Hudi 在 vivo 湖仓一体的落地实践
作者:vivo 互联网大数据团队 - Xu Yu
在增效降本的大背景下,vivo大数据基础团队引入Hudi组件为公司业务部门湖仓加速的场景进行赋能。主要应用在流批同源、实时链路优化及宽表拼接等业务场景。
一、Hudi 基础能力及相关概念介绍
1.1 流批同源能力
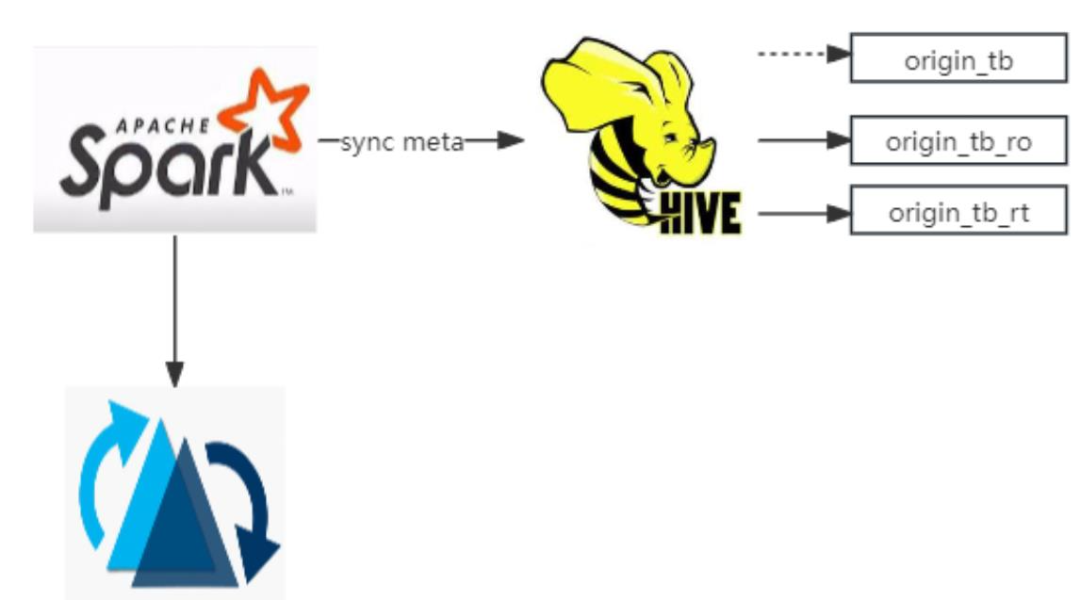
与Hive不同,Hudi数据在Spark/Flink写入后,下游可以继续使用Spark/Flink引擎以流读的形式实时读取数据。同一份Hudi数据源既可以批读也支持流读。
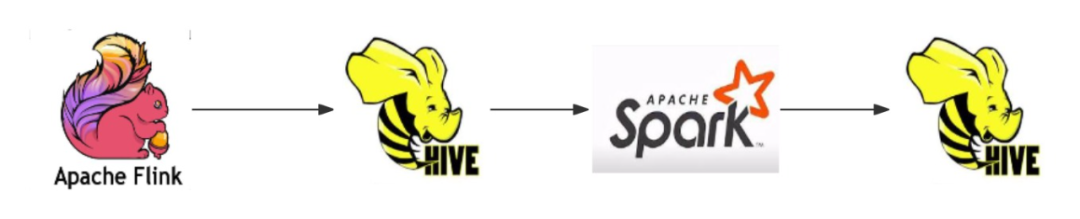
Flink、Hive、Spark的流转批架构:
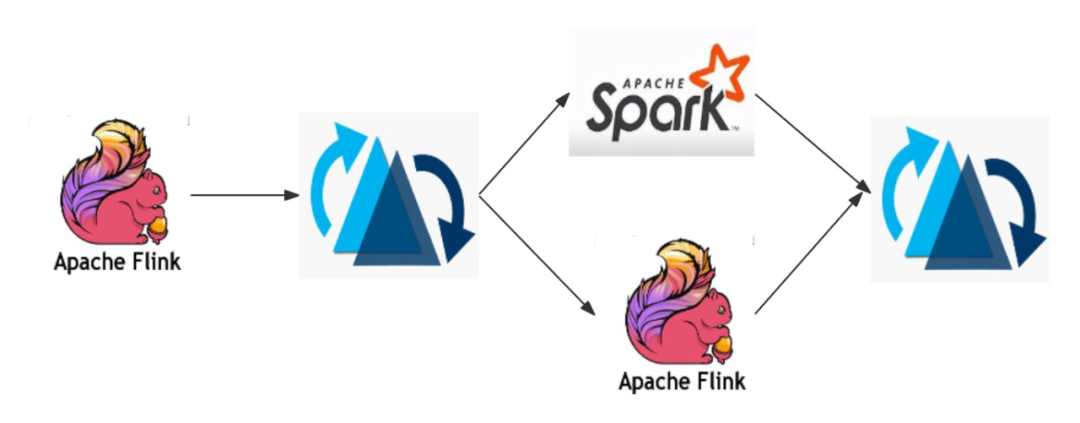
Hudi流批同源架构:
1.2 COW和MOR的概念
Hudi支持COW(Copy On Write)和MOR(Merge On Read)两种类型:
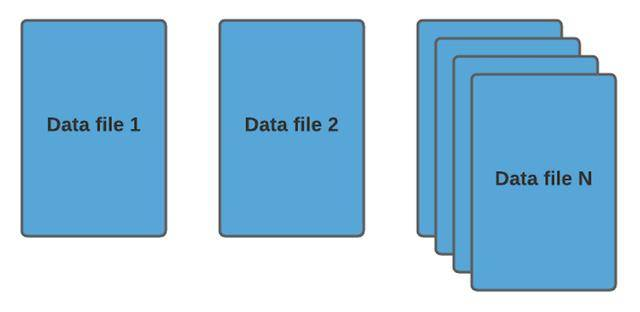
(1)COW写时拷贝:
每次更新的数据都会拷贝一份新的数据版本出来,用户通过最新或者指定version的可以进行数据查询。缺点是写入的时候往往会有写内存放大的情况,优点是查询不需要合并,直接读取效率相对比较高。JDK中的CopyOnWriteArrayList/CopyOnWriteArraySet 容器正是采用了 COW 思想。
COW表的数据组织格式如下:
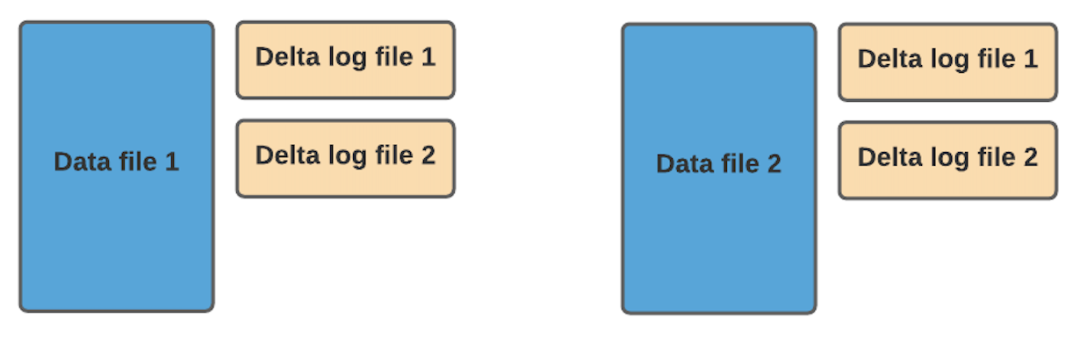
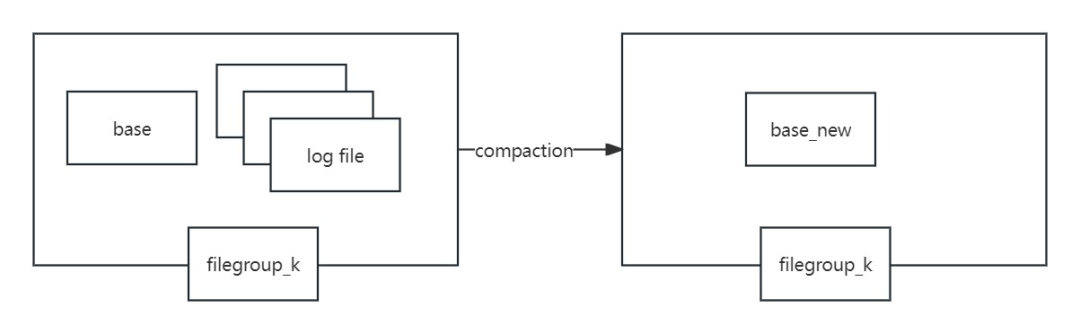
(2)MOR读时合并:
