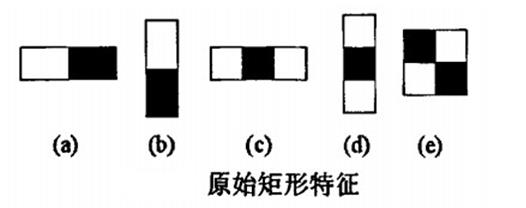
Viola-Jones人脸检測
OpenCV中有一个基于树的技术:Haar分类器,它建立了boost筛选式级联。
它能够识别出人脸和其它刚性物体。
对于检測“基本刚性”的物体(脸,汽车,自行车,人体等)这类识别任务,Haar分类器是一个实用的工具。
在2001年,Viola和Jones发表了经典的《Rapid Object Detection using a Boosted Cascade of Simple Features》[3]和《Robust Real-Time Face Detection》,在AdaBoost算法的基础上,使用Haar-like小波特征(简称类haar特征)和积分图方法进行人脸检測,他俩不是最早使用提出小波特征的,可是他们设计了针对人脸检測更有效的特征。并对AdaBoost训练出的强分类器进行级联。
这能够说是人脸检測史上里程碑式的一笔了。也因此当时提出的这个算法被称为Viola-Jones检測器。
之后。Rainer Lienhart和Jochen Maydt将这个检測器用对角特征进行了扩展《An Extended Set of Haar-like Features for Rapid Object Detection》。终于形成了OpenCV如今的Haar分类器[1][2]。
AdaBoost是Freund和Schapire在1995年提出的算法[4],是对传统Boosting算法的一大提升。Adaboost是一种迭代算法。其核心思想是针对同一个训练集训练不同的分类器(弱分类器)。然后把这些弱分类器集合起来,构成一个更强的终于分类器(强分类器)。
以下介绍Viola-Jones分类算法:
OpenCV中的Haar分类器 = 类Haar特征 + 积分图方法 + AdaBoost + 级联;
Viola-Jones分类器算法要点:
1. 使用类Haar输入特征:对矩形图像区域的和或差进行阈值化。
2. 积分图像技术加速了矩形图像区域的45度旋转的值的计算,这个图像结构被用来加速类Haar输入特征的计算。
3. 使用Adaboost来创建二分类问题(人脸与非人脸)的分类器节点(高通过率,低拒绝率)。
4. 把分类器节点组成筛选式级联(在筛选式级联里,一个节点是Adaboost类型的一组分类器)。换句话说:第一组分类器是最优,能通过包括物体的图像区域。同一时候同意一些不包括物体的图像通过;第二组分类器次优分类器。也有较低的拒绝率。以此类推。
仅仅要图像通过了整个级联,则觉得里面有物体。
这保证了级联的执行速度能够非常快,由于它一般能够在前几步就能够拒绝不包括物体的图像区域,而不必走完整个级联[6]。
1 Features类Haar特征
Viola提出的类Haar特征:
由后继者提出的扩展类Haar特征:
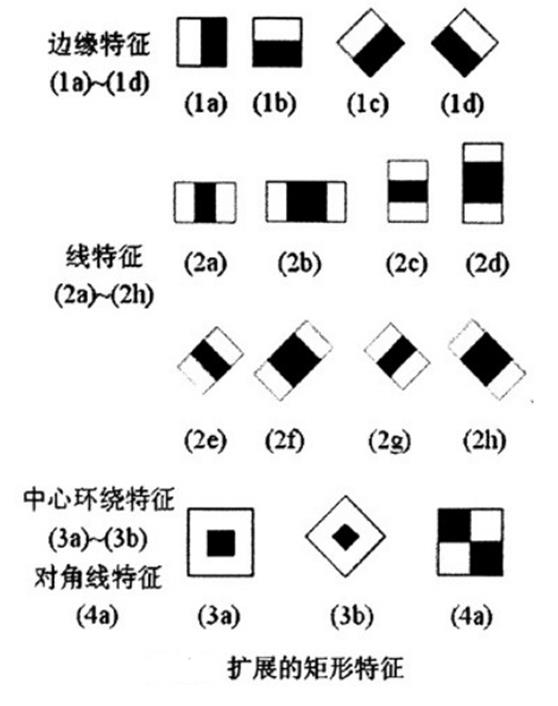
把矩形框(能够理解为特征模板)放到人脸图像区域上,将矩形框内的白色区域像素之和减去黑色区域的像素之和,得到的就是所谓的人脸特征值。类haar特征反映了图像的灰度变化,将人脸特征量化,以区分人脸和非人脸。
