面试题——为什么 Vue 中不要用 index 作为 key?(diff 算法详解)
前言
在vue中使用v-for时需要,都会提示或要求使用 :key,有的的开发者会直接使用数组的 index 作为 key 的值,但不建议直接使用 index作为 key 的值,有时我们面试时也会遇到面试官问:为什么不推荐使用 index 作为 key ?接下来和小颖一起来瞅瞅吧
为什么要有 key
当 Vue 正在更新使用 v-for 渲染的元素列表时,它默认使用“就地更新”的策略。如果数据项的顺序被改变,Vue 将不会移动 DOM 元素来匹配数据项的顺序,而是就地更新每个元素,并且确保它们在每个索引位置正确渲染。这个类似 Vue 1.x 的 track-by="$index"。
这个默认的模式是高效的,但是只适用于不依赖子组件状态或临时 DOM 状态 (例如:表单输入值) 的列表渲染输出。
为了给 Vue 一个提示,以便它能跟踪每个节点的身份,从而重用和重新排序现有元素,你需要为每项提供一个唯一 key attribute:
key的作用
官网解释:key
预期:number | string | boolean (2.4.2 新增) | symbol (2.5.12 新增)
key 的特殊 attribute 主要用在 Vue 的虚拟 DOM 算法,在新旧 nodes 对比时辨识 VNodes。如果不使用 key,Vue 会使用一种最大限度减少动态元素并且尽可能的尝试就地修改/复用相同类型元素的算法。而使用 key 时,它会基于 key 的变化重新排列元素顺序,并且会移除 key 不存在的元素。
有相同父元素的子元素必须有独特的 key。重复的 key 会造成渲染错误。
通俗解释:
key 在 diff 算法的作用,就是用来判断是否是同一个节点。
Vue 中使用虚拟 dom 且根据 diff 算法进行新旧 DOM 对比,从而更新真实 dom ,key 是虚拟 DOM 对象的唯一标识, 在 diff 算法中 key 起着极其重要的作用,key可以管理可复用的元素,减少不必要的元素的重新渲染,也要让必要的元素能够重新渲染。
为什么key 值不建议用index?
性能消耗
使用 index 做 key,破坏顺序操作的时候, 因为每一个节点都找不到对应的 key,导致部分节点不能复用,所有的新 vnode 都需要重新创建。
