FW 构建OpenStack的高可用性(HA,High Availability)
原文地址:http://blog.csdn.net/hilyoo/article/details/7704280
1、CAP理论
1) CAP 理论给出了3个基本要素:
- 一致性 ( Consistency) :任何一个读操作总是能读取到之前完成的写操作结果;
- 可用性 ( Availability) :每一个操作总是能够在确定的时间内返回;
- 分区可容忍性 (Tolerance of network Partition) :在出现网络分区的情况下,仍然能够满足一致性和可用性;
CAP 理论指出,三者不能同时满足。对这个理论有不少异议,但是它的参考价值依然巨大。
这个理论并不能为不满足这3个基本要求的设计提供借口,只是说明理论上3者不可绝对的满足,而且工程上从来不要求绝对的一致性或者可用性,但是必须寻求一种平衡和最优。
2) OpenStack、Swift与CAP的工程实践
对照CAP理论,OpenStack的分布式对象存储系统Swift满足了可用性和分区容忍性,没有保证一致性(可选的),只是实现了最终一致性。Swift如果GET操作没有在请求头中包含’X-Newest’头,那么这次读取有可能读到的不是最新的object,在一致性窗口时间内object没有被更新,那么后续GET操作读取的object将是最新的,保证了最终一致性;反之包含了’X-Newest’头,GET操作始终能读取到最新的obejct,就是一致的。
在OpenStack架构中,对于高可用性需要进行很多工作来保证。因此,下面将对OpenStack结构中的可用性进行讨论:
