Android实现中文汉字笔划(笔画)、中文拼音排序、英文排序
概述
详细
一、需求描述
最近要做一个类似微信的,在登录界面选择国家地区的功能,微信有中文汉字笔画排序以及中文拼音排序等几种方式,如下所示:
微信:简体中文、拼音排序
微信:繁体中文、笔画排序
微信 英文 字母排序
二、实现效果
下面看看我的Demo实现的效果
简体中文、拼音排序
繁体中文、笔画排序
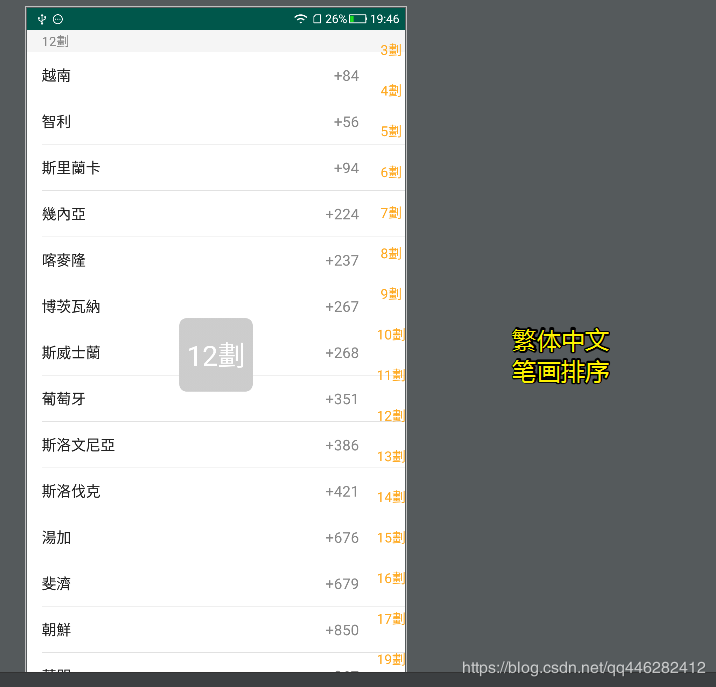
英文 字母排序
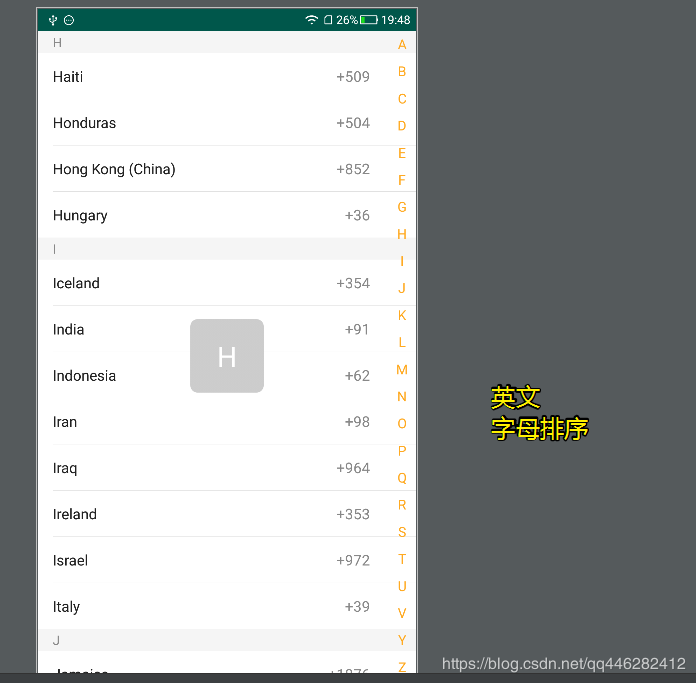
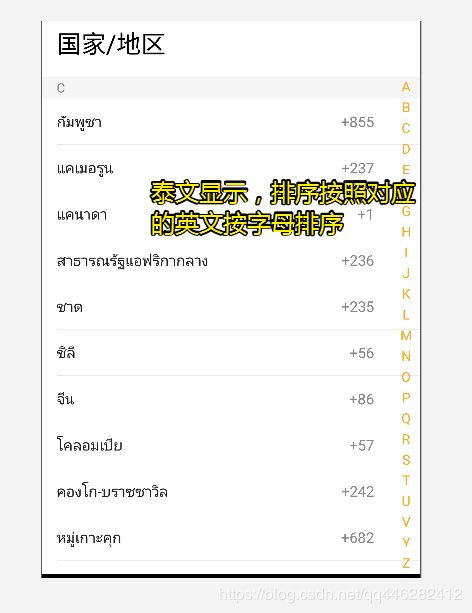
其他语言,显示其他语言,排序按照对应的英文名来排序
三、实现过程
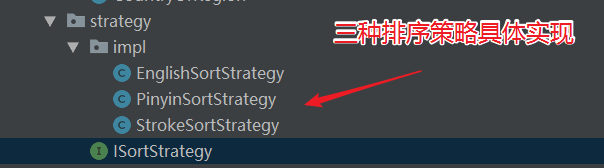
在将这部分代码抽取出来,做了一个demo。项目结构如下所示:采用策略模式,分别有EnglishSortStrategy、PinyinSortStrategy、StrokeSortStrategy三种策略,分别表示英文排序策略、拼音排序策略、汉字笔画排序策略。
+ 拼音排序
通过pin4j工具类将汉字转换为拼音,然后按照拼音的字母进行排序。
+ 笔画排序
通过查找汉字笔画数据库,将每个汉字对应的笔画数、汉字、汉字对应的编码映射到map中,然后通过查询map找到每个汉字的笔画,最终按照笔画数目进行排序。
+ 英文排序
直接通过英文的字母顺序进行排序即可。
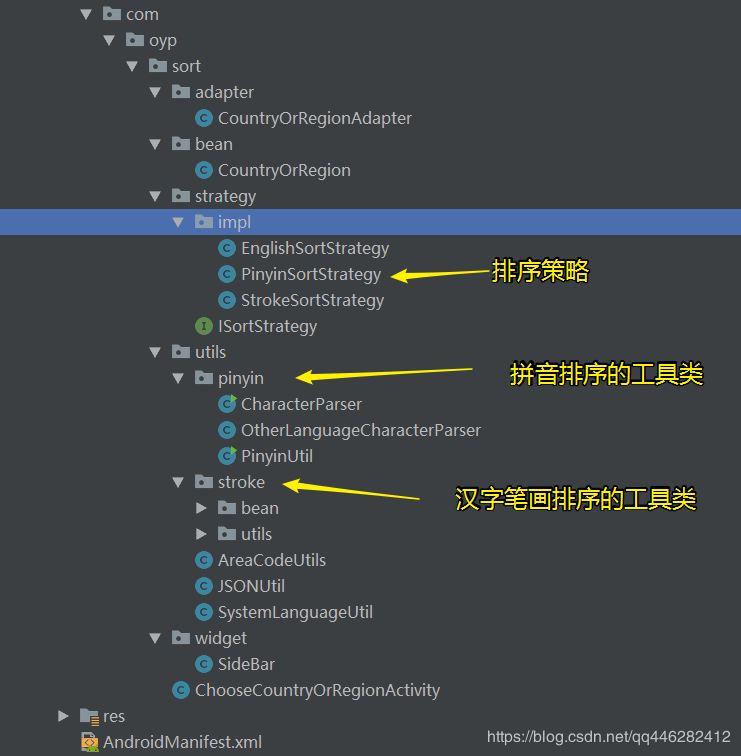

三种排序策略具体实现:
ISortStrategy.java 排序策略接口
package com.oyp.sort.strategy;
import android.content.Context;
import com.oyp.sort.adapter.CountryOrRegionAdapter;
import com.oyp.sort.bean.CountryOrRegion;
import java.util.List;
/**
* 排序的策略
*/
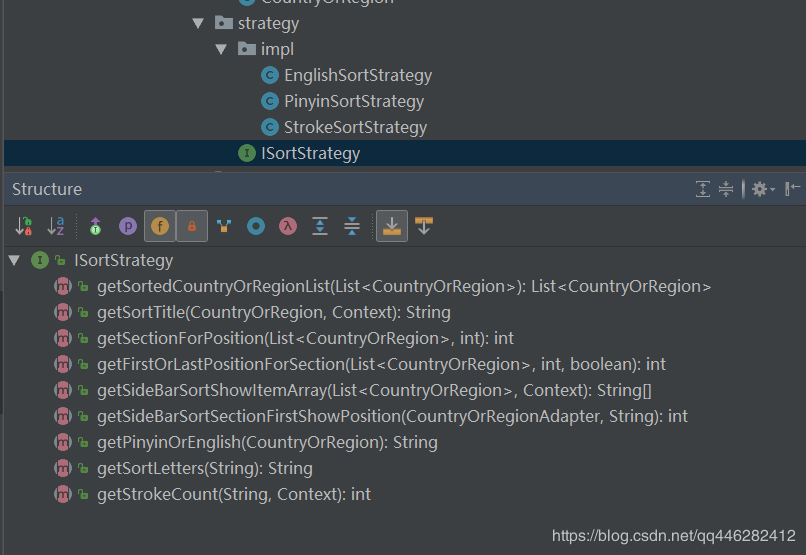
public interface ISortStrategy {
/**
* 获取排序过后的国家区域列表
*
* @param countryOrRegionList 待排序的国家区域列表
* @return 排序过后的国家区域列表
*/
List<CountryOrRegion> getSortedCountryOrRegionList(List<CountryOrRegion> countryOrRegionList);
/**
* 获取要展示的排序的title 拼音排序显示 首字母,笔画排序显示 几划
*
* @param countryOrRegion 封装的CountryOrRegion
* @return 要展示的排序的title
*/
String getSortTitle(CountryOrRegion countryOrRegion,Context context);
/**
* 根据ListView的当前位置获取排序标题 是否需要显示的对比值:
* - 拼音排序返回首字母的Char ascii值
* - 笔画排序返回首字母的汉字笔画数量
*
* @param list 数据List集合
* @param position 位置
* @return 是否需要显示的对比值
* - 拼音排序返回首字母的Char ascii值
* - 笔画排序返回首字母的汉字笔画数量
*/
int getSectionForPosition(List<CountryOrRegion> list, int position);
/**
* 获取第一次或者是最后一次 出现该排序标题的位置
*
* @param list 排序列表
* @param section 排序标题的值:拼音排序首字母的Char ascii值,笔画排序出现的笔画数
* @param isFirst 是否是第一次
* @return 第一次或者是最后一次 出现该排序标题的位置
*/