示例:
<template>
<div class="hello">
<ul>
<li v-for="(item,index) in studentList" :key="index">{{ item.name }}</li>
</ul>
<br>
<button @click="addStudent">添加一条数据</button>
</div>
</template> <script>
export default {
name: 'ceshi',
data() {
return {
studentList: [
{id: 1, name: '张三', age: 18},
{id: 2, name: '李四', age: 19},
{id: 3, name: '王麻子', age: 20},
],
};
},
methods: {
addStudent() {
const studentObj = {id: 4, name: '王五', age: 20};
this.studentList = [studentObj, ...this.studentList]
}
}
}
</script>
打开浏览器的开发工具,修改数据的文本,后面加上 “-我没变”,点击添加一条数据 按钮,则发现dom整体都变了
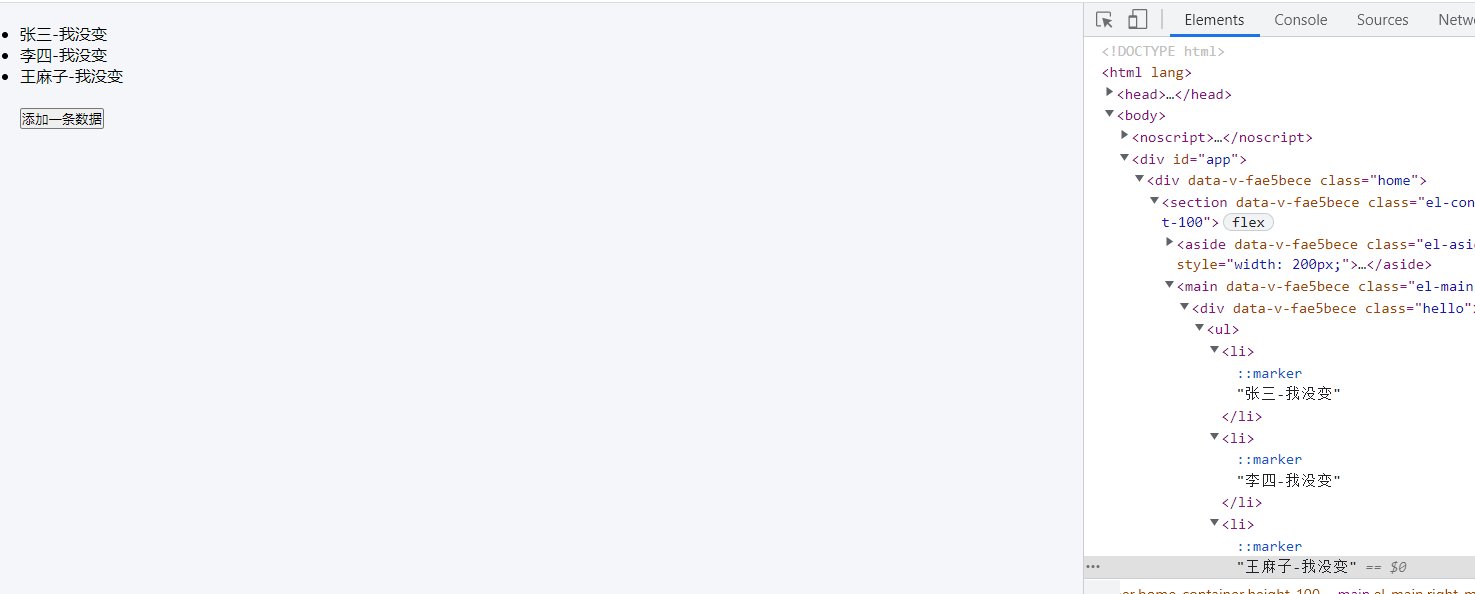

当给key绑定唯一不重复的值时:
<li v-for="item in studentList" :key="item.id">{{ item.name }}</li>
打开浏览器的开发工具,修改数据的文本,后面加上 “-我没变”,点击添加一条数据 按钮,则发现只是顶部多了一条,其他dom没有重新渲染。
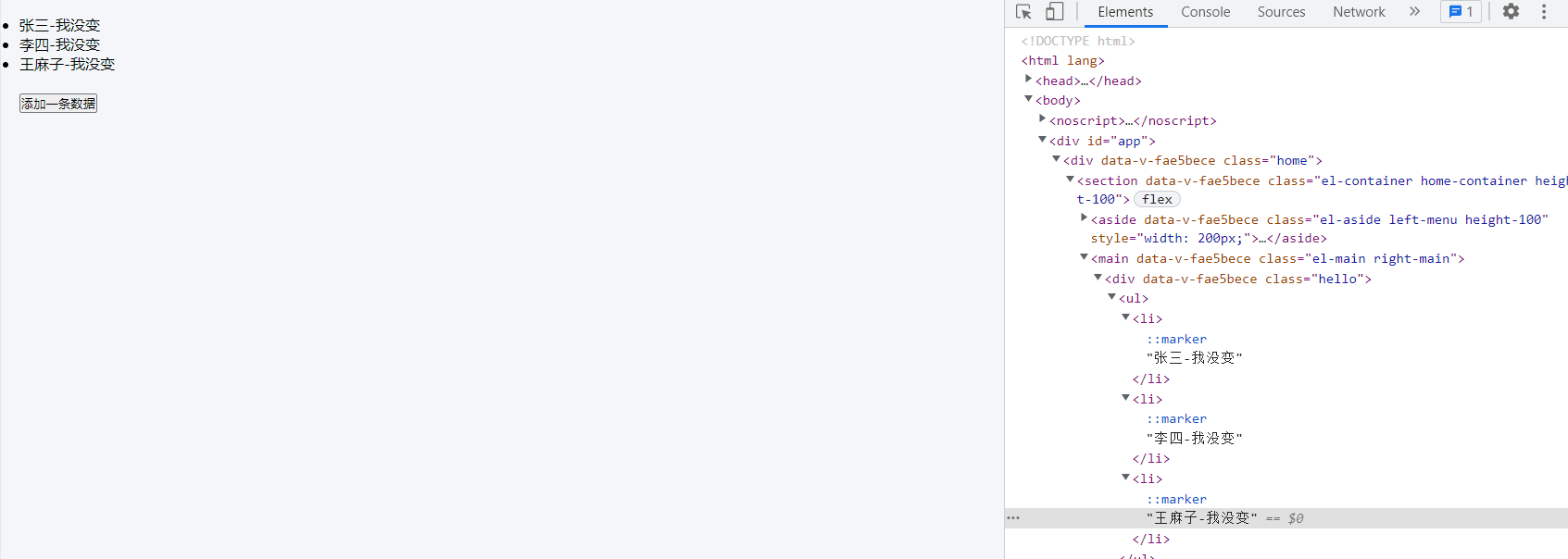
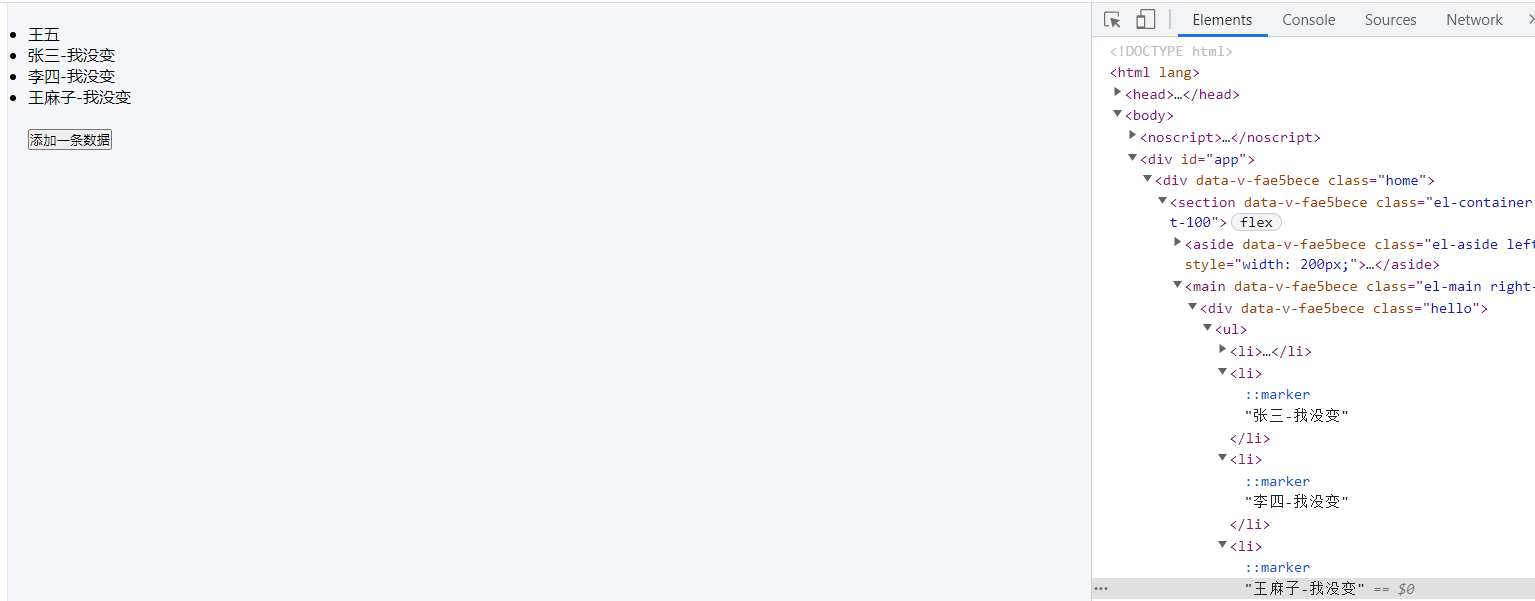
当用index做key时,当我们在前面加了一条数据时 index 顺序就会被打断,导致新节点 key 全部都改变了,所以导致我们页面上的数据都被重新渲染了。而用了不会重复的唯一标识id时,diff算法比较后发现只有头部有变化,其他没有变,则只给头部新增了一个元素。从上面比较可以看出,用唯一值作为 key 可以节约开销这样大家应该就明白了吧·················