这些类Haar特征对于“块特征”(眼睛,嘴,发际线)具有比較好的效果,但对树枝或主要靠外形(如咖啡杯)的物体不适用。
2 Integral Image积分图
Viola-Jones採用积分图的方法来实现类Haar特征的高速计算。
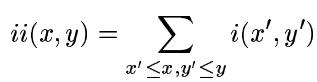
ii表示积分图。i是原图。ii(x,y)就表示i(1,1)和i(x,y)两个对角点所围城的矩形面积的大小。所谓的积分也就是个求和过程。
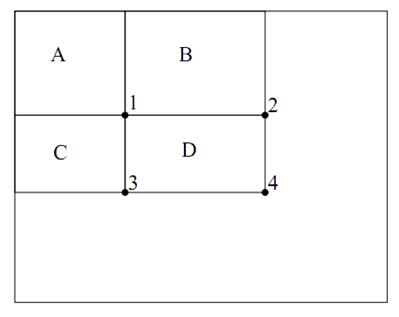
如上图所看到的,在积分图中位置1的值表示原图A区域的像素和。2表示A+B的像素和,3表示A+C的像素和,4表示A+B+C+D的像素和。所以D的面积为4+1-(2+3)。
(A+B+C+D+A-(A+B+A+C)= D)
3 Adaboost
Viola-Jones分类器是一个有监督分类器。其学习算法是Adaboost(Ada:Adaptive自适应,Boost:Boosting),其算法流程例如以下,相关证明能够參考[5][7]

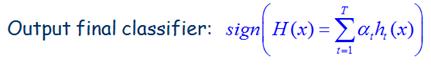
先说明下学习分类函数:
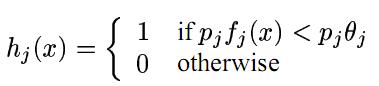
x是24*24大小的窗体,hj(x) 是一个弱分类器,fj(x)是矩形框的特征值。theta是阈值。pj是parity(用来指示不等号方向。校验?)。
Viola-Jones在论文里的Adaboost算法例如以下图:

一開始初始化权重,正样本的权重为1/l(l为正样本数)。负样本为1/m(m为负样本数),之后,在每一次迭代过程中,对每个特征都训练一个分类器hj(j=1,2,…,K),选取误分类率最低的一个特征的分类器ht作为第t次迭代的分类器(如上图图示所述。每次迭代是从180000中选出一个)。然后更新样本的权重。
最后得到的h(x)是一个由M个ht组成的强分类器。
学习的计算复杂度:O(MNK)
M次迭代,N个样本(N=m+l)。K个特征
分类器的训练过程大致如上面所述。
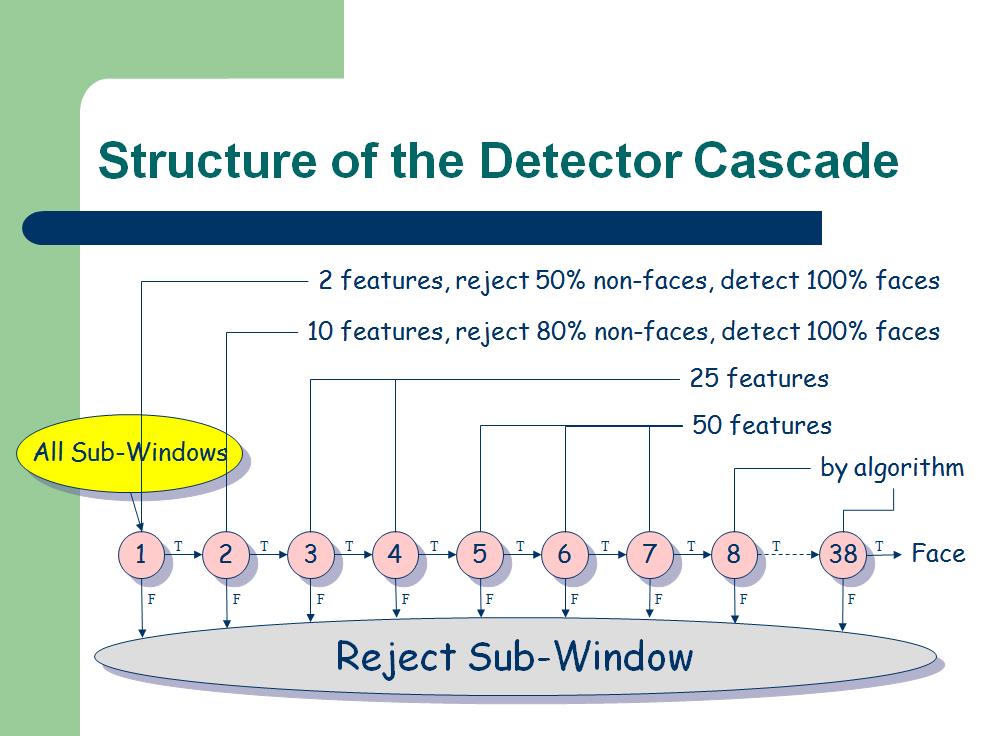
4 Attentional Cascade
接下来要介绍下筛选式级联分类器。
人脸检測中,仅仅靠一个强分类器还不足以保证检測的正确率。须要一连串的强分类器联合在一起来提高检測正确率。
这个过程相似于一个决策树。例如以下图。第一个分类器输出True结果就会触发相同具有较高检測率的第二个分类器对窗体图像做出评价,第二个分类输出True结果将触发第三个分类器对窗体图像做出评价。仅仅要有一个分类器节点输出False结果,直接觉得该窗体图像不包括目标物。
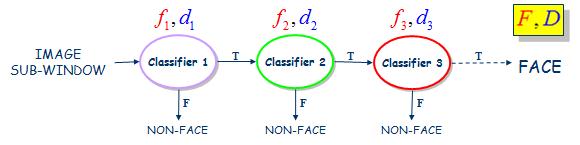
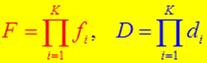
F表示假阳性率,D表示检測率(召回率)。
如果每个Stage(即一个分类器)的检測率f=0.99。假阳性率d=0.3。10个级联起来的话,F=0.9910≈0.9,D=0.310≈6∗10−6。整个筛选式级联分类器就具备了高检測率,低假阳性率。
