SpringBoot中使用消息中间件Kafka实现Websocket的集群
1、在实际项目中,由于数据量的增大及并发数的增多,我们不可能只用一台Websocket服务,这个时候就需要用到Webscoket的集群。但是Websocket集群会遇到一些问题。首先我们肯定会想到直接将Websocket的Session放到Redis等缓存服务器中,然后用的时候直接在Redis中获取。但是Webscoket的Session比较特殊,它不能被序列化,因为 WebSocket的session是有状态的,还有就是 WebSocket的session是有时效性的,只要连接一断开,该Session就会失效。
2、解决Websocket集群的三种方法
2.1、通过相应的算法,将有关联的用户(即有可能发生聊天的对象)全部指定到一台Webscoket服务。这样就不会存在聊天对象收不到消息的情况。但是这种方法有局限性,就是用户只能和有关联的用户聊天,不能和其他未建立关联的用户聊天。
2.2、使用Redis的消息订阅功能来实现WebSocket集群。大致思路如下图。
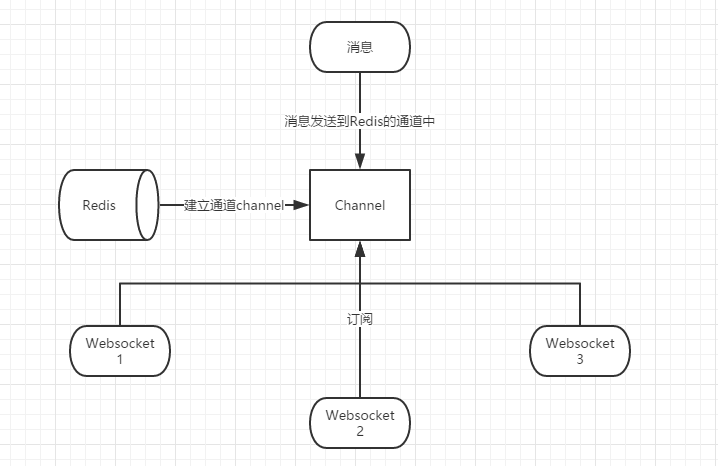
2.3、使用Kafka等消息中间件来实现Webscoket集群。这也是目前我选用的方式。其实该方法和Redis的消息订阅大致思路差不多。但是Redis我们只把他作为缓存使用,不想Redis涉及太多的业务处理,因此就选用了Kafka。
2.3.1、Kafka安装。(百度上有)
2.3.2、Kafka实现集群的大致思路,如下图(如果一个groupId下有多个消费者,则只会有一个消费者能获取到消息,所以为了保证Websocket集群都能收到消息,则需要不同的groupId。我使用的是服务器的IP来作为groupId)

2.3.3、在项目的pom文件中添加Kafka依赖(注:Kafka依赖的版本必须和服务器上安装的版本一致)
<!-- kafka依赖 -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>1.1.0.RELEASE</version>
</dependency>
2.3.4、建立Kafka的生产者Bean
package com.yxl.configuration; import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.core.DefaultKafkaProducerFactory;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.kafka.core.ProducerFactory; import java.util.HashMap;
import java.util.Map; /**
* @Author: yxl
* @Description: Kafka生产者(消息发送者)
* @DATE: Created in 2018/11/14
*/
@Configuration
@EnableKafka
public class KafkaProducerConfig { public Map<String, Object> producerConfigs() {
Map<String, Object> properties = new HashMap<>();
properties.put("bootstrap.servers", "kafka集群IP1:9092,kafka集群IP2:9092");
properties.put("acks", "all");//ack是判别请求是否为完整的条件(就是是判断是不是成功发送了)。我们指定了“all”将会阻塞消息,这种设置性能最低,但是是最可靠的。
properties.put("retries", 0);//如果请求失败,生产者会自动重试,我们指定是0次,如果启用重试,则会有重复消息的可能性。
properties.put("batch.size", 16384);//producer(生产者)缓存每个分区未发送消息。缓存的大小是通过 batch.size 配置指定的
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
return properties;
} public ProducerFactory<String, String> producerFactory() {
return new DefaultKafkaProducerFactory<>(producerConfigs());
} @Bean
public KafkaTemplate<String, String> kafkaTemplate() {
return new KafkaTemplate<String, String>(producerFactory());
} }
2.3.4、建立Kafka的消费者Bean以及消费者监听
package com.yxl.configuration; import com.yxl.myListener.MyKafkaListener;
import org.apache.commons.lang3.StringUtils;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.kafka.annotation.EnableKafka;
import org.springframework.kafka.config.ConcurrentKafkaListenerContainerFactory;
import org.springframework.kafka.config.KafkaListenerContainerFactory;
import org.springframework.kafka.core.ConsumerFactory;
import org.springframework.kafka.core.DefaultKafkaConsumerFactory;
import org.springframework.kafka.listener.ConcurrentMessageListenerContainer; import java.net.InetAddress;
import java.net.UnknownHostException;
import java.util.HashMap;
import java.util.Map;
import java.util.UUID; /**
* @Author: yxl
* @Description: Kafka消费者
* @DATE: Created in 2018/11/14
*/
@Configuration
@EnableKafka