数据错位
示例:
<template>
<div class="hello">
<ul>
<li v-for="item in studentList" :key="item.id">{{ item.name }}<input /></li>
</ul>
<br>
<button @click="addStudent">添加一条数据</button>
</div>
</template> <script>
export default {
name: 'ceshi',
data() {
return {
studentList: [
{id: 1, name: '张三', age: 18},
{id: 2, name: '李四', age: 19}
],
};
},
methods: {
addStudent() {
const studentObj = {id: 4, name: '王五', age: 20};
this.studentList = [studentObj, ...this.studentList]
}
}
}
</script>
我们往 input 里面输入一些值,添加一位同学看下效果:
这时候我们就会发现,在添加之前输入的数据错位了。添加之后王五的输入框残留着张三的信息,这很显然不是我们想要的结果。
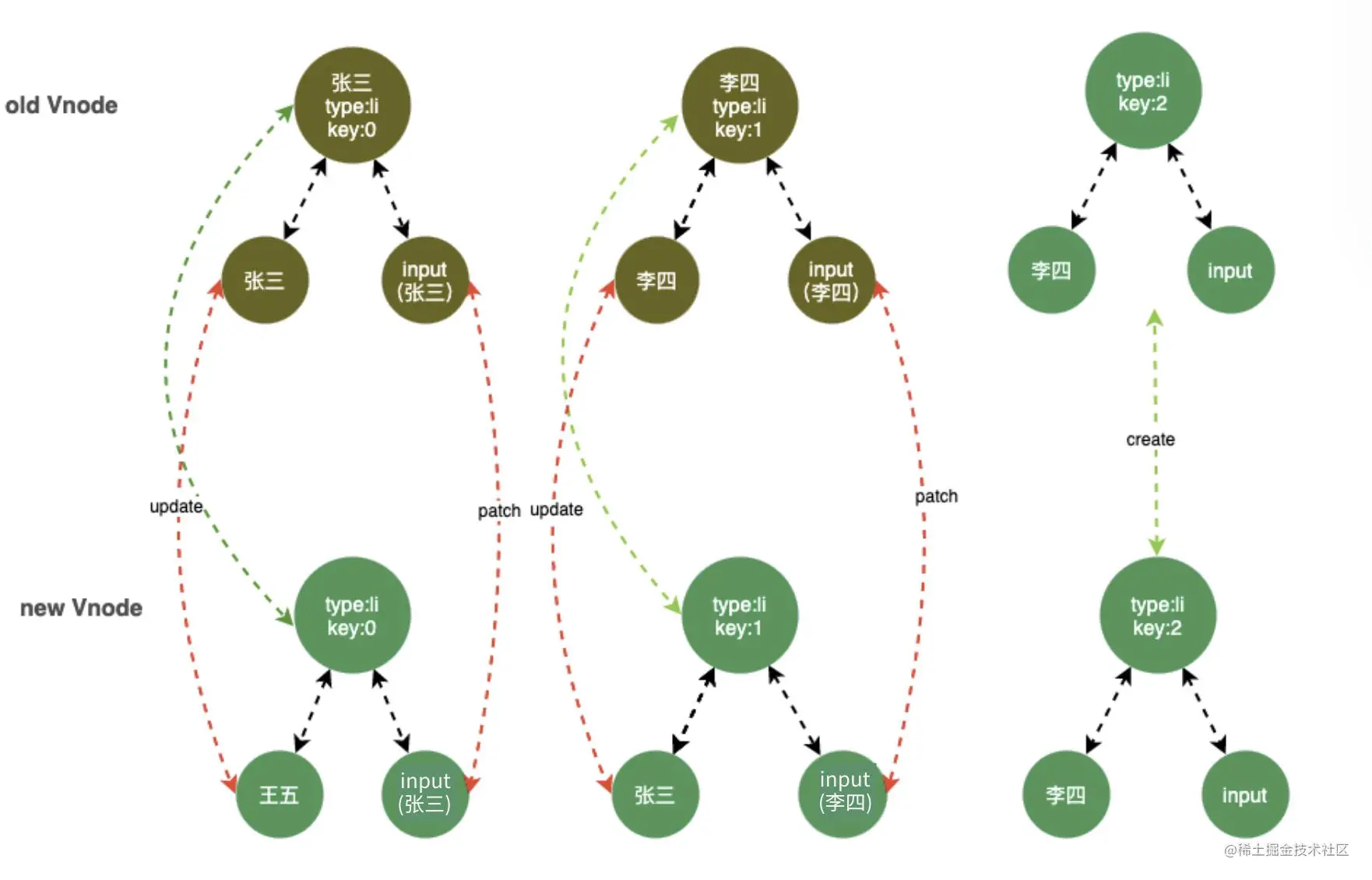
从上面比对可以看出来这时因为采用 index 作为 key 时,当在比较时,发现虽然文本值变了,但是当继续向下比较时发现 DOM 节点还是和原来一摸一样,就复用了,但是没想到 input 输入框残留输入的值,这时候就会出现输入的值出现错位的情况
当我们将key绑定为唯一标识id时,如图所示。key 相同的节点都做到了复用。起到了diff 算法的真正作用。

总结:
- 用 index 作为 key 时,在对数据进行,逆序添加,逆序删除等破坏顺序的操作时,会产生没必要的真实 DOM更新,从而导致效率低
- 用 index 作为 key 时,如果结构中包含输入类的 DOM,会产生错误的 DOM 更新
- 在开发中最好每条数据使用唯一标识固定的数据作为 key,比如后台返回的 ID,手机号,身份证号等唯一值
- 如果不对数据进行逆序添加 逆序删除破坏顺序的操作, 只用于列表展示的话 使用index 作为Key没有毛病