构建OpenStack的高可用性(HA,High Availability)
2、OpenStack的高可用性(OpenStack HA)

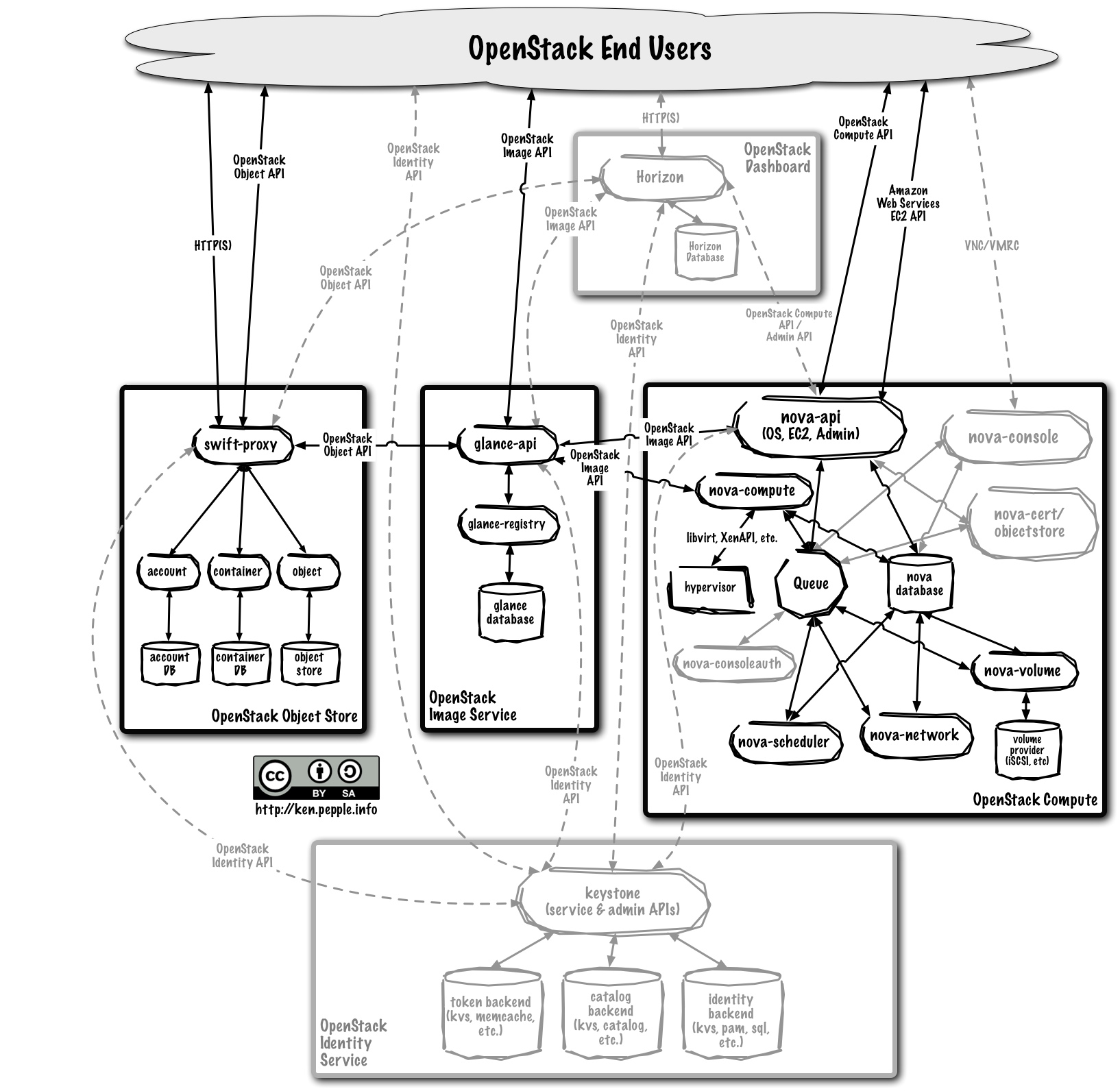
同其它大部分分布式系统一样,OpenStack也分为控制节点和计算节点两种不同功能的节点。控制节点提供除nova-compute以外的服务。这些组件和服务都是可以独立安装的,可以选择组合。
nova-compute在每个计算节点运行,暂且假设它是可信任的;或者使用备份机来实现故障转移(不过每个计算节点配置备份的代价相比收益似乎太大)。
控制节点的高可靠性是主要问题,而且对于不同的组件都有自己的高可靠性需求和方案。
(1)由于CotrolNode只有1个,且负责整个系统的管理和控制,因此当Cotrol Node不能提供正常服务时,怎么办?这就是常见的单节点故障(SPoF,single point of failure)问题。
高可用性基本上是没办法通过一台来达到目标的,更多的时候是设计方案确保在出问题的时候尽快接管故障机器,当然这要付出更大的成本。
对于单点问题,解决的方案一般是采用冗余设备或者热备,因为硬件的错误或者人为的原因,总是有可能造成单个或多个节点的失效,有时做节点的维护或者升级,也需要暂时停止某些节点,所以一个可靠的系统必须能承受单个或多个节点的停止。
常见的部署模式有:Active-passive主备模式,Active-active双主动模式,集群模式。
(2)那么如何构建冗余的控制节点?或者什么其它方法实现高可靠的控制?