int getFirstOrLastPositionForSection(List<CountryOrRegion> list, int section, boolean isFirst);
/**
* 生成不同排序规则,侧边栏需要展示的列表
*
* @param mSourceDateList 数据源
* @return SideBar需要展示的列表
*/
String[] getSideBarSortShowItemArray(List<CountryOrRegion> mSourceDateList, Context context);
/**
* 返回 滑动到侧边栏的某一项时候,需要去拿这一项首次出现在listView中的位置
*
* @param adapter 适配器
* @param sideBarSortShowItem 滑动到侧边栏的某一项
* @return 这一项首次出现在listView中的位置
*/
int getSideBarSortSectionFirstShowPosition(CountryOrRegionAdapter adapter, String sideBarSortShowItem);
/**
* 获取拼音排序需要的拼音 或者 英文排序需要的英文,中文环境的返回拼音字母,其他环境的返回 国家码转换后的国家英文名
*
* @param countryOrRegion 国家地区封装类
* @return 拼音排序需要的拼音 或者 英文排序需要的英文
*/
String getPinyinOrEnglish(CountryOrRegion countryOrRegion);
/**
* 获取 拼音排序或者英文排序需要展示的 英文首字母
*
* @param pinyin 拼音排序需要的拼音 或者 英文排序需要的英文
* @return 需要展示的 英文首字母
*/
String getSortLetters(String pinyin);
/**
* 获取 笔画排序所需要的汉字笔画数量 中文环境的返回汉字笔画数量,其他环境的返回 -1
*
* @param name 国家名
* @param context 上下文
* @return 笔画排序所需要的汉字笔画数量
*/
int getStrokeCount(String name, Context context);
}
拼音排序策略 PinyinSortStrategy.java
package com.oyp.sort.strategy.impl;
import android.content.Context;
import com.oyp.sort.adapter.CountryOrRegionAdapter;
import com.oyp.sort.bean.CountryOrRegion;
import com.oyp.sort.strategy.ISortStrategy;
import com.oyp.sort.utils.pinyin.CharacterParser;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
/**
* 根据拼音来排序的策略
*/
public class PinyinSortStrategy implements ISortStrategy {
/**
* 获取排序过后的国家区域列表
*
* @param countryOrRegionList 待排序的国家区域列表
* @return 排序过后的国家区域列表
*/
@Override
public List<CountryOrRegion> getSortedCountryOrRegionList(List<CountryOrRegion> countryOrRegionList) {
// 根据a-z进行排序源数据
Collections.sort(countryOrRegionList, new Comparator<CountryOrRegion>() {
@Override
public int compare(CountryOrRegion o1, CountryOrRegion o2) {
