Splay简介
Splay树,又叫伸展树,可以实现快速分裂合并一个序列,几乎可以完成平衡树的所有操作。其中最重要的操作是将指定节点伸展到指定位置,
节点定义
一棵普通的splay并不需要什么太多的附加数据,就像下面这样就好:
template<typename T>
class SplayNode {
public:
T data;
SplayNode* next[];
SplayNode* father;
SplayNode(){
memset(next, , sizeof(next));
}
SplayNode(T data, SplayNode* father):data(data), father(father){
memset(next, , sizeof(next));
}
int cmp(T a){
if(a == data) return -;
return (a > data) ? () : ();
}
};
伸展操作
伸展操作有三种情况,分为单旋转(一种情况)和双旋转(二种情况)
当伸展的节点的父节点为目标位置,那么只需要一次旋转就可以完成。和这个方向相反(如果为左子树,就右旋)
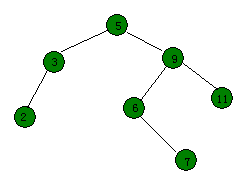
例如将开篇那张图中键值为3的点,伸展到根。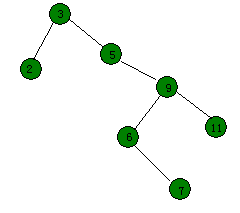
- 要伸展的节点的父节点和祖父节点共线,则先将父节点转上去,再将该节点转上去,例如上图,将键值为9的节点伸展到根。
- 第三种情况是要伸展的节点的父节点和祖父节点不共线(呈"之"字),此时先将该节点连续旋转两次达到祖父节点的位置。例如将第一张图的键值为6的节点伸展到根。

基本所有题目的数据范围都不至于使一次单旋转或双旋转就能够解决,所以实际中是通过三种情况组合进行伸展。
比如说将某个深度较深的节点伸展到根,会发现不光是这个节点的深度更小了(更浅),很多其它节点也有所受益。最坏的情况是O(n)(从小到大的数据中最小的一个伸展到根),最好的情况O(1)(刚好是父节点的直接的某个子树),平均是O(log2n)(我也不知道怎么算的,反正实际用起来绝对比这个慢,或者说常数很大,因为Splay不像AVL树和红黑树那样特别平衡)。
您可以考虑在插入、查找的过程中把结果伸展到根。
下面是代码:
inline void splay(SplayNode<T>* node, SplayNode<T>* father){
while(node->father != father){
SplayNode<T>* f = node->father;
int fd = f->cmp(node->data);
SplayNode<T>* ff = f->father;
if(ff == father){
rotate(f, fd ^ );
break;
}
int ffd = ff->cmp(f->data);
if(ffd == fd){
rotate(ff, ffd ^ );
rotate(f, fd ^ );
}else{
rotate(f, fd ^ );
rotate(ff, ffd ^ );
}
}
if(father == NULL)
root = node;
}
插入操作
Splay的插入操作很简单,按照BST的性质插进去,然后伸展到根。
//实际过程
static SplayNode<T>* insert(SplayNode<T>*& node, SplayNode<T>* father, T data){
if(node == NULL){
node = new SplayNode<T>(data, father);
return node;
}
int d = node->cmp(data);
if(d == -) return NULL;
return insert(node->next[d], node, data);
} //用户调用
inline SplayNode<T>* insert(T data){
SplayNode<T>* res = insert(root, NULL, data);
if(res != NULL) splay(res, NULL);
return res;
}
删除操作
虽然Treap的删除貌似在这也可以借鉴一下,但是还是希望用到splay函数。
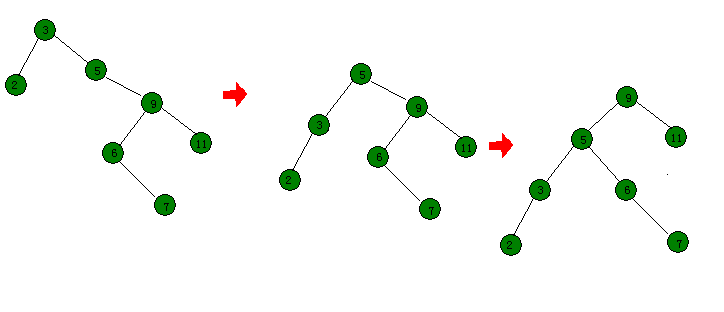
比如开始那张图,要删除键值为7的节点,那么先把它伸展到根:
如果某棵子树为空,那么直接删掉就好了,然后改下root。
先假设键值为6的节点不存在,那么直接用键值为5的节点来代替根节点就好了。可是事实上有键值为6的节点。那么想一种情况根节点的左子树的右子树为空的情况。很巧根据BST的性质(设根节点为x,根节点的左子树为y,y的右子树为z),那么x > z > y。如果不存在z,也就是说y是x的前驱(小于x且最大的数)。
根据前驱的定义,可以写出一下找根节点的前驱的代码。
SplayNode<T>* maxi = re->next[];
while(maxi->next[] != NULL) maxi = maxi->next[];
找到前驱然后伸展到根节点的左子树。最后的结果图:

实际应用时通常会加入永远都不可能被删掉的最小的一个节点(哨兵节点),这样根就不存在要删的节点的左子树为空的情况。所以可以省下一些代码。
代码:
inline boolean remove(T data){
