启发式搜索(heuristic search)———A*算法
在宽度优先和深度优先搜索里面,我们都是根据搜索的顺序依次进行搜索,可以称为盲目搜索,搜索效率非常低。
而启发式搜索则大大提高了搜索效率,由这两张图可以看出它们的差别:
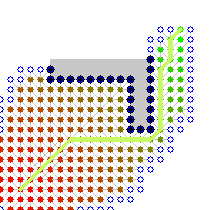 (左图类似与盲搜,右图为启发式搜索)(图片来源)
(左图类似与盲搜,右图为启发式搜索)(图片来源) 
很明显启发式的搜索效率远远大于盲搜。
什么是启发式搜索(heuristic search)
利用当前与问题有关的信息作为启发式信息,这些信息是能够提升查找效率以及减少查找次数的。
如何使用这些信息,我们定义了一个估价函数 h(x) 。h(x)是对当前状态x的一个估计,表示 x状态到目标状态的距离。
有:1、h(x) >= 0 ; 2、h(x)越小表示 x 越接近目标状态; 3、如果 h(x) ==0 ,说明达到目标状态。
与问题相关的启发式信息都被计算为一定的 h(x) 的值,引入到搜索过程中。
然而,有了启发式信息还不行,还需要起始状态到 x 状态所花的代价,我们称为 g(x) 。比如在走迷宫问题、八数码问题,我们的 g(x) 就是从起点到 x 位置花的步数 ,h(x) 就是与目标状态的曼哈顿距离或者相差的数目;在最短路径中,我们的 g(x) 就是到 x 点的权值,h(x) 就是 x 点到目标结点的最短路或直线距离。
现在,从 h(x) 和 g(x) 的定义中不能看出,假如我们搜索依据为 F(x) 函数。
当 F(x) = g(x) 的时候就是一个等代价搜索,完全是按照花了多少代价去搜索。比如 bfs,我们每次都是从离得近的层开始搜索,一层一层搜 ;以及dijkstra算法,也是依据每条边的代价开始选择搜索方向。
当F(x) = h(x) 的时候就相当于一个贪婪优先搜索。每次都是向最靠近目标的状态靠近。
人们发现,等代价搜索虽然具有完备性,能找到最优解,但是效率太低。贪婪优先搜索不具有完备性,不一定能找到解,最坏的情况下类似于dfs。
这时候,有人提出了A算法。令F(x) = g(x) + h(x) 。(这里的 h(x) 没有限制)。虽然提高了算法效率,但是不能保证找到最优解,不适合的 h(x)定义会导致算法找不到解。不具有完备性和最优性。
几年后有人提出了 A*算法。该算法仅仅对A算法进行了小小的修改。并证明了当估价函数满足一定条件,算法一定能找到最优解。估价函数满足一定条件的算法称为A*算法。
它的限制条件是 F(x) = g(x) + h(x) 。 代价函数g(x) >0 ;h(x) 的值不大于x到目标的实际代价 h*(x) 。即定义的 h(x) 是可纳的,是乐观的。
怎么理解第二个条件呢?
打个比方:你要从x走到目的地,那么 h(x) 就是你感觉或者目测大概要走的距离,h*(x) 则是你到达目的地后,发现你实际走了的距离。你预想的距离一定是比实际距离短,或者刚好等于实际距离的值。这样我们称你的 h(x) 是可纳的,是乐观的。
不同的估价函数对算法的效率可能产生极大的影响。尤其是 h(x) 的选定,比如在接下来的八数码问题中,我们选择了曼哈顿距离之和作为 h(x) ,你也可以选择相差的格子作为 h(x),只不过搜索的次数会不同。当 h(x) 越接近 h*(x) ,那么扩展的结点越少!
那么A*算法的具体实现是怎么样的呢?