if (o1.getSortLetters().equals("@")
|| o2.getSortLetters().equals("#")) {
return -1;
} else if (o1.getSortLetters().equals("#")
|| o2.getSortLetters().equals("@")) {
return 1;
} else {
// return o1.getSortLetters().compareTo(o2.getSortLetters());
return o1.getPinyinName().compareTo(o2.getPinyinName());
}
}
});
return countryOrRegionList;
}
@Override
public String getSortTitle(CountryOrRegion countryOrRegion,Context context) {
//拼音的 只需要展示 英文首字母即可
return countryOrRegion.getSortLetters();
}
@Override
public int getSectionForPosition(List<CountryOrRegion> list, int position) {
return list.get(position).getSortLetters().charAt(0);
}
/**
* 根据拼音排序标题的首字母的Char ascii值获取其 第一次或者是最后一次 出现该首字母的位置
*
* @param section 分类的首字母的Char ascii值
* @param isFirst 是否是第一次
* @return 出现该首字母的位置
*/
@Override
public int getFirstOrLastPositionForSection(List<CountryOrRegion> list, int section, boolean isFirst) {
int count = list.size();
//如果查找第一个位置,从0开始遍历
if (isFirst) {
for (int i = 0; i < count; i++) {
if (isSameASCII(list, section, i)) {
return i;
}
}
} else { //如果查找的是最后一个位置,从最后一个开始遍历
for (int i = count - 1; i > 0; i--) {
if (isSameASCII(list, section, i)) {
return i;
}
}
}
//如果没有找到 返回 -1
return -1;
}
/**
* 判断 分类的首字母的Char ascii值 是否和 列表中的位置的Char ascii值一样
*
* @param section 分类的首字母的Char ascii值
* @param position 列表中的位置
* @return 是否相同
*/
private boolean isSameASCII(List<CountryOrRegion> list, int section, int position) {
String sortStr = list.get(position).getSortLetters();
char firstChar = sortStr.toUpperCase().charAt(0);
return firstChar == section;
}
@Override
public String[] getSideBarSortShowItemArray(List<CountryOrRegion> mSourceDateList,Context context) {
List<String> list = new ArrayList<>();
int count = mSourceDateList.size();
for (int i = 0; i < count; i++) {
CountryOrRegion countryOrRegion = mSourceDateList.get(i);