相关内容
为什么要提出虚拟DOM
简而言之呢
附加面试题:
虚拟DOM是什么
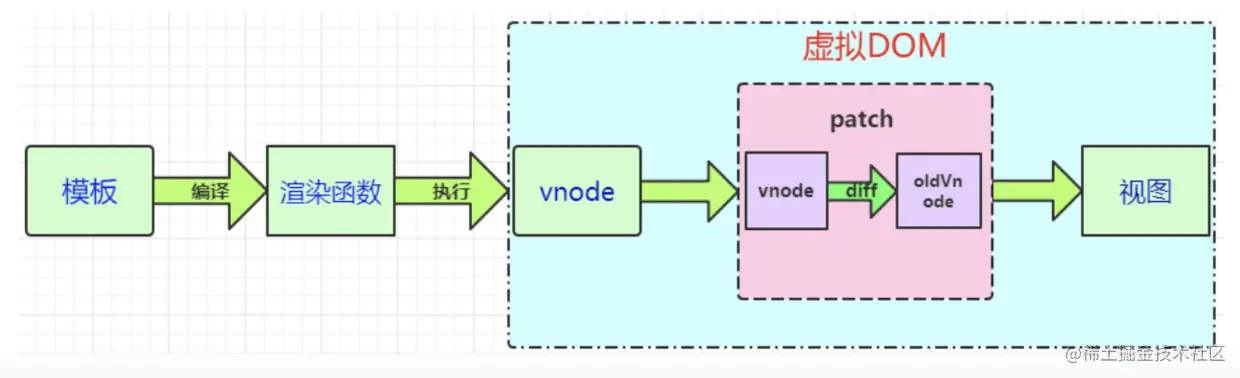
Vue.js通过编译将模版转换成渲染函数(render),执行渲染函数就可以得到一个以vnode节点(JavaScript对象)作为基础的树形结构,vnode节点里面包含标签名(tag)、属性(attrs)和子元素对象(children)等等属性,这个树形结构就是Virtual DOM,简单来说,可以把Virtual DOM理解为一个树形结构的JS对象。
参考: 浅谈Vue中的虚拟DOM
简而言之 虚拟DON就是javascript对象,通过对虚拟 DOM进行diff,算出最小差异,然后更新真实的DOM。
虚拟DOM的优势
- 提供一种方便的工具,使得开发效率得到保证
- 保证最小化的DOM操作,使得执行效率得到保证
- 具备跨平台的优势 由于 Virtual DOM 是以 JavaScript 对象为基础而不依赖真实平台环境,所以使它具有了跨平台的能力,比如说浏览器平台、Weex、Node 等。
- 提升渲染性能 Virtual DOM的优势不在于单次的操作,而是在大量、频繁的数据更新下,能够对视图进行合理、高效的更新
为什么虚拟DOM可以提高渲染速度
- 根据虚拟dom树最初渲染成真实dom
- 当数据变化,或者说是页面需要重新渲染的时候,会重新生成一个新的完整的虚拟dom
- 拿新的虚拟dom来和旧的虚拟dom做对比(使用diff算法)。得到需要更新的地方之后,从而只对发生了变化的节点进行更新操作。
如果大家不太明白的话,我们来看个示例
<template>
<div class="hello">
<ul>
<li v-for="(item,index) in studentList" :key="item.id" @click="changeName(index)">{{ item.name }}</li>
</ul>
</div>
</template> <script>
export default {
name: 'ceshi',
data() {
return {
studentList: [
{id: 1, name: '张三', age: 18},