每次更新或者插入新的数据时,并写入parquet文件,而是写入Avro格式的log文件中,数据按照FileGroup进行分组,每个FileGroup由base文件(parquet文件)和若干log文件组成,每个FileGroup有单独的FileGroupID;在读取的时候会在内存中将base文件和log文件进行合并,进而返回查询的数据。缺点是合并需要花费额外的合并时间,查询的效率受到影响;优点是写入的时候效率相较于COW快很多,一般用于要求数据快速写入的场景。
MOR数据组织格式如下:
1.3 Hudi的小文件治理方案
Hudi表会针对COW和MOR表制定不同的文件合并方案,分别对应Clustering和Compaction。
Clustering顾名思义,就是将COW表中多个FileGroup下的parquet根据指定的数据大小重新编排合并为新的且文件体积更大的文件块。如下图所示:
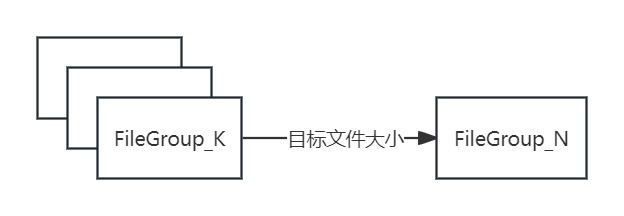
Compaction即base parquet文件与相同FileGroup下的其余log文件进行合并,生成最新版本的base文件。如下图所示:
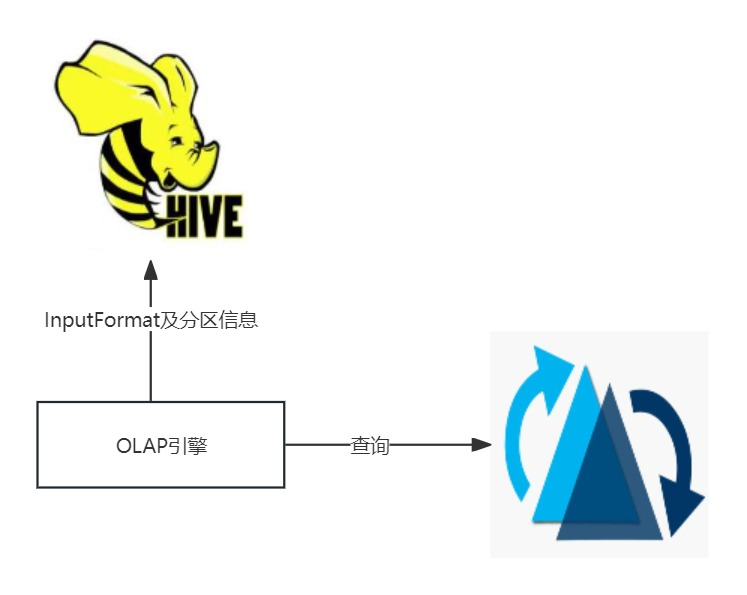
1.4 周边引擎查询Hudi的原理
当前主流的OLAP引擎等都是从HMS中获取Hudi的分区元数据信息,从InputFormat属性中判断需要启动HiveCatalog还是HudiCatalog,然后生成查询计划最终执行。当前StarRocks、Presto等引擎都支持以外表的形式对Hudi表进行查询。
1.5 Procedure介绍
Hudi 支持多种Procedure,即过程处理程序,用户可以通过这些Procedure方便快速的处理Hudi表的相关逻辑,比如Compaction、Clustering、Clean等相关处理逻辑,不需要进行编码,直接通过sparksql的语句来执行。