String sortLetters = countryOrRegion.getSortLetters();
if (!list.contains(sortLetters)) {
list.add(sortLetters);
}
}
return list.toArray(new String[list.size()]);
}
/**
* 返回 滑动到侧边栏的某个字母,首次出现在listView中的位置
*
* @param adapter 适配器
* @param sideBarSortShowItem 滑动到侧边栏的某个字母
* @return 滑动到侧边栏的某个字母首次出现在listView中的位置
*/
@Override
public int getSideBarSortSectionFirstShowPosition(CountryOrRegionAdapter adapter, String sideBarSortShowItem) {
return adapter.getPositionForSection(sideBarSortShowItem.charAt(0));
}
/**
* 拼音排序的时候,获取汉字的拼音
*
* @param countryOrRegion 国家地区封装类
* @return 汉字的拼音
*/
@Override
public String getPinyinOrEnglish(CountryOrRegion countryOrRegion) {
return CharacterParser.getInstance().getSplitSelling(countryOrRegion.getName());
}
/**
* 获取 拼音排序需要展示的 英文首字母
*
* @param pinyin 拼音排序需要的拼音
* @return 需要展示的 英文首字母
*/
@Override
public String getSortLetters(String pinyin) {
String sortString = pinyin.substring(0, 1).toUpperCase();
// 正则表达式,判断首字母是否是英文字母
if (sortString.matches("[A-Z]")) {
return sortString.toUpperCase();
} else {
return "#";
}
}
/**
* 拼音排序不需要这个字段做比较,直接返回-1
*/
@Override
public int getStrokeCount(String name, Context context) {
return -1;
}
}
英文排序策略 EnglishSortStrategy.java 继承自拼音排序策略PinyinSortStrategy.java
package com.oyp.sort.strategy.impl;
import android.content.Context;
import android.util.Log;
import com.oyp.sort.bean.CountryOrRegion;
import com.oyp.sort.utils.pinyin.OtherLanguageCharacterParser;
/**
* 根据英文来排序的策略,实际上排序策略和拼音排序是一样的
*/
public class EnglishSortStrategy extends PinyinSortStrategy {
private static final String TAG = "EnglishSortStrategy";
/**
* 英文排序的时候,返回国家码转换后的国家英文名
*
* @param countryOrRegion 国家地区封装类
* @return 国家码转换后的国家英文名
*/
@Override
public String getPinyinOrEnglish(CountryOrRegion countryOrRegion) {
//获取其他国家的英文名: 国家码转换成国家英文名
String countryCode = countryOrRegion.getCountryCode();
