已经有 Prometheus 了,还需要夜莺?
谈起当下监控,Prometheus 无疑是最火的项目,如果只是监控机器、网络设备,Zabbix 尚可一战,如果既要监控设备又要监控应用程序、Kubernetes 等基础设施,Prometheus 就是最佳选择。甚至有些开源项目,已经内置支持了 Prometheus 协议的指标暴露,比如新版本的 Zookeeper、新版本的 RabbitMQ、Nginx vts 等等。Prometheus 的影响力可见一斑。
很多场景里讲到的 Prometheus 这个词,其实已经不仅仅是 Prometheus 项目本身了,而是 Prometheus 生态,包括 Prometheus 定义的指标格式、传输协议、查询语言、各类 Exporter 采集器、各类兼容的存储等。
在 Prometheus 生态里,采集可以使用各类 Exporter,存储可以使用 VictoriaMetrics,看图可以使用 Grafana,看起来已经非常完备了,为啥又冒出一个“夜莺(Nightingale)”的开源项目,还声称和 Prometheus 无缝对接?本文尝试探讨一二。
夜莺介绍
从夜莺官网摘出一段夜莺项目介绍:
夜莺监控是一款开源云原生观测分析工具,采用 All-in-One 的设计理念,集数据采集、可视化、监控告警、数据分析于一体,与云原生生态紧密集成,提供开箱即用的企业级监控分析和告警能力。夜莺于 2020 年 3 月 20 日,在 github 上发布 v1 版本,已累计迭代 100 多个版本。
夜莺最初由滴滴开发和开源,并于 2022 年 5 月 11 日,捐赠予中国计算机学会开源发展委员会(CCF ODC),为 CCF ODC 成立后接受捐赠的第一个开源项目。夜莺的核心研发团队,也是 Open-Falcon 项目原核心研发人员,从 2014 年(Open-Falcon 是 2014 年开源)算起来,也有 10 年了,只为把监控这个事情做好。
看完项目介绍,只能知道夜莺是一个监控系统,到底和 Prometheus 有哪些差异点,暂时没有看出来。别急,我们先来看看 Prometheus 的问题。
Prometheus 的问题
Prometheus 的采集、存储、看图都已经解决的挺好了。唯独就是告警,对某些公司来讲,可能会有如下痛点:
- 一个公司有很多套 Prometheus,规则分散在多个 yaml 中不方便管理
