Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数
官网文档:《http://spark.apache.org/docs/latest/streaming-programming-guide.html#a-quick-example》
Spark Streaming提供的提供的理念是一个批次处理一定时间段内的数据,一批次处理接收到的这一批次的数据;而Structured Streaming提供的理念是使用DataFrame/DataSet方式接收流,这样的流是一个可以看做为一个无界的大表,可以持续输出统计结果,而统计结果也会跟随时间(流数据的流入)持续更新。
另外,Spark Streaming是core Spark API的一个扩展,使用时需要引入maven:
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-streaming_2.11</artifactId>
- <version>2.3.1</version>
- </dependency>
而Structured Streaming流处理是基于Spark SQL引擎,使用时要引入maven:
- <dependency>
- <groupId>org.apache.spark</groupId>
- <artifactId>spark-sql_2.11</artifactId>
- <version>2.3.1</version>
- </dependency>
Spark Streaming官网的例子reduceByKeyAndWindow
简单的介绍了spark streaming接收socket流的数据,并把接收到的数据进行windows窗口函数对数据进行批量处理。
- import java.util.Arrays;
- import org.apache.spark.SparkConf;
- import org.apache.spark.api.java.JavaSparkContext;
- import org.apache.spark.streaming.Durations;
- import org.apache.spark.streaming.api.java.JavaDStream;
- import org.apache.spark.streaming.api.java.JavaPairDStream;
- import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
- import org.apache.spark.streaming.api.java.JavaStreamingContext;
- import scala.Tuple2;
- public class HelloWord {
- public static void main(String[] args) throws InterruptedException {
- // Create a local StreamingContext with two working thread and batch interval of 1 second
- SparkConf conf = new SparkConf().setMaster("local[*]").setAppName("NetworkWordCount");
- JavaSparkContext jsc=new JavaSparkContext(conf);
- jsc.setLogLevel("WARN");
- JavaStreamingContext jssc = new JavaStreamingContext(jsc, Durations.seconds(1));
- // Create a DStream that will connect to hostname:port, like localhost:9999
- JavaReceiverInputDStream<String> lines = jssc.socketTextStream("xx.xx.xx.xx", 19999);
- // Split each line into words
- JavaDStream<String> words = lines.flatMap(x -> Arrays.asList(x.split(" ")).iterator());
- // Count each word in each batch
- JavaPairDStream<String, Integer> pairs = words.mapToPair(s -> new Tuple2<>(s, 1));
- // Reduce last 60 seconds of data, every 30 seconds