String countryEnglishName = OtherLanguageCharacterParser.getInstance().getMapData(countryCode);
Log.d(TAG,"CountryOrRegion countryCode : " + countryCode + " ,countryEnglishName:" + countryEnglishName);
return countryEnglishName;
}
/**
* 获取 英文排序需要展示的 英文首字母 ,策略和拼音排序策略一样
*
* @param pinyin 英文排序需要的英文
* @return 需要展示的 英文首字母
*/
@Override
public String getSortLetters(String pinyin) {
return super.getSortLetters(pinyin);
}
/**
* 英文排序的 直接返回-1 ,策略和拼音排序策略一样
*/
@Override
public int getStrokeCount(String name, Context context) {
return super.getStrokeCount(name, context);
}
}
汉字笔画排序策略 StrokeSortStrategy.java
package com.oyp.sort.strategy.impl;
import android.content.Context;
import android.util.Log;
import com.oyp.sort.R;
import com.oyp.sort.adapter.CountryOrRegionAdapter;
import com.oyp.sort.bean.CountryOrRegion;
import com.oyp.sort.strategy.ISortStrategy;
import com.oyp.sort.utils.stroke.bean.Stroke;
import com.oyp.sort.utils.stroke.utils.StrokeUtils;
import java.util.ArrayList;
import java.util.Collections;
import java.util.Comparator;
import java.util.List;
import java.util.regex.Pattern;
/**
* 根据汉字的笔画来排序的策略
*/
public class StrokeSortStrategy implements ISortStrategy {
private static final String TAG = "StrokeSortStrategy";
/**
* 获取排序过后的国家区域列表
*
* @param countryOrRegionList 待排序的国家区域列表
* @return 排序过后的国家区域列表
*/
@Override
public List<CountryOrRegion> getSortedCountryOrRegionList(List<CountryOrRegion> countryOrRegionList) {
//根据比较国家或地区的名称的笔画数量来进行排序
Collections.sort(countryOrRegionList, new Comparator<CountryOrRegion>() {
@Override
public int compare(CountryOrRegion c1, CountryOrRegion c2) {
int sum1 = c1.getStrokeCount();
int sum2 = c2.getStrokeCount();
return sum1 - sum2;
}
});
return countryOrRegionList;
}
@Override
public String getSortTitle(CountryOrRegion countryOrRegion,Context context) {
//返回笔划排序的笔画数量