public class KafkaConsumerConfig { @Bean
public KafkaListenerContainerFactory<ConcurrentMessageListenerContainer<String, String>> kafkaListenerContainerFactory() {
ConcurrentKafkaListenerContainerFactory<String, String> factory = new ConcurrentKafkaListenerContainerFactory<>();
factory.setConsumerFactory(consumerFactory());
factory.getContainerProperties().setPollTimeout(1500);
return factory;
} public ConsumerFactory<String, String> consumerFactory() {
return new DefaultKafkaConsumerFactory<>(consumerConfigs());
} public Map<String, Object> consumerConfigs() {
Map<String, Object> properties = new HashMap<>();
properties.put("bootstrap.servers", "kafka集群IP1:9092,kafka集群IP2:9092");
properties.put("group.id", getIPAddress()); //获取服务器Ip作为groupId
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "1000");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "30000");
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
return properties;
} public String getIPAddress() {
try {
InetAddress address = InetAddress.getLocalHost();
if (address != null && StringUtils.isNotBlank(address.getHostAddress())) {
return address.getHostAddress();
}
}catch (UnknownHostException e) {
return UUID.randomUUID().toString().replace("-","");
}
return UUID.randomUUID().toString().replace("-","");
} /**
* 自定义监听
*/
@Bean
public MyKafkaListener listener() {
return new MyKafkaListener();
}
}
2.3.4、消费者监听
package com.yxl.myListener; import com.yxl.websocket.ChatWebsocket;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.log4j.Logger;
import org.springframework.kafka.annotation.KafkaListener; /**
* @Author: yxl
* @Description:
* @DATE: Created in 2018/11/14
*/
public class MyKafkaListener { Logger logger = Logger.getLogger(MyKafkaListener.class); /**
* 发送聊天消息时的监听
* @param record
*/
@KafkaListener(topics = {"chatMessage"})
public void listen(ConsumerRecord<?, ?> record) {
logger.info("chatMessage发送聊天消息监听:"+record.value().toString());
ChatWebsocket chatWebsocket = new ChatWebsocket();
chatWebsocket.kafkaReceiveMsg(record.value().toString());
} /**
* 关闭连接时的监听
* @param record
*/
@KafkaListener(topics = {"closeWebsocket"})
private void closeListener(ConsumerRecord<?, ?> record) {
logger.info("closeWebsocket关闭websocket连接监听:"+record.value().toString());
ChatWebsocket chatWebsocket = new ChatWebsocket();
chatWebsocket.kafkaCloseWebsocket(record.value().toString());
} }
2.3.6、Websocket集群java代码
package com.kk.server.chat.websocket; import com.alibaba.fastjson.JSON;
import com.alibaba.fastjson.JSONObject;
import org.apache.commons.lang.StringUtils;
import org.apache.log4j.Logger;
import org.springframework.context.ApplicationContext;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.stereotype.Component; import javax.websocket.*;
import javax.websocket.server.PathParam;
import javax.websocket.server.ServerEndpoint;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap; /**
* Websocket集群
* Created by yxl on 2018-11-17.
