Python 运算符与基本数据类型
一、运算符

2、比较运算:

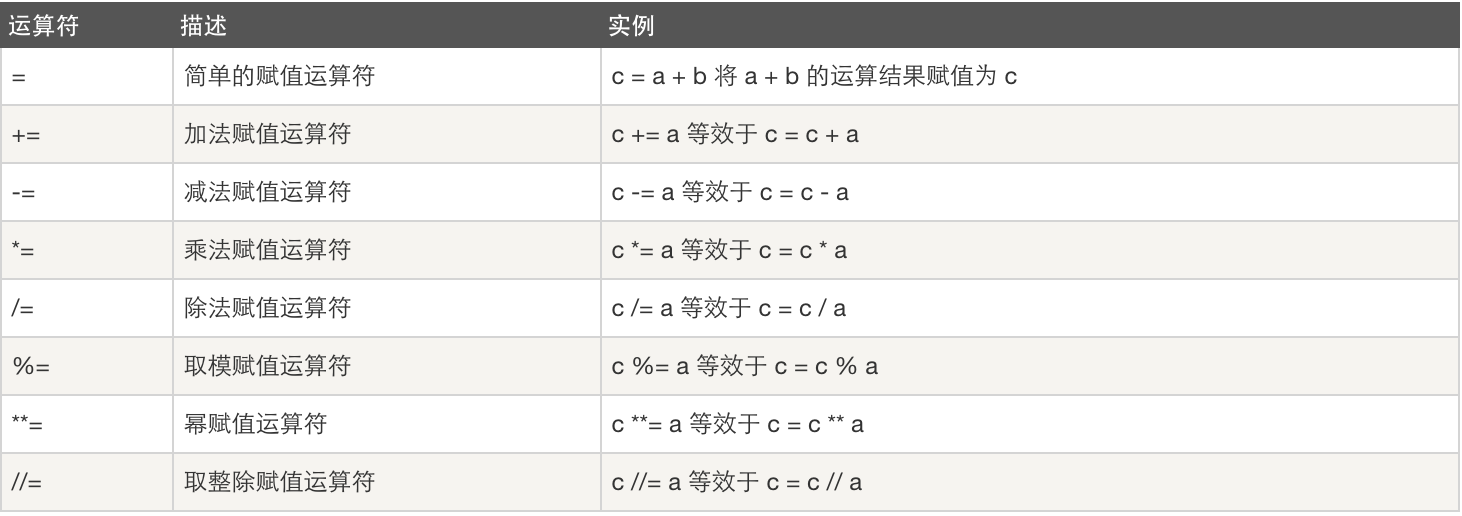
3、赋值运算:
4、逻辑运算:

5、成员运算:

二、基本数据类型
>>> True
True
>>> False
False
>>> 3 > 2
True
>>> 3 > 5
False
#布尔值还可以用and、or和not运算
>>> True and True
True
>>> True and False
False
>>> False and False
False
>>> True or True
True
>>> True or False
True
>>> False or False
False
>>> not True
False
>>> not False
True
#布尔值经常用在条件判断中,比如:
if age >= 18:
print('adult')
else:
print('teenager')
#以下结果为假,即None、‘’、[]、()、{}以及 0
>>> bool(None)
False
>>> bool('')
False
>>> bool([])
False
>>> bool(0)
False
>>> bool(())
False
>>> bool({})
False
int(整型)
在32位机器上,整数的位数为32位,取值范围为-2**31~2**31-1,即-2147483648~2147483647
############################################################ int 方法###########################################################
def bit_length(self):
pass
# 返回该整数用二进制表示时的最小位数
def __divmod__(self, *args, **kwargs):
pass
# 返回一个tuple, 包含两个元素,分别为self 与 argument相除的商和余数
###########################################################
# float 方法###########################################################
def as_integer_ratio(self):
pass
# 返回一个tuple, 即将float转化为分数形式
def fromhex(self, string):
pass
# 返回16进制表示的string转化为的float
def hex(self):
pass
# 与fromhex()相反
def is_integer(self, *args, **kwargs):
pass
# 返回 bool,判断float是否为整数
############################################################
# complex 方法#############################################################对于complex a, 可以通过a.real和a.imag使用其实部和虚部
def conjugate(self):
pass
# 返回复数的共轭复数
int, float,complex方法
"hello world"
- 移除空白
- 分割
- 长度
- 索引
- 切片
def capitalize(self):
pass
# 返回str的首字母大写,其余小写的形式, str不变
def casefold(self):
pass
# 返回str的所有字母变为小写的形式, str不变
def center(self, width, fillchar=None):
pass
# 返回str居中,长度为width,左右以fillchar填充的形式,str不变
def count(self, sub, start=None, end=None):
pass
# 返回str中[start, end)范围内sub的数目
def endswith(self, suffix, start=None, end=None):
pass
# 返回str的[start, end) 子序列是否以suffix结尾
def expandtabs(self, tabsize=8):
pass
# 返回str的所有tab变成tabsize长度的空格, str不变
def find(self, sub, start=None, end=None):
pass
# 返回str的[start, end) 范围内sub的位置, 未找到返回-1
def rfind(self, sub, start=None, end=None):
pass
# 与find()不同的是从右向左
def format(self, *args, **kwargs):
pass
# 返回str的格式化的字符串, 使用{}而非%,str不变
def index(self, sub, start=None, end=None):
pass
# 返回str的[start, end) 子序列的sub所在的下标, 未找到报错
def rindex(self, sub, start=None, end=None):
pass
# 与index()不同的是从右向左
def isalnum(self):
pass
# 返回str是否全部由字母和数字构成
def isalpha(self):
pass
# 返回str是否全部由字母构成
def isdigit(self):
pass
# 返回str是否全部由数字构成
def islower(self):
pass
# 返回str是否所有字母都是小写
def isupper(self):
