Kafka核心组件
一、Kafka核心组件及工作方式
Producer :消息生产者,就是向kafka broker发消息的客户端
Consumer :消息消费者,向kafka broker取消息的客户端
Topic :消息主题
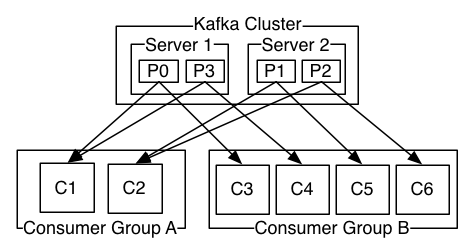
ConsumerGroup(CG):这是kafka用来实现一个topic消息的广播(发给所有的consumer)和单播(发给任意一个consumer)的手段。一个topic可以有多个CG。topic的消息会复制(不是真的复制,是概念上的)到所有的CG,但每个partition只会把消息发给该CG中的一个consumer。如果需要实现广播,只要每个consumer有一个独立的CG就可以了。要实现单播只要所有的consumer在同一个CG。用CG还可以将consumer进行自由的分组而不需要多次发送消息到不同的topic。
Broker :一台kafka服务器就是一个broker。一个集群由多个broker组成。一个broker可以容纳多个topic。
Partition:为了实现扩展性,一个非常大的topic可以分布到多个broker(即服务器)上,一个topic可以分为多个partition,每个partition是一个有序的队列。partition中的每条消息都会被分配一个有序的id(offset)。kafka只保证按一个partition中的顺序将消息发给consumer,不保证一个topic的整体(多个partition间)的顺序。
Offset:kafka的存储文件都是按照offset.kafka来命名,用offset做名字的好处是方便查找。例如你想找位于2049的位置,只要找到2048.kafka的文件即可。当然the first offset就是00000000000.kafka

二、消息发送
Producer客户端负责消息的分发,kafka集群中的任何一个broker都可以向producer提供metadata信息,这些metadata中包含"集群中存活的servers列表"/"partitions leader列表"等信息,当producer获取到metadata信息之后, producer将会和Topic下所有partition leader保持socket连接;
消息由producer直接通过socket发送到broker,中间不会经过任何"路由层",事实上,消息被路由到哪个partition上由producer客户端决定,比如可以采用"random""key-hash""轮询"等,如果一个topic中有多个partitions,那么在producer端实现"消息均衡分发"是必要的,在producer端的配置文件中,开发者可以指定partition路由的方式。
在Producer消息发送时可以指定对应的应答机制,设置发送数据是否需要服务端的反馈,有三个值0,1,-1
0: producer不会等待broker发送ack
1: 当leader接收到消息之后发送ack
-1: 当所有的follower都同步消息成功后发送ack
参数形式:request.required.acks=0
三、消息消费
本质上kafka只支持Topic;每个group中可以有多个consumer,每个consumer属于一个consumer group;
通常情况下,一个group中会包含多个consumer,这样不仅可以提高topic中消息的并发消费能力,而且还能提高"故障容错"性,如果group中的某个consumer失效那么其消费的partitions将会有其他consumer自动接管。
对于Topic中的一条特定的消息,只会被订阅此Topic的每个group中的其中一个consumer消费,此消息不会发送给一个group的多个consumer,一个group中所有的consumer将会交错的消费整个Topic,每个group中consumer消息消费互相独立,我们可以认为一个group是一个"订阅"者。
在kafka中,一个partition中的消息只会被group中的一个consumer消费(同一时刻);
一个Topic中的每个partions,只会被一个"订阅者"中的一个consumer消费,不过一个consumer可以同时消费多个partitions中的消息。
kafka的设计原理决定,对于一个topic,同一个group中不能有多于partitions个数的consumer同时消费,否则将意味着某些consumer将无法得到消息。
kafka只能保证一个partition中的消息被某个consumer消费时是顺序的;事实上,从Topic角度来说,当有多个partitions时,消息仍不是全局有序的。
四、负载均衡
当一个group中,有consumer加入或者离开时,会触发partitions均衡.均衡的最终目的,是提升topic的并发消费能力,步骤如下:
(1)假如topic1,具有如下partitions: P0,P1,P2,P3
(2)加入group中,有如下consumer: C1,C2
(3)首先根据partition索引号对partitions排序: P0,P1,P2,P3
(4)根据consumer.id排序: C0,C1
(5)计算倍数: M = [P0,P1,P2,P3].size / [C0,C1].size,本例值M=2(向上取整)
(6)然后依次分配partitions: C0 = [P0,P1],C1=[P2,P3],即Ci = [P(i * M),P((i + 1) * M -1)]
Kafka核心组件的更多相关文章
- Kafka核心组件详解
1.概述 对于Kafka的学习,在研究其系统模块时,有些核心组件是指的我们去了解.今天给大家来剖析一下Kafka的一些核心组件,让大家能够更好的理解Kafka的运作流程. 2.内容 Kafka系统设计 ...