return countryOrRegion.getStrokeCount() + context.getResources().getString(R.string.stroke_title);
}
@Override
public int getSectionForPosition(List<CountryOrRegion> list, int position) {
return list.get(position).getStrokeCount();
}
/**
* 根据笔画排序笔画数目的值获取其第一次或者是最后一次出现的位置
*
* @param section 笔画排序笔画数目
* @param isFirst 是否是第一次
* @return 第一次或者是最后一次出现指定笔画数目的值的位置
*/
@Override
public int getFirstOrLastPositionForSection(List<CountryOrRegion> list, int section, boolean isFirst) {
int count = list.size();
//如果查找第一个位置,从0开始遍历
if (isFirst) {
for (int i = 0; i < count; i++) {
if (isSameStrokeSum(list, section, i)) {
return i;
}
}
} else { //如果查找的是最后一个位置,从最后一个开始遍历
for (int i = count - 1; i > 0; i--) {
if (isSameStrokeSum(list, section, i)) {
return i;
}
}
}
//如果没有找到 返回 -1
return -1;
}
/**
* 判断 第一次出现该 笔画数目的位置 是否 和指定的位置一样
*
* @param section 笔画数目
* @param position 列表中的位置
* @return 是否相同
*/
private boolean isSameStrokeSum(List<CountryOrRegion> list, int section, int position) {
//获取指定位置的笔画数
int strokeCount = list.get(position).getStrokeCount();
return strokeCount == section;
}
@Override
public String[] getSideBarSortShowItemArray(List<CountryOrRegion> mSourceDateList, Context context) {
List<String> list = new ArrayList<>();
int count = mSourceDateList.size();
for (int i = 0; i < count; i++) {
CountryOrRegion countryOrRegion = mSourceDateList.get(i);
String strokeCount = getSortTitle(countryOrRegion,context);
if (!list.contains(strokeCount)) {
list.add(strokeCount);
}
}
return list.toArray(new String[list.size()]);
}
private static Pattern NUMBER_PATTERN = Pattern.compile("[^0-9]");
/**
* 返回 滑动到侧边栏的某个笔画描述,首次出现在listView中的位置
* 因为侧边栏显示的 类似于 "3划",因此需要将"划"字取出来,然后对比 "3" 第一次出现的postion
*
* @param adapter 适配器
* @param sideBarSortShowItem 滑动到侧边栏的某个笔画描述
* @return 滑动到侧边栏的某个笔画描述首次出现在listView中的位置
*/
@Override