- 希望能有一套易用的、权限隔离的 UI,把监控能力开放给全公司各个团队并让他们自服务,别啥事都来找监控团队
- 直接使用 Promql 查询数据、配置告警规则要求有点高,能否内置一些规则库、查询语句,让知识可沉淀,让普通用户也能开箱即用
- 告警规则希望能够更灵活一些,比如支持不同的规则不同的生效时间,能够内置提供一些告警自愈的机制等等
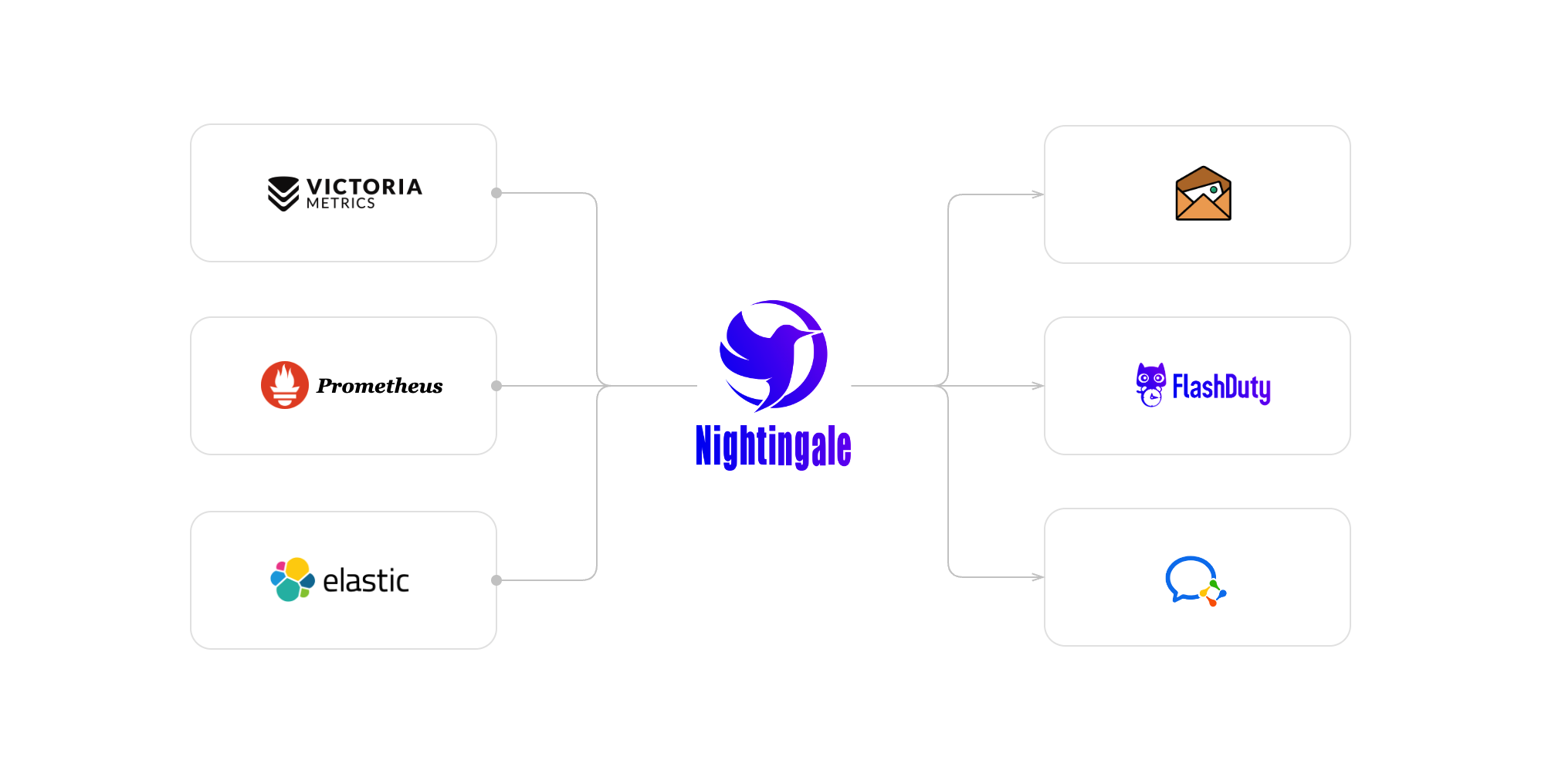
夜莺就是为此而生的。其实夜莺老版本是自成体系的,脱胎自 Open-Falcon,但是随着 Prometheus 大势起来,夜莺就开始拥抱 Prometheus 生态了。可以把夜莺看做是时序数据的告警引擎。当然,夜莺也提供看图、仪表盘的能力,甚至可以查看 Elasticsearch、Loki、TDEngine 的数据,不过当前现状就是夜莺的告警能力大家用的最多,仪表盘大都仍然使用 Grafana 居多。典型的夜莺使用的架构如下:
可以用夜莺完全替代 Prometheus 吗?