{id: 2, name: '李四', age: 19},
{id: 3, name: '王麻子', age: 20},
],
};
},
methods: {
changeName(index) {
this.studentList[index].name = '我变啦'
}
}
}
</script>
上面的修改数组值得方式 仅在 2.2.0+ 版本中支持 Array + index 用法。
如果使用之前的则使用 Vue.set( target, propertyName/index, value )
运行后,我们打开开发者工具,然后手动修改页面的文本,给每个后面加 “-我没变”
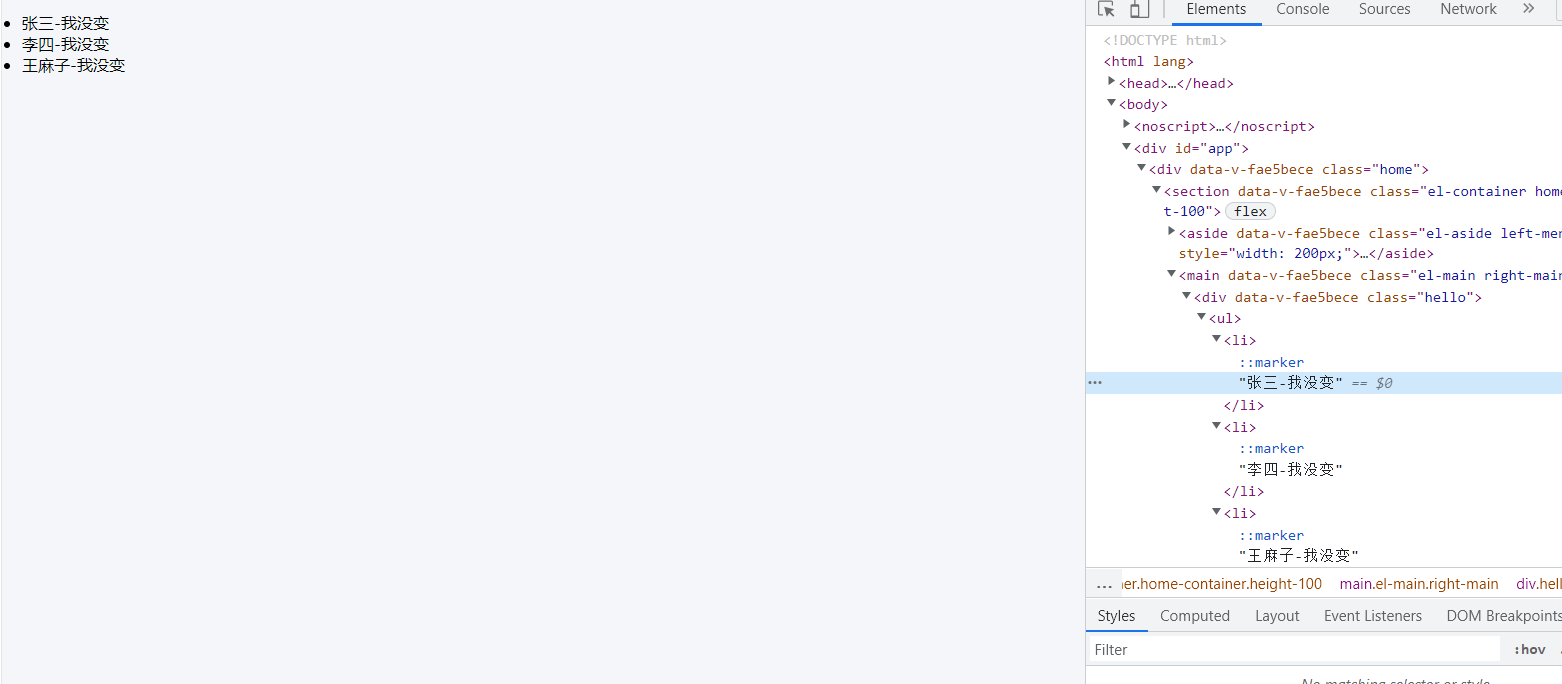
然后随便点击其中一个,我们会发现只有点击那个文本变了,并且只是它的文本内容变了,dom并没有整体变。

vue中是如何实现模板转换成视图的
参考: 浅谈Vue中的虚拟DOM
简单来说就是:通过编译将模版转换成渲染函数(render),执行渲染函数就可以得到一个以vnode节点(JavaScript对象)作为基础的树形结构(虚拟dom),当数据发生变化虚拟dm通过diff算法找出新树和旧树的不同,记录两棵树差异根据差异应用到所构建的真正的DOM树上,视图就更新。
diff算法
虚拟DOM中,在DOM的状态发生变化时,虚拟DOM会进行Diff运算,来更新只需要被替换的DOM,而不是全部重绘。 在Diff算法中,只平层的比较前后两棵DOM树的节点,没有进行深度的遍历。
规则
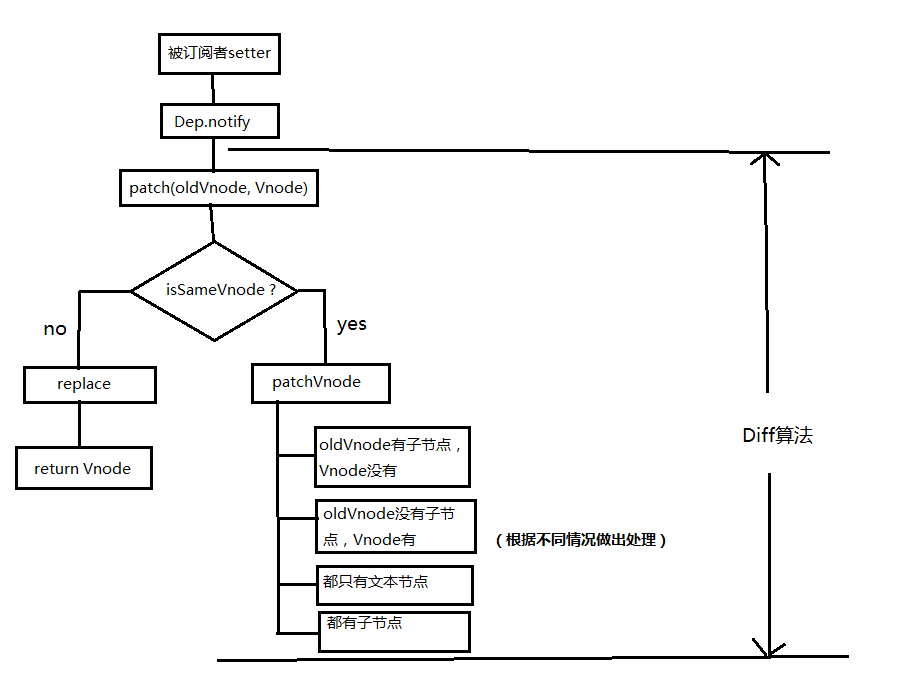
同层比较,如上面div的Old Vnode,跟其Vnode比较,div只会跟同层div比较,不会跟p进行比较,下面是示例图:

流程图
当数据发生改变时,set方法会让调用Dep.notify通知所有订阅者Watcher,订阅者就会调用patch给真实的DOM打补丁,更新相应的视图。
具体分析
patch
来看看patch是怎么打补丁的(代码只保留核心部分)
function patch (oldVnode, vnode) {
// some code
if (sameVnode(oldVnode, vnode)) {
patchVnode(oldVnode, vnode)
} else {
