=/home/plato/err.txt # 写回失败的数据所存储的文件
scripts/cluster
cluster 文件指定要运行该算法所在的集群机器的 IP
192.168.15.3
192.168.15.5
192.168.15.6
以上为 Plato 在 Nebula Graph 中的应用,目前该功能集成在 Nebula Graph 企业版中,如果你使用的是开源版本的 Nebula Graph,需按照自己的需求自己对接 Plato。
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
{kind=link}
高性能图计算系统 Plato 在 Nebula Graph 中的实践的更多相关文章
- 分布式图数据库 Nebula Graph 的 Index 实践
导读 索引是数据库系统中不可或缺的一个功能,数据库索引好比是书的目录,能加快数据库的查询速度,其实质是数据库管理系统中一个排序的数据结构.不同的数据库系统有不同的排序结构,目前常见的索引实现类型如 B ...
- Nebula Graph 的 Ansible 实践
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow & 看大厂图数据库技术实践 背景 在 Nebula-Graph 的日常测试中,我们会经常在 ...
- 分布式图数据库 Nebula Graph 中的集群快照实践
1 概述 1.1 需求背景 图数据库 Nebula Graph 在生产环境中将拥有庞大的数据量和高频率的业务处理,在实际的运行中将不可避免的发生人为的.硬件或业务处理错误的问题,某些严重错误将导致集群 ...
- Nebula Graph 在网易游戏业务中的实践
本文首发于 Nebula Graph Community 公众号 当游戏上知识图谱,网易游戏是如何应对大规模图数据的管理问题,Nebula Graph 又是如何帮助网易游戏落地游戏内复杂的图的业务呢? ...
- 图数据库 Nebula Graph 的数据模型和系统架构设计
Nebula Graph:一个开源的分布式图数据库.作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,而且能够提供极高的 ...
- 图数据库 Nebula Graph TTL 特性
导读 身处在现在这个大数据时代,我们处理的数据量需以 TB.PB, 甚至 EB 来计算,怎么处理庞大的数据集是从事数据库领域人员的共同问题.解决这个问题的核心在于,数据库中存储的数据是否都是有效的.有 ...
- Nebula Graph 在微众银行数据治理业务的实践
本文为微众银行大数据平台:周可在 nMeetup 深圳场的演讲这里文字稿,演讲视频参见:B站 自我介绍下,我是微众银行大数据平台的工程师:周可,今天给大家分享一下 Nebula Graph 在微众银行 ...
- 解析 Nebula Graph 子图设计及实践
本文首发于 Nebula Graph 公众号 NebulaGraphCommunity,Follow 看大厂图数据库技术实践. 前言 在先前的 Query Engine 源码解析中,我们介绍了 2.0 ...
- 图数据库|基于 Nebula Graph 的 BetweennessCentrality 算法
本文首发于 Nebula Graph Community 公众号 在图论中,介数(Betweenness)反应节点在整个网络中的作用和影响力.而本文主要介绍如何基于 Nebula Graph 图数据 ...
- macOS 安装 Nebula Graph 看这篇就够了
本文首发于 Nebula Graph Community 公众号 背景 刚学习图数据的内容,当前网上充斥大量的安装文档,参差不齐,部署起来令人十分头疼. 现整理一份比较完整的安装文档,供大家学习参考, ...
随机推荐
- webservice--WSDL文件生成本地的代理类
我们在对应第三方接口时常用:项目上右键---->服务引用---->WCF Web Service,如下图的页面----->填好url后---->转到,就可以发现服务,生成代理类 ...
- TienChin 活动管理-修改活动
后端 ChannelController.java @PreAuthorize("hasPermission('tienchin:channel:edit')") @GetMapp ...
- 火遍外网的Keychron测评,带你入坑;ps马上5.20了送一个给你的心爱的她/他。
那些年用过的机械键盘 如果你经常上YouTube或Instagram,然后你又对键盘感兴趣,我相信你肯定看到过他--Keychron K2,他真的是一款曝光量很高的键盘. 1.键盘keychron k ...
- [XXL-JOB] 项目集成-Framework
1.导入pom坐标 <dependency> <groupId>com.hbasesoft.framework</groupId> <artifactId&g ...
- AnyCAD程序无法启动的问题解决方法
在某些电脑上会出现基于AnyCAD开发的程序无法启动的问题,如: System-ArgumentEcception: Please check the dependendes 解决方法 安装最新的VS ...
- XXE注入详解
XML介绍 XML全称可扩展标记语言(EXtensible Markup Language),XML跟HTML格式类似,但是作用不同,XML侧重于数据传输,HTML注重于标记语言,也就是说XML其实是 ...
- 复制对象句柄DuplicateHandle(文件占坑)
DuplicateHandle文档化解释 The DuplicateHandle function duplicates an object handle. The duplicate handle ...
- MySQL系列文章汇总
MySQL系列文章汇总: 导读: 大家好,我是xbhog,MySQL还是到了单独开一个系列了,这样不管是对我还是对读者来说在查找的时候都会方便一些: 话不多说,来看下,该系列会持续更新的(还是看学到哪 ...
- 2023 CSP-J/S游记
8.14 打了场 luogu 的 \(SCP\) ,给打没信心了. 8.16 普及模拟1 8.19 普及模拟2 8.22 普及模拟3 9.5 二调讲评结束后,和班主任说了考 \(CSP\) 的事情,就 ...
- NC17193 简单瞎搞题
题目链接 题目 题目描述 一共有 n个数,第 i 个数是 xi xi 可以取 [li , ri] 中任意的一个值. 设 \(S = \sum{{x_i}^2}\) ,求 S 种类数. 输入描述 第一行 ...