其实不是替代的关系,是协同的关系。在夜莺看来,Prometheus 主要是作为时序库使用,除了 Prometheus 这个时序库,还可以选择 VictoriaMetrics、Thanos、M3DB、TDEngine 等其他时序库。夜莺呢,则只是作为一个时序库的告警引擎,既可以对接 Prometheus,也可以对接其他时序库,用户在夜莺里统一管理告警规则,对异常数据做判定,产生告警事件,并做后续分发通知、告警自愈等逻辑。
另外,如果你有多个机房,时序库分散在多个机房,机房之间的网络不好,即便发生网络割裂你也希望边缘机房能够自治不影响告警,夜莺也非常合适。这种情况夜莺称为边缘机房部署模式,时序库和告警引擎下沉部署,网络断了也没事,网络好的时候还可以在中心端统一查看数据,统一管理告警规则,其架构图如下:
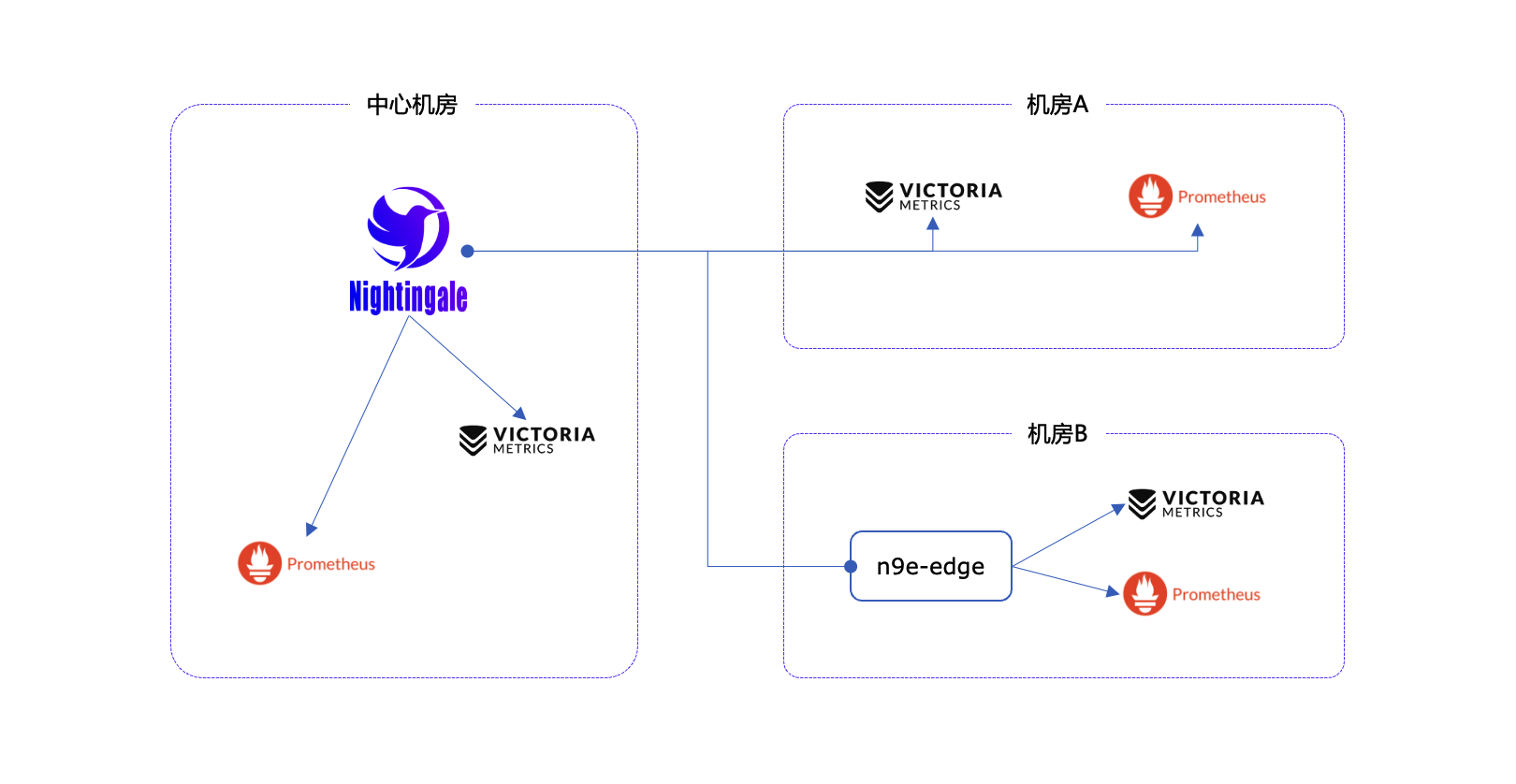
上例中,演示了 3 个机房的部署架构,其中机房 A 和中心机房之间网络链路很好,机房 B 和中心机房之间的网络链路不太好,各个机房都有时序库。所以,中心机房的夜莺告警引擎直接处理中心机房和机房 A 的时序库,机房 B 的时序库由机房 B 的告警引擎处理,也就是图中的 n9e-edge,n9e-edge 会从中心机房的夜莺同步告警规则,然后对本机房的时序库做告警判定。