- JavaPairDStream<String, Integer> windowedWordCounts = pairs.reduceByKeyAndWindow((i1, i2) -> i1 + i2,
- Durations.seconds(60),
- Durations.seconds(30));
- // Print the first ten elements of each RDD generated in this DStream to the console
- windowedWordCounts.print();
- jssc.start(); // Start the computation
- jssc.awaitTermination(); // Wait for the computation to terminate
- }
- }
输入数据:

窗口中数据随着时间的变化:
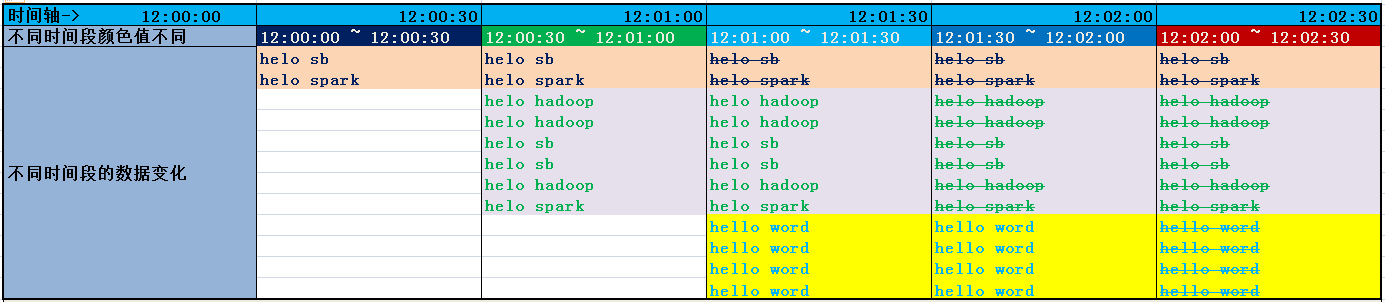
实际工作中上边的代码统计出的结果:

Window操作解读:
- // Reduce last 60 seconds of data, every 30 seconds
- JavaPairDStream<String, Integer> windowedWordCounts = pairs.reduceByKeyAndWindow((i1, i2) -> i1 + i2,
- Durations.seconds(60),
- Durations.seconds(30));
上边代码的意义就是:按照key对value进行求count,数据处理范围是60s内的数据,每隔30s统计一次。
Spark Streaming提供了窗口计算,它允许你对滑动窗口上的数据使用变换(transformations)。下图说明了滑动窗口:
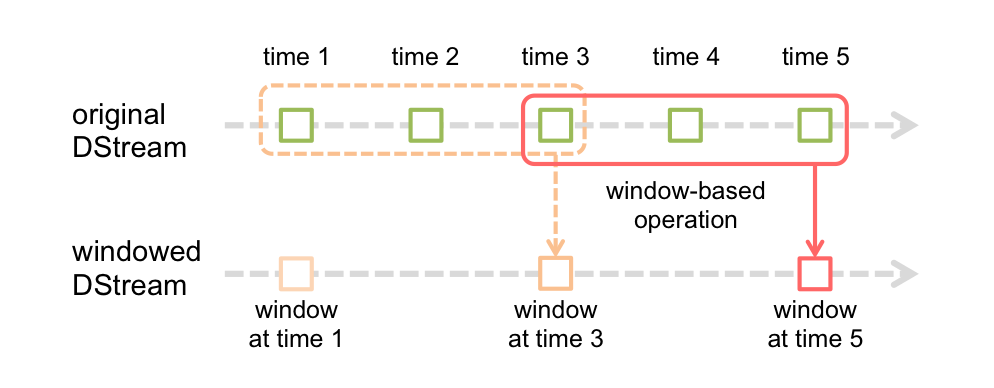
上图介绍了,两个信息:
1)original DStream:Spark Streaming是把一段时间接收到的流作为一个批数据“也就是图中上边绿色框框示意内容”;
2)windowed DStream:窗口每次滑动就是把“滑动长度(时间)”内的数据(一批)合并到一起进行一次运算,另外"'滑动长度(时间)'内的数据"受两个因素影响:“窗口时长”、“水印时长”(Structured Streaming编程中拥有的)。
上边的例子及图可以充分解释为什么每次窗口触发时参与计算的数据受“窗口时长”的影响。“窗口时长”实际上就是定义每次窗口事件触发时,参与计算的数据长度(范围)。
记录:
这篇文章写的不错,而且例子也不错:https://blog.csdn.net/l_15156024189/article/details/81612860
Kafka:ZK+Kafka+Spark Streaming集群环境搭建(二十二)Spark Streaming接收流数据及使用窗口函数的更多相关文章
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十二)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网。
Centos7出现异常:Failed to start LSB: Bring up/down networking. 按照<Kafka:ZK+Kafka+Spark Streaming集群环境搭 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十)安装hadoop2.9.0搭建HA
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十六)Structured Streaming中ForeachSink的用法
Structured Streaming默认支持的sink类型有File sink,Foreach sink,Console sink,Memory sink. ForeachWriter实现: 以写 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十九)ES6.2.2 安装Ik中文分词器
注: elasticsearch 版本6.2.2 1)集群模式,则每个节点都需要安装ik分词,安装插件完毕后需要重启服务,创建mapping前如果有机器未安装分词,则可能该索引可能为RED,需要删除后 ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十五)Spark编写UDF、UDAF、Agg函数
Spark Sql提供了丰富的内置函数让开发者来使用,但实际开发业务场景可能很复杂,内置函数不能够满足业务需求,因此spark sql提供了可扩展的内置函数. UDF:是普通函数,输入一个或多个参数, ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十四)定义一个avro schema使用comsumer发送avro字符流,producer接受avro字符流并解析