接下来说明下级联分类器的训练过程。这个过程要考虑以下两种平衡:一是弱分类器的个数和计算时间的平衡(添加特征个数能提高检測率和减少误识率。但会添加计算时间),二是强分类器检測率和误识率之间的平衡。
训练过程将选择每个stage可接受的最大假阳性率f。每个stage可接受的最小检測率d及得到终于级联分类器的假阳性率为Ftarget,正样本集P。负样本集N。
初始化F0=1.0,D0=1.0。i表示stage的个数。当级联分类器的假阳性率不够低时(即Fi>Ftarget),要添加stage个数(即i=i+1),ni表示强分类器具有ni个弱分类器。初始赋值0;然后,在Fi>f∗Fi−1情况下(假阳性率过高,须要通过添加特征数来减少),添加强分类器中的弱分类器个数ni=ni+1,用P和N运用Adaboost训练一个有ni个特征的强分类器。用交叉验证集来评估当前级联分类器的Fi和Di。减少第i层的分类器阈值直到当前级联分类器的检測率Di>d∗Di−1;利用当前的级联分类器检測非人脸图像,将误识的图像Φ放入N。算法流程可见下图:

终于的级联分类器结构例如以下图所看到的:
最后说明一点,在检測时,是对检測器进行比例缩放,而不是对图像进行缩放,例如以下图。

原文链接:http://blog.csdn.net/u011285477/article/details/49659567
【參考资料】
[1]http://blog.csdn.net/zouxy09/article/details/7929570
[2]http://blog.csdn.net/zouxy09/article/details/7922923
[3]http://www.csd.uwo.ca/Courses/CS9840a/Papers/violaJones_CVPR2001.pdf
[4]http://www.yorku.ca/gisweb/eats4400/boost.pdf
[5]http://wenku.baidu.com/link?url=eqhmYYuX_3-itbdZZZ5vrBacczhpZhlUwejd0iB8JloOUxVdrqaRXiYIpjO7qVuKUzBEZkH6icyS1QKs_V_YXkQZ3pcLQN4zlCWO8Uhn9Q3
[6]《学习OpenCV》(中文版) 清华大学出版社
[7]《统计学习方法》李航 著 清华大学出版社
[第一次写博客,不足的地方望看官指正]
Viola-Jones人脸检測的更多相关文章
- 【从零学习openCV】IOS7下的人脸检測
前言: 人脸检測与识别一直是计算机视觉领域一大热门研究方向,并且也从安全监控等工业级的应用扩展到了手机移动端的app,总之随着人脸识别技术获得突破,其应用前景和市场价值都是不可估量的,眼下在学习ope ...
- 利用opencv中的级联分类器进行人脸检測-opencv学习(1)
OpenCV支持的目标检測的方法是利用样本的Haar特征进行的分类器训练,得到的级联boosted分类器(Cascade Classification).注意,新版本号的C++接口除了Haar特征以外 ...