- Kafka 设计与原理详解
一.Kafka简介 本文综合了我之前写的kafka相关文章,可作为一个全面了解学习kafka的培训学习资料. 转载请注明出处 : 本文链接 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索. ...
- Kafka概念入门(一)
序:如何保证kafka全局消息有序? 比如,有100条有序数据,生产者发送到kafka集群,kafka的分片有4个,可能的情况就是一个分片保存0-25,一个保存25-50......这样消息在kafk ...
- Kafka学习资料
博客系列: Apache Kafka简介Apache Kafka安装和使用Apache Kafka核心概念kafka核心组件和流程—控制器kafka核心组件和流程—协调器kafka核心组件和流程—日志 ...
- Kafka集群安装部署、Kafka生产者、Kafka消费者
Storm上游数据源之Kakfa 目标: 理解Storm消费的数据来源.理解JMS规范.理解Kafka核心组件.掌握Kakfa生产者API.掌握Kafka消费者API.对流式计算的生态环境有深入的了解 ...
- 一脸懵逼学习KafKa集群的安装搭建--(一种高吞吐量的分布式发布订阅消息系统)
kafka的前言知识: :Kafka是什么? 在流式计算中,Kafka一般用来缓存数据,Storm通过消费Kafka的数据进行计算.kafka是一个生产-消费模型. Producer:生产者,只负责数 ...
- 最全Kafka 设计与原理详解【2017.9全新】
一.Kafka简介 1.1 背景历史 当今社会各种应用系统诸如商业.社交.搜索.浏览等像信息工厂一样不断的生产出各种信息,在大数据时代,我们面临如下几个挑战: 如何收集这些巨大的信息 如何分析它 如何 ...
- kafka学习总结之kafka核心
1. Kafka核心组件 (1)replication(副本).partition(分区) 一个topic可以有多个副本,副本的数量决定了有多少个broker存放写入的数据:副本是以partitio ...
- JMS规范与Kafka
一.为什么需要消息队列 消息队列的核心作用就是三点:解耦一个系统中各个子模块的互相绑定与依赖,异步执行后台耗时逻辑,并行处理一个请求中涉及的多个操作. 以我们常见的下订单场景来说明,我们熟悉的淘宝,后 ...
随机推荐
- 纯css制作带三角(兼容所有浏览器)
如何用 border 来制作三角. html 代码如下: 代码如下: <div class="arrow-up"></div> <div class= ...
- CacheDependency 的使用方法
//创建缓存依赖项 CacheDependency dep = new CacheDependency(fileName); //创建缓存 HttpContext.Current.Cache.Inse ...
- GlusterFS六大卷模式說明
GlusterFS六大卷說明 第一,分佈卷 在分布式卷文件被随机地分布在整个砖的体积.使用分布式卷,你需要扩展存储,冗余是重要或提供其他硬件/软件层.(簡介:分布式卷,文件通过hash算法随机的分 ...
- sysbench 压力测试工具
一.sysbench压力测试工具简介: sysbench是一个开源的.模块化的.跨平台的多线程性能测试工具,可以用来进行CPU.内存.磁盘I/O.线程.数据库的性能测试.目前支持的数据库有MySQL. ...
- linux中守护进程启停工具start-stop-daemon
1.功能作用 启动和停止系统守护程序 2.位置 /sbin/start-stop-daemon 3.主要参数 Commands: -S|--start -- <argument> ... ...
- C# 日志系统 log4net 配置及使用
1.引用Dll 版本是:1.2.10.0,下载Dll 2.Web.config文件配置 <?xml version="1.0" encoding="utf-8&qu ...
- [励志英语片段]practicing deliberately
最近看到一篇鸡汤文,觉得措词造句皆为吾辈所能接受,以后可以用作写作或口语素材~ 文章中心思想:同样是训练100小时,结果可以大不一样~所以不要用时间来欺骗自己. Consider the activi ...
- C++ vs Python向量运算速度评测
本文的起源来自最近一个让我非常不爽的事. 我最近在改一个开源RNN工具包currennt(http://sourceforge.net/projects/currennt/),想用它实现RNNLM功能 ...
- mysql union查询
1.mysql总是通过创建并填充临时表来执行union查询; 2.除非要服务器消除重复的行,否则一定要用union all.如果没有all关键字,mysql会在临时表加个distinct选项,会导致临 ...
- nginx 开机自动启动
接下来聊一聊nginx的开机自启吧 看了看都是用脚本启动的,我也就不扯啥犊子了,都是前人经验 我的操作系统是centos 7 nginx版本是1.10.3 首先看一下自己的nginx配置 我的是 ./ ...