参考<在Kafka中使用Avro编码消息:Consumer篇>.<在Kafka中使用Avro编码消息:Producter篇> 在了解如何avro发送到kafka,再从kafka ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十八)ES6.2.2 增删改查基本操作
#文档元数据 一个文档不仅仅包含它的数据 ,也包含 元数据 —— 有关 文档的信息. 三个必须的元数据元素如下:## _index 文档在哪存放 ## _type 文档表示的对象类别 ## ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(十三)kafka+spark streaming打包好的程序提交时提示虚拟内存不足(Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical memory used; 2.2 GB of 2.1 G)
异常问题:Container is running beyond virtual memory limits. Current usage: 119.5 MB of 1 GB physical mem ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(九)安装kafka_2.11-1.1.0
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
- Kafka:ZK+Kafka+Spark Streaming集群环境搭建(八)安装zookeeper-3.4.12
如何搭建配置centos虚拟机请参考<Kafka:ZK+Kafka+Spark Streaming集群环境搭建(一)VMW安装四台CentOS,并实现本机与它们能交互,虚拟机内部实现可以上网.& ...
随机推荐
- ELASTIC制图等高级使用
基于上一个安装部署的文档后(ELASTIC 5.2部署并收集nginx日志) http://www.cnblogs.com/kerwinC/p/6387073.html 本次带来一些使用的分享. ki ...
- FreeCommander 学习手册
概述 转载请注明出处:http://www.cnblogs.com/skywang12345/p/3470728.html FreeCommander(下文简称FC),是Windows下面比较强大的文 ...
- C# TextWriter类
来自:https://www.yiibai.com/csharp/c-sharp-textwriter.html C# TextWriter类是一个抽象类.它用于将文本或连续的字符串写入文件.它在Sy ...
- ibatis.net:第八天,QueryForDictionary
xml <statement id="FindOrdersByCustomer" parameterClass="string" resultClass= ...
- 利用WebSocket传输数组或者Blob的方案
最近在利用Html5的WebSocket进行即时通讯,一点小心得,大家一起讨论吧 首先把WebSocket的协议网址和WebSocket API网址给大家: 协议:http://tools.ietf. ...
- 关于 java,nio,bufferedreader,bytebuffer
有没有一种方法来读取的ByteBuffer有一个BufferedReader,而无需将其转换为String优先?我想读通过一个相当大的 ByteBuffer作为文本行和我想避免它写入磁盘性能方面的原因 ...
- spring boot 之@JsonView 简单介绍
@JsonView是jackson json中的一个注解,spring webmvc也支持这个注解. 这个注解的作用就是控制输入输出后的json. 假设我们有一个用户类,其中包含用户名和密码,一般情况 ...
- versionCode溢出的问题
android应用的版本主要由versionCode和versionName来决定,android系统是根据versionCode来验证新的apk是否能安装.如果已安装高版本的应用,就无法使用覆盖安装 ...
- ImageView和onTouchListener实现,点击查看图片细节
这是来自疯狂android讲义上的例子,其实没啥意思.就是用监听器获取到手指的坐标,然后根据这个坐标开始绘制一个图片.(这里的绘制方式有些问题,所以凑合看看吧.) 首先,还是布局文件(两个ImageV ...
- 全文居中及DIV居中
第一种方案(全文档): body { text-align: center; } body div { margin: 0 auto; } 第二种方案(某DIV): .testing- ...