SplayNode<T>* re = find(data);
if(re == NULL) return false;
SplayNode<T>* maxi = re->next[];
if(maxi == NULL){
root = re->next[];
if(re->next[] != NULL) re->next[]->father = NULL;
delete re;
return true;
}
while(maxi->next[] != NULL) maxi = maxi->next[];
splay(maxi, re);
maxi->next[] = re->next[];
if(re->next[] != NULL) re->next[]->father = maxi;
maxi->father = NULL;
delete re;
root = maxi;
return true;
}
前驱后继操作
首先把要求前驱或后继的节点伸展到根。然后很容易就想到。
inline SplayNode<T>* findPre(SplayNode<T>* node) {
if(node != root) splay(node, NULL);
SplayNode<T>* s = node->next[];
while(s != NULL && s->next[] != NULL) s = s->next[];
return s;
}
inline SplayNode<T>* findSuf(SplayNode<T>* node) {
if(node != root) splay(node, NULL);
SplayNode<T>* s = node->next[];
while(s != NULL && s->next[] != NULL) s = s->next[];
return s;
}
如果不是该树内的节点,后继用upper_bound,前驱就用自创的less_bound。思路和upper_bound差不多。
static SplayNode<T>* less_bound(SplayNode<T>*& node, T val){
if(node == NULL) return node;
int to = node->cmp(val);
if(val == node->data) to = ;
SplayNode<T>* ret = less_bound(node->next[to], val);
return (ret == NULL && node->data < val) ? (node) : (ret);
}
SplayNode<T>* less_bound(T data){
SplayNode<T>* p = less_bound(root, data);
if(p != NULL)
splay(p, NULL);
return p;
}
可重Splay
·节点定义
既然让Splay支持重复的内容,那么就要加入一个count。因为根据BST的性质,新加入的重复的节点,放哪都会破坏性质(因为都是大于或小于),所以只好加在原先节点的头上
template<typename T>
class SplayNode {
public:
T data;
int count; //这里
SplayNode* next[];
SplayNode* father;
SplayNode(){
9 memset(next, , sizeof(next));
}
SplayNode(T data, SplayNode* father):data(data), father(father), count(){
memset(next, , sizeof(next));
}
int cmp(T a){
if(a == data) return -;
return (a > data) ? () : ();
}
void addCount(int val){ //这里
this->count += val;
}
};
·插入 & 删除操作
插入特判是否有重复的键值,删除特判count为0.(即是否需要移除节点)
名次操作
要进行名次操作(K小值和x的排名)对于一个节点,要做到O(log2n) 就要想办法通过某些手段不做一些无用的访问。这时可以考虑加入一个s(size)附加数据,记录该子树上的节点(数据,包括重复的内容)个数。
而且旋转后某些节点的s需要改变,所以需要一个维护s的函数
template<typename T>
class SplayNode {
public:
T data;
int s; //这里
int count;
SplayNode* next[];
SplayNode* father;
//.......
void maintain(){ //这里
s = count;
for(int i = ; i < ; i++)
if(next[i] != NULL)
s += next[i]->s;
}
void addCount(int val){
this->s += val;
this->count += val; //这里
}
};
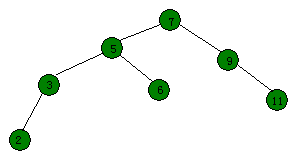
旋转时,如何确定待维护节点?先看一下下图(怎么感觉两张图都有在树链剖分)

由此可以得出规律,旧的"根节点"和新的"根节点"需要维护。
inline static void rotate(SplayNode<T>*& node, int d){
//.......