pass
# 返回str是否所有字母都是大写
def isspace(self):
pass
# 返回str是否全部由空白字符构成
def istitle(self):
pass
# 返回是否所有单词都是大写开头
def join(self, iterable):
pass
# 返回通过指定字符str连接序列iterable中元素后生成的新字符串
def ljust(self, width, fillchar=None):
pass
# 返回str左对齐,不足width的以fillchar填充, str不变
def rjust(self, width, fillchar=None):
pass
# 返回str右对齐,不足width的以fillchar填充, str不变
def lower(self):
pass
# 返回str全部小写的拷贝, str不变
def upper(self):
pass
# 返回str全部大写的拷贝, str不变
def swapcase(self):
pass
# 返回str全部大小写交换的拷贝, str不变
def strip(self, chars=None):
pass
# 返回str移除左右两侧所有chars的拷贝,str不变
def lstrip(self, chars=None):
pass
# 返回str移除左侧所有chars的拷贝,str不变
def rstrip(self, chars=None):
pass
# 返回str移除右侧所有chars的拷贝,str不变
def partition(self, sep):
pass
# 返回str以sep分割的前,sep,后部分构成的tuple,
# 未发现返回sep和两个空字符构成的tuple
def rpartition(self, sep):
pass
# 和partition()不同的是从右向左
def replace(self, old, new, count=None):
pass
# 返回str把count数目的old替换为new的拷贝,str不变
def split(self, sep=None, maxsplit=-1):
pass
# 返回一个以sep分隔str的maxsplit(默认最大)的list,str不变
def rsplit(self, sep=None, maxsplit=-1):
pass
# 和split()不同的是从右向左
def splitlines(self, keepends=None):
pass
# 返回一个以\n或\r或\r\n分隔的list,若keepends=true,保留换行
def startswith(self, prefix, start=None, end=None):
pass
# 返回str的[start, end)范围内是否以prefix开头
def title(self):
pass
# 返回所有单词是大写开头的拷贝,str不变
def zfill(self, width):
pass
# 返回str的以width为长度,不够左侧补0的拷贝(不会截短),str不变
def maketrans(self, *args, **kwargs):
pass
# 返回生成的一个翻译表,与translate()搭配使用
def translate(self, table):
pass
# 根据maketrans()生成的table来翻译str,返回拷贝,str不变
str方法
str方法
a.对str中的方法的总结:
- 大小写,空格与table,特定格式等的转化,替换: capitalize,casefold,expandtabs,format,lower,upper,swapcase,replace,title,maketrans,translate
- 填充与移除字符串,连接与分隔字符串: center,strip,lstrip,rstrip,join,ljust,rjust,partition,rpartition,split,rsplit,splitlines,zfill
- 子序列数目,位置:count,find,rfind,index,rindex
- 判断字母,数字,大小写,空格,开头,结尾 :endswith,isalnum,isalpha,isdigit,islower,isupper,isspace,istitle,startswith
- 和左右扫描方向有关的方法一般还包括一个r__()方法,表示从右向左扫描
- 所有方法均不改变str,只是返回一个拷贝或bool
b.几个方法详解:
- format:
# 通过位置
string1 = "{0} is the most {1} teacher of life"
str1 = string1.format("Suffering", "powerful")
# str1 = "Suffering is the most powerful teacher of life"
string2 = "{0}, {1}, {0}"
str2 = string2.format("Edward", "Tang"}
# str2 = "Edward, Tang, Edward"
# 通过关键词
string = "{name} is {age}"
str = string.format(name="Edward", age=19)
# str = "Edward is 19"
# 填充和对齐
# ^、<、>分别是居中、左对齐、右对齐,后面带宽度
# :号后面带填充的字符,只能是一个字符,不指定的话默认是用空格填充
string1 = "{: >6}"
str1 = string1.format("Ed")
# str1 = " Ed"
string2 = "{:*<6}"
str2 = string2.format("Ed")