*/
@ServerEndpoint("/chat/{userId}")
@Component
public class ChatWebsocket { private Logger logger = Logger.getLogger(ChatWebsocket.class); private static ApplicationContext applicationContext; private KafkaTemplate kafkaTemplate; //静态变量,用来记录当前在线连接数。应该把它设计成线程安全的。
private static int onlineCount = 0;
//concurrent包的线程安全Set,用来存放每个客户端对应的MyWebSocket对象。若要实现服务端与单一客户端通信的话,可以使用Map来存放,其中Key可以为用户标识
private static Map<String, Session> drWebSocketSet = new ConcurrentHashMap<>(); //医生web /**
* 连接建立成功调用的方法
*
* @param userId 用户标识
*/
@OnOpen
public void onOpen(@PathParam("userId") String userId, Session session) { if (kafkaTemplate == null) {
kafkaTemplate = applicationContext.getBean(KafkaTemplate.class); //获取kafka的Bean实例
} drWebSocketSet.put(userId, session);
} /**
* s
* 收到客户端消息后调用的方法
*
* @param message 客户端发送过来的消息
* @param session 可选的参数
*/
@OnMessage
public void onMessage(String message, Session session) throws IOException {
if ("ping".equals(message)) {
session.getBasicRemote().sendText("pong"); //心跳
} else {
sendMessage(message, session); //调用Kafka进行消息分发
} } /**
* 发送消息
*
* @param message
* @param session
* @throws IOException
*/
public void sendMessage(String message, Session session) throws IOException {
if (StringUtils.isNotBlank(message)) { JSONObject jsonObject = JSONObject.parseObject(message); String sender_id = jsonObject.getString("sender_id"); //发送者ID
String receiver_id = jsonObject.getString("receiver_id"); //接受者ID //TODO 这里可以进行优化。可以首先根据接收方的userId,即receiver_id判断接收方是否在当前服务器,若在,直接获取session发送即可就不需要走Kafka了,节约资源
kafkaTemplate.send("chatMessage", s);
}
} /**
* 连接关闭调用的方法
*/
@OnClose
public void onClose(Session session) {
Map<String, String> pathParameters = session.getPathParameters();
String userId = pathParameters.get("userId"); //从session中获取userId
Map<String, String> map = new HashMap<>();
map.put("username", userId);
kafkaTemplate.send("closeWebsocket", JSON.toJSONString(map));
}
} /**
* 关闭连接
*
* @param map 当前登录客户端的map
*/
private void close(Map<String, Session> map, String username) {
if (StringUtils.isNotBlank(username)) {
logger.info("关闭websocket链接,关闭客户端username:" + username);
if (map.get(username) != null) {
map.remove(username);
}
}
} /**
* kafka发送消息监听事件,有消息分发
*
* @param message
* @author yxl
*/
public void kafkaReceiveMsg(String message) {
JSONObject jsonObject = JSONObject.parseObject(message); String receiver_id = jsonObject.getString("receiver_id"); //接受者ID if (drWebSocketSet.get(receiver_id) != null) {
drWebSocketSet.get(receiver_id).getBasicRemote.sendText(message); //进行消息发送
}
} /**
* kafka监听关闭websocket连接
*
* @param closeMessage
*/
public void kafkaCloseWebsocket(String closeMessage) {
JSONObject jsonObject = JSONObject.parseObject(closeMessage);
String userId = jsonObject.getString("userId");
drWebSocketSet.remove(userId);
} /**
* 发生错误时调用
*
* @param session
* @param error
*/
@OnError
public void onError(Session session, Throwable error) {
logger.info("webscoket发生错误!关闭websocket链接");
//onClose(session);
error.printStackTrace();
logger.info("webscoket发生错误!" + error.getMessage());
} }
websocket中不能直接注入相应的Bean实例,这个时候可以看我的另一篇博客https://www.cnblogs.com/Amaris-Lin/p/9038813.html
SpringBoot中使用消息中间件Kafka实现Websocket的集群的更多相关文章
- RabbitMQ和Kafka的高可用集群原理
前言 小伙伴们,通过前边文章的阅读,相信大家已经对RocketMQ的基本原理有了一个比较深入的了解,那么大家对当前比较常用的RabbitMQ和Kafka是不是也有兴趣了解一些呢,了解的多一些也不是坏事 ...
- 关于ASP.NET Core WebSocket实现集群的思考
前言 提到WebSocket相信大家都听说过,它的初衷是为了解决客户端浏览器与服务端进行双向通信,是在单个TCP连接上进行全双工通讯的协议.在没有WebSocket之前只能通过浏览器到服务端的请求应答 ...