很多人可能想到实现active-passive模式,使用心跳机制或者类似的方法进行备份,通过故障转移来实现高可靠性。Openstack是没有多个控制节点的,Pacemaker需要多种服务各自实现这种备份、监听和切换。
仔细分析控制节点提供的服务,主要就是nova-api、nova-network、nova-schedule、nova-volume,以及glance、keysonte和数据库mysql等,这些服务是分开提供的。nova-api、nova-network、glance等可以分别在每个计算节点上工作,RabbitMQ可以工作在主备模式,mysql可以使用冗余的高可用集群。
下面分别介绍:
1)nova-api和nova-scheduler的高可靠性
这样当控制节点出现故障,计算节点的nova-api等服务都照常进行。
2)nova-volume的高可靠性
3) 网络服务nova-network的高可靠性
OpenStack的网络已经存在多种高可靠的方案,常用的你只需要使用 --multi_host 选项就可以让网络服务处于高可用模式(high availability mode),具体介绍见Existing High Availability Options for Networking。
方案1: Multi-host
多主机。每个计算节点上配置nova-network。这样,每个计算节点都会实现NAT, DHCP和网关的功能,必然需要一定的开销,可以与hardware gateway方式结合,避免每个计算节点的网关功能。这样,每个计算节点都需要安装nova-compute外还要nova-network和nova-api,并且需要能连接外网。具体介绍见Nova Multi-host Mode against SPoF。
方案2: Failover
故障转移。能够4秒转移到热备份上,详细介绍见https://lists.launchpad.net/openstack/msg02099.html。不足之处是,需要备份机,而且有4秒延迟。
方案3: Multi-nic
多网卡技术。把VM桥接到多个网络,VM就拥有2种传出路由,实现故障时切换。但是这需要监听多个网络,也需要设计切换策略。
方案4: Hardware gateway
硬件网关。需要配置外部网关。由于VLAN模式需要对每个网络有一个网关,而hardware gateway方式只能对所有实例使用一个网关,因此不能在VLAN模式下使用。
方案5: Quantum(OpenStack下一个版本Folsom中)
Quantum的目标是逐步实现功能完备的虚拟网络服务。它暂时会继续兼容旧的nova-network的功能如Flat、Flatdhcp等。但是实现了类似multi_host的功能,支持OpenStack工作在主备模式(active-backup这种高可用性模式)。
Quantum只需要一个nova-network的实例运行,因此不能与multi_host模式共同工作。
Quantum允许单个租户拥有多个私人专用L2网络,通过加强QoS,以后应该能使hadoop集群很好的在nova节点上工作。
对于Quantum的安装使用,这篇文章Quantum Setup 有介绍。
4) glance、keystone的高可靠性
OpenStack的镜像可以使用swift存储,glance可以运行在多个主机。Integrating OpenStack ImageService (Glance) with Swift 介绍了glance使用swift存储。
集群管理工具 Pacemaker 是强大的高可用性解决方案,能够管理多节点集群,实现服务切换和转移,可与Corosync 和 Heartbeat等配套使用。Pacemaker 能够较为灵活的实现主备、N+1 、N-N 等多种模式。
bringing-high-availability-openstack-keystone-and-glance介绍了如何通过Pacemaker实现keystone和glance的高可靠。在每个节点安装OCF代理后,它能够告诉一个节点另一个节点是否正常运行glance和keysone服务,从而帮助Pacemaker开启、停止和监测这些服务。
5) Swift对象存储的高可靠性
|
Built-in Replication(N copies of accounts, container, objects) 3x+ data redundancy compared to 2x on RAID 内建冗余机制 RAID技术只做两个备份,而Swift最少有3个备份 |
High Availability 高可靠性 |
|
Easily add capacity unlike RAID resize 可以方便地进行存储扩容 |
Elastic data scaling with ease 方便的扩容能力 |
|
No central database 没有中心节点 |
Higher performance, No bottlenecks 高性能,无瓶颈限制 |
6) 消息队列服务RabbitMQ的高可靠性
RabbitMQ失效就会导致丢失消息,可以有多种HA机制:
- publisher confirms 方法可以在故障时通知什么写入了磁盘。
- 多机集群机制,但是节点失效容易导致队列失效。