public int getSideBarSortSectionFirstShowPosition(CountryOrRegionAdapter adapter, String sideBarSortShowItem) {
try {
//提取字符串中的数字
int strokeCount = Integer.parseInt(numberIntercept(sideBarSortShowItem));
//然后查询出 这个数字首次出现的时候
return adapter.getPositionForSection(strokeCount);
} catch (Exception e) {
Log.e(TAG,Log.getStackTraceString(e));
}
return 0;
}
/**
* 提取字符串中的数字
*
* @param numberString 包含数字的字符串
* @return 字符串中的数字
*/
public String numberIntercept(String numberString) {
return NUMBER_PATTERN.matcher(numberString).replaceAll("");
}
/**
* 笔画排序的时候,不需要拼音
*
* @param countryOrRegion 国家地区封装类
* @return 空字符串
*/
@Override
public String getPinyinOrEnglish(CountryOrRegion countryOrRegion) {
return "";
}
@Override
public String getSortLetters(String pinyin) {
return "#";
}
/**
* 获取 笔画排序所需要的汉字笔画数量 中文环境的返回汉字笔画数量,其他环境的返回 -1
*
* @param name 国家名
* @param context 上下文
* @return 笔画排序所需要的汉字笔画数量
*/
@Override
public int getStrokeCount(String name, Context context) {
//取出首字母上的字符code //返回指定索引处的字符(Unicode 代码点)。索引引用 char 值(Unicode 代码单元),其范围从 0到 length() - 1。
int codePoint = name.codePointAt(0);
//得到笔画的相关信息
StrokeUtils strokeUtils = StrokeUtils.newInstance(context);
//获取首个汉字
Stroke stroke = strokeUtils.getStroke(codePoint + "");
if (stroke != null) {
return Integer.parseInt(stroke.getStrokeSum());
}
return -1;
}
}
四、使用策略
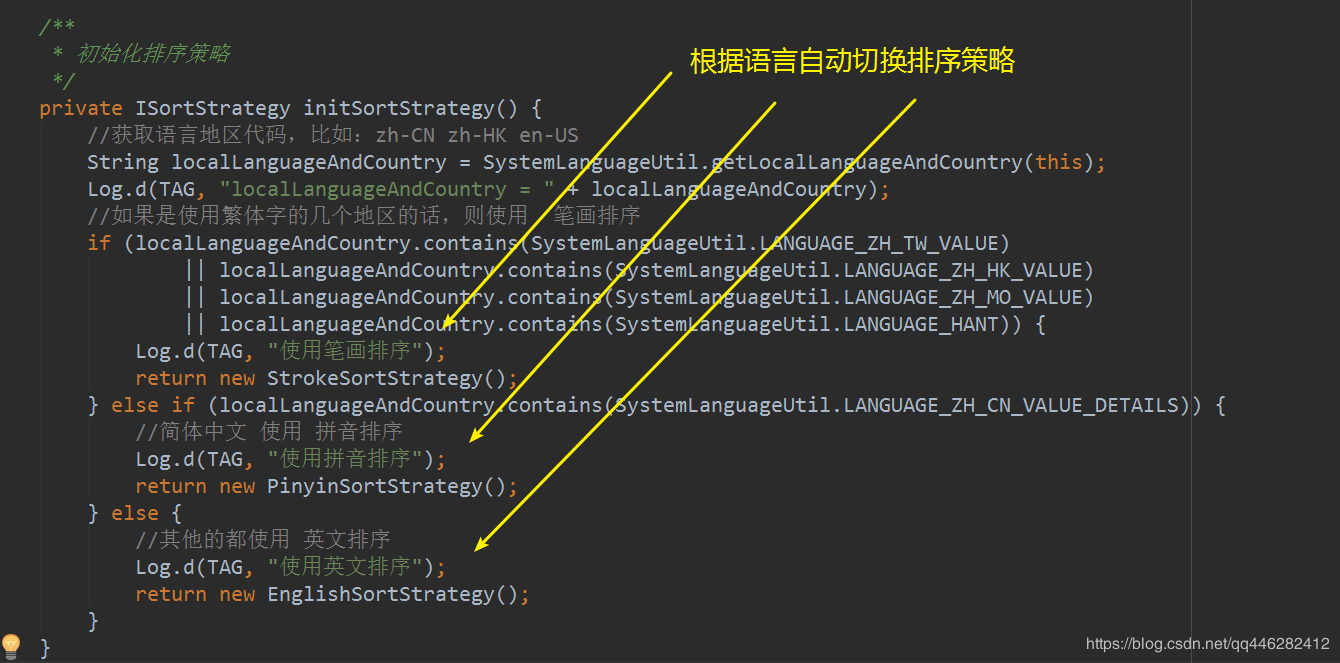
初始化排序策略,根据语言自动切换不同的排序策略
使用排序策略
使用策略主要是在两个地方,初始化数据的时候,使用不同排序策略,生成不同的数据
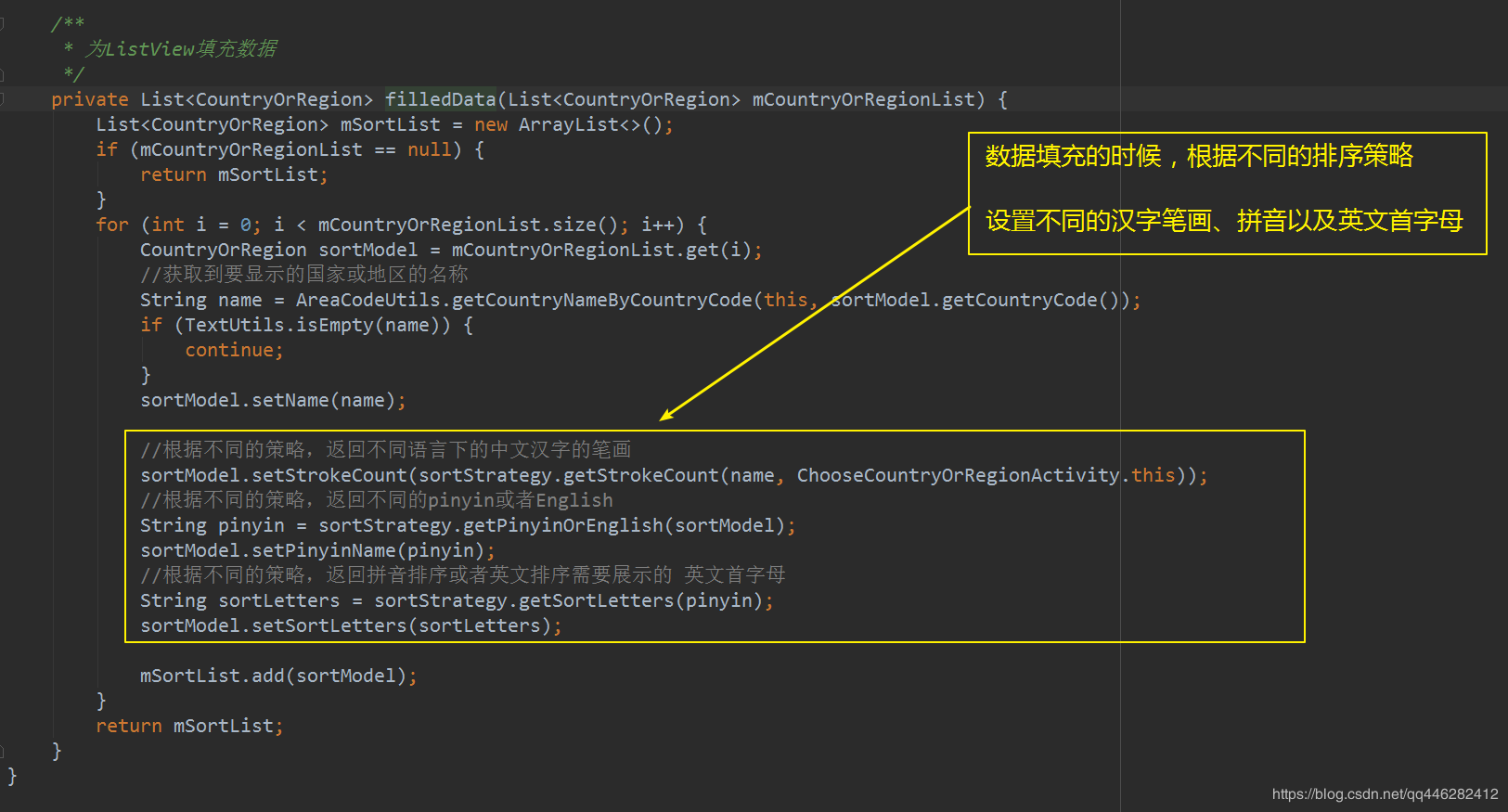
数据排序的时候,使用不同策略对数据源进行排序
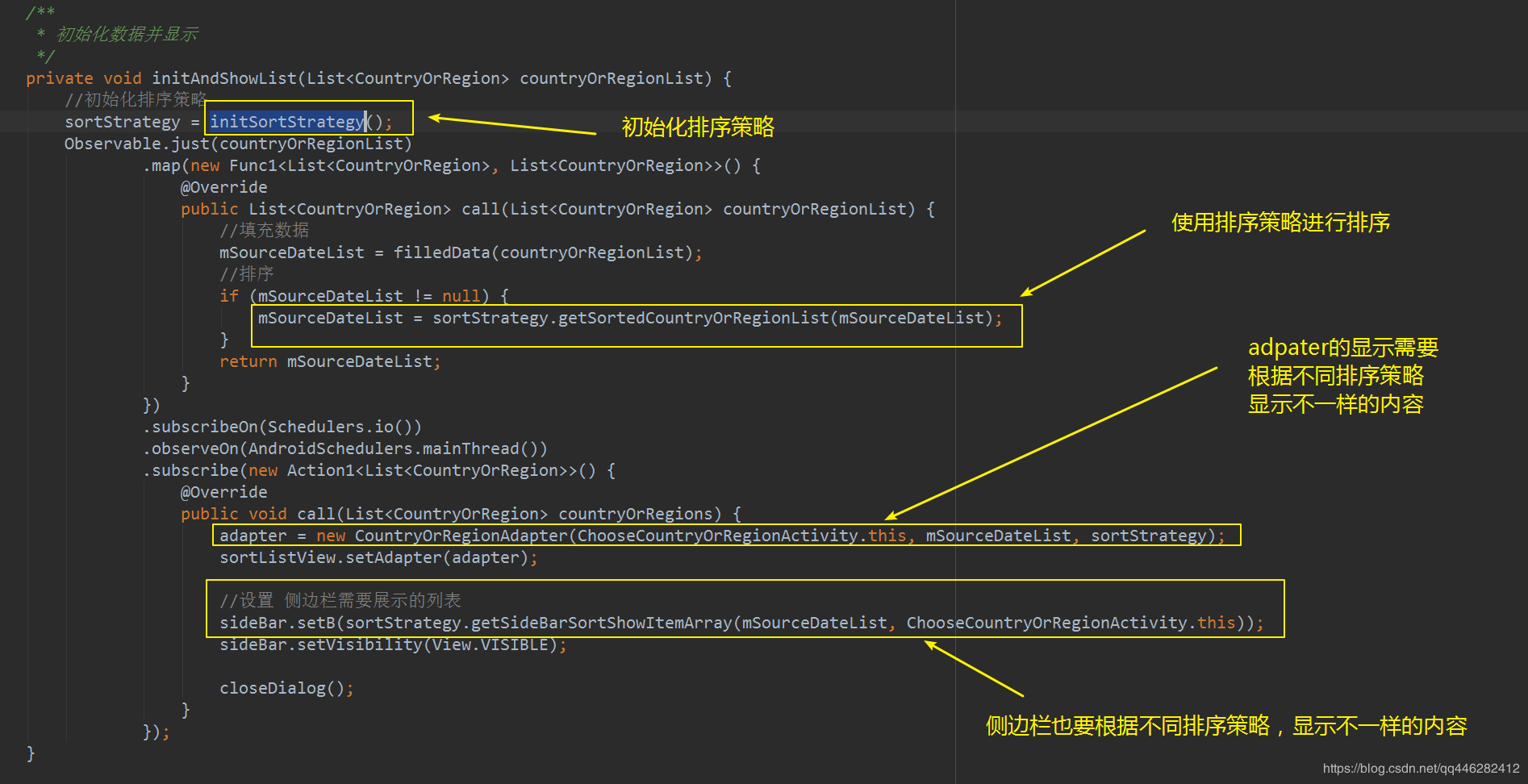
Adapter展示item标题的时候,根据不同策略展示不同的标题
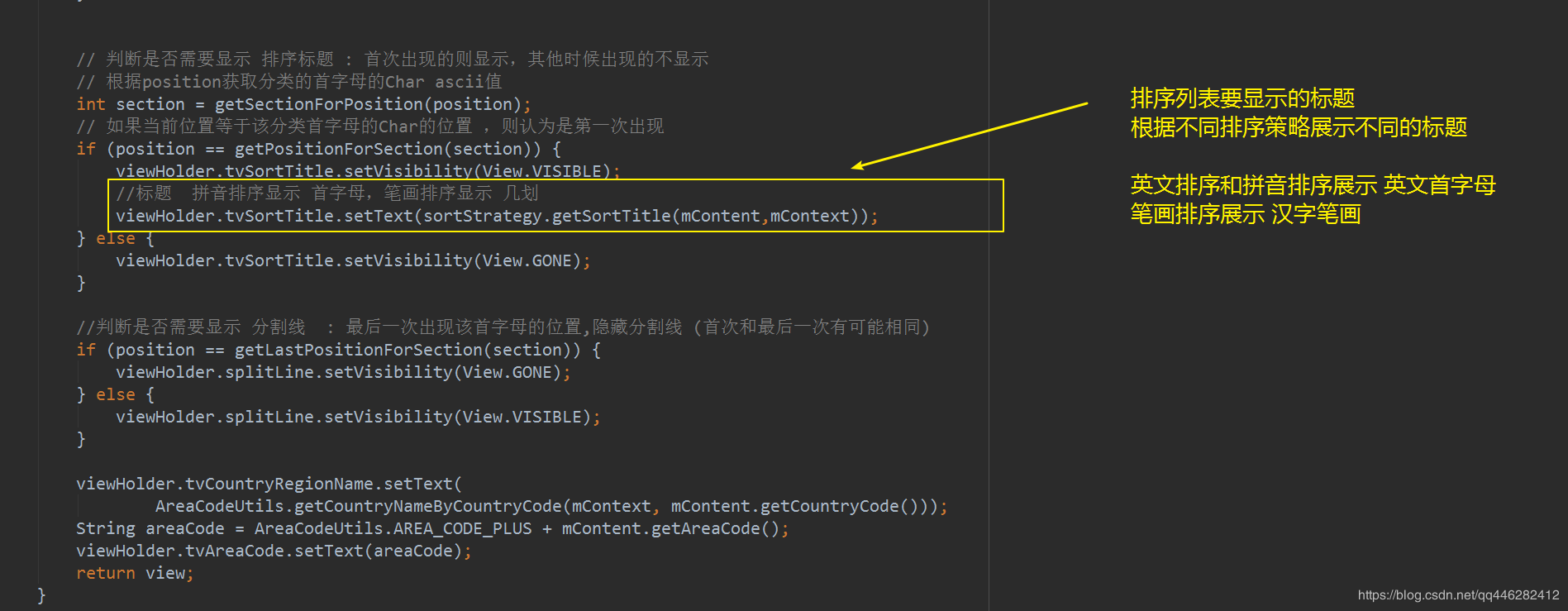
Adapter做逻辑判断位置的时候,不同的策略返回不同的位置

注:本文著作权归作者,由demo大师发表,拒绝转载,转载需要作者授权
Android实现中文汉字笔划(笔画)、中文拼音排序、英文排序的更多相关文章
- 简单测试--C#实现中文汉字转拼音首字母
第一种: 这个是自己写的比较简单的实现方法,要做汉字转拼音首字母,首先应该有一个存储首字母的数组,然后将要转拼音码的汉字与每个首字母开头的第一个汉字即“最小”的汉字作比较,这里的最小指的是按拼音规则比 ...