1、将源点加入open表
2、
while(OPEN!=NULL)
{
从OPEN表中取f(n)最小的节点n;
if(n节点==目标节点)
break;
for(当前节点n的每个子节点X)
{
计算f(X);
if(XinOPEN)
if(新的f(X)<OPEN中的f(X))
{
把n设置为X的父亲;
更新OPEN表中的f(n); //不要求记录路径的话可以直接加入open表,旧的X结点是不可能比新的先出队
}
if(XinCLOSE)
continue;
if(Xnotinboth)
{
把n设置为X的父亲;
求f(X);
并将X插入OPEN表中;
}
}//endfor
将n节点插入CLOSE表中;
按照f(n)将OPEN表中的节点排序;//实际上是比较OPEN表内节点f的大小,从最小路径的节点向下进行。
}//endwhile(OPEN!=NULL) 3、保存路径,从目标点出发,按照父节点指针遍历,直到找到起点。
以八数码问题为例:
我们从1、仅考虑代价函数; 2、仅考虑贪婪优先; 3、A*算法。
1 #include<bits/stdc++.h>
2 using namespace std;
3 struct Maze{
4 char s[3][3];
5 int i,j,fx,gx;
6 bool operator < (const Maze &a )const{
7 return fx>a.fx;
8 }
9 } c;
10 int fx[4][2]={{-1,0},{1,0},{0,1},{0,-1}};
11 map<char ,Maze > mp;
12 int T;
13 int get_hx(char s[3][3]){
14 int hx=0;
15 for(int i=0;i<3;i++){
16 for(int j=0;j<3;j++){
17 hx+=abs(mp[s[i][j]].i-i)+abs(mp[s[i][j]].j-j);
18 }
19 }
20 return (int)hx;
21 }
22 void pr(char s[3][3]){
23 cout<<"step: "<<T++<<endl;
24 for(int i=0;i<3;i++){
25 for(int j=0;j<3;j++)
26 cout<<s[i][j];
27 cout<<endl;
28 }
29 cout<<endl;
30 }
31 int key(char s[3][3]){
32 int ans=0;
33 for(int i=0;i<3;i++)
34 for(int j=0;j<3;j++)
35 ans=ans*10+(s[i][j]-'0');
36 return ans;
37 }
38 void BFS(){
39 T=0;
40 map<int ,bool >flag;
41 queue < Maze > q;
42 q.push(c);
43 flag[key(c.s)]=1;
44 while(!q.empty()){
45 Maze now=q.front();
46 q.pop();
47 pr(now.s);
48 if(get_hx(now.s)==0){
49 break;
50 }
51 for(int i=0;i<4;i++){
52 int x,y;
53 x=now.i+fx[i][0];
54 y=now.j+fx[i][1];
55 if(!(x>=0&&x<3&&y>=0&&y<3)) continue;
56 Maze tmp=now;
57 tmp.s[now.i][now.j]=tmp.s[x][y];
58 tmp.s[x][y]='0';
59 tmp.i=x ; tmp.j=y ;
60 tmp.fx++;
61 if(!flag[key(tmp.s)]){
62 q.push(tmp);
63 flag[key(tmp.s)]=1;
64 }
65 }
66 }
67 }
68 void Greedy_best_first_search(){
69 T=0;
70 priority_queue< Maze > q ;
71 map<int ,int >flag;
72 c.fx=get_hx(c.s);
73 q.push(c);
74 flag[key(c.s)]=1;
75 while(!q.empty()){
76 Maze now=q.top();
77 q.pop();
78 pr(now.s);
79 if(get_hx(now.s)==0){
80 break;
81 }
82 for(int i=0;i<4;i++){
83 int x,y;
84 x=now.i+fx[i][0];
85 y=now.j+fx[i][1];
86 if(!(x>=0&&x<3&&y>=0&&y<3)) continue;
87 Maze tmp=now;
88 tmp.s[now.i][now.j]=tmp.s[x][y];
89 tmp.s[x][y]='0';
90 tmp.i=x ; tmp.j=y ;
91 tmp.fx=get_hx(tmp.s);
92 if(!flag[key(tmp.s)]){
93 q.push(tmp);
94 flag[key(tmp.s)]=1;
95 }