1.6 项目架构
1. 按时效性要求进行分类
秒级延迟:
分钟级延迟:
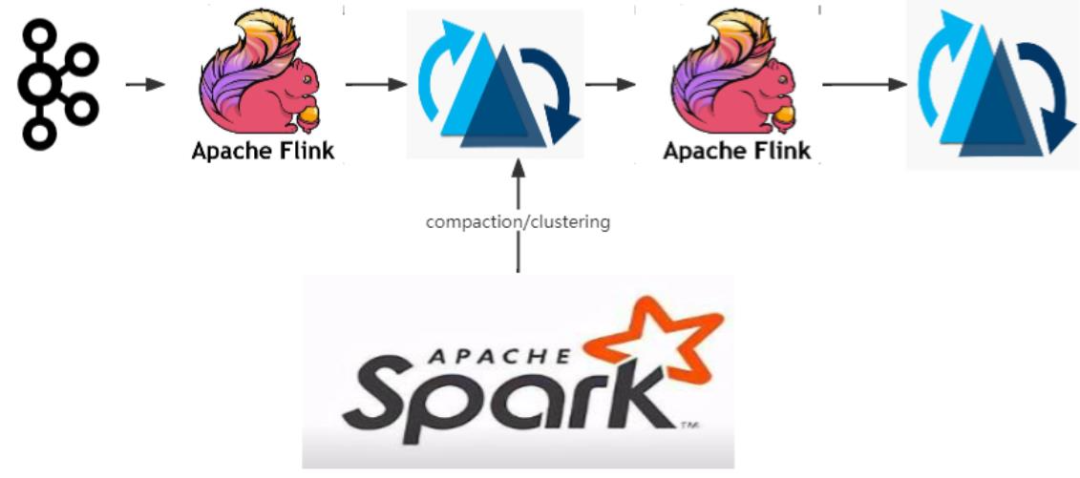
当前Hudi主要还是应用在准实时场景:
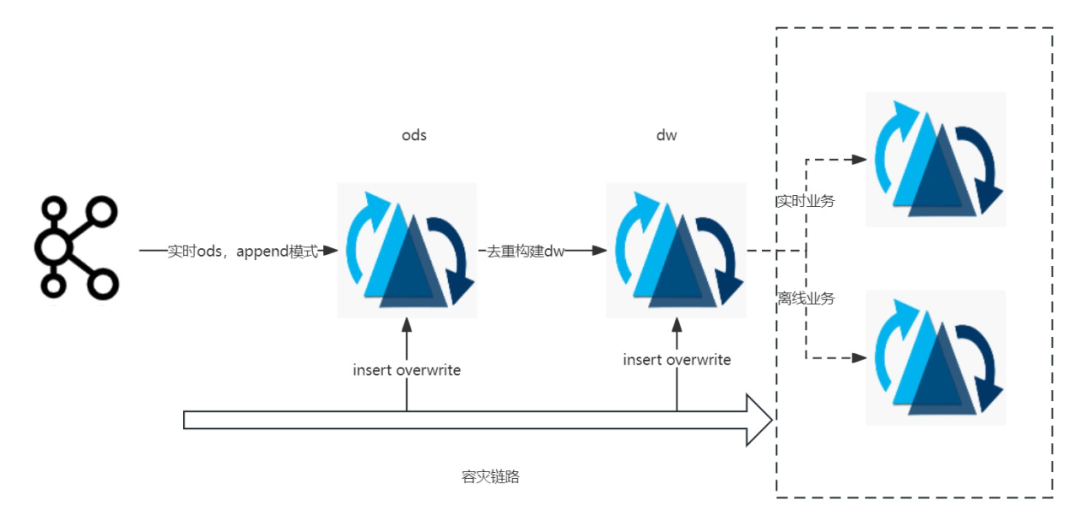
上游从Kafka以append模式接入ods的cow表,下游部分dw层业务根据流量大小选择不同类型的索引表,比如bucket index的mor表,在数据去重后进行dw构建,从而提供统一数据服务层给下游的实时和离线的业务,同时ods层和dw层统一以insert overwrite的方式进行分区级别的容灾保障,Timeline上写入一个replacecommit的instant,不会引发下游流量骤增,如下图所示:
1.7 线上达成能力
实时场景:
支持1亿条/min量级准实时写入;流读延迟稳定在分钟级
离线场景:
支持千亿级别数据单批次离线写入;查询性能与查询Hive持平(部分线上任务较查询Hive提高20%以上)
小文件治理:
95%以上的合并任务单次执行控制在10min内完成
二、组件能力优化
2.1 组件版本
当前线上所有Hudi的版本已从0.12 升级到 0.14,主要考虑到0.14版本的组件能力更加完备,且与社区前沿动态保持一致。
2.2 流计算场景
1. 限流
数据积压严重的情况下,默认情况会消费所有未消费的commits,往往因消费的commits数目过大,导致任务频繁OOM,影响任务稳定性;优化后每次用户可以摄取指定数目的commits,很大程度上避免任务OOM,提高了任务稳定性。

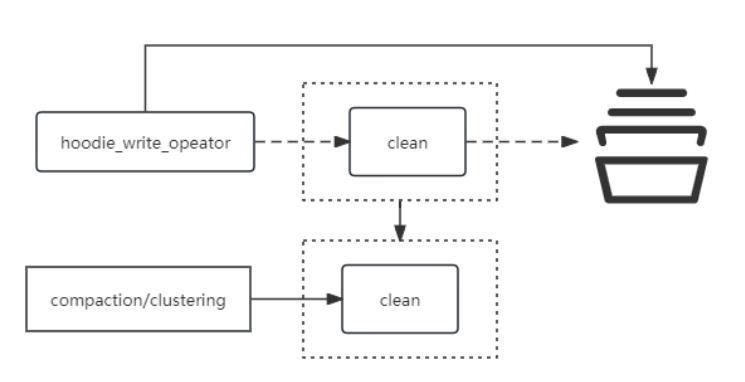