- ELK+Kafka学习笔记之搭建ELK+Kafka日志收集系统集群
0x00 概述 关于如何搭建ELK部分,请参考这篇文章,https://www.cnblogs.com/JetpropelledSnake/p/9893566.html. 该篇用户为非root,使用用 ...
- Kafka设计解析(十七)Kafka 0.11客户端集群管理工具AdminClient
转载自 huxihx,原文链接 Kafka 0.11客户端集群管理工具AdminClient 很多用户都有直接使用程序API操作Kafka集群的需求.在0.11版本之前,kafka的服务器端代码(即添 ...
- 在Centos 7上安装配置 Apche Kafka 分布式消息系统集群
Apache Kafka是一种颇受欢迎的分布式消息代理系统,旨在有效地处理大量的实时数据.Kafka集群不仅具有高度可扩展性和容错性,而且与其他消息代理(如ActiveMQ和RabbitMQ)相比,还 ...
- CentOS7.4搭建kafka单结点和集群
操作系统选择 CentOS7.4x86-64(操作系统的x86_64是跟CPU有关的,最早AMD公司开发出了一款向下兼容x86CPU,向上又扩充了指令集,具有了64位CPU的特性,这款CPU后来改名为 ...
- Kafka的3节点集群详细启动步骤(Zookeeper是外装)
首先,声明,kafka集群是搭建在hadoop1.hadoop2和hadoop3机器上. kafka_2.10-0.8.1.1.tgz的1或3节点集群的下载.安装和配置(图文详细教程)绝对干货 如下分 ...
- Kafka入门初探+伪集群部署
Kafka是目前非常流行的消息队列中间件,常用于做普通的消息队列.网站的活性数据分析(PV.流量.点击量等).日志的搜集(对接大数据存储引擎做离线分析). 全部内容来自网络,可信度有待考证!如有问题, ...
- kafka环境搭建2-broker集群+zookeeper集群(转)
原文地址:http://www.jianshu.com/p/dc4770fc34b6 zookeeper集群搭建 kafka是通过zookeeper来管理集群.kafka软件包内虽然包括了一个简版的z ...
随机推荐
- selenium java-3 定位元素的八种方法
web driver提供了八种元素定位的方法: id name class name tag name link text partial link text xpath css selector 如 ...
- 正则捕获的细节及replace分析
1.var reg=/./与var reg=/\./的区别? 前者代表任意一个字符, 后者代表这个字符串中得有一个点 2.?的使用 如果单独的一个字符后面带? 代表1个或0个这个字符的出现: 列如: ...
- 利用python,简单的词语纠错
利用python,编写一个简单的词语纠正修改器. 原文:http://norvig.com/spell-correct.html #!/usr/bin/env python # coding=utf- ...
- BPM与ESB
BPM:业务流程管理 --监控处理流程的轨迹以及处理过程 开源:JBPM 场景: 1.单一系统的协同工作比如审批流程,请假流程 2.多个系统的集成,复用各个子系统,构建新的处理流程(流程的优化与流程 ...
- ETL编程模型(场景)
使用场景: ETL是一个处理过程. 多个数据源之间进行数据同步 1:n:一对多同步数据 n:1:多个数据源到一个目的段 m;n:多个数据源多个目的段 ========================= ...
- git本地项目上传远程
Git的安装就不说了. 原文:https://blog.csdn.net/zamamiro/article/details/70172900 github官网说明: …or create a new ...
- MyBatis 中#与$的区别
今天在工作中有个点击排序的功能调试了许久,终寻因,总结之. 需求是这样的,页面有个table,有一列的上下箭头可点击并排序.对于这种需求,我的mybatis.xml的sql配置写成了如下: < ...
- 使用 intellij idea 进行远程调试
转自:http://yiminghe.iteye.com/blog/1027707 以前都是很土得打 log ,发现一篇关于 java 调试器架构 ,以及 eclipse 上使用 的文章,在常用的 i ...
- Hive 简介
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行. 其优点是学习成本低,可以通过 ...
- 35. CentOS-6.3安装Mysql-5.5.29
安装方式分为rpm和源码编译安装两种,本文是采用mysql源码编译方式,编译器使用Cmake.软件需要mysql-5.5.29.tar.gz和cmake-2.8.10.2.tar.gz,请自行下载.下 ...