96 }
97 }
98 }
99 void A_star(){
100 T=0;
101 priority_queue< Maze > q ;
102 map<int ,int >flag;
103 c.gx=0;
104 c.fx=get_hx(c.s)+c.gx;
105 q.push(c);
106 while(!q.empty()){
107 Maze now=q.top();
108 q.pop();
109 flag[key(now.s)]=now.fx;
110 pr(now.s);
111 if(get_hx(now.s)==0){
112 break;
113 }
114 for(int i=0;i<4;i++){
115 int x,y;
116 x=now.i+fx[i][0];
117 y=now.j+fx[i][1];
118 if(!(x>=0&&x<3&&y>=0&&y<3)) continue;
119 Maze tmp=now;
120 tmp.s[now.i][now.j]=tmp.s[x][y];
121 tmp.s[x][y]='0';
122 tmp.i=x ; tmp.j=y ;
123 tmp.gx++;
124 tmp.fx=get_hx(tmp.s)+tmp.gx;
125 if(!flag[key(tmp.s)]){
126 q.push(tmp);
127 }else if(flag[key(tmp.s)]>tmp.fx){
128 flag[key(tmp.s)]=0;
129 q.push(tmp);
130 }
131 }
132 }
133 }
134 int main(){
135 mp['1'].i=0;mp['1'].j=0;
136 mp['2'].i=0;mp['2'].j=1;
137 mp['3'].i=0;mp['3'].j=2;
138 mp['4'].i=1;mp['4'].j=2;
139 mp['5'].i=2;mp['5'].j=2;
140 mp['6'].i=2;mp['6'].j=1;
141 mp['7'].i=2;mp['7'].j=0;
142 mp['8'].i=1;mp['8'].j=0;
143 mp['0'].i=1;mp['0'].j=1;
144 for(int i=0;i<3;i++){
145 for(int j=0;j<3;j++){
146 cin>>c.s[i][j];
147 }
148 char x=getchar();
149 }
150 cin>>c.i>>c.j;
151 c.fx=0;
152 cout<<"八数码问题 BFS 解法(即仅以当前代价 g(x)搜索): "<<endl;
153 BFS();
154 cout<<"八数码问题 Greedy_best_first_search 解法(即仅以估计函数 h(x)搜索): "<<endl;
155 Greedy_best_first_search();
156 cout<<"八数码问题 A* 解法: "<<endl;
157 A_star();
158 return 0;
159 }
160 /*
161 283
162 164
163 705
164 2 1
165 */
结果显示:
1、仅考虑代价函数:36步。
2、仅考虑贪婪优先:5步。
3、A*算法:5步。
明显,在引入了启发式信息后,大大的提高了搜索的效率。
引申问题: 第 k 短路问题。
思路: 先从终点求出最短路,作为 h(x) 。然后维护优先队列,维护 F(x) 最小,第一次出来的终点是最短路,终点第二次出来的是次短路……
求第k短路时,A*算法优化的是查找的次数,可以理解为剪枝,更快速的找到最短路,次短路……
其他操作和正常的求最短路没有什么区别,找到终点第k次出队的值,就是第k短路。
(可能你会说在无向图中存在有回头路,没错,有可能次短路只是最短路走了一次回头路,但这确实也是一条次短路)。
启发式搜索(heuristic search)———A*算法的更多相关文章
- 【启发式搜索】【A*算法】hdu6171 Admiral
一个舰队的目标状态如上图.红色是旗舰.然后给你初始局面,每一次决策可以把旗舰和其上一层或下一层的两个相邻的进行交换.如果能在20步内出解的话,输出最小步数:否则输出“too difficult”. 把 ...
- 【算法】禁忌搜索算法(Tabu Search,TS)超详细通俗解析附C++代码实例
01 什么是禁忌搜索算法? 1.1 先从爬山算法说起 爬山算法从当前的节点开始,和周围的邻居节点的值进行比较. 如果当前节点是最大的,那么返回当前节点,作为最大值 (既山峰最高点):反之就用最高的邻居 ...
- 浅谈关于特征选择算法与Relief的实现
一. 背景 1) 问题 在机器学习的实际应用中,特征数量可能较多,其中可能存在不相关的特征,特征之间也可能存在相关性,容易导致如下的后果: 1. 特征个数越多,分析特征.训练模型所需的时间就越 ...
- 利用Red Blob游戏介绍A*算法
转自:http://gad.qq.com/program/translateview/7194337 在游戏中,我们经常想要找到从一个位置到另一个位置的路径.我们不只是想要找到最短距离,同时也要考虑旅 ...