const oEl = oldVnode.el // 当前oldVnode对应的真实元素节点
let parentEle = api.parentNode(oEl) // 父元素
createEle(vnode) // 根据Vnode生成新元素
if (parentEle !== null) {
api.insertBefore(parentEle, vnode.el, api.nextSibling(oEl)) // 将新元素添加进父元素
api.removeChild(parentEle, oldVnode.el) // 移除以前的旧元素节点
oldVnode = null
}
}
// some code
return vnode
}
patch函数接收两个参数oldVnode和Vnode分别代表新的节点和之前的旧节点
- 判断两节点是否值得比较,值得比较则执行
patchVnodefunction sameVnode (a, b) {
return (
a.key === b.key && // key值
a.tag === b.tag && // 标签名
a.isComment === b.isComment && // 是否为注释节点
// 是否都定义了data,data包含一些具体信息,例如onclick , style
isDef(a.data) === isDef(b.data) &&
sameInputType(a, b) // 当标签是<input>的时候,type必须相同
)
} - 不值得比较则用
Vnode替换oldVnode
如果两个节点都是一样的,那么就深入检查他们的子节点。如果两个节点不一样那就说明Vnode完全被改变了,就可以直接替换oldVnode。
虽然这两个节点不一样但是他们的子节点一样怎么办?别忘了,diff可是逐层比较的,如果第一层不一样那么就不会继续深入比较第二层了。(我在想这算是一个缺点吗?相同子节点不能重复利用了...)
patchVnode
当我们确定两个节点值得比较之后我们会对两个节点指定patchVnode方法。那么这个方法做了什么呢?
patchVnode (oldVnode, vnode) {
const el = vnode.el = oldVnode.el
let i, oldCh = oldVnode.children, ch = vnode.children