# str2 = "Ed****"
# 控制精度
string = “{:.2f}”
str1 = string.format(3.1415926)
# str1 = "3.14"
# 金额分隔符
string = "{:,}"
str = string.format(1234567)
# str = "1,234,567"
- maketrans和translate:
# s.maketrans('s1', 's2') s1 和 s2 的长度必须一致,生成一个转换表
# s.translate(table) 对字符串s按照table里的字符映射关系替换
s = "I was a handsome boy"
table = s.maketrans("abcde", "12345")
str = s.translate(table)
# str = "I w1s 1 h1n4som5 2oy"
- join和split:
# join用于用指定str连接参数的str序列
lst = ['a', 'b', 'c', 'd']
s = '-'.join(lst)
# s = "a-b-c-d"
def accum(s):
return '-'.join(c.upper() + c.lower() * i for i, c in enumerate(s))
# s = "abcd",返回 “A-Bb-Ccc-Dddd”
# split用于用指定参数拆分str
s = "a-b-c-d"
lst = s.split('-')
# lst = ['a', 'b', 'c', 'd']
c.索引和切片:
Python中的索引和C类似,但是可以从右边开始:
word = "python" # word[0] = 'p' # word[5] = 'n' # word[-1] = 'n', 表示最后一个, -0和0一样
除了索引, 还支持切片:
word = "python" # word[0: 2] = 'py' # word[2: 5] = 'tho' # word[: 2] = 'py', 等同于[0: 2] # word[3:] = 'hon', 等同于[3: len(word)] # word[::-1] = "nohtyp",反转字符串
切片和c++中的迭代器类似,都是为单闭合区间;
切记str是const的, 不可以通过赋值等改变它们
name_list = ['alex', 'seven', 'eric'] 或 name_list = list(['alex', 'seven', 'eric'])
基本操作:
- 索引
- 切片
- 追加
- 删除
- 长度
- 切片
- 循环
- 包含
def append(self, p_object):
pass
# 添加元素p_object到list末尾,p_object可以是任何类型
def clear(self):
pass
# 清空list中的元素
def copy(self):
pass
# 返回一个list的浅拷贝
def count(self, value):
pass
# 返回list中的value的个数
def extend(self, iterable)
pass
# 添加整个iterable到list末尾,扩展list
def index(self, value, start=None, stop=None):
pass
# 返回子序列[start, stop)中value第一次出现的下标,未找到报错
def insert(self, index, p_object):
pass
# 插入一个p_object到下标为index的元素之前
def pop(self, index=None):
pass
# 弹出index位置的元素并返回此元素, list为空或index超出范围会报错
def remove(self, value):
pass
# 清除list中第一个值为value的元素,不返回此值
def reverse(self):
pass
# 反转整个list
def sort(self, key=None, reverse=False):
pass
# 排序list,key可以为lambda或cmp,reverse为True需要反转
list方法
list方法
a.对list中方法的总结:
- 添加:append, extend, insert
- 删除:clear, pop, remove
- 搜素:count, index
- 拷贝:copy
- 排序:sort
- 反转:reverse
- 与str不同,list中元素大都直接修改list,返回None而不是拷贝
b.几个方法详解:
- append和extend:
lst = [1, 5, 4, 3, 8] lst.append(3) # lst = [1, 5, 4, 3, 8, 3] lst.append([1, 2, 3]) # lst = [1, 5, 4, 3, 8, 3, [1, 2, 3]],始终把参数当做一个元素 lst.extend([1, 2, 3]) #[1, 5, 4, 3, 8, 3, [1, 2, 3], 1, 2, 3],合并为一个list
c.索引和切片:
与str基本一致,但是由于list可变,还存在一个del语言:
lst = [3, 4, 5, 6, 7] del lst[0] # lst = [4, 5, 6, 7] del lst[1:3] # lst = [4, 7] del lst[:] # lst = []
6、元祖
ages = (11, 22, 33, 44, 55) 或 ages = tuple((11, 22, 33, 44, 55))
- 索引
- 切片
- 循环
- 长度
- 包含
def count(self, value):
pass
# 返回tuple中value的个数
def index(self, value, start=None, stop=None):