这样一来,即便机房 B 和中心机房之间网络割裂,由于 n9e-edge 内存中早就同步到了告警规则,所以机房 B 的告警引擎还是可以正常处理机房 B 的两个时序库的告警判定工作。提升了监控系统整体高可用性。
什么场景用夜莺而非 Prometheus?
关键看你的痛点是什么。如果现阶段使用单点的 Prometheus 也可以很好的解决你的问题,完全没必要换,在任何公司,技术工具的迁移都是会受到各种阻力的,懂的自然懂。
如果你有告警规则管理的痛点、边缘机房告警高可用的痛点,那可以尝试一下夜莺。任何工具都有自己的优缺点,根据场景选择。
夜莺可以接收各类监控系统的告警统一做事件通知吗?
有些朋友看到夜莺可以对接各类时序库,做告警判断生成告警事件并分发,就想说,那我其他的监控系统产生的告警能否也交给夜莺去发送呢?这样就可以统一管理告警通知模板、联系人、认证登录权限等问题。
实际是不行的。这是一个典型的事件 OnCall 需求,收集各个监控系统(比如 Prometheus、Zabbix、Open-Falcon、蓝鲸、各类云监控、ElastAlert 等)的告警,统一做告警收敛降噪、排班、认领升级、按条件灵活分发等,这个需求要想做好,值得用一个单独的产品来搞,我们姑且称这个产品为 OnCall 产品。