- Matlab人脸检測方法(Face Parts Detection)具体解释
今天同学让我帮忙制作一个人脸表情识别的样本库,当中主要是对人脸进行裁剪,这里用到了一个相对较新的Matlab人脸检測方法Face Parts Detection.网上百度了一下发现关于Matlab人脸 ...
- 基于QT和OpenCV的人脸检測识别系统(1)
人脸识别分为两大步骤 1.人脸检測 这个是首要实现的.你得实现人脸显示的时候把人脸框出来,当然算法非常多,另一些人眼检測鼻子检測什么的 主要用的是这个 const char *faceCascadeF ...
- OpenFace库(Tadas Baltrusaitis)中基于Haar Cascade Classifiers进行人脸检測的測试代码
Tadas Baltrusaitis的OpenFace是一个开源的面部行为分析工具.它的源代码能够从 https://github.com/TadasBaltrusaitis/OpenFace 下载. ...
- OpenCv 人脸检測的学习
近期公司要组织开发分享,可是自己还是新手真的不知道分享啥了,然后看了看前段时间研究过OpenCv,那么就分享他把. openCv就不介绍了,说下人脸检測.事实上是通过openCv里边已经训练好的xml ...
- OpenCV人脸检測(完整源代码+思路)
本博文IDE为vs2013 OpenCV2.49 话不多说,先看视频演示(20S演示): 例如以下: https://v.youku.com/v_show/id_XMjYzMzkxMTYyMA==.h ...
- C++开发人脸性别识别教程(10)——加入图片的人脸检測程序
现在我们的MFC框架已经初具规模,能够读取并显示目录下的图片.在这篇博文中我们将向当中加入人脸检測的程序. 一.人脸检測算法 这里我们使用OpenCv封装的Adaboost方法来进行人脸检測,參见:C ...
- 基于QT和OpenCV的人脸检測识别系统(2)
紧接着上一篇博客的讲 第二步是识别部分 人脸识别 把上一阶段检測处理得到的人脸图像与数据库中的已知 人脸进行比对,判定人脸相应的人是谁(此处以白色文本显示). 人脸预处理 如今你已经得到一张人脸,你能 ...
随机推荐
- Echarts柱状图的点击事件
最近在做一些图表统计的功能,用到了百度的开源图表软件Echatrs,不得不提的是:不但上手简单而且扩展功能也是十分强大.在使用的过程中也遇到了不少问题,可能由于有关Echatrs的资料并不是很齐全,所 ...
- 利用JQuery 来操作 ListBox和ListBox内移动
[导读]利用jquery 来操作 listbox和listbox内移动function listbox_move(listfrom,listto) { var size = $(" &quo ...
- 最大整数(Noip1998连接多位数)
最大整数(Noip1998连接多位数)[问题描述] 设有n个正整数(n≤20),将它们联接成一排,组成一个最大的多位整数. 例如:n=3时,3个整数13,312,343联接成的最大整数为:343312 ...
- Mac OS X上安装配置apache服务器
说明:Mac在安装完成Mac系统的时候它已经自带了apache服务器,接下来就是配置和将它启动运行了.那么接下来要做的事情就是: 1.配置apache的配置文件 2.设置虚拟主机 启动并查看apach ...
- ContentResolver.query()—>buildQueryString()
Cursor cursor = context.getContentResolver().query(Sms.CONTENT_URI, new String[]{"threa ...
- 严重: The web application [] registered the JDBC driver [com.microsoft.sqlserver.jdbc.SQLServerDriver] but failed to unregister it when the web application was stopped. To prevent a memory leak, the JDB
idea项目启动报如下错误, 网上的方法都试了都没用, 一直没解决, 干掉项目, 重新从svn检出就好了...坑 啊 Root WebApplicationContext: initializatio ...
- linux shell 脚本攻略学习3
1.Bash中的READ命令 #读取n个字符存入变量 read -n number_of_chars variable_name 示例: amosli@amosli-pc:~$ read -n var ...
- 线程同步之mutex和Semaphore
表示之前对semaphore信号量木有神码概念. 比较纳闷这玩意要干嘛,好吧继续stackflow: Mutex can be released only by thread that had acq ...
- 【C++】atoi与stoi
stoi函数默认要求输入的参数字符串是符合int范围的[-2147483648, 2147483647],否则会runtime error.atoi函数则不做范围检查,若超过int范围,则显示-214 ...
- Spring 3.0 AOP 之 AOP 术语 (一)
关于AOP.之前我已写过一个系列的随笔: <自己实现简单的AOP>,它的关注点在于实现.实现语言是C#,实现方式为 自定义实现 RealProxy 抽象类.重写Invoke方法,以便进行方 ...