Storm 集群的搭建及其Java编程进行简单统计计算
一、Storm集群构建
编写storm 与 zookeeper的yml文件
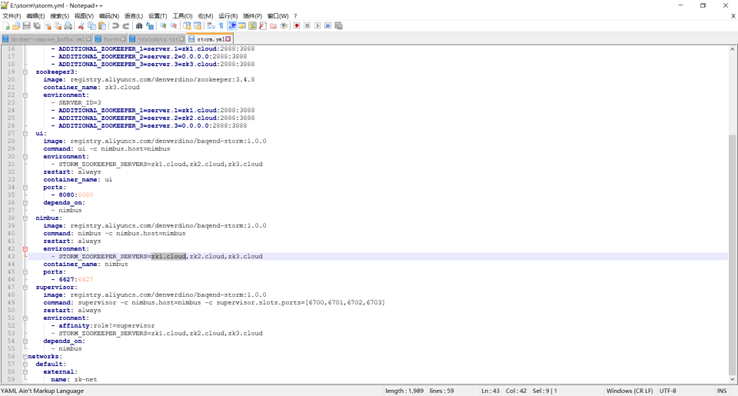
storm yml文件的编写
具体如下:
version: '2'
services:
zookeeper1:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk1.cloud
environment:
- SERVER_ID=1
- ADDITIONAL_ZOOKEEPER_1=server.1=0.0.0.0:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=zk2.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=zk3.cloud:2888:3888
zookeeper2:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk2.cloud
environment:
- SERVER_ID=2
- ADDITIONAL_ZOOKEEPER_1=server.1=zk1.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=0.0.0.0:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=zk3.cloud:2888:3888
zookeeper3:
image: registry.aliyuncs.com/denverdino/zookeeper:3.4.8
container_name: zk3.cloud
environment:
- SERVER_ID=3
- ADDITIONAL_ZOOKEEPER_1=server.1=zk1.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_2=server.2=zk2.cloud:2888:3888
- ADDITIONAL_ZOOKEEPER_3=server.3=0.0.0.0:2888:3888
ui:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: ui -c nimbus.host=nimbus
environment:
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
restart: always
container_name: ui
ports:
- 8080:8080
depends_on:
- nimbus
nimbus:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: nimbus -c nimbus.host=nimbus
restart: always
environment:
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