node->maintain();
node->father->maintain();
}
首先来说求K小值吧,从根节点开始访问(这不是废话吗),然后确定左子树的个数ls,如果左子树为空,那么就记为0。
很容易就能想到一个节点的左子树的个数为ls个,那么以这个节点为根的树上,根的排名是(ls + 1)名。于是我们可以得出递归的边界(写成while也行)
if(k >= ls + && k <= ls + node->count) return node;
如果访问左子树(k <= ls),那么没有什么特别的。但是如果访问右子树,你现在要求的右子树上的第某小值,而k是对于当前的node来说,所以应该减去s和node->count。
K小值代码:
static SplayNode<T>* findKth(SplayNode<T>*& node, int k){
int ls = (node->next[] != NULL) ? (node->next[]->s) : ();
if(k >= ls + && k <= ls + node->count) return node;
if(k <= ls) return findKth(node->next[], k);
return findKth(node->next[], k - ls - node->count);
}
inline SplayNode<T>* findKth(int k){
if(k <= || k > root->s) return NULL;
SplayNode<T>* p = findKth(root, k);
splay(p, NULL);
return p;
}
求x的排名就很简单了。还是访问,比当前节点小,访问左子树,相等返回r + 1,否则访问右子树,r加上当前节点的左子树的大小和count。如果访问到了NULL,返回r + 1。
为什么返回的都是r + 1呢?
因为加的左子树的大小等都是确定比它小的节点的个数。
下面是代码:
inline int rank(T data){
SplayNode<T>* p = root;
int r = ;
while(p != NULL){
int ls = (p->next[] != NULL) ? (p->next[]->s) : ();
if(p->data == data) return r + ls + ;
int d = p->cmp(data);
if(d == ) r += ls + p->count;
p = p->next[d];
}
return r + ;
}
区间操作
·split(int from, int end)
从原树中分离出一段区间[from, end]。
和之前删除的思想一样,调用splay函数使某个(没错,就是一个)特定的子树就是这一个区间。这里不好想,我就直接说吧。
/*
* 先找到第(end + 1)名,然后伸展到根,然后找到(from - 1)名,伸展到根的左子树。然后根的左子树的右子树就是这个区间了。
* 当然(end + 1)和(from - 1)都不一定会存在,所以特判或者加入哨兵节点。
*/
SplayNode<T>* split(int from, int end){
if(from > end) return NULL;
if(from == && end == root->s){
findKth(, NULL);
return this->root;
}
if(from == ){
findKth(end + , NULL);
findKth(from, root);
return root->next[];
}
if(end == root->s){
findKth(from - , NULL);
findKth(end, root);
return root->next[];
}
findKth(end + , NULL);
findKth(from - , root);
return root->next[]->next[];
}
分离区间
不过通常都需要用Splay来处理字符串等,这些是按照数组下标来建立Splay。翻转也是家常便饭,因此只能靠访问的顺序来当成"下标"(翻转后很难修改记录的下标)。
至于翻转操作就打lazy标记,然后建立一个pushDown()函数
void pushDown(){
swap(next[], next[]);
for(int i = ; i < ; i++)
if(next[i] != NULL)
next[i]->lazy ^= ;
lazy = false;
}
就像这样,很多区间操作都可以做。
Splay简介的更多相关文章
- [数据结构]Splay简介
Splay树,又叫伸展树,可以实现快速分裂合并一个序列,几乎可以完成平衡树的所有操作.其中最重要的操作是将指定节点伸展到指定位置, 目录 节点定义 旋转操作 伸展操作 插入操作 删除操作 lower_ ...
- splay详解(一)
前言 Spaly是基于二叉查找树实现的, 什么是二叉查找树呢?就是一棵树呗:joy: ,但是这棵树满足性质—一个节点的左孩子一定比它小,右孩子一定比它大 比如说 这就是一棵最基本二叉查找树 对于每次插 ...
- 【BZOJ】1507: [NOI2003]Editor(Splay)
http://www.lydsy.com/JudgeOnline/problem.php?id=1507 当练splay模板了,发现wjmzbmr的splay写得异常简介,学习了.orzzzzzzzz ...