if (oldVnode === vnode) return
if (oldVnode.text !== null && vnode.text !== null && oldVnode.text !== vnode.text) {
api.setTextContent(el, vnode.text)
}else {
updateEle(el, vnode, oldVnode)
if (oldCh && ch && oldCh !== ch) {
updateChildren(el, oldCh, ch)
}else if (ch){
createEle(vnode) //create el's children dom
}else if (oldCh){
api.removeChildren(el)
}
}
}
这个函数做了以下事情:
- 找到对应的真实dom,称为
el - 判断
Vnode和oldVnode是否指向同一个对象,如果是,那么直接return - 如果他们都有文本节点并且不相等,那么将
el的文本节点设置为Vnode的文本节点。 - 如果
oldVnode有子节点而Vnode没有,则删除el的子节点 - 如果
oldVnode没有子节点而Vnode有,则将Vnode的子节点真实化之后添加到el - 如果两者都有子节点,则执行
updateChildren函数比较子节点,这一步很重要
参考:详解vue的diff算法
updataChildren原理
面试题——为什么 Vue 中不要用 index 作为 key?(diff 算法详解)的更多相关文章
- 均值、中值、高斯、non-local means算法详解
文章仅为个人理解,如有不妥之处欢迎指正. 写几个常见的图像去噪滤波器. 1.均值滤波器 均值滤波器是最简单的图像平滑滤波器,其3*3的模板为 1 9 [ 1 1 1 1 1 1 1 1 1 ] \fr ...
- 算法进阶面试题01——KMP算法详解、输出含两次原子串的最短串、判断T1是否包含T2子树、Manacher算法详解、使字符串成为最短回文串
1.KMP算法详解与应用 子序列:可以连续可以不连续. 子数组/串:要连续 暴力方法:逐个位置比对. KMP:让前面的,指导后面. 概念建设: d的最长前缀与最长后缀的匹配长度为3.(前缀不能到最后一 ...