- N数码问题的启发式搜索算法--A*算法python实现
一.启发式搜索:A算法 1)评价函数的一般形式 : f(n) = g(n) + h(n) g(n):从S0到Sn的实际代价(搜索的横向因子) h(n):从N到目标节点的估计代价,称为启发函数(搜索的纵 ...
- ACM算法锦集
一:知识点 数据结构: 1,单,双链表及循环链表 2,树的表示与存储,二叉树(概念,遍历)二叉树的 应用(二叉排序树,判定树,博弈树,解答树等) 3,文件操作(从文本文件中读入数据并输出到文本文 件中 ...
- 关于Beam Search
Wiki定义:In computer science, beam search is a heuristic search algorithm that explores a graph by exp ...
- 干货 | 自适应大邻域搜索(Adaptive Large Neighborhood Search)入门到精通超详细解析-概念篇
01 首先来区分几个概念 关于neighborhood serach,这里有好多种衍生和变种出来的胡里花俏的算法.大家在上网搜索的过程中可能看到什么Large Neighborhood Serach, ...
- javascript 实现 A-star 寻路算法
在游戏开发中,又一个很常见的需求,就是让一角色从A点走到B点,而我们期望所走的路是最短的,最容易想到的就是两点之间直线最短,我们可以通过勾股定理来求出两点之间的距离,但这个情况只能用于两点之间没有障碍 ...
- 游戏人工智能 读书笔记 (四) AI算法简介——Ad-Hoc 行为编程
本文内容包含以下章节: Chapter 2 AI Methods Chapter 2.1 General Notes 本书英文版: Artificial Intelligence and Games ...
随机推荐
- 浅谈API安全的应用
理论基础 API它的全称是Application Programming Interface,也叫做应用程序接口,它定义了软件之间的数据交互方式.功能类型.随着互联网的普及和发展,API 从早期的 ...
- CodeForces 1367F2 Flying Sort (Hard Version)
题意 给一个长度为\(n\)的数组,你可以有两种操作 将某一个数放置在数组开头 将某一个数放置在数组结尾 问最小操作多少次可以得到一个非递减数列 (比\(F1\)难在\(n\)变大,且数组中元素可以有 ...
- 原来你是这样的JAVA[06]-反射
1.JVM为每个加载的class及interface创建了对应的Class实例来保存class及interface的所有信息: 获取一个class对应的Class实例后,就可以获取该class的所有信 ...
- 安卓APK加固工具 如何进行实名认证购买和激活
安卓APK资源混淆加密重签名工具 价格表 授权时长 价格 1小时 49 1天 99 1个月 199 1个季度 399 半年 599 1年 799 付费版功能 功能点 免费版 付费版 去除广告信息 × ...
- CSP-J/S 初赛冲刺
CSP-J/S 初赛冲刺 对于咱们信奥选手来说,会做的题要坚决不丢分,不会做的题要学会尽量多拿分,这样你的竞赛之路才能一路亨通! Linux 基础操作 文件(文件夹)操作 列出文件:ls 列出隐藏文件 ...
- Ds100p -「数据结构百题」51~60
纪念 数据结构一百题50题了呢,该过半周年啦~~~~ LYC和WGY半年的努力让这个几乎玩笑一般的系列到了现在. 今后也请多多关照啦. 祝愿dp100p早日过半 51.CF1000F One Occu ...
- daemonset应用创建了,但是没有pod被调度起来
环境: k8s版本1.25.2 一个master 两个node节点 集群节点全部允许调度(无污点),且资源充足. 操作系统版本: Ubuntu22.01 排查思路: 查看kubelet 日志,和c ...
- Jupyter_Notebook_添加代码自动补全功能
Jupyter Notebook 添加代码自动补全功能 安装 如果之前安装过显示目录功能的话,这一步骤可以跳过. pip install jupyter_contrib_nbextensions 配置 ...
- Rethinking Point Cloud Registration as Masking and Reconstruction论文阅读
Rethinking Point Cloud Registration as Masking and Reconstruction 2023 ICCV *Guangyan Chen, Meiling ...
- Merge-Lrc 合并歌词的小工具
Merge-Lrc 背景 音乐区有群友希望各种乱七八糟的歌词(lrc 格式居多,里面甚至还有翻译)可以整理成单一的文件,或者一个仅翻译的歌词可以和原文的歌词合并.于是就开发了这款工具.地址:https ...