pass
# 返回子序列[start, stop)中第一个值为value的下标
tuple方法
tuple方法
person = {"name": "mr.wu", 'age': 18}
或
person = dict({"name": "mr.wu", 'age': 18})
常用操作:
- 索引
- 新增
- 删除
- 键、值、键值对
- 循环
- 长度
def clear(self):
pass
# 清空dict中的元素
def copy(self):
pass
# 返回dict的一个拷贝
def fromkeys(*args, **kwargs):
pass
# 返回一个dict,所有的key都对应同一个value(默认为None)
def get(self, k, d=None):
pass
# 返回key为k时对应的value,如果不存在,返回d
def setdefault(self, k, d=None):
pass
# 返回key为k时对应的value,如果不存在,添加一个k: d
def items(self):
pass
# 返回dict中所有key, value构成的dict_items()
def keys(self):
pass
# 返回dict中所有key构成的dict_keys()
def values(self):
pass
# 返回dict中所有value构成的dict_values()
def pop(self, k, d=None):
pass
# 弹出dict中k所对应的value,没找到返回d
def popitem(self):
pass
# 随机弹出dict中一个(key, value),dict为空时出错
def update(self, E=None, **F):
pass
# 用另一个dict F 来更新原dict, 返回None
dict方法
dict方法
- 添加:直接用dic[key] = value即可添加
- 删除:clear, pop, popitem
- 查找, 引用:get, setdefault, items, keys, values
- 构建:copy, fromkeys, update
- 与list类似,但由于是无序的,所有没有下标的操作,且popitem弹出的元素也是随机的
b.几个方法详解:
- pop和popitem:
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
# key为str的构建时也可以写成 dic = dict(k1 = 'v1', k2 = 'v2', k3 = 'v3)
k = dic.pop('k1')
# k = 'v1'且 dic = {'k2': 'v2', 'k3': 'v3'}
item = dic.popitems()
# item = (‘k2’, 'v2')或('k3', v3') 因为dic是无序的,且dic会随之变化
- get和setdefault:
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
s1 = get('k1') # s1 = dic['k1']
s2 = get('k4', 'v4') # s2 = 'v4'
s1 = setdefault('k1') # s1 = dic['k1']
s2 = setdefault('k4', 'v4') # dic['k4'] = 'v4'
- items, keys, values:
dic = {'k1': 'v1', 'k2': 'v2', 'k3': 'v3'}
for k in dic.keys():
print(k)
for v in dic.values():
print(v)
for k, v in dic.items():
print(k, v)
# 分别输出了dic中所有的key, value和键值对
- fromkeys和update:
# fromkeys第一个参数可以是任意类型的序列,
# 第二个参数为空默认value都为None
dic = dict.fromkeys(('k1', 'k2', 'k3'))
# dic = {'k2': None, 'k1': None, 'k3': None}
dic = dict.fromkeys(('k1', 'k2', 'k3'), 520)
# dic = {'k2': 520, 'k3': 520, 'k1': 520}
# update将dic1更新, 返回None
dic1 = {'k1': 13, 'k2': 14, 'k3': 520}
dic2 = {'k4': 'Edward', 'k3': '250'}
dic = dic1.update(dic2)
# dic = None
# dic2 = {'k1': 13, 'k2': 14, 'k3': 250, 'k4': 'Edward'}
def add(self, *args, **kwargs):
pass
# 向set中添加一个元素,返回None
def clear(self, *args, **kwargs):
pass
# 清空set中的元素
def copy(self, *args, **kwargs):
pass
# 返回一个set的浅拷贝
def difference(self, *args, **kwargs):
pass
# 返回一个set,其中不含参数集合中的元素,差集
def difference_update(self, *args, **kwargs):
pass
# 和difference()相比,set自身更新为差集,返回None
def symmetric_difference(self, *args, **kwargs):
pass