- java获取中文汉字的所有拼音
java获取中文汉字的所有拼音 中文汉字可能有很多读音,java中分别用1,2,3,4来区别,例如“作”字,就有三个读音,zuo1,zuo2,zuo4. java获取汉字读音拼音代码如下所示: S ...
- Android 正则表达式匹配汉字中文
关于中文的正则表达式, 应该是^[\\u4E00-\\u9FFF]+$, 和论坛里常被人提起的^[\\u4E00-\\u9FA5]+$很接近需要注意的是论坛里说的^[\\u4E00-\\u9FA5]+ ...
- Android输入法扩展之外接键盘中文输入
大家想不想要这样一台Android Surface平板,看着就过瘾吧. watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQvSVRsZWFrcw==/font/ ...
- Android 解压zip文件(支持中文)
过了n多天后,当再次使用原先博客上写的那篇: Android 压缩解压zip文件 去做zip包的解压的时候,出现了原来没有发现的很多问题.首先是中文汉字问题,使用java的zip包不能很好的解决解压问 ...
- 用C#生成随机中文汉字验证码的基本原理
前几天去申请免费QQ号码,突然发现申请表单中的验证码内容换成了中文,这叫真叫我大跌眼镜感到好笑,Moper上的猫儿们都大骂腾讯采用中文验证码.^_^ 我不得不佩服腾讯为了防止目前网络上横行的QQ号码 ...
- php使用strlen()判断中文汉字字符串长度
php使用strlen()判断中文汉字字符串长度 对于含有中文情况,此时可以采用: iconv_strlen($str,"UTF-8"); iconv_strlen 是无论是何种编 ...
- Oracle一个中文汉字占用几个字节
Oracle 一个中文汉字 占用几个字节,要根据Oracle中字符集编码决定 查看oracle server端字符集 select userenv('language') from dual; 如 ...
- char 型变量中能不能存贮一个中文汉字,为什么?
char类型可以存储一个中文汉字,因为Java中使用的编码是Unicode(不选择任何特定的编码,直接使用字符在字符集中的编号,这是统一的唯一方法),一个char类型占2个字节(16比特),所以放一个 ...
随机推荐
- Linux命令之du
Linux du命令用来查看文件或目录所占用磁盘空间的大小(Summarize disk usage of each FILE, recursively for directories.) 语法: d ...
- 强大的模板引擎开源软件NVelocity
背景知识NVelocity(http://sourceforge.net/projects/nvelocity )是从java编写的Velocity移植的.net版本,是java界超强的模版系统,.n ...
- verilog语法学习目录
verilog语法实例学习(1) Verilog中的注释 Verilog中的信号 标识符 信号的值 Verilog中的数字 Verilog中的参数 verilog语法实例学习(2) 线网类型 变量类型 ...
- 东芝发布运行Win 10的AR眼镜,它和Google Glass企业版有哪些异同?
https://www.leiphone.com/news/201803/Tw0nrq6vGDIvbmXr.html 雷锋网(公众号:雷锋网)获悉,3月13日,东芝发布新AR眼镜dynaEdge AR ...
- 轻松搞定 easyui datagrid 二次加载的问题(转)
对于使用url方式的初学者,经常碰到重复请求的问题,这个问题的根源是因为一旦设置了url参数,Datagrid组件在实例化的时候就会做请求,如何避免二次加载这样问题呢,个人觉得注意以下两点基本就可以防 ...
- 字符串 CSV解析 表格 逗号分隔值 通讯录 电话簿 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- Linq-插入insert
1.简单形式 说明:new一个对象,使用InsertOnSubmit方法将其加入到对应的集合中,使用SubmitChanges()提交到数据库. NorthwindDataContext db = n ...
- Spring(十五):通过注解配置 Bean
在ClassPath中扫描组件 1)组件扫描(component scanning):Spring能够从classpath下自动扫描,侦测和实例化具有特定注解的组件: 2)特定组件包含: --- @C ...
- rpcserver不可用
今天用打印机.电脑一直弹出rpcserver不可用.如图: 解决的方法:将例如以下服务启动就可以解决,如图:
- MySQL开启慢查询日志时报Errcode: 13 的解决方法
开启慢查询日志时会出现(Errcode: 13 - Permission denied)文件找不到的错误,但文件明明是存在的并且有读写的权限. mysql> set global slow_qu ...