container_name: nimbus
ports:
- 6627:6627
supervisor:
image: registry.aliyuncs.com/denverdino/baqend-storm:1.0.0
command: supervisor -c nimbus.host=nimbus -c supervisor.slots.ports=[6700,6701,6702,6703]
restart: always
environment:
- affinity:role!=supervisor
- STORM_ZOOKEEPER_SERVERS=zk1.cloud,zk2.cloud,zk3.cloud
depends_on:
- nimbus
networks:
default:
external:
name: zk-net
拉取Storm搭建需要的镜像,这里我选择镜像版本为 zookeeper:3.4.8 storm:1.0.0
键入命令:
docker pull zookeeper:3.4.8 docker pull storm:1.0.0
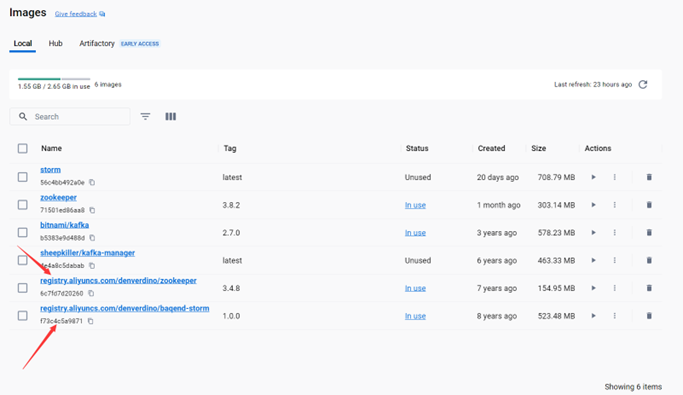
storm镜像 获取
使用docker-compose 构建集群
在power shell中执行以下命令:
docker-compose -f storm.yml up -d
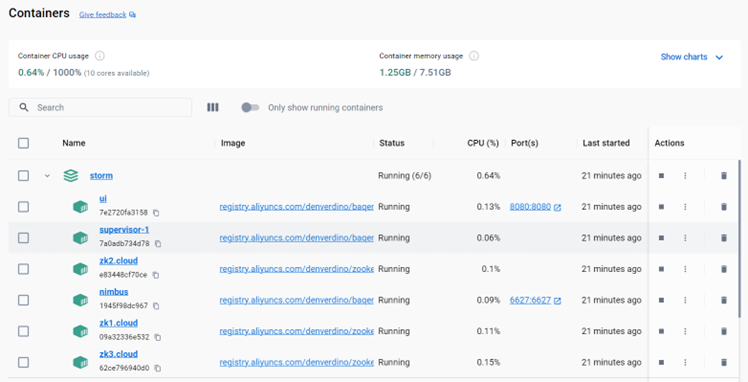
docker-compose 构建集群
在浏览器中打开localhost:8080 可以看到storm集群的详细情况
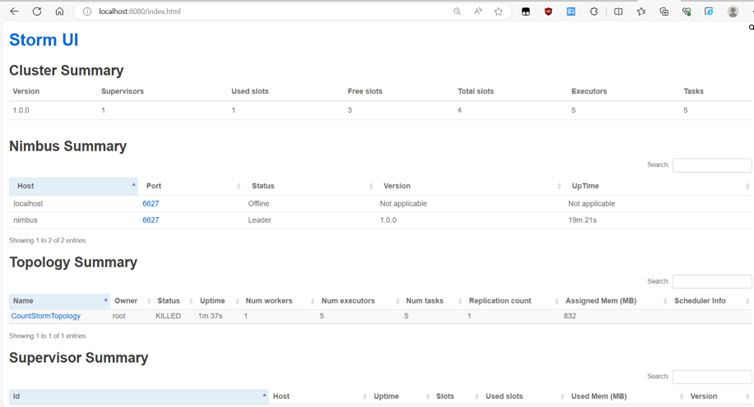
storm UI 展示
二、Storm统计任务
统计股票交易情况交易量和交易总金额 (数据文件存储在csv文件中)
编写DataSourceSpout类
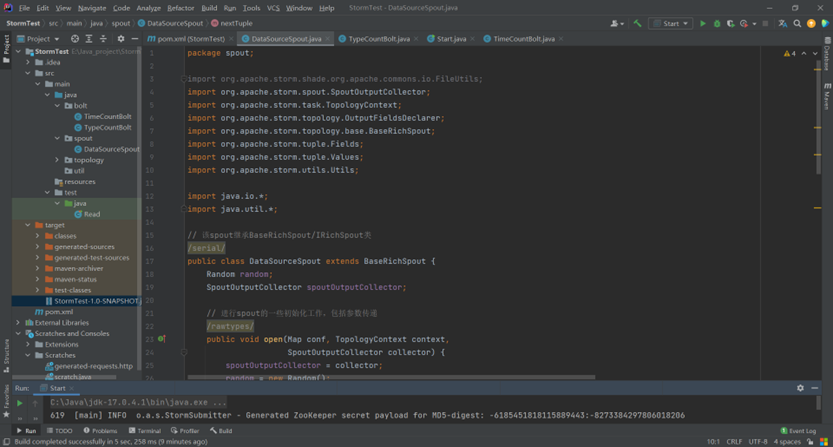
DataSourceSpout类
编写bolt类
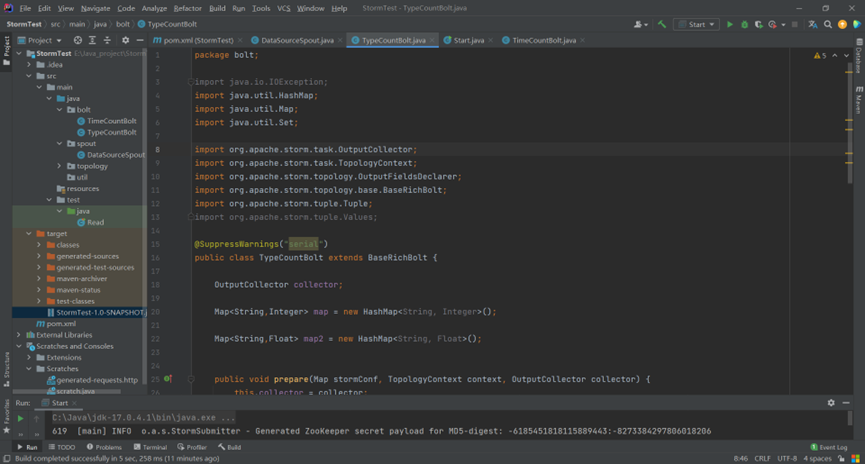
编写topology类
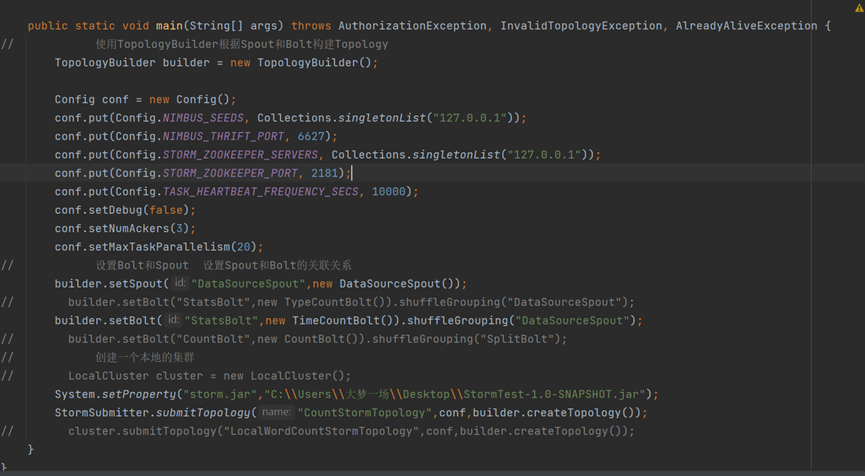
需要注意的是 Storm Java API 下有本地模型和远端模式
在本地模式下的调试不依赖于集群环境,可以进行简单的调试
如果需要使用生产模式,则需要将
1、 编写和自身业务相关的spout和bolt类,并将其打包成一个jar包
2、将上述的jar包放到客户端代码能读到的任何位置,
3、使用如下方式定义一个拓扑(Topology)
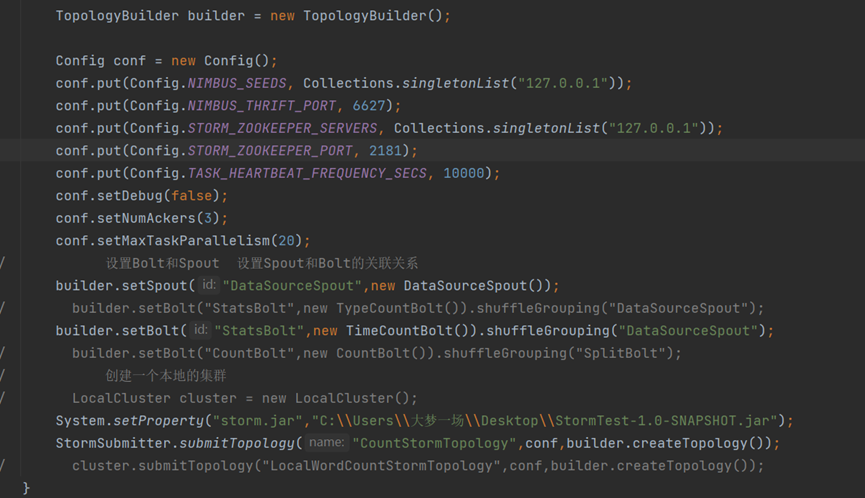
演示结果:
本地模式下的调试:
正在执行:
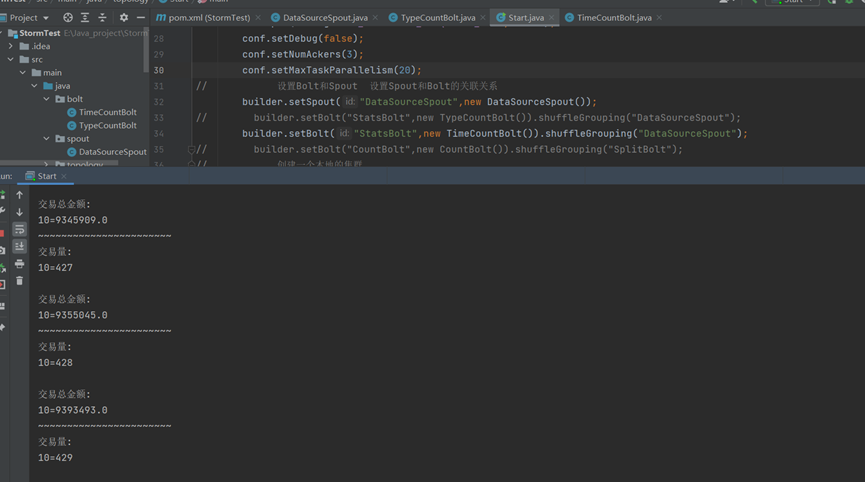
根据24小时
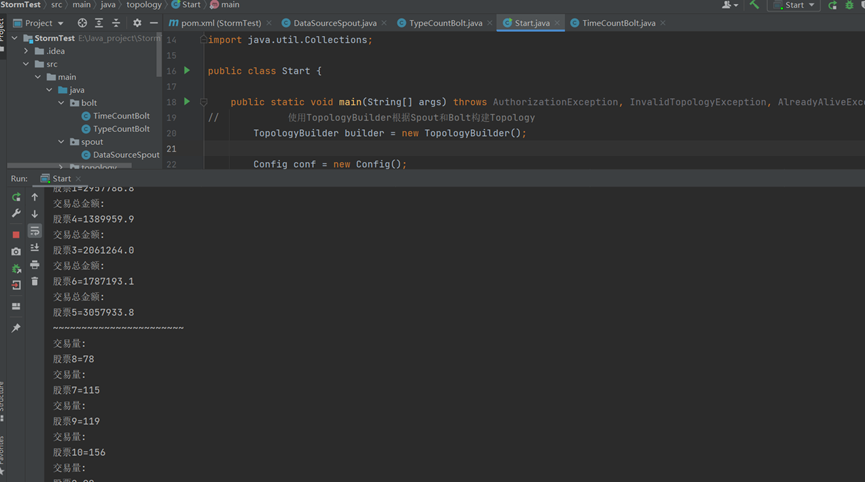
根据股票种类
生产模式:

向集群提交topology
三、核心计算bolt的代码
1.统计不同类型的股票交易量和交易总金额:
package bolt;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
@SuppressWarnings("serial")
public class TypeCountBolt extends BaseRichBolt {
OutputCollector collector;
Map<String,Integer> map = new HashMap<String, Integer>();
Map<String,Float> map2 = new HashMap<String, Float>();
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] data = line.split(",");
Integer count = map.get(data[2]);
Float total_amount = map2.get(data[2]);
if(count==null){
count = 0;
}
if(total_amount==null){
total_amount = 0.0f;
}
count++;
total_amount+=Float.parseFloat(data[3]) * Integer.parseInt(data[4]);
map.put(data[2],count);
map2.put(data[2],total_amount);
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~");
Set<Map.Entry<String,Integer>> entrySet = map.entrySet();
for(Map.Entry<String,Integer> entry :entrySet){
System.out.println("交易量:");
System.out.println(entry);
}
System.out.println();
Set<Map.Entry<String,Float>> entrySet2 = map2.entrySet();
for(Map.Entry<String,Float> entry :entrySet2){
System.out.println("交易总金额:");
System.out.println(entry);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
2. 统计不同每个小时的交易量和交易总金额
package bolt;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.HashMap;
import java.util.Map;
import java.util.Set;
public class TimeCountBolt extends BaseRichBolt {
OutputCollector collector;
Map<Integer,Integer> map = new HashMap<Integer, Integer>();
Map<Integer,Float> map2 = new HashMap<Integer, Float>();