2. 外置clean算子
避免单并行度的clean算子最终阶段影响数据实时写入的性能;将clean单独剥离到
compaction/clustering执行。这样的好处是单个clean算子,不会因为其生成clean计划和执行导致局部某些Taskmanager出现热点的问题,极大程度提升了实时任务稳定性。
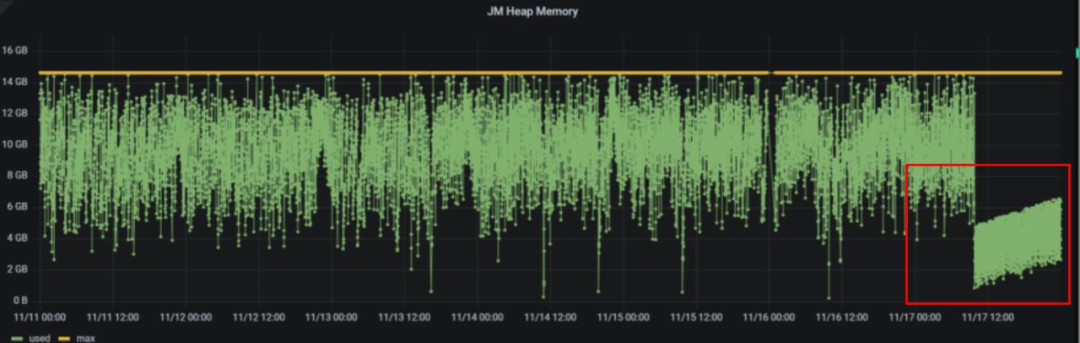
3. JM内存优化
部分大流量场景中,尽管已经对Hudi进行了最大程度的调优,但是JM的内存仍然在较高水位波动,还是会间隔性出现内存溢出影响稳定性。这种情况下我们尝试对 state.backend.fs.memory-threshold 参数进行调整;从默认的20KB调整到1KB,JM内存显著下降;同时运行至今state相关数据未产生小文件影响。
2.3 批计算场景
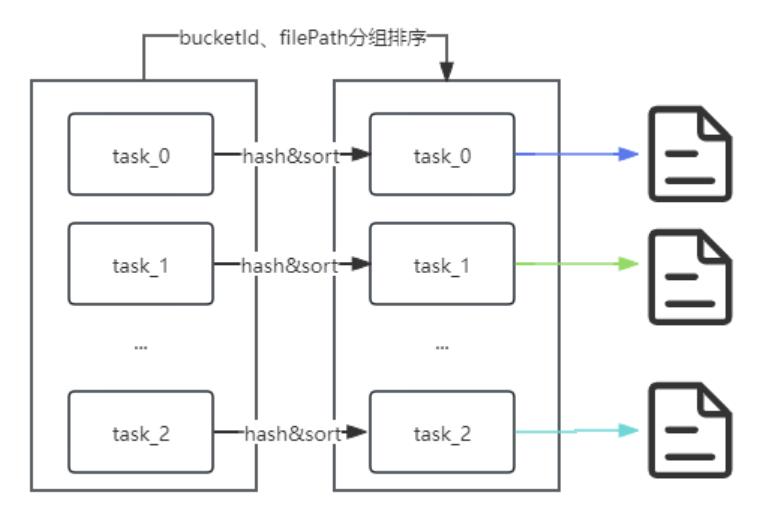
1. Bucket index下的BulkInsert优化
0.14版本后支持了bucket表的bulkinsert,实际使用过程中发现分区数很大的情况下,写入延迟耗时与计算资源消耗较高;分析后主要是打开的句柄数较多,不断CPU IO 频繁切换影响写入性能。
因此在hudi内核进行了优化,主要是基于partition path和bucket id组合进行预排序,并提前关闭空闲写入句柄,进而优化cpu资源使用率。
这样原先50分钟的任务能降低到30分钟以内,数据写入性能提高约30% ~ 40%。
优化前:
优化后:
2. 查询优化
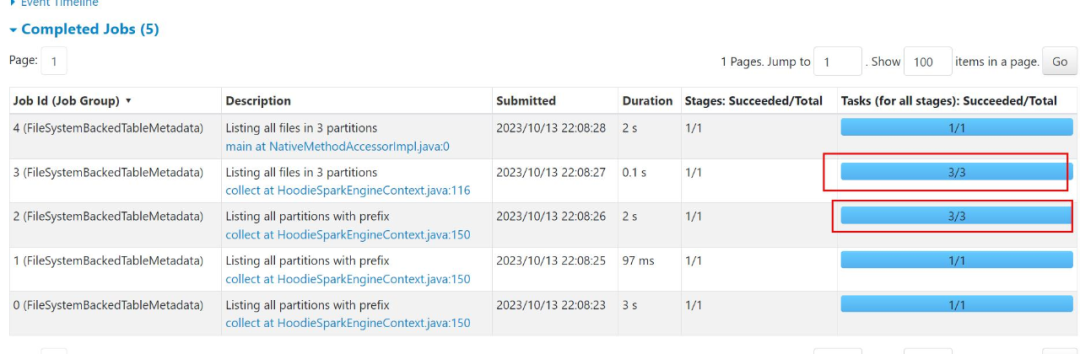