# 返回集合之间的对称差集
def symmetric_difference_update(self, *args, **kwargs):
pass
# 和symmetric_difference()相比,set自身更新为对称差集,返回None
def intersection(self, *args, **kwargs):
pass
# 返回set和参数集合的交集
def intersection_update(self, *args, **kwargs):
pass
# 和intersection()相比,set自身更新为交集,返回None
def union(self, *args, **kwargs):
pass
# 返回set和参数集合的并集
def update(self, *args, **kwargs):
pass
# 和union()相比,set自身更新为并集,返回None
def discard(self, *args, **kwargs):
pass
# 清除set中的参数元素,返回None, 若没有不做任何事,
def isdisjoint(self, *args, **kwargs):
pass
# 返回集合之间是否交集为空
def issubset(self, *args, **kwargs):
pass
# 返回是否set为参数集合的子集
def issuperset(self, *args, **kwargs):
pass
# 返回是否set为参数集合的父集
def pop(self, *args, **kwargs):
pass
# 弹出set中一个随机的值并返回,set为空会出错
def remove(self, *args, **kwargs):
pass
# 清除set中的参数元素,返回None,没有会出错
set方法
set方法
a.对set中方法的总结:
- 差集,交集,并集运算:difference, difference_update, symmetric_difference, symmetric_difference_update, intersection, intersection_update, union, update
- 添加元素:add
- 删除元素:clear, discard, remove, pop
- 拷贝:copy
- 判断空集,父集,子集:isdisjoint, issubset, issuperset
- 集合间的运算都有两个版本,分别直接在原set上操作和返回一个拷贝
- 与dict相比,没有key,也是无序的,所有没有下标操作,pop也是随机弹出元素
b.集合的运算符:
a, b, c均为集合
差集:c = a - b 等同于 c = a.difference(b)
a -= b 等同于 a.difference_update(b)
对称差集:c = a ^ b 等同于 c = a.symmetric_difference(b)
a ^= b 等同于 a.symmetric_difference_update(b)
交集:c = a & b 等同于 c = a.intersection(b)
a &= b 等同于 a.intersection_update(b)
并集:c = a | b 等同于 c = a.union(b)
a |= b 等同于 a.update(b)
判断子集: a <= b 等同于 a.issubset(b)
判断父集: a >= b 等同于 a.issupperset(b)
其他
li = [11,22,33,44]
for item in li:
print item
li = [11,22,33]
for k,v in enumerate(li, 1):
print(k,v)
print range(1, 10) # 结果:[1, 2, 3, 4, 5, 6, 7, 8, 9] print range(1, 10, 2) # 结果:[1, 3, 5, 7, 9] print range(30, 0, -2) # 结果:[30, 28, 26, 24, 22, 20, 18, 16, 14, 12, 10, 8, 6, 4, 2]
练习题
一、元素分类
有如下值集合 [11,22,33,44,55,66,77,88,99,90...],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {'k1': 大于66的所有值, 'k2': 小于66的所有值}
功能要求:
- 要求用户输入总资产,例如:2000
- 显示商品列表,让用户根据序号选择商品,加入购物车
- 购买,如果商品总额大于总资产,提示账户余额不足,否则,购买成功。
- 附加:可充值、某商品移除购物车
goods = [
{"name": "电脑", "price": 1999},
{"name": "鼠标", "price": 10},
{"name": "游艇", "price": 20},
{"name": "美女", "price": 998},
]
五、用户交互,显示省市县三级联动的选择
dic = {
"河北": {
"石家庄": ["鹿泉", "藁城", "元氏"],
"邯郸": ["永年", "涉县", "磁县"],
}
"河南": {
...
}
"山西": {
...
}
}
参考资料:
http://www.cnblogs.com/wupeiqi/articles/5444685.html
https://www.cnblogs.com/EdwardTang/p/5786007.html
Python 运算符与基本数据类型的更多相关文章
- (三)、python运算符和基本数据类型
运算符 1.算数运算: 2.比较运算: 3.赋值运算: 4.逻辑运算: 5.成员运算: 基本数据类型 1.数字 int(整形) # python3里不管数字有多长都叫整形# python2里分为整形和 ...