public void prepare(Map stormConf, TopologyContext context, OutputCollector collector) {
this.collector = collector;
}
public void execute(Tuple input) {
String line = input.getStringByField("line");
String[] data = line.split(",");
Date date = new Date();
SimpleDateFormat dateFormat= new SimpleDateFormat("yyyy-MM-dd hh:mm:ss");
try {
date = dateFormat.parse(data[0]);
} catch (ParseException e) {
e.printStackTrace();
}
Integer count = map.get(date.getHours());
Float total_amount = map2.get(date.getHours());
if(count==null){
count = 0;
}
if(total_amount==null){
total_amount = 0.0f;
}
count++;
total_amount+=Float.parseFloat(data[3]) * Integer.parseInt(data[4]);
map.put(date.getHours(),count);
map2.put(date.getHours(),total_amount);
System.out.println("~~~~~~~~~~~~~~~~~~~~~~~");
Set<Map.Entry<Integer,Integer>> entrySet = map.entrySet();
for(Map.Entry<Integer,Integer> entry :entrySet){
System.out.println("交易量:");
System.out.println(entry);
}
System.out.println();
Set<Map.Entry<Integer,Float>> entrySet2 = map2.entrySet();
for(Map.Entry<Integer,Float> entry :entrySet2){
System.out.println("交易总金额:");
System.out.println(entry);
}
}
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
Storm 集群的搭建及其Java编程进行简单统计计算的更多相关文章
- 【Hadoop离线基础总结】zookeeper的介绍以及集群环境搭建、网络编程和RPC的简单了解
ZooKeeper的介绍以及集群环境搭建.网络编程和RPC的简单了解 ZooKeeper介绍 概述 ZooKeeper是一个分布式协调服务的开源框架,主要用来解决分布式集群中应用系统的一致性问题.例如 ...