0.14版本中,部分情况下分区裁剪会失效,从而导致条件查询往往会扫描不相关的分区,在分区数庞大的情况下,会导致driver OOM,对此问题进行了修复,提高了查询任务的速度和稳定性。
eg:select * from `hudi_test`.`tmp_hudi_test` where day='2023-11-20' and hour=23;
(其中tmp_hudi_test是一张按日期和小时二级分区的表)
修复前:
修复后:
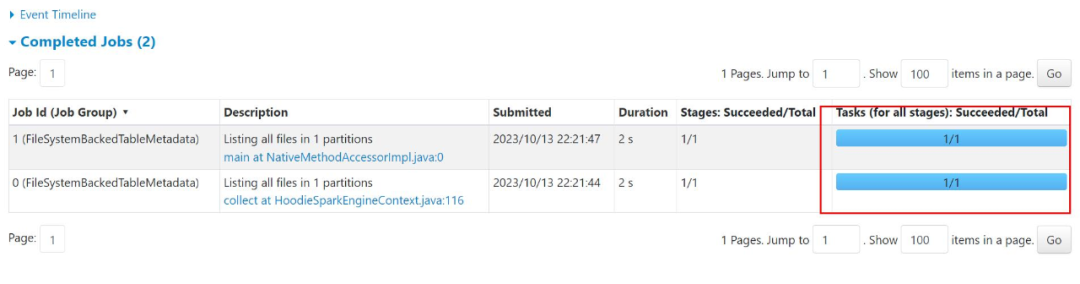
优化后不仅包括减少分区的扫描数目,也减少了一些无效文件RPC的stage。
3. 多种OLAP引擎支持
此外,为了提高MOR表管理的效率,我们禁止了RO/RT表的生成;同时修复了原表的元数据不能正常同步到HMS的缺陷(这种情况下,OLAP引擎例如Presto、StarRocks查询原表数据默认仅支持对RO/RT表的查询,原表查询为空结果)。
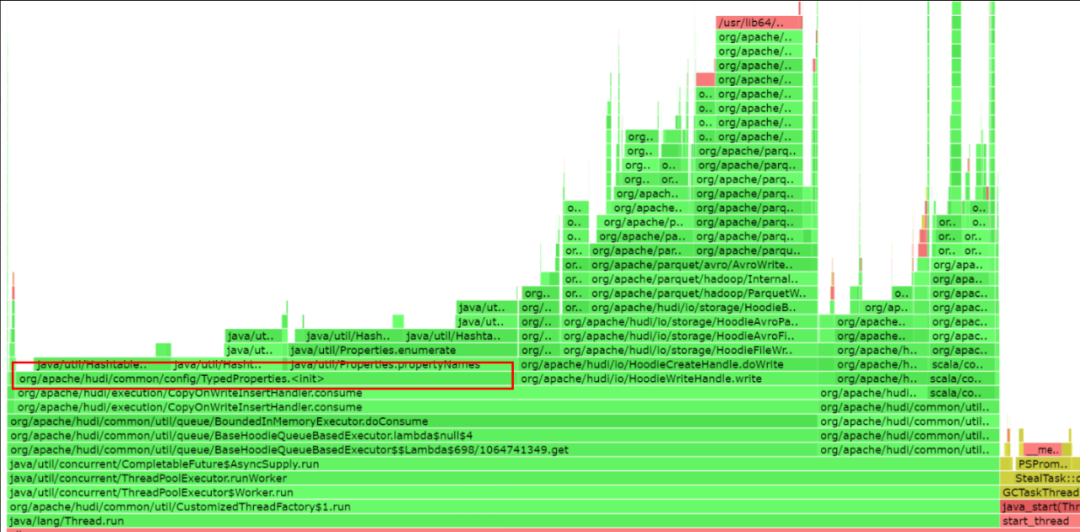
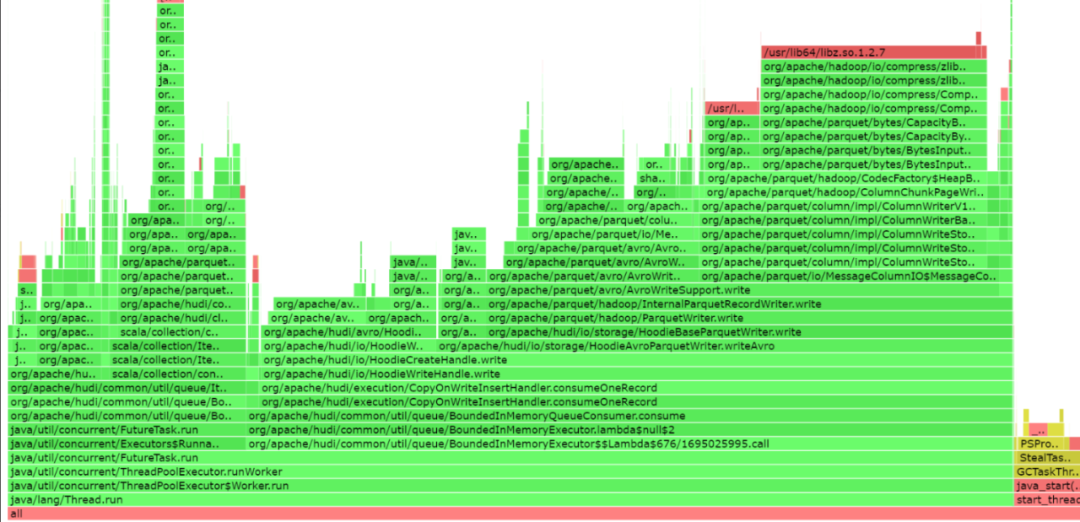
2.4 小文件合并
1. 序列化问题修复
0.14版本Hudi在文件合并场景中,Compaction的性能相较0.12版本有30%左右的资源优化,比如:原先0.12需要6G资源才能正常启动单个executor的场景下,0.14版本 4G就可以启动并稳定执行任务;但是clustering存在因TypedProperties重复序列化导致的性能缺陷。完善后,clustering的性能得到30%以上的提升。
可以从executor的修复前后的火焰图进行比对。
修复前:
修复后:
2. 分批compaction/clustering