- 主备模式(active-passive),能够实现故障时转移,但是启动备份机可能需要延迟甚至失效。
在容灾与可用性方面,RabbitMQ提供了可持久化的队列。能够在队列服务崩溃的时候,将未处理的消息持久化到磁盘上。为了避免因为发送消息到写入消息之间的延迟导致信息丢失,RabbitMQ引入了Publisher Confirm机制以确保消息被真正地写入到磁盘中。它对Cluster的支持提供了Active/Passive与Active/Active两种模式。例如,在Active/Passive模式下,一旦一个节点失败,Passive节点就会马上被激活,并迅速替代失败的Active节点,承担起消息传递的职责。如图所示:

图 Active/Passive Cluster(图片来自RabbitMQ官方网站)
active-passive模式存在所说的问题,因此,基于RabbitMQ集群引入了一种双主动集群机制(active-active)解决了这些问题。http://www.rabbitmq.com/ha.html这篇文章详细介绍了RabbitMQ的高可靠部署和原理。
7) 数据库mysql的高可靠性
集群并不就是高可靠,常用的构建高可靠的mysql的方法有Active-passive主备模式:使用DRBD实现主备机的灾容,Heartbeat或者Corosync做心跳监测、服务切换甚至failover,Pacemaker实现服务(资源)的切换及控制等;或者类似的机制。其中主要使用Pacemaker实现了mysql的active-passive高可用集群。
一个重要的技术是DRBD:(distributed replication block device)即分布式复制块设备,经常被用来代替共享磁盘。
它的工作原理是:在A主机上有对指定磁盘设备写请求时,数据发送给A主机的kernel,然后通过kernel中的一个模块,把相同的数据传送给B主机的kernel中一份,然后B主机再写入自己指定的磁盘设备,从而实现两主机数据的同步,也就实现了写操作高可用。DRBD一般是一主一从,并且所有的读写操作,挂载只能在主节点服务器上进行,,但是主从DRBD服务器之间是可以进行调换的。这里有对 DRBD 的介绍。
HAforNovaDB - OpenStack介绍了只使用共享磁盘而没有使用DRBD,通过Pacemaker实现OpenStack的高可靠。
NovaZooKeeperHeartbeat介绍了使用ZooKeeper作心跳检测。
Pacemaker与DRBD、Mysql的工作模式可以参考下图:

其它的方案,根据 MySQLPerformance Blog 的说法,MySQL几种高可用解决方案能达到的可用性如下:

3、构建高可用性的OpenStack(High-availability OpenStack)
一般来说,高可用性也就是建立冗余备份,常用策略有:
- 集群工作模式。多机互备,这样模式是把每个实例备份多份,没有中心节点,比如分布式对象存储系统Swift、nova-network多主机模式。
- 自主模式。有时候,解决单点故障(SPoF)可以简单的使用每个节点自主工作,通过去主从关系来减少主控节点失效带来的问题,比如nova-api只负责自己所在节点。
- 主备模式。常见的模式active-passive,被动节点处于监听和备份模式,故障时及时切换,比如mysql高可用集群、glance、keystone使用Pacemaker和Heartbeat等来实现。
- 双主模式。这种模式互备互援,RabbitMQ就是active-active集群高可用性,集群中的节点可进行队列的复制。从架构上来说,这样就不用担心passive节点不能启动或者延迟太大了?
总之,对于OpenStack的优化和改进不断,对于OpenStack的部署和应用也在不断尝试和发展。需要实践调优。实践非常重要,好的设计和想法需要实践来验证。
FW 构建OpenStack的高可用性(HA,High Availability)的更多相关文章
- HDFS HA(High Availability)高可用性
HDFS HA(High Availability)高可用性 参考文献: 官方文档 全文翻译 Hadoop组件之-HDFS(HA实现细节) 这张图片的个人理解 由于NameNode在Hadoop1只有 ...
- 理解 OpenStack 高可用(HA) (6): MySQL HA
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1)OpenStack 高可用方案概述 (2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3)N ...
- 集群(cluster)和高可用性(HA)的概念
1.1 什么是集群 简单的说,集群(cluster)就是一组计算机,它们作为一个整体向用户提供一组网络资源.这些单个的计算机系统就是集群的节点(node).一个理想的集群是,用户从来不会意识到集群系统 ...
- 理解 OpenStack 高可用(HA) (4): Pacemaker 和 OpenStack Resource Agent (RA)
本系列会分析OpenStack 的高可用性(HA)概念和解决方案: (1)OpenStack 高可用方案概述 (2)Neutron L3 Agent HA - VRRP (虚拟路由冗余协议) (3)N ...