- python运算符与数据类型
python运算符 Python语言支持以下类型的运算符: 算术运算符 比较(关系)运算符 赋值运算符 逻辑运算符 位运算符 成员运算符 身份运算符 运算符优先级 以下假设变量: a=10,b=20: ...
- Python学习笔记 - day3 - 数据类型及运算符
Python的数据类型 计算机顾名思义就是可以做数学计算的机器,因此,计算机程序理所当然地可以处理各种数值.但是,计算机能处理的远不止数值,还可以处理文本.图形.音频.视频.网页等各种各样的数据,不同 ...
- Python 运算符与数据类型
Python 的创始人为吉多·范罗苏姆(Guido van Rossum).1989年的圣诞节期间,吉多·范罗苏姆为了在阿姆斯特丹打发时间,决心开发一个新的脚本解释程序,作为ABC语言的一种继承.Py ...
- python基础[1]——python运算符&python数据类型之数值型
python常用运算符&数字&布尔值 上节回顾 一.变量名和标识符 变量名的命名规范 (1)只能包含数字,字母和下划线 (2)只能以字母和下划线开头(不能以数字开头) (3)标识符是区 ...
- Python运算符,python入门到精通[五]
运算符用于执行程序代码运算,会针对一个以上操作数项目来进行运算.例如:2+3,其操作数是2和3,而运算符则是“+”.在计算器语言中运算符大致可以分为5种类型:算术运算符.连接运算符.关系运算符.赋值运 ...
- python变量与基础数据类型
一.什么是变量 变量是什么? 变量:把程序运行的中间结果临时的存在内存里,以便后续的代码调用.在python中一切都是变量. 1.python变量命名的要求 1,必须有数字,字母,下划线任意组合. ...
- Python学习之路--1.0 Python概述及基本数据类型
Python是一门解释性语言,弱类型语言 python程序的两种编写方式: 1.进入cmd控制台,输入python进入编辑模式,即可直接编写python程序 2.在.朋友文件中编写python代码,通 ...
- Python运算符及逻辑运算
基本运算符 运算符用于执行程序代码运算,会针对一个以上操作数项目来进行运算.例如:2+3,其操作数是2和3,而运算符则是“+”.在计算器语言中运算符大致可以分为5种类型:算术运算符.连接运算符.关系运 ...
随机推荐
- python中的range与xrange
range 也是一种类型(type),它是一个数字的序列(s sequence of numbers),而且是不可变的,通常用在for循环中. class range(stop) class rang ...
- CNN中的卷积理解和实例
卷积操作是使用一个二维卷积核在在批处理的图片中进行扫描,具体的操作是在每一张图片上采用合适的窗口大小在图片的每一个通道上进行扫描. 权衡因素:在不同的通道和不同的卷积核之间进行权衡 在tensorfl ...
- 从经典面试题看java中类的加载机制
1.概述 类加载是Java程序运行的第一步,研究类的加载有助于了解JVM执行过程,并指导开发者采取更有效的措施配合程序执行,对理解java虚拟机的连接模型和java语言的动态性都有很大帮助. 由于Ja ...
- iOS安装包重签笔记
https://blog.csdn.net/skylin19840101/article/details/60583893
- CGI servlet Applet Scriptlet Scriptlet JSP data layer(数据层),business layer(业务层), presentation layer(表现层)
https://en.wikipedia.org/wiki/Common_Gateway_Interface In computing, Common Gateway Interface (CGI) ...
- iOS-数据缓存(转载)
一.关于同一个URL的多次请求 有时候,对同一个URL请求多次,返回的数据可能都是一样的,比如服务器上的某张图片,无论下载多少次,返回的数据都是一样的. 上面的情况会造成以下问题 (1)用户流量的浪费 ...
- Balls and Boxes---hdu5810(推公式)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5810 有n个球m个盒子,随机把球放到盒子中,求每个盒子球个数的方差的期望值 E[V]; 推公式吧,或者 ...
- operator, itertools
import operator import itertools info_list = [ {'name': 'Quinn', 'age': 50}, {'name': 'Ryan', 'age': ...
- flask简单的路由分发
flask简单的路由分发 from flask import Flask, request app = Flask(__name__) @app.route('/hello') def index() ...
- (2.17)Mysql之SQL基础——日期函数
关键词:mysql时间函数,mysql日期函数 [1]curdate():返回当前日期(2019-03-06),curdate()+0 返回(20190306) [2]curtime():返回当前时间 ...