compaction/clustering默认不支持按commits数分批次执行,为了更好的兼容平台调度能力,对compaction/clustering相关procedure进行了改进,支持按批次执行。
同时对其他部分procedure也进行了优化,比如copy_to_table支持了列裁剪拷贝、delete_procedures支持了批量执行等,降低sparksql的执行时间。
3. clean优化
Hudi0.14 在多分区表的场景下clean的时候很容易OOM,主要是因为构建HoodieTableFileSystemView的时候需要频繁访问TimelineServer,因产生大量分区信息请求对象导致内存溢出。具体情况如下:
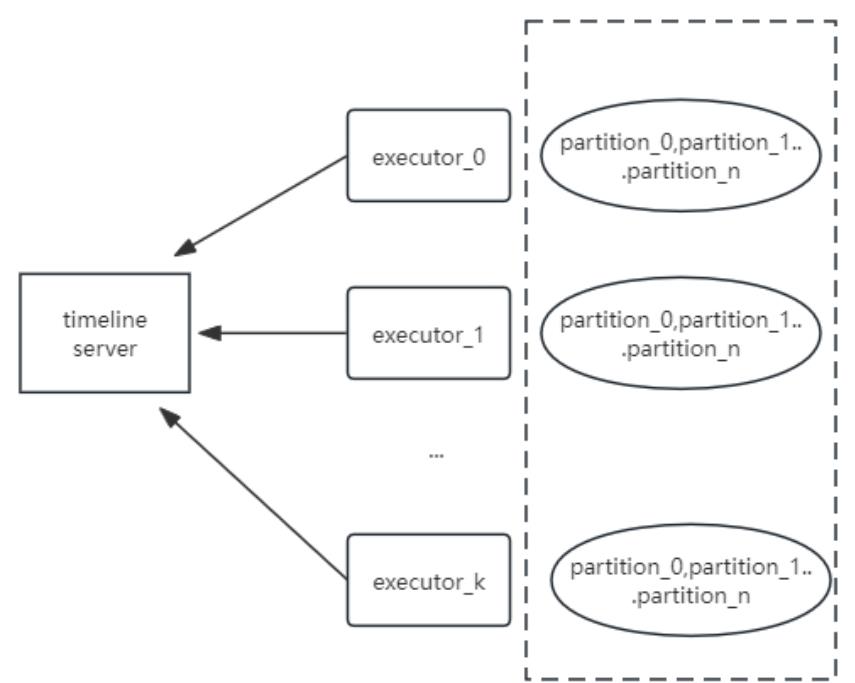
对此我们对partition request Job做了相关优化,将多个task分为多个batch来执行,降低对TimelineSever的内存压力,同时增加了请求前的缓存判断,如果已经缓存的将不会发起请求。
改造后如下:
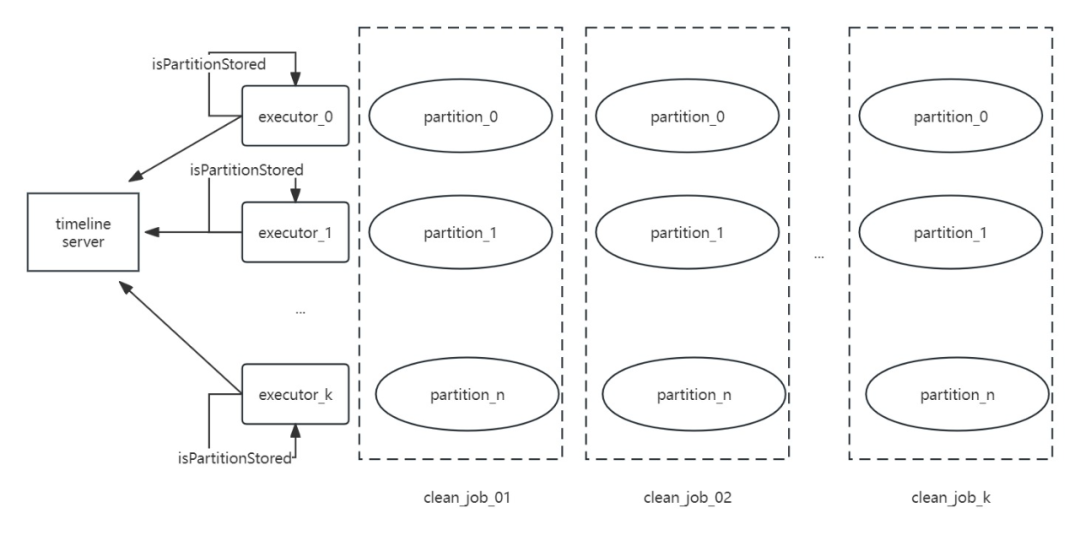
此外实际情况下还可以在FileSystemViewManager构建过程中将 remoteview 和 secondview 的顺序互调,绝大部分场景下也能避免clean oom的问题,直接优先从secondview中获取分区信息即可。
2.5 生命周期管理
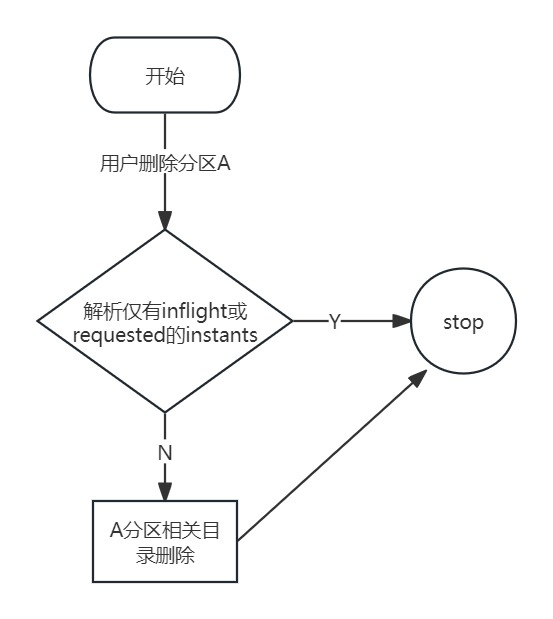
当前计算平台支持用户表级别生命周期设置,为了提高删除的效率,我们设计实现了直接从目录对数据进行删除的方案,这样的收益有:
降低了元数据交互时间,执行时间快;
无须加锁、无须停止任务;
不会影响后续compaction/clustering 相关任务执行(比如执行合并的时候不会报文件不存在等异常)。