- [模板] 平衡树: Splay, 非旋Treap, 替罪羊树
简介 二叉搜索树, 可以维护一个集合/序列, 同时维护节点的 \(size\), 因此可以支持 insert(v), delete(v), kth(p,k), rank(v)等操作. 另外, prev ...
- 平衡树简单教程及模板(splay, 替罪羊树, 非旋treap)
原文链接https://www.cnblogs.com/zhouzhendong/p/Balanced-Binary-Tree.html 注意是简单教程,不是入门教程. splay 1. 旋转: 假设 ...
- [洛谷日报第62期]Splay简易教程 (转载)
本文发布于洛谷日报,特约作者:tiger0132 原地址 分割线下为copy的内容 [洛谷日报第62期]Splay简易教程 洛谷科技 18-10-0223:31 简介 二叉排序树(Binary Sor ...
- Splay模板讲解及一些题目
普通平衡树模板以及文艺平衡树模板链接. 简介 平衡二叉树(Balanced Binary Tree)具有以下性质:它是一棵空树或它的左右两个子树的高度差的绝对值不超过1,并且左右两个子树都是一棵平衡二 ...
- 伸展树(Splay Tree)进阶 - 从原理到实现
目录 1 简介 2 基础操作 2.1 旋转 2.2 伸展操作 3 常规操作 3.1 插入操作 3.2 删除操作 3.3 查找操作 3.4 查找某数的排名.查找某排名的数 3.4.1 查找某数的排名 3 ...
- [学习笔记]平衡树(Splay)——旋转的灵魂舞蹈家
1.简介 首先要知道什么是二叉查找树. 这是一棵二叉树,每个节点最多有一个左儿子,一个右儿子. 它能支持查找功能. 具体来说,每个儿子有一个权值,保证一个节点的左儿子权值小于这个节点,右儿子权值大于这 ...
随机推荐
- gitlab svlogd runsv 基于Rotated Log的日志统计
小结: 1. 日志轮询 log roate 日志文件自动转存和重命名 2. rotated log独立于其他模块,可以以静态库或者动态库的形式支持二次开发: 3. [root@d1 ~]# gitla ...
- vue - vue + vue-router + vuex 简单项目
简单的,我的首页,我的笔记项目 vue + vue-router + vuex View + VM(ViewModel) + Model (webpack) vue init webpack lint ...
- 2018/04/07 每日一个Linux命令 之 logrotate
简介 日志的存在一直是 Linux 里面一个比较重要内容. 但是随着服务器运行的时间越来越长,日志越来越大.我见过一个线上项目 TP3.2 log文件有260+G的...... logrotate 也 ...
- Mayor's posters---poj2528线段树、离散化
题目链接:http://poj.org/problem?id=2528 题意:有n张海报要贴,每张需要用的区间为L到R,后面的可以贴在之前的上面,就是吧之前的挡住,求最后我们能看到几张海报: 我们可以 ...
- 【JMeter】集合点的设置
[JMeter]集合点的设置 简单来理解一下,虽然我们的“性能测试”理解为“多用户并发测试”,但真正的并发是不存在的,为了更真实的实现并发这感念,我们可以在需要压力的地方设置集合点,每到输入用户名和密 ...
- Pycharm自动换行
只对当前文件有效的操作是菜单栏->View -> Active Editor -> Use Soft Wraps. 要是想对所有文件都起到效果,就要在setting里面进行操作.Pe ...
- 模仿linux内核定时器代码,用python语言实现定时器
大学无聊的时候看过linux内核的定时器,如今已经想不起来了,也不知道当时有没有看懂,如今想要模仿linux内核的定时器.用python写一个定时器,已经想不起来它的设计原理了.找了一篇blog,li ...
- HTML <input> 标签的 name 属性
定义和用法 name 属性规定 input 元素的名称. name 属性用于对提交到服务器后的表单数据进行标识,或者在客户端通过 JavaScript 引用表单数据. 注释:只有设置了 name 属性 ...
- Twitter OA prepare: Visit element of the array
分析:就是建立一个boolean array来记录array里面每个元素的访问情况,遇到访问过的元素就停止visiting,返回未访问的结点个数 public int visiting(int[] A ...
- 《User Modeling with Neural Network for Review Rating Prediction》评论打分预测
摘要: 传统的评分预测只考虑到了文本信息,没有考虑到用户的信息,因为同一个词 在不同的用户表达中是不一样的.同样good 一词, 有人觉得5分是good 有人觉得4分是good.但是传统的文本向量表达 ...