OnCall 产品和各个监控系统之间的关系是:
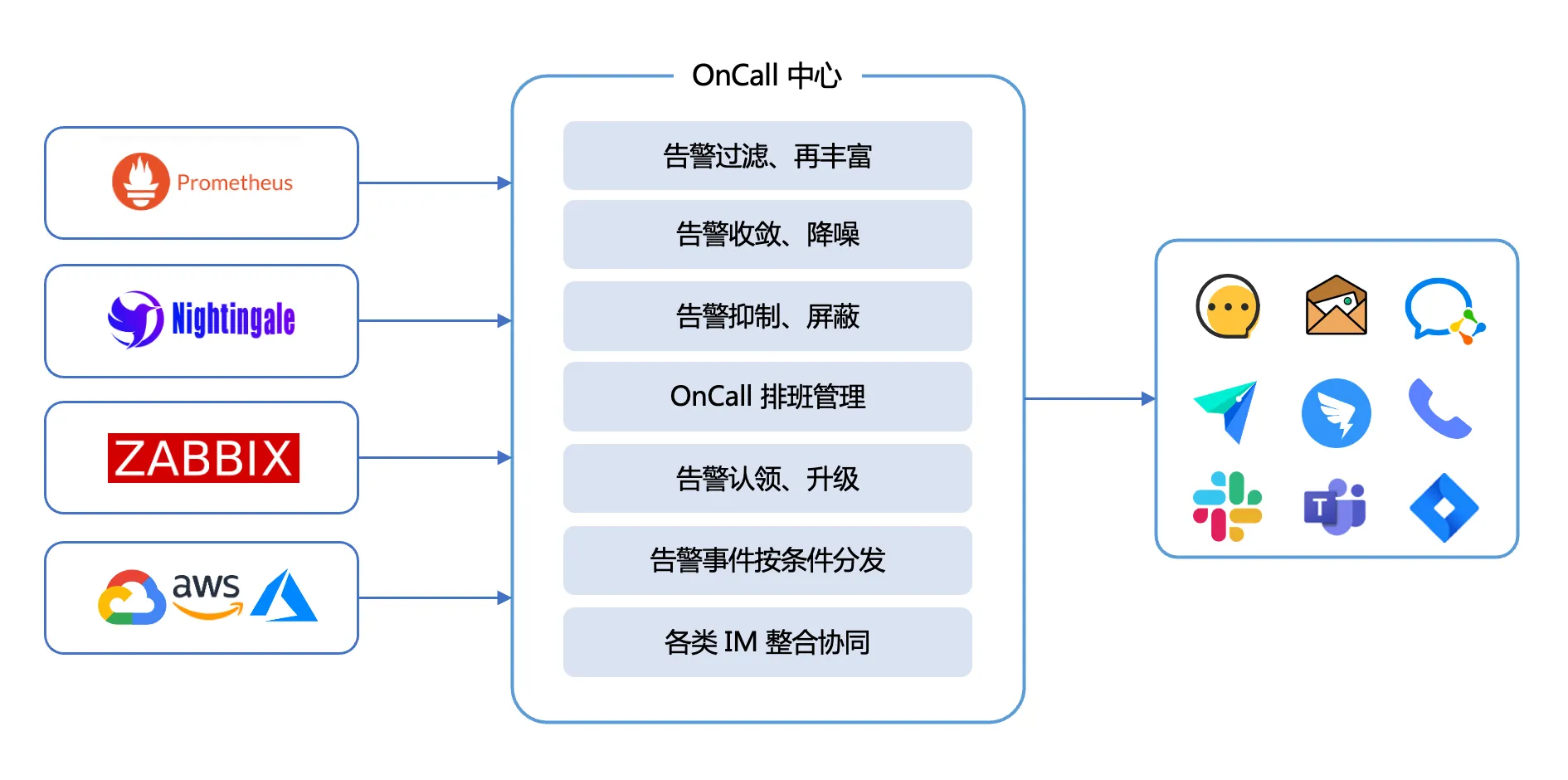
即:监控系统(包括各类云监控)重点把数据采集、存储、可视化分析、告警判定这些问题解决好,负责产生告警事件,之后告警事件就交给 OnCall 中心来处理即可,OnCall 中心来负责告警事件的收敛降噪、抑制屏蔽、过滤分发等等诸多事宜。
好的 OnCall 产品都是商业产品,比如 PagerDuty、FlashDuty、Opsgenie 等,大家可以自行 Google,各取所需。
夜莺比 Prometheus 还多了啥有意思的功能?
这里我随便截几张系统图,略作介绍。
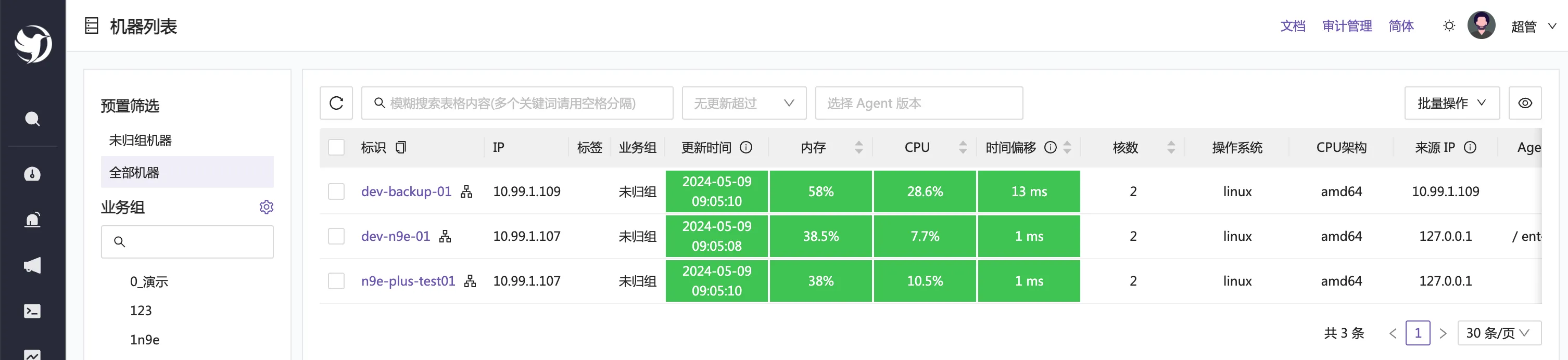
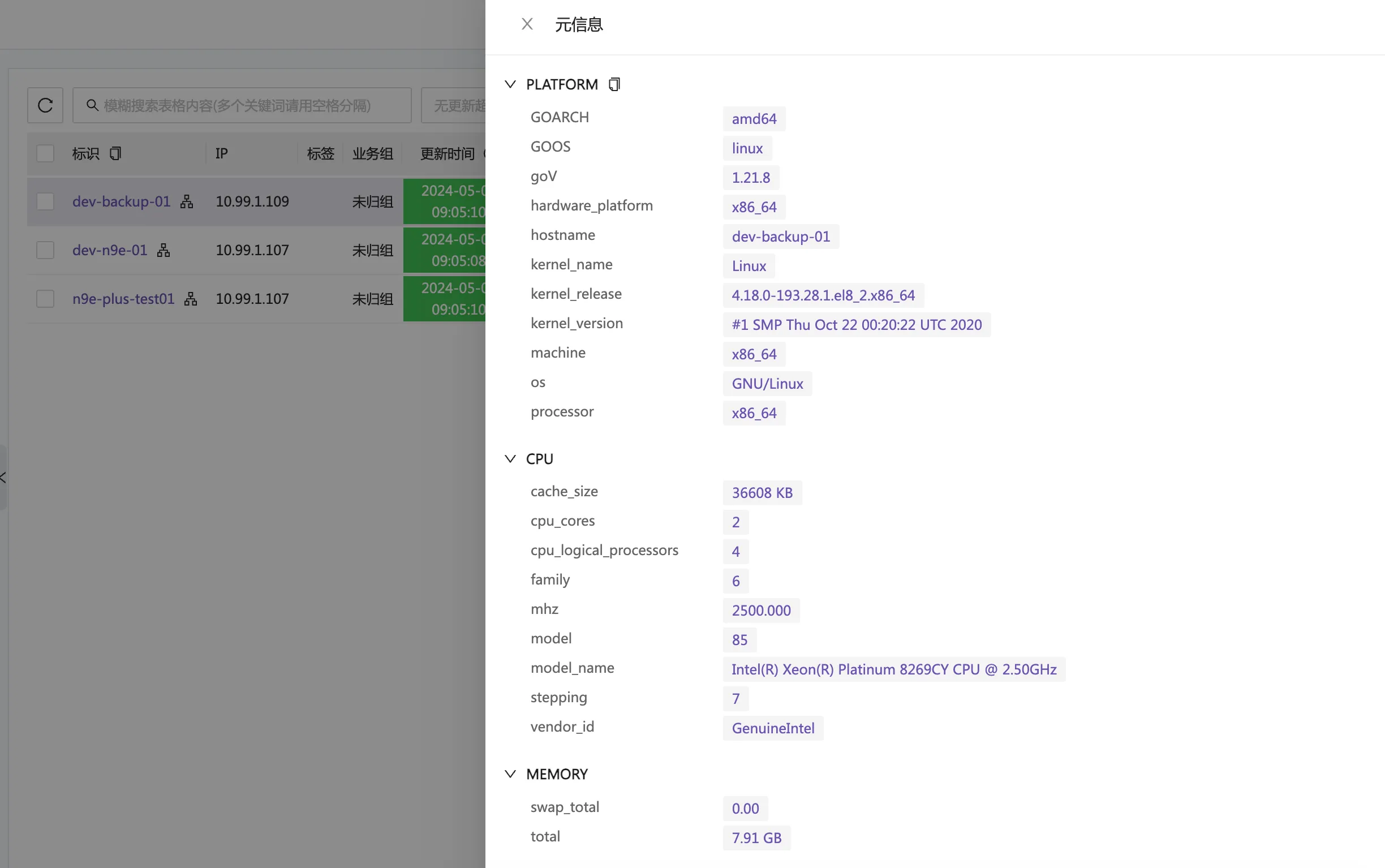
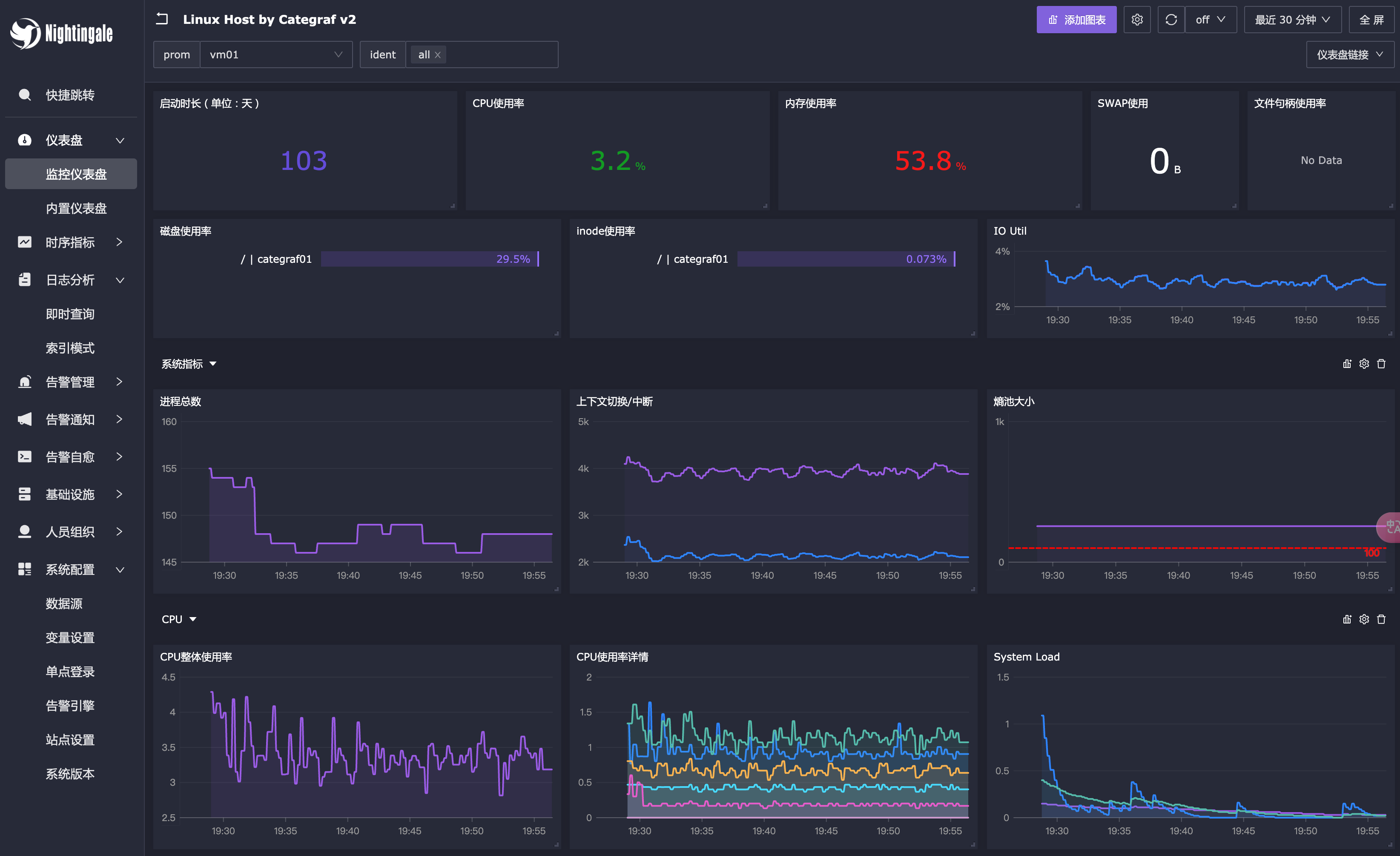