删除前会对compaction/clustering等instants的元数据信息进行扫描,经过合法性判断后区分用户需要删除的目录是否存在其中,如果有就保存;否则直接删除。流程如下:
三、总结
我们分别在流批场景、小文件治理、生命周期管理等方向做了相关优化,上线后的收益主要体现这四个方向:
部分实时链路可以进行合并,降低了计算和存储资源成本;
基于watermark有效识别分区写入的完成度,接入湖仓的后续离线任务平均SLA提前时间不低于60分钟;
部分流转批后的任务上线后执行时间减少约40%(比如原先执行需要150秒的任务可以缩短到100秒左右完成 ;
离线增量更新场景,部分任务相较于原先Hive任务可以下降30%以上的计算资源。
同时跟进用户实际使用情况,发现了一些有待优化的问题:
Hudi生成文件的体积相较于原先Hive,体积偏大(平均有1.3 ~ 1.4的比例);
流读的指标不够准确;
Hive—>Hudi迁移需要有一定的学习成本;
针对上述问题,我们也做了如下后续计划:
对hoodie parquet索引文件进行精简优化,此外业务上对主键的重新设计也会直接影响到文件体积大小;
部分流读的指标不准,我们已经完成初步的指标修复,后续需要补充更多实时的任务指标来提高用户体验;
完善Hudi迁移流程,提供更快更简洁的迁移工具,此外也会向更多的业务推广Hudi组件,进一步挖掘Hudi组件的潜在使用价值。
Hudi 在 vivo 湖仓一体的落地实践的更多相关文章
- 李呈祥:bilibili在湖仓一体查询加速上的实践与探索
导读: 本文主要介绍哔哩哔哩在数据湖与数据仓库一体架构下,探索查询加速以及索引增强的一些实践.主要内容包括: 什么是湖仓一体架构 哔哩哔哩目前的湖仓一体架构 湖仓一体架构下,数据的排序组织优化 湖仓一 ...