- 转载~kxcfzyk:Linux C语言多线程库Pthread中条件变量的的正确用法逐步详解
Linux C语言多线程库Pthread中条件变量的的正确用法逐步详解 多线程c语言linuxsemaphore条件变量 (本文的读者定位是了解Pthread常用多线程API和Pthread互斥锁 ...
- Android中Intent传值与Bundle传值的区别详解
Android中Intent传值与Bundle传值的区别详解 举个例子我现在要从A界面跳转到B界面或者C界面 这样的话 我就需要写2个Intent如果你还要涉及的传值的话 你的Intent就要写两 ...
- ORACLE中RECORD、VARRAY、TABLE的使用详解(转)
原文地址:ORACLE中RECORD.VARRAY.TABLE的使用详解
- Java集合中List,Set以及Map等集合体系详解
转载请注明出处:Java集合中List,Set以及Map等集合体系详解(史上最全) 概述: List , Set, Map都是接口,前两个继承至collection接口,Map为独立接口 Set下有H ...
- 对python3中pathlib库的Path类的使用详解
原文连接 https://www.jb51.net/article/148789.htm 1.调用库 ? 1 from pathlib import 2.创建Path对象 ? 1 2 3 4 5 ...
- Python的Django框架中forms表单类的使用方法详解
用户表单是Web端的一项基本功能,大而全的Django框架中自然带有现成的基础form对象,本文就Python的Django框架中forms表单类的使用方法详解. Form表单的功能 自动生成HTML ...
- Oracle中的SQL分页查询原理和方法详解
Oracle中的SQL分页查询原理和方法详解 分析得不错! http://blog.csdn.net/anxpp/article/details/51534006
- javascript 中合并排序算法 详解
javascript 中合并排序算法 详解 我会通过程序的执行过程来给大家合并排序是如何排序的... 合并排序代码如下: <script type="text/javascript& ...
随机推荐
- python中的注释noqa: F401
在Python中,"noqa: F401" 是一个特殊的注释指示.它主要用于在静态代码检查工具(例如Flake8)运行时,告知工具忽略特定的 "F401" 错误 ...
- 一个可将执行文件打包成Windows服务的.Net开源工具
Windows服务一种在后台持续运行的程序,它可以在系统启动时自动启动,并在后台执行特定的任务,例如监视文件系统.管理硬件设备.执行定时任务等. 今天推荐一个可将执行文件打包成Windows 服务的工 ...
- 【Hexo】NexT 主题的配置使用记录
目录 简介 版本 安装 配置记录 风格/主题 网页图标 菜单栏 侧边栏 本地搜索 代码块 动画效果 阅读进度 书签 Mermaid lazyload fancybox pangu 捐赠 版权声明 不蒜 ...
- 【日常踩坑】从 SSLEOFError 到正确配置 Proxy
目录 踩坑 代理服务器 普通的代理服务器 因国家法律规定,部分内容已删除,完整内容请查看文章末尾链接 代理配置 追根溯源 urllib3 pip 万恶之源 urllib 参考资料 本文主要参考 Pyt ...
- WebAPI接口文档快速编写
近期项目使用了WebAPI,需要先给出接口文档,本着能省事就省事的原则,自然最好是能找到自动生成文档的方式. 一.使用Apifox,官网写着这是个API一体化协作平台,说白了,对于我来说,这就是个测试 ...
- 升讯威在线客服系统的并发高性能数据处理技术:PLINQ并行查询技术
我在业余时间开发维护了一款免费开源的升讯威在线客服系统,也收获了许多用户.对我来说,只要能获得用户的认可,就是我最大的动力. 最近客服系统成功经受住了客户现场组织的压力测试,获得了客户的认可. 客户组 ...
- @RequiredArgsConstructor和@Authwired
我们在java后端书写接口时,对service层成员变量的注入和使用有以下两种实现方式: 1) @RequiredArgsConstructor import lombok.RequiredArgsC ...
- angular + express 实现websocket通信
最近需要实现一个功能,后端通过TCP协议连接雷达硬件的控制器,前端通过websocket连接后端,当控制器触发消息的时候,把信息通知给所以前端: 第一个思路是单独写一个后端服务用来实现websocke ...
- Rethinking Point Cloud Registration as Masking and Reconstruction论文阅读
Rethinking Point Cloud Registration as Masking and Reconstruction 2023 ICCV *Guangyan Chen, Meiling ...
- jmeter生成随机英文的几种方法
第一种:用BeanShell后置处理程序 1.写脚本 import java.util.Random; String random(int s_length) { strings= &qu ...