夜莺不做采集,可以对接市面上各类采集器,其中,categraf 采集器和夜莺的对接最为丝滑,使用 categraf 作为采集器的话,可以采集机器的各类元信息,构建一个轻量的机器层面的 CMDB。
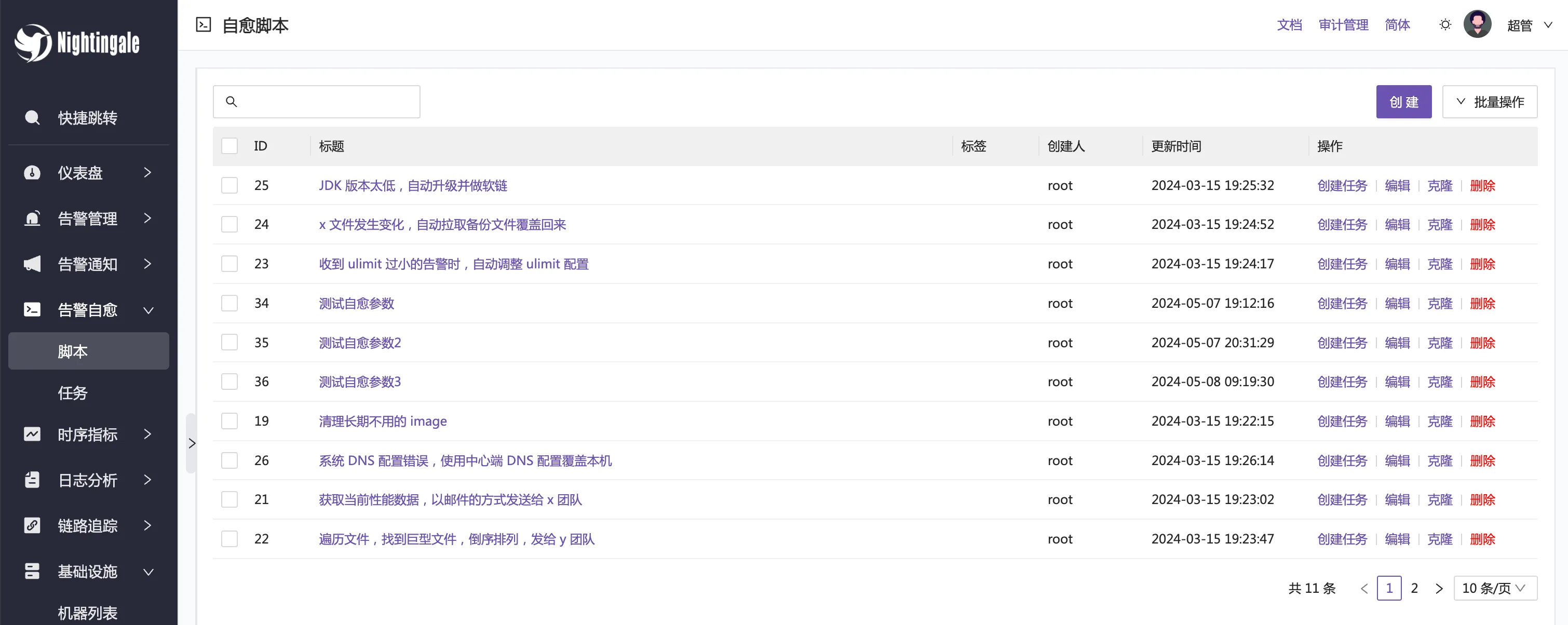
夜莺内置提供告警自愈的能力,即告警时可以自动到告警的机器上执行脚本,你可以在脚本里写一些自动化的修复逻辑。
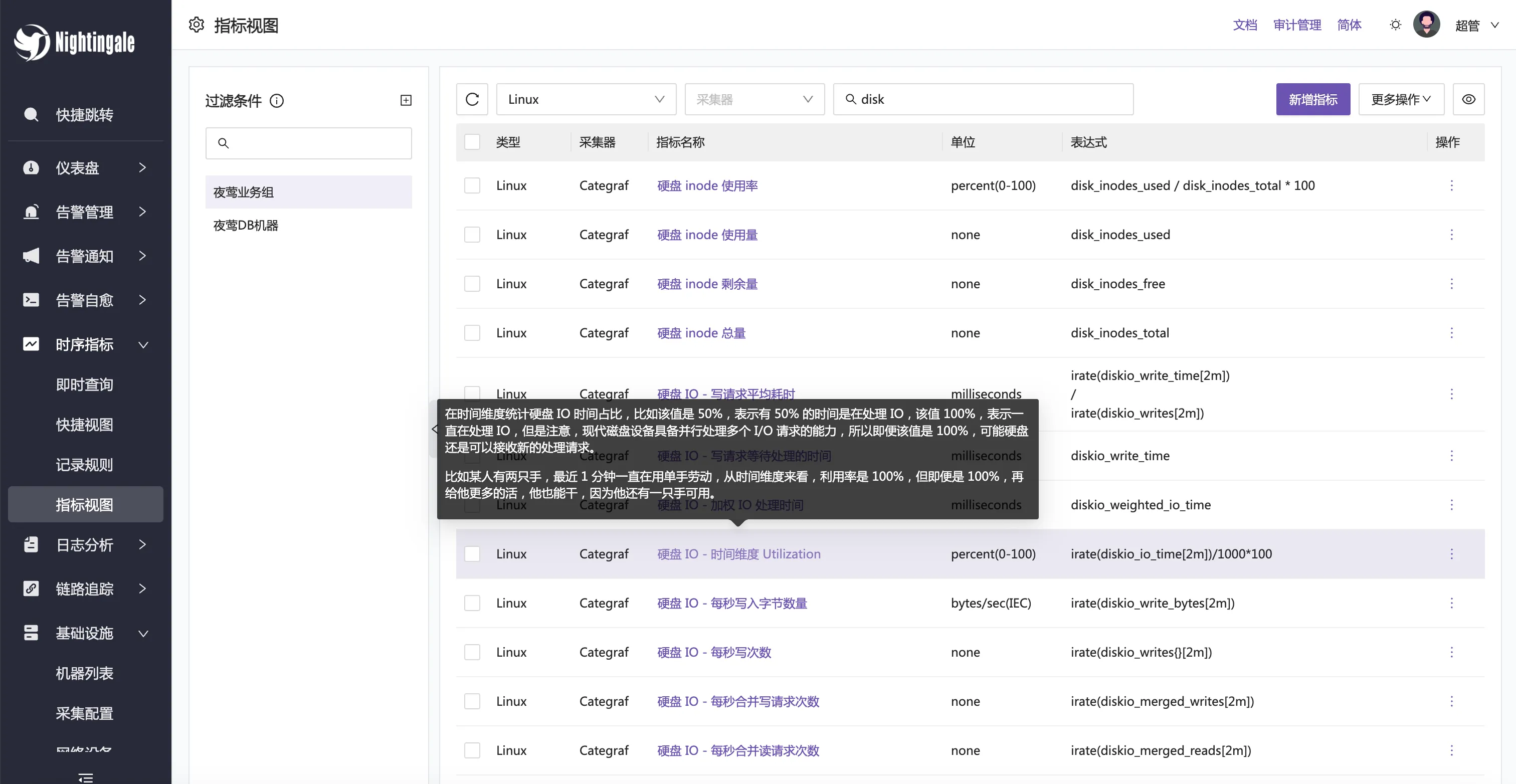
夜莺内置提供了指标视图,会在 v7 beta3 版本放出,会内置提供很多常用的 promql,点击查询即可,对小白用户会极为友好。
小结
已经有 Prometheus 了,为啥还需要夜莺(Nightingale)?本文算是对这个问题的一个探索性回复。希望对你有帮助,感谢大家的阅读。
已经有 Prometheus 了,还需要夜莺?的更多相关文章
- 5分钟了解Prometheus
Prometheus(译:普罗米修斯)用领先的开源监控解决方案为你的指标和警报提供动力(赋能). 1. 概述 1.1. Prometheus是什么? Prometheus是一个开源的系统监控和警报 ...