- 华为云FusionInsight湖仓一体解决方案的前世今生
摘要:华为云发布新一代智能数据湖华为云FusionInsight时再次提到了湖仓一体理念,那我们就来看看湖仓一体的来世今生. 伴随5G.大数据.AI.IoT的飞速发展,数据呈现大规模.多样性的极速增长 ...
- 划重点!AWS的湖仓一体使用哪种数据湖格式进行衔接?
此前Apache Hudi社区一直有小伙伴询问能否使用Amazon Redshift查询Hudi表,现在它终于来了. 现在您可以使用Amazon Redshift查询Amazon S3 数据湖中Apa ...
- 分支路径图调度框架在 vivo 效果广告业务的落地实践
作者:vivo 互联网AI团队- Liu Zuocheng.Zhou Baojian 本文根据周保建老师在"2022 vivo开发者大会"现场演讲内容整理而成.公众号回复[2022 ...
- Apache Hudi在华米科技的应用-湖仓一体化改造
徐昱 Apache Hudi Contributor:华米高级大数据开发工程师 巨东东 华米大数据开发工程师 1. 应用背景及痛点介绍 华米科技是一家基于云的健康服务提供商,拥有全球领先的智能可穿戴技 ...
- 华为云MRS支持lakeformation能力,打造一站式湖仓,释放数据价值
摘要:对云端用户而言,业务价值发现是最重要的,华为MRS支持LakeFormation后,成功降低了数据应用的成本,帮助客户落地"存"与"算"的管理,加快推进了 ...
- MRS+LakeFormation:打造一站式湖仓,释放数据价值
摘要:华为LakeFormation是企业级的一站式湖仓构建服务. 本文分享自华为云社区<华为云MRS支持LakeFormation能力,打造一站式湖仓,释放数据价值]>,作者:break ...
- 基于Apache Hudi构建数据湖的典型应用场景介绍
1. 传统数据湖存在的问题与挑战 传统数据湖解决方案中,常用Hive来构建T+1级别的数据仓库,通过HDFS存储实现海量数据的存储与水平扩容,通过Hive实现元数据的管理以及数据操作的SQL化.虽然能 ...
- vivo 云原生容器探索和落地实践
作者:vivo 互联网容器团队- Pan Liangbiao 本文根据潘良彪老师在"2022 vivo开发者大会"现场演讲内容整理而成.公众号回复[2022 VDC]获取互联网技术 ...
- 基于 Kafka 的实时数仓在搜索的实践应用
一.概述 Apache Kafka 发展至今,已经是一个很成熟的消息队列组件了,也是大数据生态圈中不可或缺的一员.Apache Kafka 社区非常的活跃,通过社区成员不断的贡献代码和迭代项目,使得 ...
随机推荐
- 《Kali渗透基础》11. 无线渗透(一)
@ 目录 1:无线技术 2:IEEE 802.11 标准 2.1:无线网络分层 2.2:IEEE 2.3:日常使用标准 2.3.1:802.11 2.3.2:802.11b 2.3.3:802.11a ...
- 快手商品详情API接口如何使用
使用快手开的API接口获取商品详情,可按照以下步骤进行: 1.注册账号并创建应用 注册开发者账号,并在账号后台中创建一个应用,获得AppKey和AppSecret等信息.这些信息是使用API接口访问快 ...
- 遗传算法解决航路规划问题(MATLAB)
遗传算法 文章部分图片和思路来自司守奎,孙兆亮<数学建模算法与应用>第二版 定义:遗传算法是一种基于自然选择原理和自然遗传机制的搜索(寻优)算法,模拟自然界中的声明进化机制,在人工系统中实 ...
- 有Root与无Root安装git-lfs
有Root与无Root安装git-lfs 直接安装 先查看arm还是AMD 例如当前使用Rocky Linux 8.8版本的内核.因此,应该下载适用于Rocky Linux 8.x的Git LFS安装 ...
- AK、SK实现(双方API交互:签名及验证)
参考:https://blog.csdn.net/yqwang75457/article/details/117815474 1.原理 AK/SK: AK:Access Key Id,用于标示用户. ...
- C# 使用Windows身份验证连接Sql Server
C# 使用Windows身份验证连接Sql Server 使用Windows身份验证连接Sql Server 的字符串为: server=.;database=test_user;Trusted_Co ...
- To_Heart—题解——好多好多!
1.CF1860D link && submission 发现自己并不会处理纯纯的 dp 甚至自己根本不会dp! 定义 dp_{i,j,k} 状态表示前 i 个字符有 j 个 0, 0 ...
- Fisher线性判别分析(二分类)
LDA(Linear Discriminant Analysis)是一种经典的线性判别方法,又称Fisher判别 分析.该方法思想比较简单:给定训练集样例,设法将样例投影到一维的直线 上,使得同类样例 ...
- 14. 从零开始编写一个wmproxy(代理,内网穿透等), HTTP文件服务器的实现过程及参数
用Rust手把手编写一个wmproxy(代理,内网穿透等), HTTP中的压缩gzip,deflate,brotli算法 项目 ++wmproxy++ gite: https://gitee.com/ ...
- Windows10 下载并编译指定版本chromium源码
1.一些信息 Chromium 的官网是 https://www.chromium.org/ Git 仓库是 https://chromium.googlesource.com/chromium/sr ...