- “高可用性”(High Availability)??
“高可用性”(High Availability)通常来描述一个系统经过专门的设计,从而减少停工时间,而保持其服务的高度可用性. 计算机的高可用性 计算机系统的可用性用平均无故障时间(MTTF)来度量 ...
- Citrix 服务器虚拟化之十 Xenserver高可用性HA
Citrix 服务器虚拟化之十 Xenserver高可用性HA HA是一套全自动功能设计,规划.它可以安全地恢复出现问题的XenServe 主机.例如物理破坏网络或主机的硬件故障,HA可确保无需任何人 ...
- 如何构建OpenStack镜像
本文以制作CentOS7.2镜像为例,详细介绍手动制作OpenStack镜像详细步骤,解释每一步这么做的原因.镜像上传到OpenStack glance,支持以下几个功能: 支持密码注入功能(nova ...
- openstack neutron L3 HA
作者:Liping Mao 发表于:2014-08-20 版权声明:能够随意转载,转载时请务必以超链接形式标明文章原始出处和作者信息及本版权声明 近期Assaf Muller写了一篇关于Neutro ...
- OpenStack G版以后的Availability Zone与Aggregate Hosts
关于Availability Zone与Aggregate Hosts的概念解析,可以参考这篇文章:http://blog.chinaunix.net/uid-20940095-id-3875022. ...
随机推荐
- iOS 定时器的比较
然而,在iOS中有很多方法完成以上的任务,到底有多少种方法呢?经过查阅资料,大概有三种方法:NSTimer.CADisplayLink.GCD.接下来我就一一介绍它们的用法. 一.NSTimer 1. ...
- Apache安全配置基线指导
搜索关键词:Apache安全配置基线指导 参考链接: windows服务器下Apache 的降权 https://www.landui.com/help/show-1749.html
- javax.net.ssl.SSLHandshakeException: sun.security.validator.ValidatorException: PKIX path building failed
1.使用HttpClient4.3 调用https出现如下错误: javax.net.ssl.SSLHandshakeException: sun.security.validator.Validat ...
- nessus 激活码
nessus激活码的申请 nessus屏蔽了中国的激活码申请,中国IP申请的时候会直接跳转到购买商业版的页面. 解决方法: 使用IE代理或者VPN,用美国的IP最好,然后访问网址: http://ww ...
- Elasticsearch 5.x 关于term query和match query的认识
http://blog.csdn.net/yangwenbo214/article/details/54142786 一.基本情况 前言:term query和match query牵扯的东西比较多, ...
- Linux 下 c 语言 聊天软件
这是我学C语言写的第一个软件,是一个完整的聊天软件,里面包括客户端,和服务器端,可以互现聊天,共享文件,有聊天室等,是一个有TCP和UDP协议的聊天软件,测试过很多次在CENTOS和UBUNTU下都通 ...
- Sqlserver Sequence操作
USE [database_test] GO --创建SEQUENCE CREATE SEQUENCE defaultSequence AS INT --设置开始行 START --自增量 INCRE ...
- .net环境下的缓存技术-转载!
摘要: 介绍缓存的基本概念和常用的缓存技术,给出了各种技术的实现机制的简单介绍和适用范围说明,以及设计缓存方案应该考虑的问题(共17页) 1 概念 1.1 缓存能解决的问题 · 性 ...
- Delphi Code Editor 之 基本操作
Delphi Code Editor 之 基本操作 毫无疑问,Delphi是高度可视化的.这是使用Delphi进行编程的最大好处之一.当然,任何一个有用的程序中都有大量手工编写的代码.当读者开始编写应 ...
- spy-debugger 前端调试工具
一站式页面调试.抓包工具.远程调试任何手机浏览器页面,任何手机移动端webview(如:微信,HybirdApp等).支持HTTP/HTTPS,无需USB连接设备. Language: Engl ...