- Prometheus学习系列(三)之Prometheus 概念:数据模型、metric类型、任务、实例
前言 本文来自Prometheus官网手册1.Prometheus官网手册2 和 Prometheus简介 说明 Prometheus从根本上存储的所有数据都是时间序列: 具有时间戳的数据流只属于单个 ...
- Prometheus简介【转】
Prometheus简介 Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在 ...
- 01 . Prometheus简介及安装配置Grafana
Promethus简介 Prometheus受启发于Google的Brogmon监控系统(相似的Kubernetes是从Google的Brog系统演变而来),从2012年开始由前Google工程师在S ...
- 主流前沿的开源监控和报警系统Prometheus+Grafana入门之旅
Prometheus概述 定义 Prometheus 官网地址 https://prometheus.io/ Prometheus 官网文档地址 https://prometheus.io/docs/ ...
- Prometheus 特点
1.1 Prometheus的特点 Prometheus是一个开源的完整监控解决方案,其对传统监控系统的测试和告警模型进行了彻底的颠覆,形成了基于中央化的规则计算.统一分析和告警的新模型. 相比于传统 ...
- Kubernetes 学习23 kubernetes资源指标API及自定义指标API
一.概述 1.上集中我们说到,官方文档提示说从k8s 1.11版本开始,将监控体系指标数据获取机制移向新一代的监控模型.也就意味着对于我们的k8s来讲现在应该有这样两种资源指标被使用.一种是资源指标, ...
- 章节1-Prometheus基础(1)
目录 一.Prometheus安装部署 1. 简介 监控的目的 Prometheus的优势 2. Prometheus工作流程: 2.1 服务端 2.2 客户端 2.3 metrics主要数据类型 3 ...
- Prometheus-operator 介绍和配置解析
随着云原生概念盛行,对于容器.服务.节点以及集群的监控变得越来越重要.Prometheus 作为 Kubernetes 监控的事实标准,有着强大的功能和良好的生态.但是它不支持分布式,不支持数据导入. ...
- prometheus监控系统
关于Prometheus Prometheus是一套开源的监控系统,它将所有信息都存储为时间序列数据:因此实现一种Profiling监控方式,实时分析系统运行的状态.执行时间.调用次数等,以找到系统的 ...
随机推荐
- HarmonyOS NEXT应用开发之异常处理案例
介绍 本示例介绍了通过应用事件打点hiAppEvent获取上一次应用异常信息的方法,主要分为应用崩溃.应用卡死以及系统查杀三种. 效果图预览 使用说明: 点击构建应用崩溃事件,3s之后应用退出,然后打 ...
- 有效预警6要素:亿级调用量的阿里云弹性计算SRE实践
简介: 关注保持良好的预警处理,持续解决系统隐患,促进系统稳定健康发展. 编者按:随着分布式系统和业务需求的飞速发展,监控告警在我们保障系统稳定性和事故快速恢复的全周期中都是至关重要的.9月3号,阿里 ...
- 从 Flink Forward Asia 2021,看Flink未来开启新篇章
简介:本文将对FFA Keynote议题作一些简单的归纳总结,感兴趣的小伙伴们可以在FFA官网[2]找到相关主题视频观看直播回放. 作者 | 梅源(Yuan Mei) 来源 | 阿里技术公众号 ...
- 从操作系统层面分析Java IO演进之路
简介: 本文从操作系统实际调用角度(以CentOS Linux release 7.5操作系统为示例),力求追根溯源看IO的每一步操作到底发生了什么. 作者 | 道坚来源 | 阿里技术公众号 前言 本 ...
- 一文了解EPaxos核心协议流程
简介: EPaxos(Egalitarian Paxos)作为工业界备受瞩目的下一代分布式一致性算法,具有广阔的应用前景.但纵观业内,至今仍未出现一个EPaxos的工程实现,甚至都没看到一篇能把EPa ...
- [PHP] Laravel 联查中对不同表字段关系加条件的方式
如果条件需要加在 where 条件里,使用 whereColumn,如下示例: whereColumn('A.b_id', '=', 'B.id'); 如果需要加载 join 的 on 之后作为多个条 ...
- [FE] uni-app Grid 宫格组件 uni-grid 用法
文档上的描述是比较简陋的,不明所以. 核心就是两块内容,一个是 uni-grid 可以加 change 事件:另一个是 uni-grid-item 上面 index 属性值会作为 change 指定函 ...
- [Contract] Solidity 合约使用 truffle 部署到测试网和主网
使用 truffle 发布到非本地的以太坊主网或者测试网时,需要提供钱包的助记词或私钥. 首先安装 truffle 组件:npm install @truffle/hdwallet-provider ...
- WPF 自己封装 Skia 差量绘制控件
使用 Skia 能做到在多个不同的平台使用相同的一套 API 绘制出相同界面效果的图片,可以将图片绘制到应用程序的渲染显示里面.在 WPF 中最稳的方法就是通过 WriteableBitmap 作为承 ...
- vue-cli快速搭建项目的几个文件(一)
===========app.vue文件============= <template> <div id="app"> <router ...