- 一:Storm集群环境搭建
第一:storm集群环境准备及部署[1]硬件环境准备--->机器数量>=3--->网卡>=1--->内存:尽可能大--->硬盘:无额外需求[2]软件环境准备---& ...
- 大数据处理框架之Strom:Storm集群环境搭建
搭建环境 Red Hat Enterprise Linux Server release 7.3 (Maipo) zookeeper-3.4.11 jdk1.7.0_80 Pyth ...
- Storm —— 集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 学习之路(四)—— Storm集群环境搭建
一.集群规划 这里搭建一个3节点的Storm集群:三台主机上均部署Supervisor和LogViewer服务.同时为了保证高可用,除了在hadoop001上部署主Nimbus服务外,还在hadoop ...
- Storm 系列(四)—— Storm 集群环境搭建
一.集群规划 这里搭建一个 3 节点的 Storm 集群:三台主机上均部署 Supervisor 和 LogViewer 服务.同时为了保证高可用,除了在 hadoop001 上部署主 Nimbus ...
- storm集群环境搭建
1.环境 Java环境 卸载虚机环境中自带的openJdk,安装sun的jdk,配置环境变量 2.安装storm 下载storm安装包 解压到安装目录,配置环境变量 vi /etc/profile # ...
- storm集群快速搭建
sudo mkdir /export/serverssudo chmod -R 777 /exportmkdir /export/servers tar -zxvf apache-storm-1.0. ...
- Storm集群的搭建
storm的环境和hadoop的环境没有任何关系 1.安装Zookeeper集群 2.解压storm 3.修改文件conf/storm.yaml 3.1.配置zookeeper服务器 storm.zo ...
- centos7:storm集群环境搭建
1.安装storm 下载storm安装包 在线下载 wget http://apache.fayea.com/storm/apache-storm-1.1.1/apache-storm-1.1.1.t ...
随机推荐
- 一次Python本地cache不当使用导致的内存泄露
背景 近期一个大版本上线后,Python编写的api主服务使用内存有较明显上升,服务重启后数小时就会触发机器的90%内存占用告警,分析后发现了本地cache不当使用导致的一个内存泄露问题,这里记录一下 ...
- Adapter 适配器模式简介与 C# 示例【结构型1】【设计模式来了_6】
〇.简介 1.什么是适配器模式? 一句话解释: 两个无关联的类,通过实现同一接口或继承对方得到新的适配器类,新的适配器类中通过实现原本类的操作,可达到进行相同的操作的目的. 适配器模式(Apapt ...
- java循环自动生成简单图片
import java.awt.*; import java.awt.font.FontRenderContext; import java.awt.geom.Rectangle2D; import ...
- 「にちじょう記録」MTIDnWtMOA
Mistakes That I Don't Want to Make Once Again. // Caution // 差分 / 前缀和后注意询问区间端点有变化-- 不要考虑了右边界就不考虑左边界 ...
- Teamcenter RAC 开发之《Excel模版导出》
背景 在做 Teamcenter RAC客制化表单后,TMD肯定有一个需求要导出表单,毕竟所谓的客制化表单就是从纸质表单中出来的,那么写代码必不可少......... 那么问题来了,对于一个Excel ...
- Strimzi Kafka Bridge(桥接)实战之一:简介和部署
欢迎访问我的GitHub 这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos 关于<Strimzi Kafka Bridge( ...
- TrueUpdate白加黑木马分析保姆级教程
目录 TrueUpdate白加黑木马分析保姆级教程 0x00:前言 TrueUpdate是什么? 0x01: TrueUpdate逆向分析解压密码 查壳 脱壳 分金定穴 找到解压密码方法1: 找到解压 ...
- ContextWrapper
/* * Copyright (C) 2006 The Android Open Source Project * * Licensed under the Apache License, Versi ...
- visio 2010 kit tools
Getting Office License Configuration Information.---------------------------------------Backing Up L ...
- WPF 中引入依赖注入(.NET 通用主机)
WPF 中引入依赖注入(.NET 通用主机) 在网上看到的文章都是通过 App.cs 中修改配置进行的,这样侵入性很高而且服务主机是通过 App 启动时加载的而不是服务主机加载的 App 有一点违反原 ...